










CSAPP 第七章读书笔记 - Linking part1
链接(linking)是将各种代码和数据片段收集并组合成一个单一文件的过程,该文件可以加载(copied or loaded)到内存并执行。在编译(compile)时,源代码被翻译成机器代码;在加载(load)时,程序被加载到内存并由加载器(loader)执行;在运行(run)时,由应用程序进行。在早期的计算机系统中,链接是手动执行的。在现代系统中,链接是由称为链接器(linker)的程序自动执行的。
Compiler Drivers

gcc 指令:
gcc -Og -o prog main.c sum.c -v
这个命令的目的是使用 GCC 编译器,将 main.c 和 sum.c 这两个源代码文件编译成一个可执行文件,并且使用较低的优化级别 -Og 以保持代码可读性。生成的可执行文件将命名为 “prog”,并且使用 -v 选项来获取详细的编译信息。
[root@edb3963640a6 Linking]# gcc -Og -o prog main.c sum.c -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
Target: x86_64-redhat-linux
Configured with: ../configure --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap --enable-shared --enable-threads=posix --enable-checking=release --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu --enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin --enable-initfini-array --disable-libgcj --with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install --with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install --enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-redhat-linux
Thread model: posix
gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
COLLECT_GCC_OPTIONS='-Og' '-o' 'prog' '-v' '-mtune=generic' '-march=x86-64'
/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/cc1 -quiet -v main.c -quiet -dumpbase main.c -mtune=generic -march=x86-64 -auxbase main -Og -version -o /tmp/cc6Th7ko.s
GNU C (GCC) version 4.8.5 20150623 (Red Hat 4.8.5-44) (x86_64-redhat-linux)
compiled by GNU C version 4.8.5 20150623 (Red Hat 4.8.5-44), GMP version 6.0.0, MPFR version 3.1.1, MPC version 1.0.1
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
ignoring nonexistent directory "/usr/lib/gcc/x86_64-redhat-linux/4.8.5/include-fixed"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../x86_64-redhat-linux/include"
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-redhat-linux/4.8.5/include
/usr/local/include
/usr/include
End of search list.
GNU C (GCC) version 4.8.5 20150623 (Red Hat 4.8.5-44) (x86_64-redhat-linux)
compiled by GNU C version 4.8.5 20150623 (Red Hat 4.8.5-44), GMP version 6.0.0, MPFR version 3.1.1, MPC version 1.0.1
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
Compiler executable checksum: 231b3394950636dbfe0428e88716bc73
COLLECT_GCC_OPTIONS='-Og' '-o' 'prog' '-v' '-mtune=generic' '-march=x86-64'
as -v --64 -o /tmp/ccyVkyur.o /tmp/cc6Th7ko.s
GNU assembler version 2.27 (x86_64-redhat-linux) using BFD version version 2.27-44.base.el7_9.1
COLLECT_GCC_OPTIONS='-Og' '-o' 'prog' '-v' '-mtune=generic' '-march=x86-64'
/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/cc1 -quiet -v sum.c -quiet -dumpbase sum.c -mtune=generic -march=x86-64 -auxbase sum -Og -version -o /tmp/cc6Th7ko.s
GNU C (GCC) version 4.8.5 20150623 (Red Hat 4.8.5-44) (x86_64-redhat-linux)
compiled by GNU C version 4.8.5 20150623 (Red Hat 4.8.5-44), GMP version 6.0.0, MPFR version 3.1.1, MPC version 1.0.1
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
ignoring nonexistent directory "/usr/lib/gcc/x86_64-redhat-linux/4.8.5/include-fixed"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../x86_64-redhat-linux/include"
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-redhat-linux/4.8.5/include
/usr/local/include
/usr/include
End of search list.
GNU C (GCC) version 4.8.5 20150623 (Red Hat 4.8.5-44) (x86_64-redhat-linux)
compiled by GNU C version 4.8.5 20150623 (Red Hat 4.8.5-44), GMP version 6.0.0, MPFR version 3.1.1, MPC version 1.0.1
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
Compiler executable checksum: 231b3394950636dbfe0428e88716bc73
COLLECT_GCC_OPTIONS='-Og' '-o' 'prog' '-v' '-mtune=generic' '-march=x86-64'
as -v --64 -o /tmp/ccWYCrIu.o /tmp/cc6Th7ko.s
GNU assembler version 2.27 (x86_64-redhat-linux) using BFD version version 2.27-44.base.el7_9.1
COMPILER_PATH=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/:/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/:/usr/libexec/gcc/x86_64-redhat-linux/:/usr/lib/gcc/x86_64-redhat-linux/4.8.5/:/usr/lib/gcc/x86_64-redhat-linux/
LIBRARY_PATH=/usr/lib/gcc/x86_64-redhat-linux/4.8.5/:/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/:/lib/../lib64/:/usr/lib/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../:/lib/:/usr/lib/
