







文章地址:https://arxiv.org/pdf/2307.15290.pdf
注意:本文使用的是Baichuan13B和Baichuan13B-chat,其他模型结果可能有变化。
(1)预训练数据来源、处理
专业领域
国家标准、领域书籍、领域网页(30000)
通用领域
悟道数据集提取文章
处理方式
文本提取(丢弃了图片、url和表格)、质量过滤(敏感词过滤、语言过滤和有效的文本长度过滤)、重复数据消除(在文章和句子级别上消除重复,最大限度地减少了重复数据对模型训练的影响)。领域语料库有2660w token,通用语料库有27660w token。
(2)微调数据生成方式,附录里面有生成的prompt
25000条专业领域指令数据
单轮对话:根据给定知识,GPT4生成。
多轮对话:根据给定文章,GPT4生成。
生成方式:如下图所示

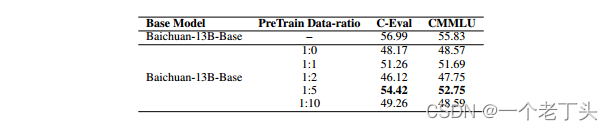
(3)预训练和微调阶段专业领域数据与通用领域数据不同比例对模型通用能力以及专业能力的影响
预训练阶段
1:5比例最佳。
sft阶段
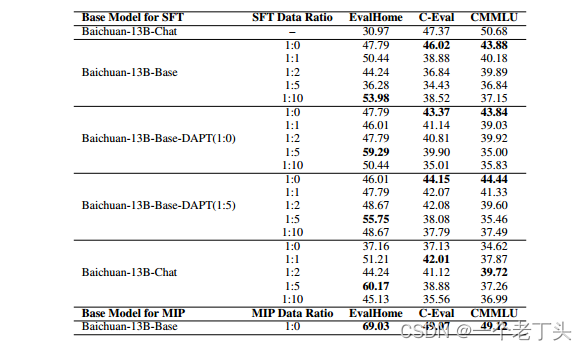
25000条专业sft数据,SFT的通用语料则从 Alpaca_gpt4_data_zh和Belle进行随机采样而得。
-
在领域内测试集上的表现,经过SFT之后相比于不进行SFT效果更佳。
-
在SFT阶段,随着通用语料的增加,在通用测试集上的表现是更差的,也就是模型的通用能力遗忘得更多。
-
相比于领域内预训练,直接对Chat模型进行SFT,在家装测试集上表现是最佳的(这个可能因为通用模型训练时候已经有大量相关数据)。
-
在本项目中,1:5的比例混合,在家居测试集上的表现是最佳的。
-
预训练阶段,混合预训练数据和指令微调数据进行训练,通用能力和领域能力都达到最佳
(4)MIP预训练策略
MIP(Multi-Task Instruction Pretraining),将领域内预训练语料和领域内instruction tuning语料混合直接对Baichuan-13B-Base进行训练。结果中显示,这种方法相比于其他的方法,在领域内测试集和通用测试集效果是最好的。
(5)专业领域测试集EvalHome的生成(论文附录有样例)















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









