









NVIDIA Intern Hiring Test
Deep Learning Software Intern/Deep Learning Performance Architect Intern/GPU
给大家放上笔试网址 HackerRank.(感觉有点海笔)
样题
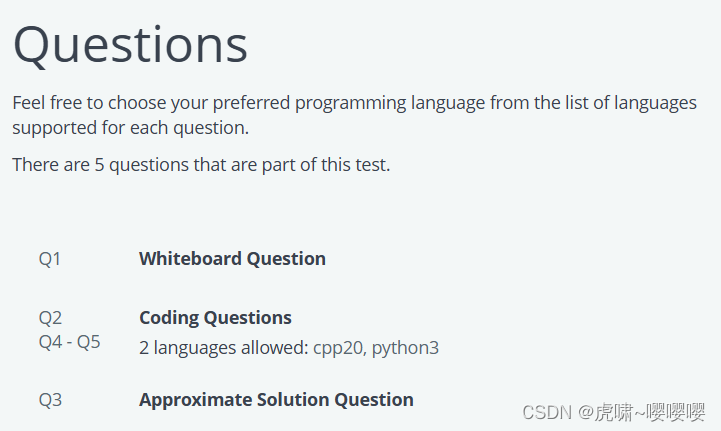
Sample test 1
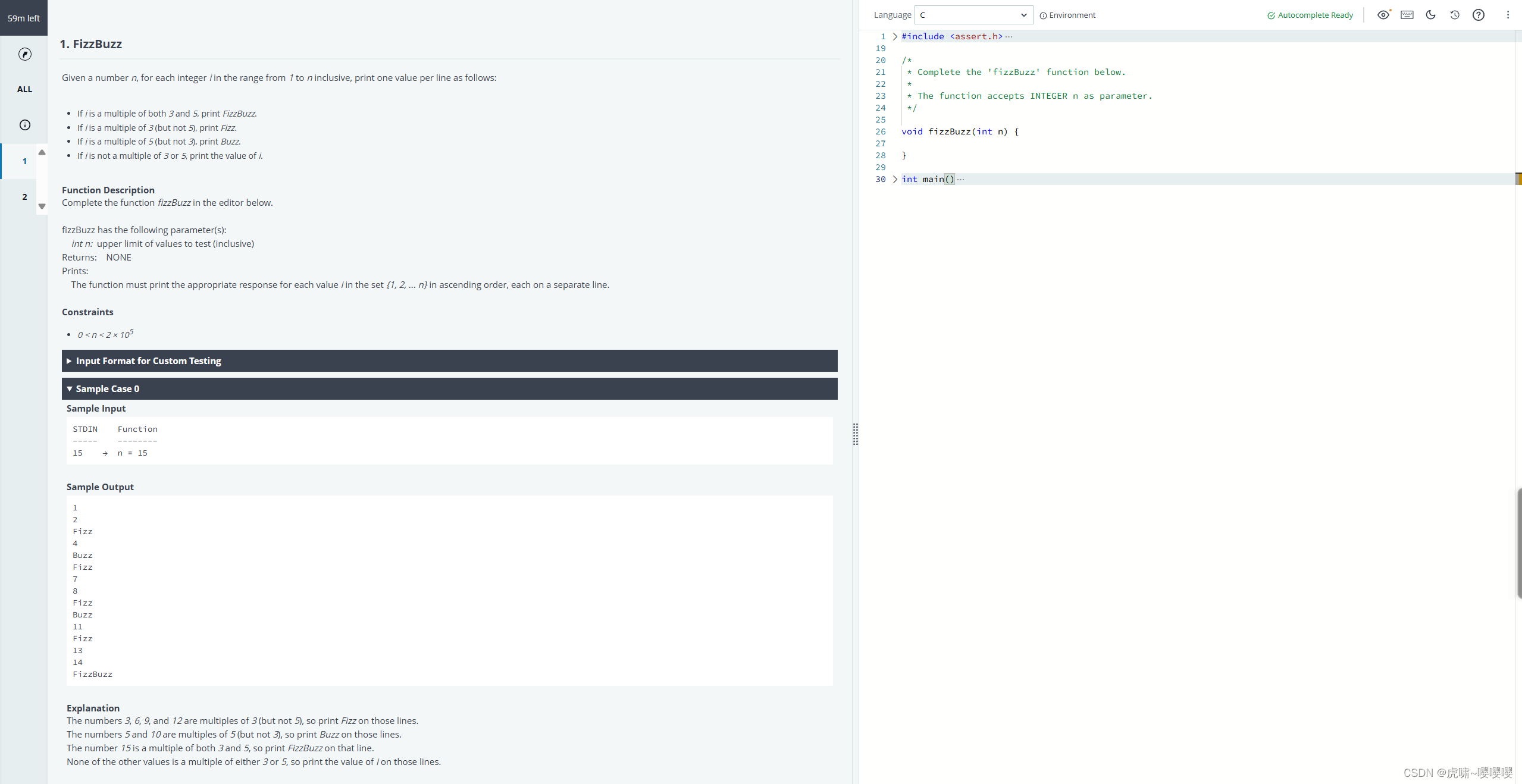
Sample test 2
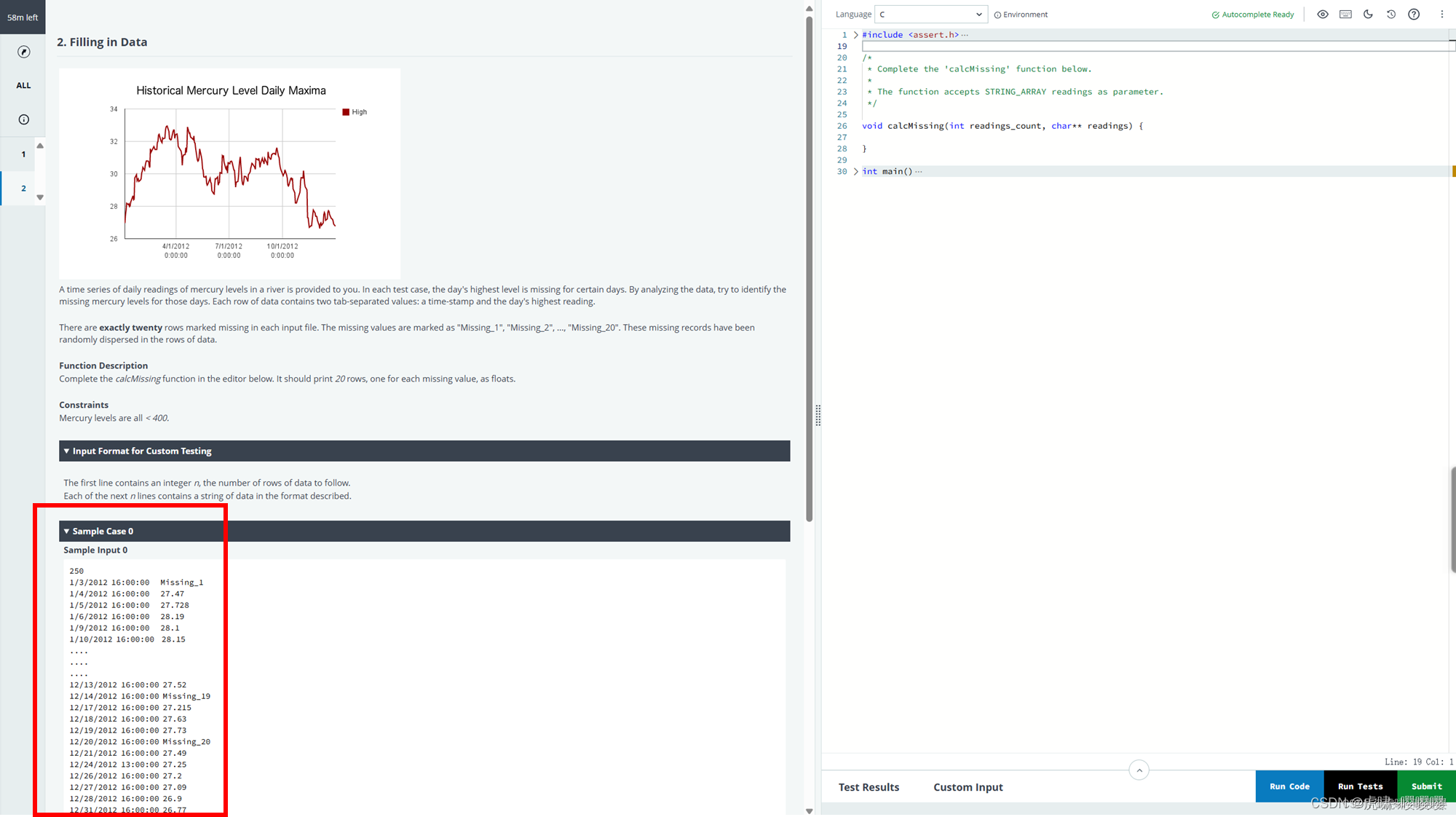
Sample Case 0 细节如下:
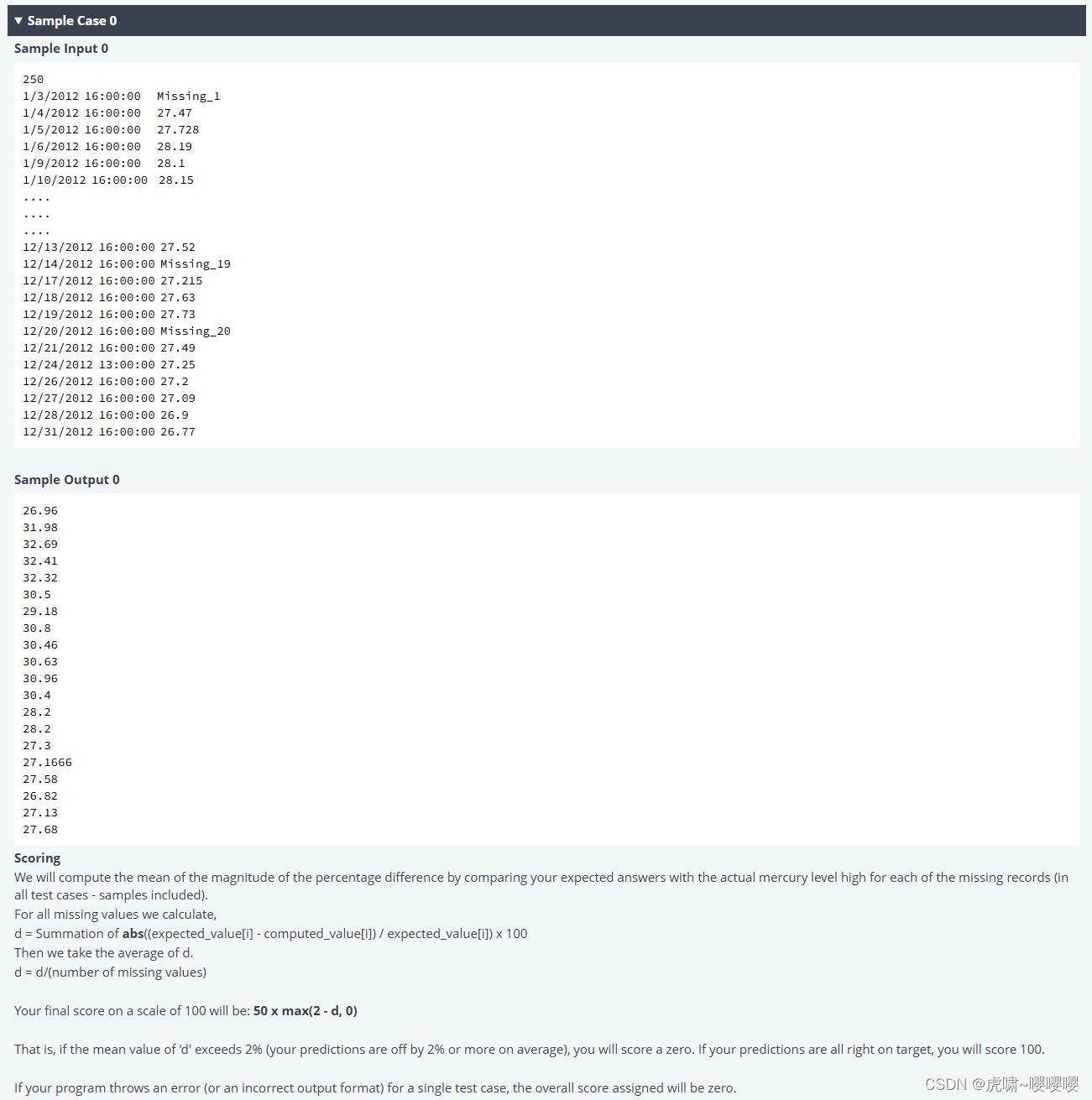
关于第二题需要注意的是,如果代码没有跑通是0分。
样题解析及参考答案
Sample test 1