COLLECT_GCC_OPTIONS='-Og' '-o' 'prog' '-v' '-mtune=generic' '-march=x86-64'
/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/collect2 --build-id --no-add-needed --eh-frame-hdr --hash-style=gnu -m elf_x86_64 -dynamic-linker /lib64/ld-linux-x86-64.so.2 -o prog /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crt1.o /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crti.o /usr/lib/gcc/x86_64-redhat-linux/4.8.5/crtbegin.o -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5 -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64 -L/lib/../lib64 -L/usr/lib/../lib64 -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../.. /tmp/ccyVkyur.o /tmp/ccWYCrIu.o -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/gcc/x86_64-redhat-linux/4.8.5/crtend.o /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crtn.o
步骤1:
The driver first runs the Cpreprocessor (cpp), which translates theCsource file main.c into an ASCII intermediate file main.i:
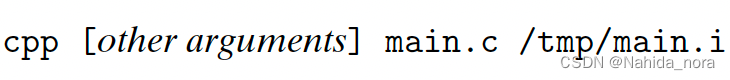
步骤二:
The driver runs the C compiler (cc1), which translates main.i into an ASCII assembly-language file main.s:
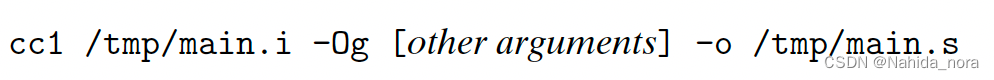
步骤三:
The driver runs the assembler (as), which translates main.s into a binary relocatable object file main.o:
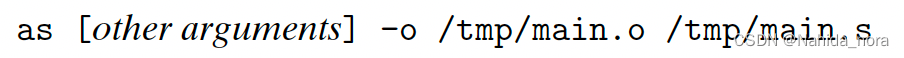
步骤四:
The driver runs the linker program ld ( 包括static linker), which combines main.o and sum.o, along with the necessary system object files, to create the binary executable object file prog:
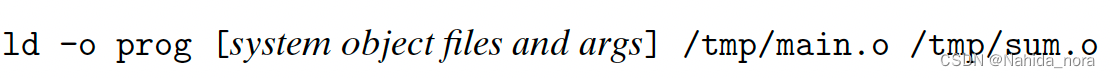
步骤五:
run the executable prog:
Shell调用操作系统中的一个名为加载器(loader)的函数,该加载器将可执行文件“prog”中的代码和数据复制到内存中,然后将控制权转移至程序的起始位置。
静态链接:
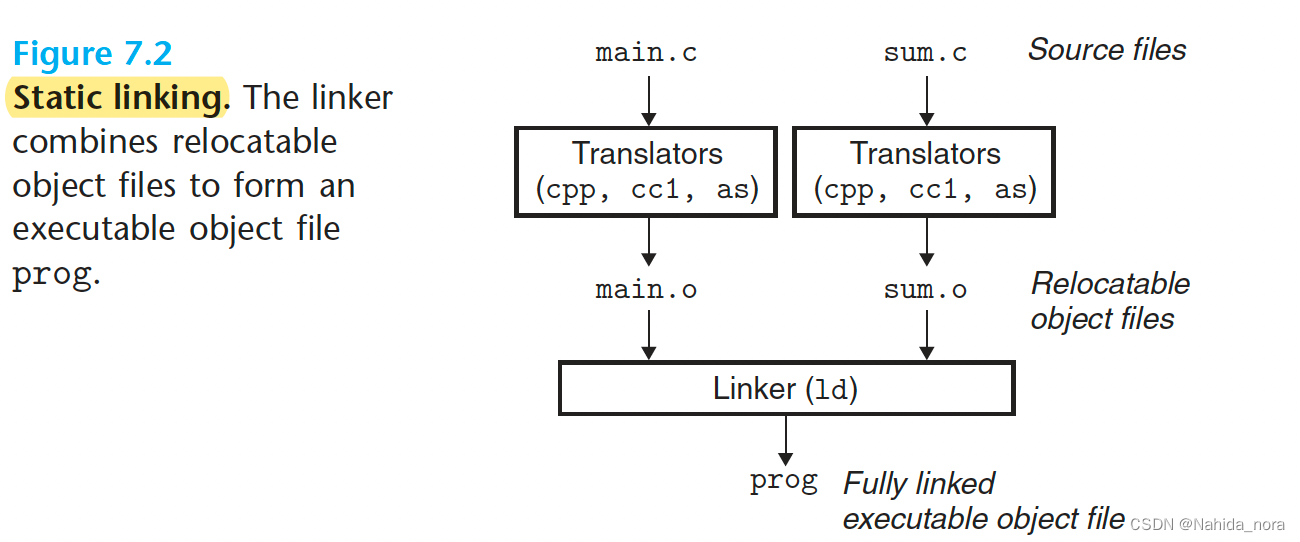
Static Linking
To build the executable, the linker must perform two main tasks:
- Symbol resolution
- Relocation: 编译器和汇编器生成从地址0开始的代码和数据段。链接器通过为每个符号定义关联一个内存位置,然后修改所有对这些符号的引用,使它们指向这个内存位置,来重新定位这些段。链接器通过使用由汇编器生成的详细指令,称为重定位项(relocation entries)。
ld 介绍
ld 是GNU Binutils工具集中的一个命令,用于链接目标文件并生成可执行文件。它在编译器生成目标文件之后,将这些目标文件组合在一起,解析符号引用,执行地址重定位,并生成最终的可执行文件。以下是 ld 的一些主要特性和用法:
-
目标文件的链接:
ld的主要任务是将一个或多个目标文件链接在一起,创建一个完整的可执行文件。这些目标文件可以是由编译器生成的,也可以是其他程序员提供的。 -
符号解析:
ld解析目标文件中的符号引用,确保每个符号都能找到其对应的定义。这通常涉及在不同目标文件之间解决函数和变量的引用关系。 -
地址重定位:链接器负责执行地址重定位,确保在不同目标文件中定义的地址能够正确地映射到最终的内存地址。这涉及到对目标文件中的地址引用进行调整。
-
库的链接:
ld也可以链接共享库(动态链接库),以便在运行时动态加载共享库。这样,程序可以共享和重用库中的代码和数据,减小可执行文件的大小。 -
脚本文件支持:通过使用链接脚本,
ld允许用户更灵活地控制链接过程,包括定义存储段(section)、分配地址空间等。链接脚本是一个文本文件,其中包含一系列指令,用于指导链接器如何组织可执行文件的各个部分。 -
动态链接器的调用:在某些系统中,
ld还负责生成可执行文件中的动态链接器的信息,以便在程序运行时动态加载共享库。
基本上,ld 是一个非常强大的工具,用于将各种目标文件组合成可执行文件。在实际编程中,通常通过调用高级编译器(如GCC)来隐式地使用 ld,而不是直接调用它。
Object Files
object files 主要分为3类:
目标文件有三种形式:
- 可重定位目标文件(Relocatable object file):包含以二进制形式表示的代码和数据,可以在编译时与其他可重定位目标文件合并,生成可执行目标文件。
- 可执行目标文件(Executable object file):包含以二进制形式表示的代码和数据,可以直接复制到内存并执行。
- 共享目标文件(Shared object file):一种特殊类型的可重定位目标文件,可以在加载时或运行时动态加载到内存并链接。
编译器和汇编器生成可重定位目标文件(包括共享目标文件)。链接器生成可执行目标文件(object file)。从技术上讲,目标模块(object module)是一系列字节,而目标文件(object file)是存储在磁盘上目标模块的文件。
目标文件按照特定的目标文件格式(object file format)组织,这些格式因系统而异。最初的Unix系统使用a.out格式。Windows使用可移植可执行(PE)格式。Mac OS-X使用Mach-O格式。现代的x86-64 Linux和Unix系统使用可执行和可链接格式(ELF)。这些格式的基本概念是相似。
Relocatable Object Files
ELF格式的object file格式:
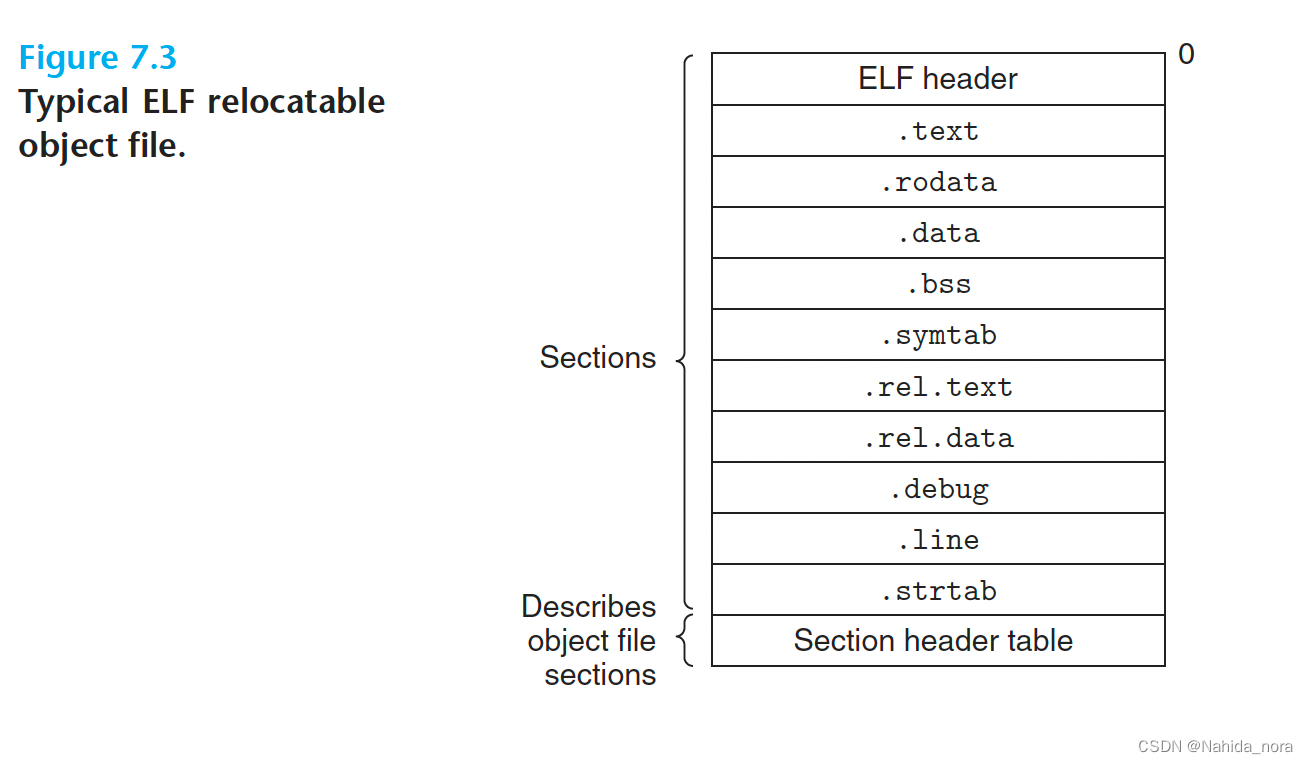
图7.3显示了典型的ELF可重定位目标文件的格式。ELF头以一个16字节的序列开头,描述了生成文件的系统的字长和字节顺序。ELF头的其余部分包含使链接器能够解析和解释目标文件的信息。这包括ELF头的大小,目标文件类型(例如,可重定位、可执行或共享),机器类型(例如,x86-64),段头表的文件偏移量,以及段头表中的条目大小和数量。各个段的位置和大小由段头表(section header table)描述,该表对目标文件中的每个段包含一个固定大小的条目。
Symbols and Symbol Tables
每个可重定位目标模块(relocatable object module) m都有一个符号表(symbol table),其中包含有关由m定义和引用的符号的信息。在链接器的上下文中,有三种不同类型的符号:
- 全局符号(Global symbols)由模块m定义,并且可以被其他模块引用。全局链接符号对应于非静态的C函数和全局变量(nonstatic C functions and global variables)。
- 全局符号(Global symbols)由模块m引用,但由其他某个模块定义。这些符号被称为外部符号(externals),对应于在其他模块中定义的非静态C函数和全局变量。(nonstatic C functions and global variables that are defined in other modules)
- 本地符号(Local symbols)由模块m专属地定义和引用。这些符号对应于在模块m中使用static属性定义的静态C函数和全局变量。(static C functions and global variables that are defined with the static attribute.)这些符号在模块m内部任何地方都是可见的,但不能被其他模块引用。
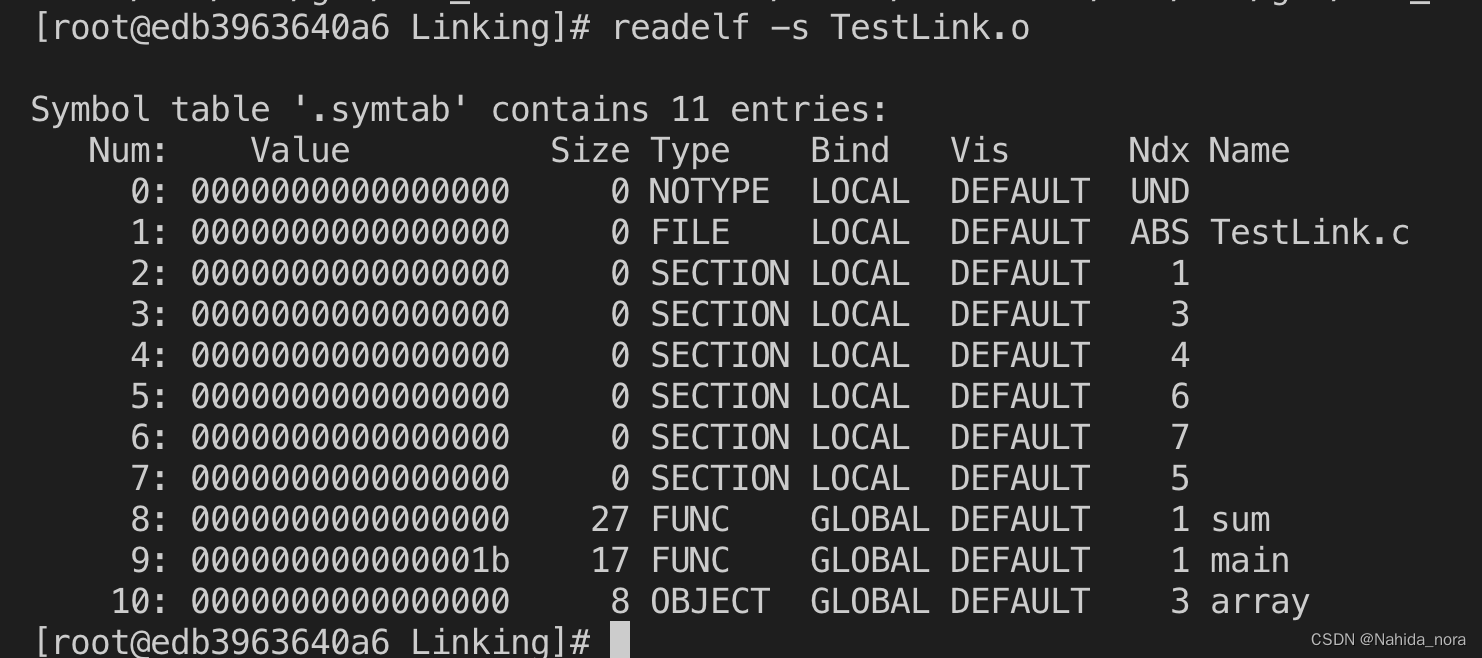
使用readelf 打印符号表:

