






论文名称:Adaptive Loss-aware Quantization for Multi-bit Networks
会议&年份:2020 CVPR
背景:
网络中各层对量化粒度的敏感程度是不同的。那么假设给予的总的bit数不变的基础上,分别给对量化更敏感的层更多的bit数,较不敏感的层更少的bit数,从而达到更好的精度。
主要方法:
将权重和激活值都量化,并提出一种多比特网络上的,自适应的,最小化loss的量化模型方法(ALQ)
(1)压缩方法:
把权重和激活值量化到二进制基上——MBN
(2)量化方法:ALQ
过去的量化方法:
预先确定全局位宽,再学习出一个量化器,将全精度参数转换为二进制基和坐标。
但是缺点在于:
- 实际上不同层会有不同的最优位宽
- 训练一个量化器并通过最小化重建误差,尽量还原全精度的模型,这种间接的优化方式可能导致精度损失,而且还依赖近似的梯度
- 其实之前的方法都没有量化第一层和最后一层,而且通常这两层计算量很大
而本文的ALQ量化方法是:
- 自适应位宽,也就是根据每层参数的重要性,重要的获得更多的位宽
- 最小化模型误差,即最小化模型的损失函数来保持推理精度,直接优化
- 把第一层和最后一层也量化了
实现的方法是:
(1)权重量化
将权重用二进制基+坐标的形式表达。
-
对每层的权重,每轮删去不重要的权重(变成0),删去的权重会影响二进制基的数量,进而影响本层的位宽,这样就能让重要的权重拥有更多的位宽。
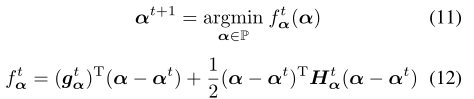
-
重新训练上一步剩余下来的二进制基和坐标来恢复精度,优化方法为AMSGrad法,优化目标为loss,这样能实现平滑的减少基向量的个数。
(2)激活值量化
输入某一层之前,将上一层的feature map激活成{−1,+1},以实现按位操作来加速
比如,对某个输出x,量化结果是: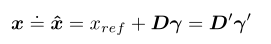
x r e f x_{ref} xref是一个正的浮点数,是引入的,与层有关的,会适应relu输出范围的参数,也会与下一层的权重进行卷积。
γ \gamma γ和 x r e f x_{ref} xref都会在前向传播中更新。
效果:
在VGG/CIFAR10上,与别的量化方法相比,IW表示平均每个参数的bit数















 1204
1204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