Leetcode简单题原题Fizz Buzz,不细嗦了。
Sample test 2
题目描述
给定一个时间序列数据,包含每天河流中汞含量的读数。在每个测试用例中,某些天的最高汞含量是缺失的。通过分析这些数据,需要识别那些天的缺失值。
每行数据包含两个用制表符分隔的值:时间戳和当天的最高读数。
输入数据中恰好有二十行标记为缺失。缺失值的标记格式为 “Missing_1”, “Missing_2”, …, “Missing_20”。这些缺失记录在数据行中是随机分布的。
功能描述
需要完成 calcMissing 函数,在编辑器中实现。该函数应打印20行,每行一个缺失值,用浮点数表示。
约束
汞含量值均小于400。
输入格式(自定义测试)
第一行包含一个整数 n,表示数据行数。
接下来的 n 行每行包含一个时间戳和一个当天的最高读数,格式为 “时间戳\t最高读数”。
#include <assert.h>
#include <ctype.h>
#include <limits.h>
#include <math.h>
#include <stdbool.h>
#include <stddef.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char* readline();
char* ltrim(char*);
char* rtrim(char*);
int parse_int(char*);
double linearInterpolate(double x0, double y0, double x1, double y1, double x) {
return y0 + (x - x0) * (y1 - y0) / (x1 - x0);
}
/*
* Complete the 'calcMissing' function below.