编译器向汇编器导出一对具有不同名称的局部链接符号。例如,它可能对函数 f 中的定义使用 x.1,而对函数 g 中的定义使用 x.2。
符号表是由汇编器构建的,它使用由编译器导出到汇编语言 .s 文件中的符号。ELF(Executable and Linkable Format)符号表包含在 .symtab 节中。
简而言之,编译器导出局部链接符号,这些符号在函数 f 和函数 g 中具有不同的名称,例如 x.1 和 x.2。符号表是由汇编器构建的数据结构,它包含在 ELF 文件的 .symtab 节中,每个条目描述一个符号的信息。
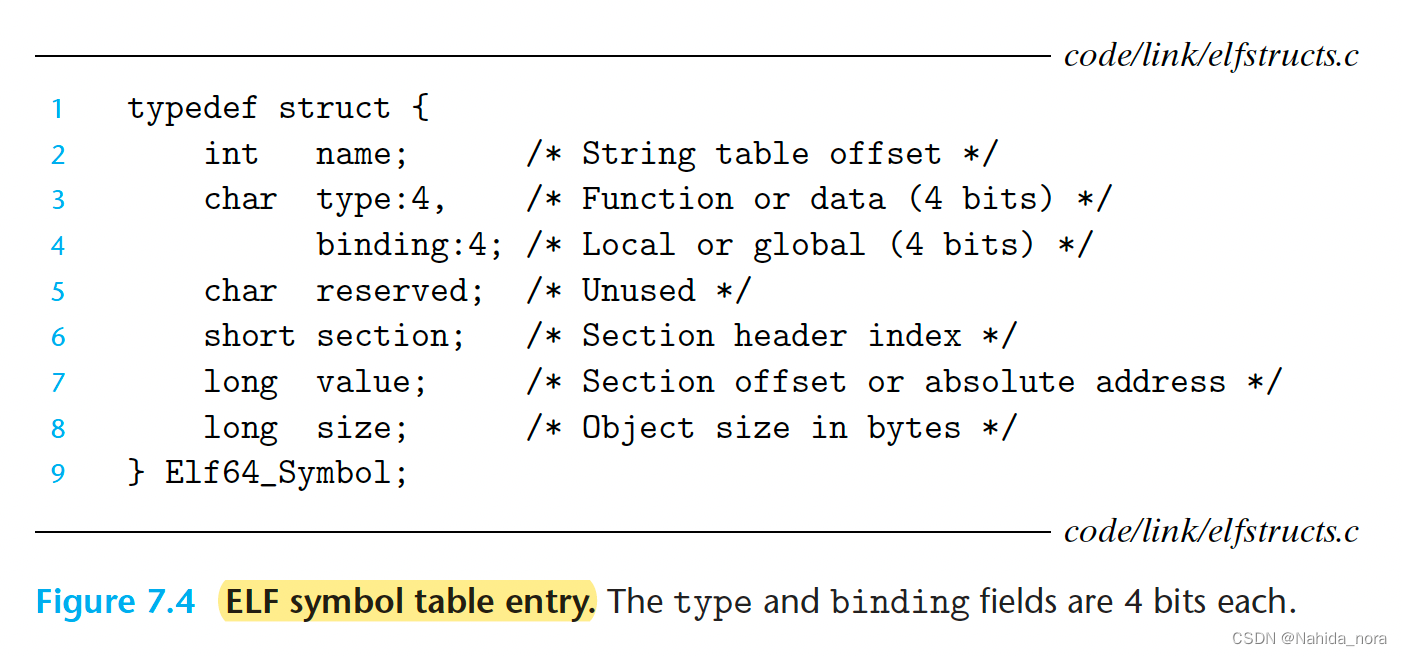
图 7.4 展示了每个条目的格式。symbol table 是条目的数组。
名称是一个字节偏移,指向字符串表中符号的以 null 结尾的字符串名称。 (The name is a byte offset into the string table that points to the null-terminated string name of the symbol.)
值是符号的地址。对于可重定位模块,该值是从定义对象的部分开头的偏移量。对于可执行对象文件,该值是绝对运行时地址。 (The value is the symbol’s address. For relocatable modules, the value is an offset from the beginning of the section where the object is defined. For executable object files, the value is an absolute run-time address.)
大小是对象的大小(以字节为单位)。类型通常是数据或函数。符号表还可以包含有关各个部分和原始源文件路径的条目。因此,这些对象也有各自的类型。 (The size is the size (in bytes) of the object. The type is usually either data or function. The symbol table can also contain entries for the individual sections and for the path name of the original source file. So there are distinct types for these objects as well.)
绑定字段指示符号是本地的还是全局的。每个符号分配给对象文件的某个部分,由部分字段表示,该字段是部分头表的索引。 (The binding field indicates whether the symbol is local or global. Each symbol is assigned to some section of the object file, denoted by the section field, which is an index into the section header table.)
有三个特殊的伪部分,它们没有部分头表中的条目:ABS 用于不应重新定位的符号。UNDEF 用于未定义的符号,即在此对象模块中引用但在其他地方定义的符号。COMMON 用于尚未分配的未初始化数据对象。对于 COMMON 符号,值字段给出对齐要求,大小字段给出最小大小。 (There are three special pseudosections that don’t have entries in the section header table: ABS is for symbols that should not be relocated. UNDEF is for undefined symbols—that is, symbols that are referenced in this object module but defined elsewhere. COMMON is for uninitialized data objects that are not yet allocated. For COMMON symbols, the value field gives the alignment requirement, and size gives the minimum size.)
请注意,这些伪部分仅存在于可重定位的目标文件中;它们不存在于可执行的目标文件中。 (Note that these pseudosections exist only in relocatable object files; they do not exist in executable object files.)
COMMON 和 .bss 之间的不同与linker有关。

readelf 例子:

前八个未显示的条目是链接器在内部使用的本地符号。在这个例子中,一个用于定义全局符号 main 的条目,Ndx=1 表示 .text 部分,这是一个位于 .text 部分偏移(即值)为零的 24 字节函数。接下来是对全局符号 array 的定义,Ndx=3 表示 .data 部分,是一个位于 .data 部分偏移为零的 8 字节对象。最后一个条目来自对外部符号 sum 的引用。
Symbol Resolution
代码举例:

执行gcc:

链接器(linker)通过将每个引用与其输入的可重定位目标文件(input relocatable object files)的符号表中的一个符号定义关联来解析符号引用。对于引用与引用所在模块相同的局部符号,符号解析是直观的。编译器(compiler)每个模块只允许一个局部符号的定义。编译器还确保具有局部链接器符号(local linker symbols)的静态局部变量(static local variables)具有唯一的名称。
对全局符号的引用解析更加棘手。当编译器(compiler)遇到一个在当前模块中未定义的符号(变量或函数名)时,它假定该符号在某个其他模块中定义,生成一个链接器符号表条目(linker symbol table entry,),并留给链接器(linker)处理。如果链接器在其输入的任何模块中找不到被引用符号的定义,它会打印一个错误消息并终止。
Linkers Resolve Duplicate Symbol Names
在编译时,编译器将每个全局符号导出到汇编器时标记为强符号(strong)或弱符号(weak),而汇编器会将这些信息隐式地编码到可重定位目标文件的符号表中。
Linux linkers 使用以下三条规则处理duplicate symbol names:
Functions and initialized global stvariables get strong symbols. Uninitialized global variables get weak symbols.

compile 和 link 的例子:
case1:

2个同名strong symbol。
case2:

bae3.c 的f()函数的x会修改foo3.c的x, 因为foo3.c的x是strong symbol,导致函数输出不符合预期。
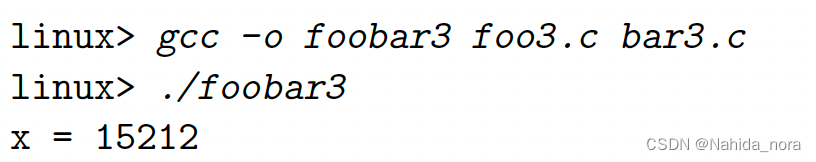
case3:


double 是8字节,int是4字节。 执行f(), 会覆盖foo5.c的int x和y的值。但是执行gcc不会出现error, 而是一个warning。
可以通过增加gcc参数规避问题,例如-fno-common flag,存在多个重名的global symbol会出发error;-Werror, 将warning转化为error。
Functions and initialized global stvariables get strong symbols. Uninitialized global variables get weak symbols.
因为在某些情况下,链接器允许多个模块定义具有相同名称的全局符号。当编译器正在翻译某个模块并遇到一个弱全局符号,比如x时,它不知道是否还有其他模块也定义了x,如果是这样,它无法预测链接器可能会选择哪个x的多个实例。因此,编译器将决策推迟到链接器,通过将x分配给COMMON。另一方面,如果x被初始化为零,则它是一个强符号(因此必须按照规则2唯一),因此编译器可以自信地将其分配给.bss。类似地,静态符号由于构造而是唯一的,因此编译器可以自信地将它们分配给.data或.bss。
Linking with Static Libraries
在链接时,链接器只会复制程序引用的目标模块,这降低了可执行文件在磁盘和内存中的大小。另一方面,应用程序员只需要包含少量库文件的名称。(事实上,C编译器驱动程序总是将libc.a传递给链接器,所以先前提到的对libc.a的引用是不必要的。)
在Linux系统中,静态库以一种称为存档的特定文件格式存储在磁盘上。存档是一组串联的可重定位目标文件,带有一个头部,描述了每个成员目标文件的大小和位置。存档的文件名以.a为后缀。
为了使我们对库的讨论更具体,考虑图7.6中的一对vector例程。每个例程在其自己的目标模块中定义,对输入vectors进行vector operation,并将结果存储在输出vector中。作为副作用,每个例程需要通过递增一个全局变量记录调用次数。
创建静态库libvector.a:
linux> gcc -c addvec.c multvec.c
linux> ar rcs libvector.a addvec.o multvec.o
//vector.h
#ifndef VECTOR_H
#define VECTOR_H
void addvec(int *x, int *y, int *z, int n);
void multvec(int *x, int *y, int *z, int n);
#endif
//main2.c
#include <stdio.h>
#include "vector.h"
int x[2] = {1, 2};
int y[2] = {3, 4};
int z[2];
int main(){
addvec(x, y, z, 2);
printf("z = [%d %d]\n", z[0], z[1]);
return 0;
}
要使用该库,可以编写一个应用程序,如图7.7中的main2.c,它调用addvec库例程。包含(或头)文件vector.h定义了libvector.a中例程的函数原型。
为了构建可执行文件,我们将编译和链接输入文件main2.o和libvector.a:
linux> gcc -c main2.c
linux> gcc -static -o prog2c main2.o /home/csapp/Linking/libvector.a
or
linux> gcc -c main2.c
linux> gcc -static -o prog2c main2.o -L. -lvector
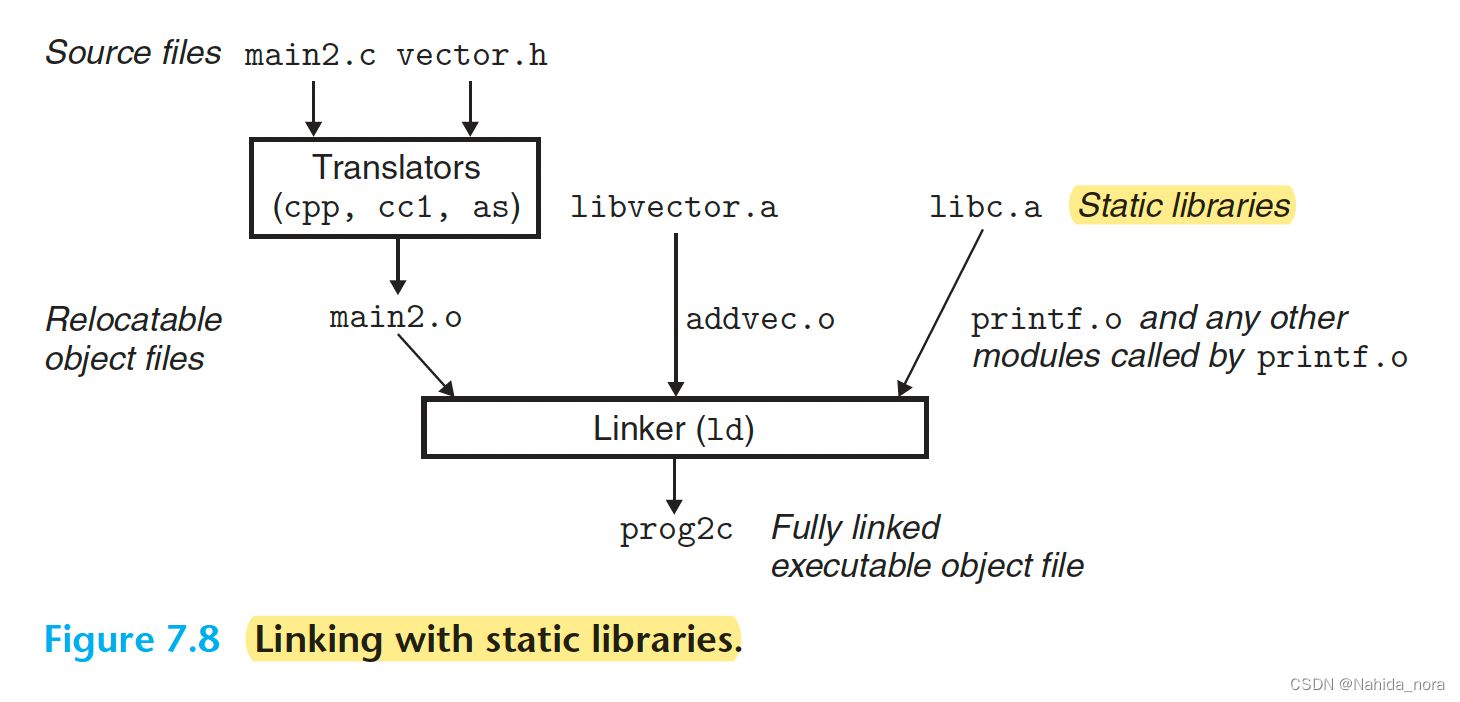
在链接器运行时,它确定由 addvec.o 定义的 addvec 符号被 main2.o 引用,因此将 addvec.o 复制到可执行文件中。由于程序未引用由 multvec.o 定义的任何符号,因此链接器不会将该模块复制到可执行文件中。链接器还从 libc.a 复制了 printf.o 模块,以及来自C运行时系统的许多其他模块。
How Linkers Use Static Libraries to Resolve References
在符号解析阶段,链接器按照与编译器驱动程序命令行上的顺序相同的顺序从左到右扫描可重定位目标文件和存档文件(档案文件包含多个可重定位目标文件)。(驱动程序会自动将命令行上的任何 .c 文件转换为 .o 文件。)在此扫描期间,链接器维护了一组将被合并以形成可执行文件的可重定位目标文件集 E(relocatable object files),一组未解析的符号集 U(即被引用但尚未定义的符号),以及一组在先前输入文件中已经定义的符号集 D。最初,E、U 和 D 都为空。
对于命令行(command line)上的每个输入文件 f,链接器确定 f 是否是一个目标文件或一个存档(object file or an archive)。如果 f 是一个目标文件(object file),链接器将 f 添加到 E,更新 U 和 D 以反映 f 中的符号定义和引用,然后继续处理下一个输入文件。
如果 f 是一个存档(archive),链接器尝试将 U 中未解析的符号与存档的成员定义的符号进行匹配。如果某个存档成员 m (archive
member)定义了解决 U 中引用的符号,则将 m 添加到 E,并更新 U 和 D 以反映 m 中的符号定义和引用。这个过程迭代地遍历存档中的成员目标文件,直到达到一个固定点,即 U 和 D 不再改变。此时,任何未包含在 E 中的成员目标文件都被简单地丢弃,链接器继续处理下一个输入文件。
如果在链接器完成对命令行上的输入文件的扫描时 U 不为空,它会打印一个错误并终止。否则,它将合并和重定位 E 中的目标文件以构建输出的可执行文件(executable file)。
这个算法可能会导致一些令人困惑的链接时错误,因为命令行上库和目标文件的顺序是重要的。如果定义一个符号的库在命令行上出现在引用该符号的目标文件之前,那么引用将无法解析,链接将失败。