*
* The function accepts STRING_ARRAY readings as parameter.
*/
void calcMissing(int readings_count, char** readings) {
// 存储已知值和缺失值的索引
int missingIndices[20]; // 假设最多有20个缺失值
int missingCount = 0;
int knownCount = 0;
int knownIndices[readings_count];
double knownValues[readings_count];
for (int i = 0; i < readings_count; i++) {
char* value = strchr(readings[i], '\t') + 1; // 跳过时间戳,读取值
if (strstr(value, "Missing") != NULL) {
missingIndices[missingCount++] = i;
}
else {
knownIndices[knownCount] = i;
knownValues[knownCount++] = atof(value);
}
}
// 对每个缺失值进行线性插值
for (int i = 0; i < missingCount; i++) {
int idx = missingIndices[i];
// 寻找左右的已知值
int leftIdx = -1, rightIdx = -1;
double leftValue = 0, rightValue = 0;
for (int j = 0; j < knownCount; j++) {
if (knownIndices[j] < idx) {
leftIdx = knownIndices[j];
leftValue = knownValues[j];
}
else if (knownIndices[j] > idx && rightIdx == -1) {
rightIdx = knownIndices[j];
rightValue = knownValues[j];
break;
}
}
// 如果找到了左右的已知值,则进行插值
if (leftIdx != -1 && rightIdx != -1) {
double interpolatedValue = linearInterpolate(leftIdx, leftValue, rightIdx, rightValue, idx);
printf("%.2f\n", interpolatedValue);
}
else if (leftIdx == -1) { //缺失值没有左值,取最近值
//fprintf(stderr, "Error: Could not find sufficient known values for interpolation.\n");
int i = 0;
while (!knownIndices[i])
i++;
printf("%.2f\n", knownValues[i]);
}
else if (rightIdx == -1) { //缺失值没有右值,取最近值
int j = knownCount - 1;
while (!knownIndices[j])
i++;
printf("%.2f\n", knownValues[j]);
}
}
}
//主函数大致理解就好,只用写功能函数。
int main()
{
int readings_count = parse_int(ltrim(rtrim(readline())));
char** readings = malloc(readings_count * sizeof(char*));
for (int i = 0; i < readings_count; i++) {
char* readings_item = readline();
*(readings + i) = readings_item;
}
calcMissing(readings_count, readings);
return 0;
}
char* readline() {
size_t alloc_length = 1024;
size_t data_length = 0;
char* data = malloc(alloc_length);
while (true) {
char* cursor = data + data_length;
char* line = fgets(cursor, alloc_length - data_length, stdin);
if (!line) {
break;
}
data_length += strlen(cursor);
if (data_length < alloc_length - 1 || data[data_length - 1] == '\n') {
break;
}
alloc_length <<= 1;
data = realloc(data, alloc_length);
if (!data) {
data = '\0';
break;
}
}
if (data[data_length - 1] == '\n') {
data[data_length - 1] = '\0';
data = realloc(data, data_length);
if (!data) {
data = '\0';
}
}
else {
data = realloc(data, data_length + 1);
if (!data) {
data = '\0';
}
else {
data[data_length] = '\0';
}
}
return data;
}
char* ltrim(char* str) {
if (!str) {
return '\0';
}
if (!*str) {
return str;
}
while (*str != '\0' && isspace(*str)) {
str++;
}
return str;
}
char* rtrim(char* str) {
if (!str) {
return '\0';
}
if (!*str) {
return str;
}
char* end = str + strlen(str) - 1;
while (end >= str && isspace(*end)) {
end--;
}
*(end + 1) = '\0';
return str;
}
int parse_int(char* str) {
char* endptr;
int value = strtol(str, &endptr, 10);
if (endptr == str || *endptr != '\0') {
exit(EXIT_FAILURE);
}
return value;
}
代码中的strstr()函数的底层实现也是一道LeetCode简单题找出字符串中第一个匹配项的下标.
strstr(value, "Missing") != NULL
用到的是KMP算法,感兴趣的可以去刷一下,常跟匈牙利算法放在一起进行区分。关于对匈牙利算法的应用,最近做到的是素数伴侣,也是懒懒散散刷题以来,做的第一道困难级别的题,希望可以坚持刷题坚持记录。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