当处理 libvector.a 时,U 是空的,因此 libvector.a 中的任何成员目标文件都不会被添加到 E 中。因此,对 addvec 的引用永远不会被解析,链接器会输出一个错误消息并终止。
对于库的一般规则是将它们放在命令行的末尾。如果不同库的成员是独立的,即没有一个成员引用另一个成员定义的符号,那么这些库可以以任意顺序放在命令行的末尾。然而,如果库不是独立的,那么它们必须按照这样的顺序排列:对于由存档的成员在外部引用的每个符号 s,至少一个 s 的定义必须在命令行上的对 s 的引用之后。例如,假设 foo.c 调用 libx.a 和 libz.a 中的函数,而libx.a和libz.a调用 liby.a 中的函数。那么在命令行上,libx.a 和 libz.a 必须在 liby.a 之前:
linux> gcc foo.c libx.a libz.a liby.a
如果必要,可以在命令行上重复库以满足依赖关系的要求。例如,假设 foo.c 调用 libx.a 中的一个函数,libx.a的函数调用 liby.a 中的一个函数,后者liby.a又调用 libx.a 中的一个函数。那么 libx.a 必须在命令行上重复:
linux> gcc foo.c libx.a liby.a libx.a
或者,我们也可以将 libx.a 和 liby.a 合并成一个单独的存档。
gcc main.c /usr/lib/printf.o /usr/lib/scanf.o 和 gcc main.c /usr/lib/libm.a /usr/lib/libc.a 的区别?
-
gcc main.c /usr/lib/printf.o /usr/lib/scanf.o:-
在这个命令中,你正在编译源文件
main.c,并显式地将其与对象文件/usr/lib/printf.o和/usr/lib/scanf.o链接在一起。 -
/usr/lib/printf.o和/usr/lib/scanf.o是包含 printf 和 scanf 函数编译代码的独立对象文件。你直接指定这些对象文件与你的main.c进行链接。
-
-
gcc main.c /usr/lib/libm.a /usr/lib/libc.a:-
在这个命令中,你正在编译源文件
main.c,并将其与静态库/usr/lib/libm.a和/usr/lib/libc.a链接在一起。 -
/usr/lib/libm.a是数学函数的静态库,/usr/lib/libc.a是标准 C 库的静态库。 -
当你链接到一个静态库时,链接器只会将库中对你程序中使用的符号有影响的对象文件引入。这可能包括各种标准函数,比如数学库 (
libm) 和 C 库 (libc) 中提供的函数。
-
总的来说,主要的区别在于你正在链接的内容:
-
在第一个命令中,你直接链接了与 printf 和 scanf 相关的特定对象文件。
-
在第二个命令中,你链接了标准 C 库 (
libc.a) 和数学库 (libm.a),它们包含一系列提供标准 C 函数和数学函数的对象文件。
Relocation
链接器完成了符号解析步骤,它就将代码中的每个符号引用与确切的一个符号定义关联(即,与其输入目标模块中的符号表条目关联)。链接器知道了其输入目标模块中代码和数据部分的确切大小。现在,它准备开始重定位步骤,在这一步中,它合并输入模块并为每个符号分配运行时地址。重定位包括两个步骤:
-
重定位部分和符号定义。在这一步中,链接器将相同类型的所有部分合并为相同类型的新的聚合部分。例如,来自输入模块的 .data 部分都被合并成一个将成为输出可执行对象文件(input modules)的 .data 部分。然后,链接器为新的聚合部分、由输入模块定义的每个部分以及输入模块定义的每个符号分配运行时内存地址。完成这一步后,程序中的每个指令和全局变量都具有唯一的运行时内存地址。
-
在部分内部重定位符号引用(relocating symbol references)。在这一步中,链接器修改代码和数据部分体内的每个符号引用,使其指向正确的运行时地址(run-time addresses)。为执行这一步,链接器依赖于可重定位目标模块(relocatable object modules)中的数据结构,称为重定位条目(relocation entries),我们将在接下来进行描述。
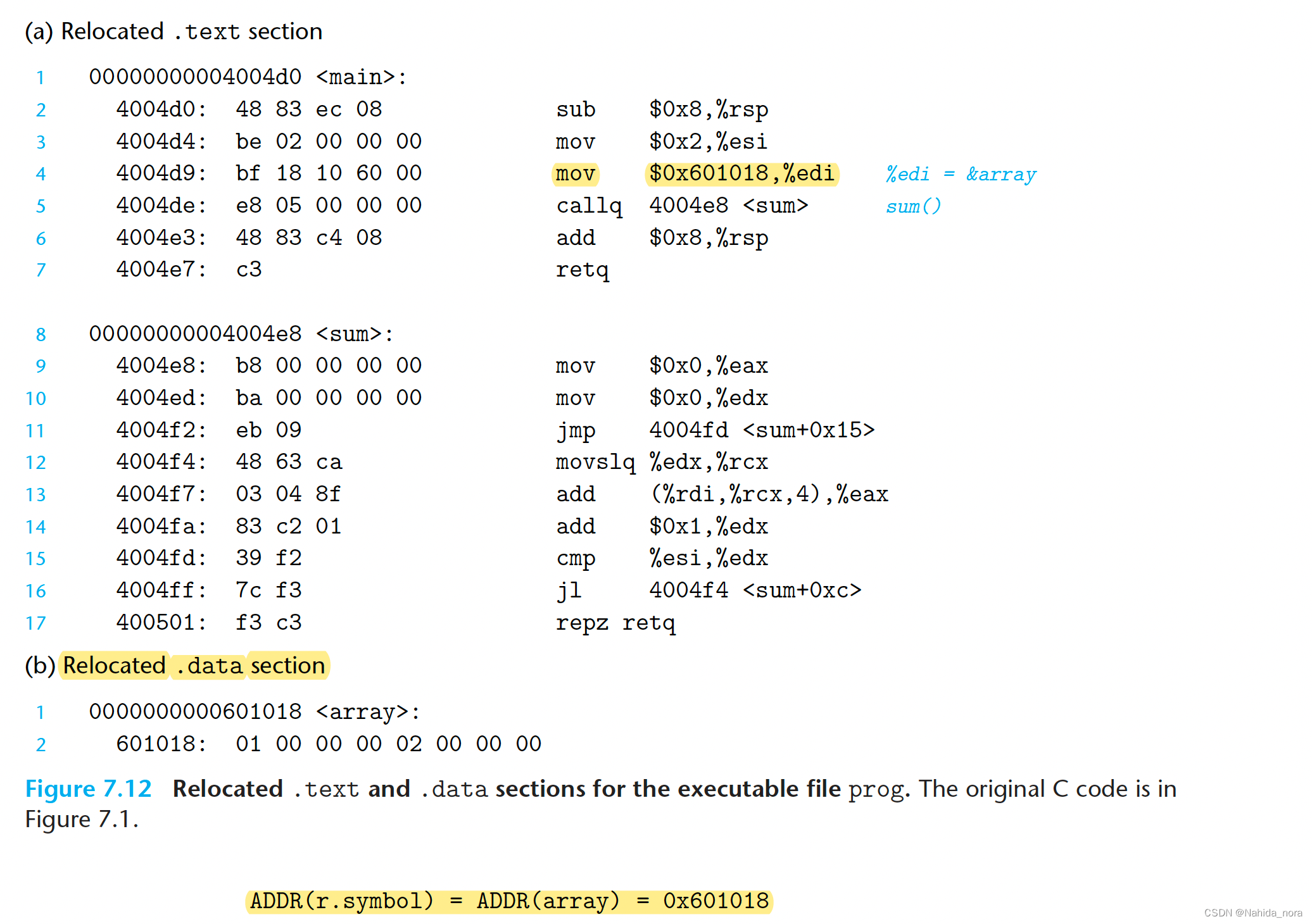
当汇编器生(assembler)成目标模块(object module)时,它不知道代码和数据最终将存储在内存的何处。它也不知道被模块引用的任何外部定义的函数或全局变量的位置。因此,每当汇编器遇到对其最终位置未知的对象的引用时,它都会生成一个重定位条目(relocation entry),告诉链接器在将目标文件合并到可执行文件中时如何修改引用。代码的重定位条目放在 .rel.text 中,数据的重定位条目放在 .rel.data 中。

图 7.9 显示了 ELF 重定位条目的格式。偏移量是需要修改的引用的部分偏移量。符号标识应该指向修改后引用的符号。类型告诉链接器如何修改新的引用。addend是一个有符号常数,由某些类型的重定位使用,用于偏移修改后引用的值。
ELF 定义了 32 种不同的重定位类型,其中许多相当复杂。两种最基本的重定位类型:
-
R_X86_64_PC32:对使用32位PC相对地址的引用进行重定位。PC相对地址是相对于程序计数器(PC)当前运行时值的偏移量。当CPU执行使用PC相对寻址的指令时,它通过将指令中编码的32位值添加到PC的当前运行时值来形成有效地址(例如,调用指令的目标),而PC始终是内存中下一条指令的地址。
-
R_X86_64_32:对使用32位绝对地址的引用进行重定位。使用绝对寻址时,CPU直接使用指令中编码的32位值作为有效地址,无需进一步修改。
这两种重定位类型支持 x86-64 小代码模型,该模型假定可执行对象文件中代码和数据的总大小小于2GB,因此可以在运行时使用32位PC相对地址进行访问。小代码模型是gcc的默认模型。大于2GB的程序可以使用 -mcmodel=medium(中型代码模型)和 -mcmodel=large(大型代码模型)标志进行编译。
绝对寻址和相对寻址
绝对寻址和相对寻址是两种不同的寻址方式,用于确定程序中数据或指令的内存地址。这两种寻址方式在处理器执行指令时的行为有所不同:
-
绝对寻址:
- 在绝对寻址中,指令中直接包含了要访问的内存地址。
- CPU执行该指令时,无需进行其他计算,直接使用指令中的地址作为有效地址。
- 这种方式适用于全局变量、静态数据等在编译时已知位置的情况。
- 例子:
mov eax, [0x12345678],直接将地址0x12345678处的数据加载到寄存器eax。
-
相对寻址:
- 在相对寻址中,指令中包含了一个相对于某个基准地址的偏移量。
- CPU在执行指令时,将该偏移量与某个寄存器或程序计数器(PC)的值相加,以计算出最终的有效地址。
- 这种方式适用于位置在运行时确定的情况,例如函数调用、跳转等。
- 例子:
call 0x1000,将当前程序计数器的值与0x1000相加,实现函数调用。

在上文提到的 x86-64 小代码模型中,采用了相对寻址的方式(R_X86_64_PC32)。在这个模型中,假设可执行对象文件的代码和数据总大小小于2GB,因此可以使用32位PC相对地址进行访问。这有助于减小指令中的地址大小,提高指令的紧凑性。相对寻址的一个优势是,如果整个程序被加载到内存中的不同位置,它仍然可以正确地工作,因为所有地址都是相对于当前位置的偏移量。
Relocating Symbol References


函数加载和函数调用的区别?
函数加载和函数调用是两个不同的概念,涉及到程序的执行和控制流。以下是它们的区别:
-
函数加载(Function Loading):
- 定义: 函数加载是指将函数的机器码或二进制代码从磁盘加载到内存中,使得它可以在程序执行期间被调用。
- 时间点: 函数加载发生在程序启动时或运行时的某个时刻,具体取决于编程语言和执行环境。
- 过程: 操作系统或运行时系统负责将函数的二进制代码加载到内存,并可能进行一些初始化工作。
-
函数调用(Function Invocation):
- 定义: 函数调用是指在程序中的一个地方通过函数名来执行函数的代码块,传递参数并接收返回值。
- 时间点: 函数调用发生在程序执行期间,当程序执行到调用函数的语句时。
- 过程: 程序在执行到函数调用语句时,会跳转到函数的入口地址,执行函数的代码块。调用完成后,程序回到原来的执行点。
简而言之,函数加载发生在程序启动或运行时,涉及将函数的二进制代码加载到内存中。函数调用发生在程序执行期间,通过函数名执行函数的代码块。加载是一次性的,而调用可以在程序执行的不同阶段多次发生。
多次调用main函数,静态全局变量地址会改变吗?
在典型的操作系统环境下,多次调用 main 函数不会导致静态全局变量的地址改变。静态全局变量的地址在程序启动时被分配,并在整个程序的执行过程中保持不变。每次调用 main 函数时,程序都会重新执行,但静态全局变量的地址不会因为这个原因而改变。
一般而言,静态全局变量的地址是在程序加载时确定的,并在整个程序执行期间保持不变。
static 使用
static 关键字在 C 和 C++ 中有不同的用法,它可以用于全局变量和局部变量,分别有不同的含义。
-
全局变量:
- 非静态全局变量(Non-Static Global Variable): 在文件作用域内声明的普通全局变量,默认情况下具有外部链接性(external linkage)。这意味着该变量在整个程序中都是可见的,其他文件也可以访问它。
int globalVar; // 非静态全局变量,默认具有外部链接性- 静态全局变量(Static Global Variable): 使用
static修饰的全局变量具有内部链接性(internal linkage)。这意味着该变量仅在声明它的文件中可见,不能被其他文件访问。
static int staticGlobalVar; // 静态全局变量,具有内部链接性 -
局部变量:
- 非静态局部变量(Non-Static Local Variable): 函数内部声明的普通局部变量。它们在函数执行时创建,在函数执行结束时销毁。每次函数调用都会创建一个新的实例。
void exampleFunction() { int localVar; // 非静态局部变量 }- 静态局部变量(Static Local Variable): 使用
static修饰的局部变量。它们在程序执行过程中只创建一次,而不是每次函数调用。它们在函数调用之间保留其值。
void exampleFunction() { static int staticLocalVar; // 静态局部变量 }
总的来说,static 关键字用于全局变量时可以改变其链接性,而用于局部变量时可以改变其生命周期和初始化行为。
local symbol table 和 symbol table
在 ELF(Executable and Linkable Format)文件中,存在两种主要的符号表,分别是局部符号表(Local Symbol Table)和全局符号表(Global Symbol Table)。这两者之间有一些关键的区别:
-
局部符号表(Local Symbol Table):
- 局部符号表包含了仅在当前目标文件中可见的符号。这些符号通常是在目标文件的编译过程中定义的,对其他目标文件或可执行文件不可见。
- 局部符号表中的符号在链接时用于解析目标文件内的引用,但不会被传递到生成的可执行文件或共享库中。
- 局部符号表中的符号通常是与文件内部的局部变量、局部函数等相关的。
-
全局符号表(Global Symbol Table):
- 全局符号表包含了在整个程序中可见的符号。这些符号可以由其他目标文件引用,并在链接时被解析。
- 全局符号表中的符号通常是与全局变量、全局函数、外部库等相关的。
- 全局符号表中的符号在链接过程中会被传递到生成的可执行文件或共享库中,以供其他模块使用。
GCC 编译器生成的可执行文件或目标文件包含符号表信息,您可以使用一些工具来查看这些信息。以下是一些常用的工具及其用法:
-
readelf:
readelf是一个用于显示 ELF 格式文件信息的工具。可以使用以下命令查看局部符号表和全局符号表:# 显示局部符号表 readelf -s --section=.symtab your_executable # 显示全局符号表 readelf -s --section=.dynsym your_executable其中,
your_executable是您的可执行文件或目标文件的名称。这里使用-s选项来显示符号表信息,而--section=.symtab和--section=.dynsym用于指定显示的符号表。
assembler (as)介绍
as 是GNU Assembler的命令行工具,用于将汇编语言源代码转换为机器码或目标文件。GNU Assembler是GCC套件的一部分,负责处理汇编语言,生成可执行文件或目标文件。
以下是 as 的一些主要特性和功能:
-
汇编语言支持:
as支持多种体系结构的汇编语言,包括x86、ARM、MIPS等。用户可以使用不同的指令集和语法来编写汇编代码,具体取决于目标体系结构。 -
目标文件生成:
as的主要任务是将汇编代码翻译成目标文件,这些文件包含了机器码或可重定位代码。目标文件通常用于链接,以生成最终的可执行文件。 -
符号表和重定位信息:生成的目标文件包含符号表和重定位信息,这些信息用于在链接阶段解析符号引用和执行地址重定位。这是为了确保在链接时可以正确地将多个目标文件组合在一起。
-
宏汇编:
as支持宏汇编,允许程序员使用宏指令来简化和抽象汇编代码。这提高了代码的可读性和维护性。 -
交叉编译:
as可以用于交叉编译,即在一个系统上生成另一个体系结构的目标文件。这对于嵌入式系统和跨平台开发非常有用。 -
可选的优化:
as允许应用一些基本的汇编优化,如指令调度和指令选择。然而,更复杂的优化通常由后续的编译器阶段处理。
使用 as 的基本语法如下:
as source_file.s -o output_file.o
这会将 source_file.s 中的汇编代码汇编成一个目标文件 output_file.o。通常,as 的使用是由GCC自动完成的,用户更多地使用高级语言编写代码,而编译器会负责调用适当的汇编器和链接器。
C compiler (cc1) 介绍
cc1 不是一个特定的C编译器,而是GNU Compiler Collection(GCC)中的一个组件,用于处理C语言的前端编译。GCC是一个包含多个编程语言支持的强大编译器套件,cc1 是其中之一。
以下是 cc1 的主要功能和一般性介绍:
-
前端编译器:
cc1是GCC的前端编译器,负责将C源代码转换为汇编代码。前端编译器主要涉及词法分析、语法分析、语义分析等步骤,以便生成中间表示形式(如树状表示或中间代码)。 -
语言特性支持:
cc1支持C语言的标准,如C89、C99、C11等,同时也支持一些GNU扩展和特性,使得GCC可以处理更广泛的C代码。 -
优化:虽然
cc1主要负责将源代码转换为中间表示形式,但它也会应用一些基本的优化,以改善生成的汇编代码的性能。这些优化是前端编译阶段的一部分,而更复杂的优化通常在后端编译器中进行。 -
目标无关性:
cc1在处理前端编译时是目标无关的,这意味着它不关心最终代码将在哪种体系结构上运行。目标相关的信息将在后续的编译阶段由GCC的后端组件处理。 -
插件支持:
cc1支持插件机制,允许用户扩展和定制编译过程。通过插件,用户可以添加新的优化、分析工具或其他定制功能。
请注意,通常情况下,开发者直接使用GCC命令行工具,而不是直接调用 cc1。GCC会自动调用 cc1 以及其他相关的编译器组件,使得编译过程更加方便。例如,使用命令 gcc -c file.c 会调用 cc1 生成目标文件。
C preprocessor 介绍
C预处理器(C Preprocessor)是C语言编译过程中的一个重要组件,它在实际编译之前对源代码进行预处理。预处理器负责执行一系列预处理步骤,包括宏替换、文件包含、条件编译等,以生成最终的源代码供编译器处理。
以下是C预处理器的一些关键功能和特性:
-
宏替换(Macro Replacement):预处理器支持宏定义,允许程序员创建自定义的宏,以便在代码中进行简化和重用。这些宏在预处理阶段会被相应的代码片段替换。
#define MAX(x, y) ((x) > (y) ? (x) : (y)) int result = MAX(10, 5); // 在预处理阶段替换为:int result = ((10) > (5) ? (10) : (5)); -
文件包含(File Inclusion):预处理器允许通过
#include指令将一个文件的内容嵌入到另一个文件中。这是为了实现模块化和代码重用。#include <stdio.h> -
条件编译(Conditional Compilation):通过
#if、#ifdef、#ifndef、#else和#endif等指令,预处理器可以根据条件编译不同的代码块,这对于实现跨平台代码和调试时的条件性编译非常有用。#ifdef DEBUG printf("Debug mode is enabled\n"); #endif -
注释删除(Comment Removal):预处理器会删除源代码中的注释,以便在后续的编译阶段中不包含注释信息。
// 这是一条注释 -
符号常量定义(Symbolic Constants):使用
#define指令可以定义符号常量,这些常量在源代码中被用作标识符,提高了代码的可读性和维护性。#define PI 3.14159
总体而言,C预处理器通过执行这些预处理步骤,使得源代码在进入编译器之前经过了一系列的转换和替换,为编译器提供了更加适合处理的源代码。
ELF-64 介绍
ELF(Executable and Linkable Format)是一种用于可执行文件、目标文件和共享库的文件格式。ELF 文件格式支持多种架构,其中 ELF-64 是针对 64 位体系结构的一种特定变体。
以下是 ELF-64 文件格式的一些关键特点:
-
体系结构: ELF-64 适用于 64 位系统架构,如 x86_64。
-
文件头(ELF Header): 包含了关于文件的基本信息,如文件类型、入口点地址、段表头和节表头等。
-
节表(Section Table): 包含了程序的各个节(sections)的信息,例如代码段、数据段、符号表、字符串表等。每个节都有一个唯一的标识符和相关的信息。
-
段表(Program Header Table): 描述了在运行时如何加载文件到内存的信息,包括各个段的起始地址、文件中的偏移量等。
-
重定位表(Relocation Table): 包含了需要在加载时进行地址重定位的信息,确保程序能够正确地在内存中执行。
-
符号表(Symbol Table): 包含了程序中使用的符号(如变量、函数等)的信息,以及它们在内存中的地址。
-
动态链接信息: 包含了共享库的信息,以及在运行时由动态链接器解析的相关信息。
-
程序入口点: 指示程序执行的起始点,即程序开始执行的地址。
ELF-64 文件格式具有良好的灵活性和可扩展性,支持先进的特性,如动态链接和共享库,使得它在现代操作系统中被广泛使用。这种格式的设计旨在满足不同类型的应用程序和系统需求,同时提供了足够的结构来支持可执行文件和共享库之间的交互。
objdump 和 readelf指令例子
objdump -dx TestLink.o
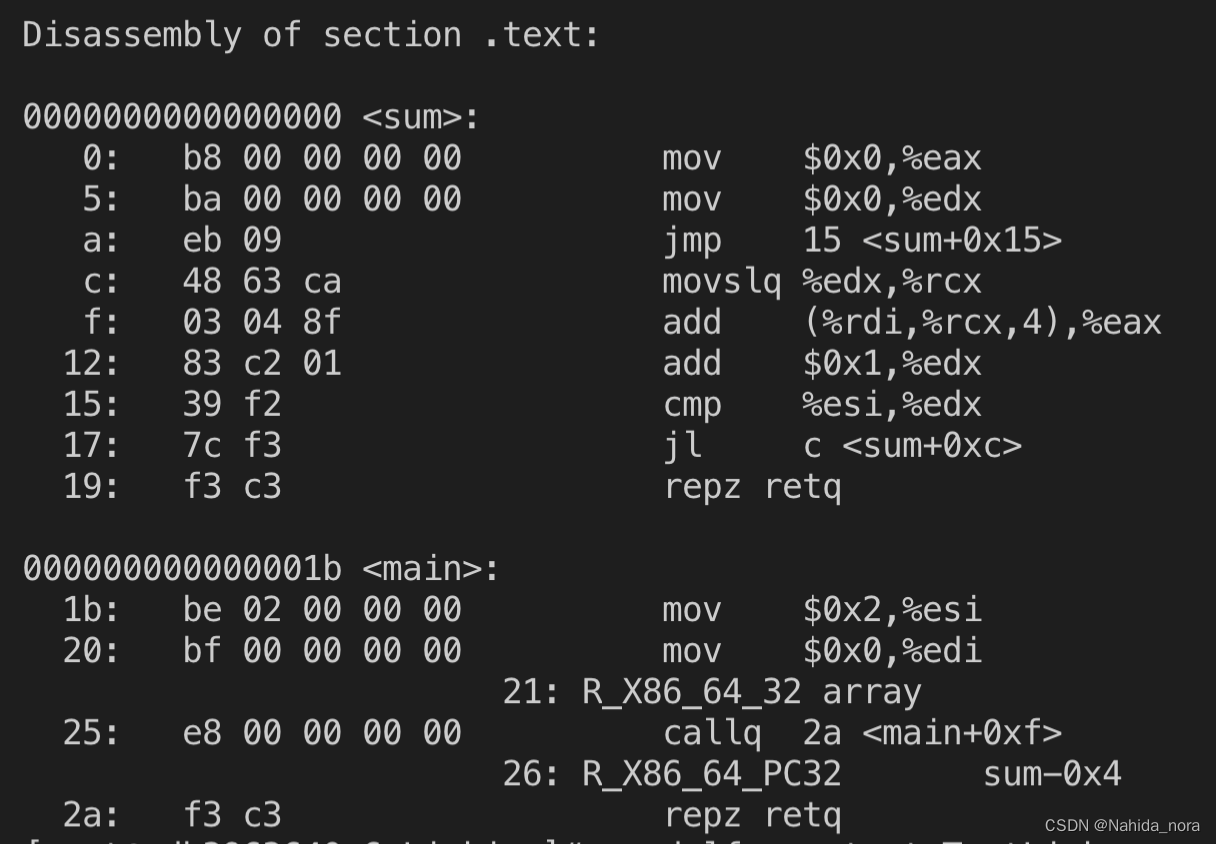
readelf -x .text TestLink.o


readelf打印的是重定向的text的虚拟地址。
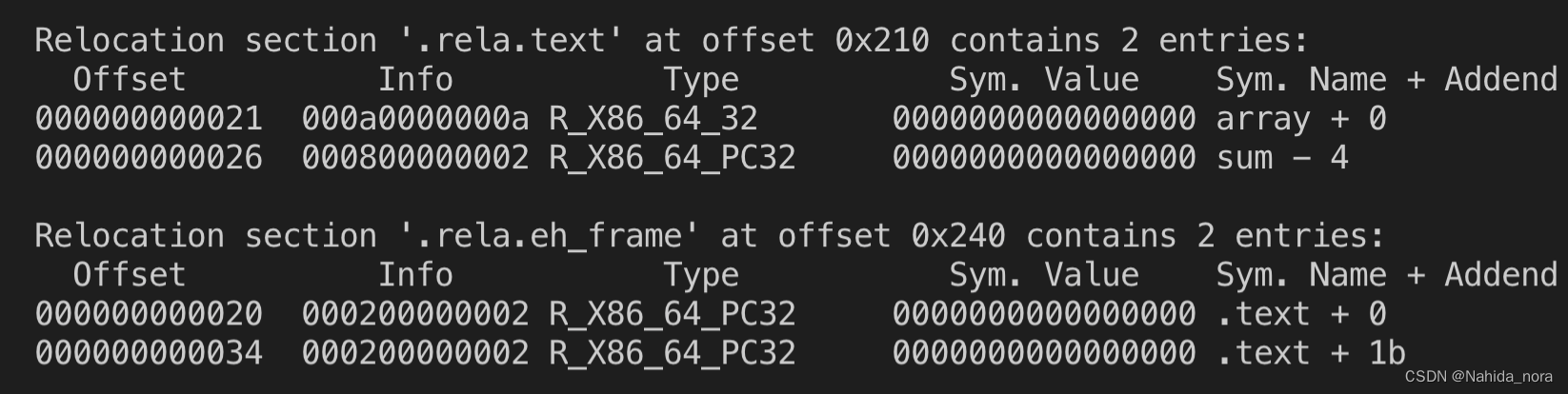
offset (0x21) 对应汇编代码的 21: R_X86_64_32 array 。
000000000000001b <main>:
1b: be 02 00 00 00 mov $0x2,%esi
20: bf 00 00 00 00 mov $0x0,%edi
21: R_X86_64_32 array
25: e8 00 00 00 00 callq 2a <main+0xf>
26: R_X86_64_PC32 sum-0x4
2a: f3 c3 repz retq
readelf打印的是data的虚拟地址。

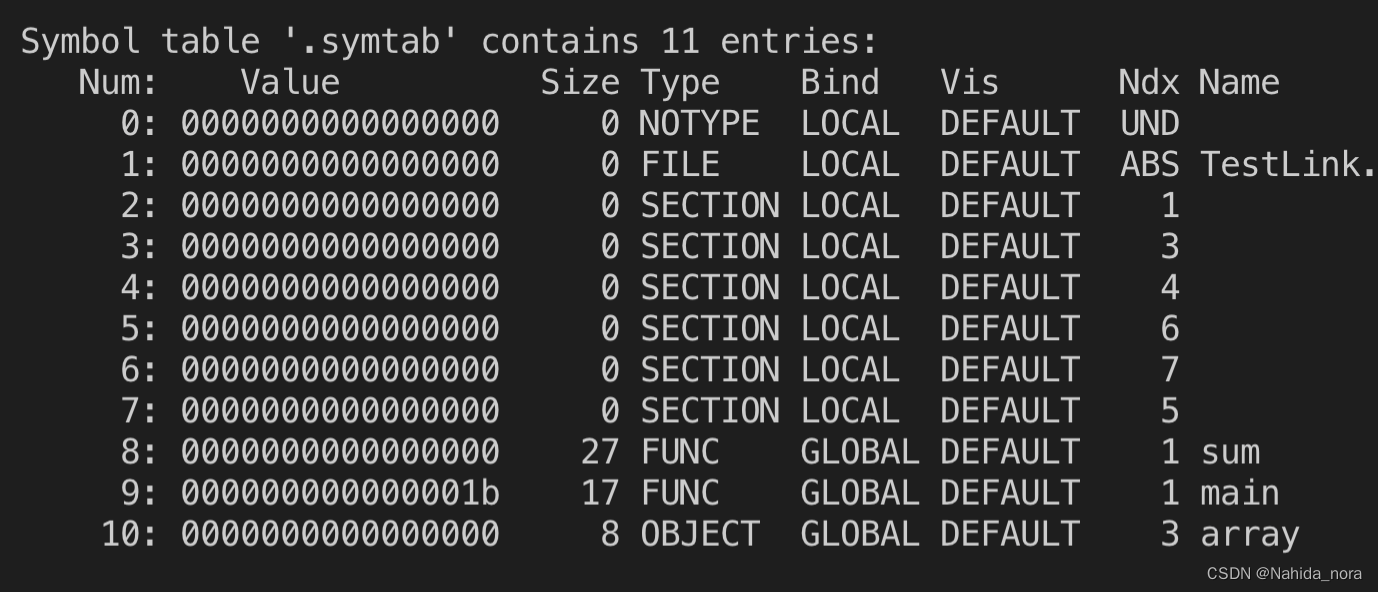
readelf打印符号表。
R_X86_64_PC32和R_X86_64_PLT32
R_X86_64_PC32 和 R_X86_64_PLT32 是 x86_64 架构中用于表示重定位(relocation)类型的两种不同类型。
-
R_X86_64_PC32:- 全称: Relocation Type x86_64 Program Counter Relative, 32-bit.
- 作用: 表示与程序计数器(PC)相关的32位重定位。
- 描述: 当一个程序在执行时,经常需要在运行时进行地址解析和重定位。
R_X86_64_PC32类型的重定位用于指定一个32位相对地址,该地址是相对于指令的下一个指令的地址(即相对于程序计数器)的偏移量。
-
R_X86_64_PLT32:- 全称: Relocation Type x86_64 32-bit PLT Address.
- 作用: 用于处理过程链接表(Procedure Linkage Table,PLT)的32位地址重定位。
- 描述: PLT 是在动态链接时用于解析函数调用地址的一种机制。
R_X86_64_PLT32用于指定32位相对地址,该地址是相对于 PLT 中相应条目的地址的偏移量。这种重定位类型通常与动态链接器一起使用,以确保在运行时正确解析函数调用。
这两种重定位类型都是在链接时或运行时用于修正地址的一种机制,以适应目标文件或可执行文件的加载和执行环境。在编译和链接过程中,这些重定位信息会被写入目标文件,而在运行时,动态链接器会根据这些信息来进行符号解析和地址重定位,确保程序能够正确执行。
readelf 指令
readelf 是一个用于读取 ELF(Executable and Linkable Format)文件信息的命令行工具。ELF 是一种用于可执行文件、共享库和核心转储文件的标准文件格式。以下是一些 readelf 命令的用法示例:
-
查看 ELF 文件头信息:
readelf -h executable_file这个命令用于显示 ELF 文件的头部信息,包括文件类型、架构、入口地址等。
-
查看节表信息:
readelf -S executable_file该命令用于显示 ELF 文件的节表信息,包括每个节的名称、地址、大小等。
-
查看程序头表信息:
readelf -l executable_file该命令用于显示 ELF 文件的程序头表信息,包括段的类型、偏移、虚拟地址等。
-
查看符号表信息:
readelf -s executable_file该命令用于显示 ELF 文件的符号表信息,包括符号的地址、大小、类型等。
-
显示动态节信息:
readelf -d executable_file
该命令用于显示 ELF 文件的动态节信息,包括动态链接库的名称、重定位入口等。

gcc 问题
gcc 执行失败:
attempt to open /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../libc.a failed
attempt to open //usr/x86_64-redhat-linux/lib64/libc.a failed
attempt to open //usr/lib64/libc.a failed
attempt to open //usr/local/lib64/libc.a failed
attempt to open //lib64/libc.a failed
attempt to open //usr/x86_64-redhat-linux/lib/libc.a failed
attempt to open //usr/local/lib/libc.a failed
attempt to open //lib/libc.a failed
执行:
yum install glibc-static















 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









