







ByteBuffer 一个重要的类
在 java 的 NIO 当中,有一个很重要的类,就是 ByteBuffer 。
- NIO 是什么?
Java NIO(New Input/Output)是一种提供了基于缓冲区的高效、可扩展的 I/O 操作方式的 API。与传统的基于流的 I/O 不同,Java NIO 以缓冲区为中心,通过使用通道(Channel)和选择器(Selector)等组件来实现 I/O 操作。
Java NIO 主要由以下三个核心组件组成:- 缓冲区(Buffer):缓冲区是一个数组,用于存储数据。Java NIO 中的所有 I/O 操作都是通过缓冲区来实现的。常见的缓冲区类型包括 ByteBuffer、CharBuffer、IntBuffer 等。
- 通道(Channel):通道类似于流,但是通道可以双向传输数据。与传统的流不同,通道可以直接读写缓冲区数据,而不需要通过中间缓冲区进行传输。Java NIO 提供了多种类型的通道,包括文件通道、网络通道等。
- 选择器(Selector):选择器用于监听多个通道的事件,可以实现非阻塞 I/O 操作。在一个线程中,可以使用一个选择器监听多个通道,当某个通道有数据准备就绪时,选择器会通知相应的线程进行处理。
Java NIO 可以提高系统的性能,尤其是在需要同时处理多个连接或者大量数据的情况下。在 Java 中,Socket 通信默认使用的是阻塞式 I/O,而 Java NIO 可以通过使用缓冲区、通道和选择器等组件来实现非阻塞式 I/O 操作,提高了系统的并发处理能力和吞吐量。
我们具体分析一下 NIO 组件之一 Buffer 中的代表类 ByteBuffer 。
ByteBuffer 类的重要组成:
public abstract class ByteBuffer
extends Buffer
implements Comparable<ByteBuffer>
- 它是一个抽象类,具体功能由子类实现。
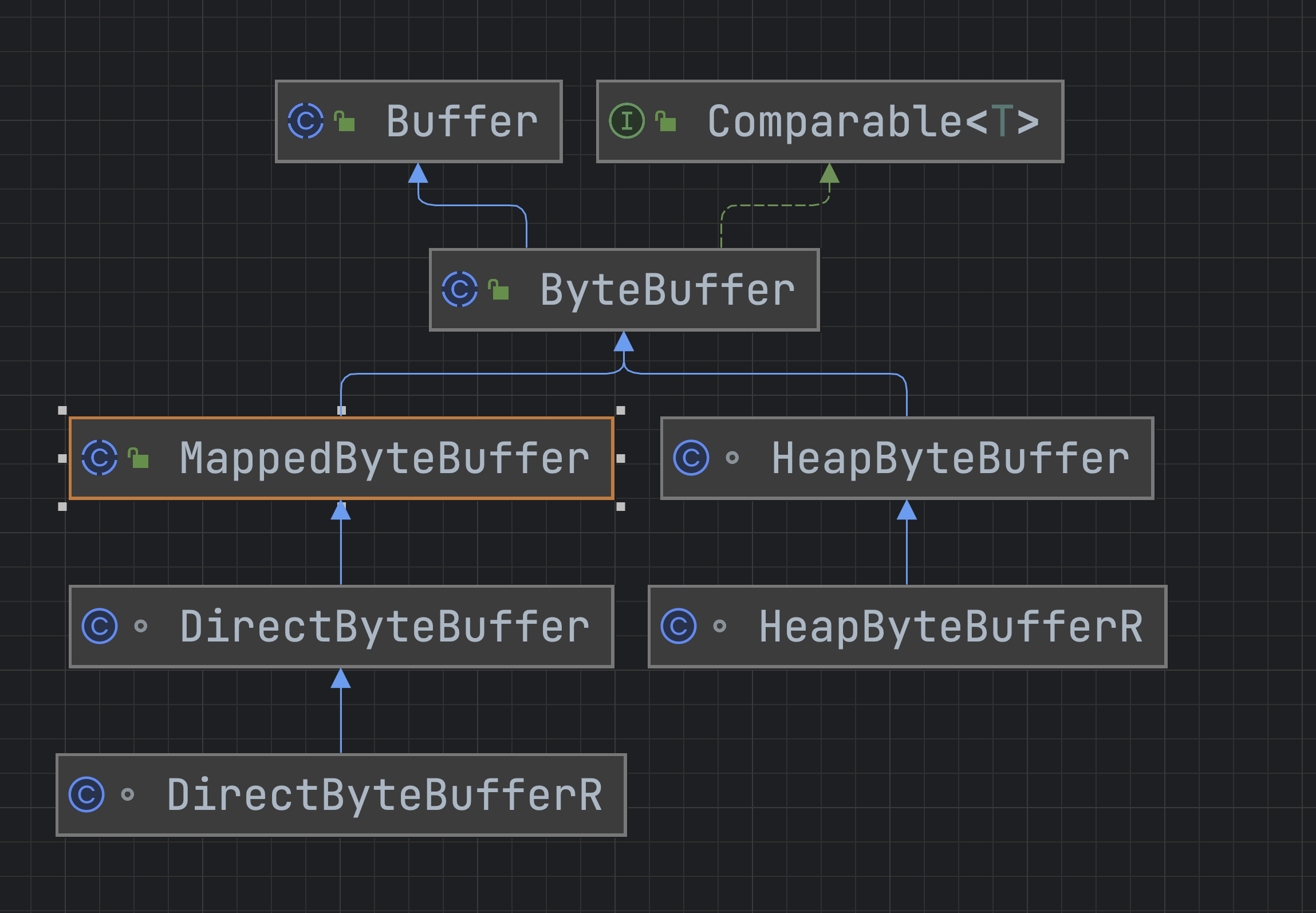
- HeapByteBuffer 是 Java NIO 中 ByteBuffer 类的一种实现,它表示在 Java 堆内存中分配的字节缓冲区。与直接缓冲区(DirectByteBuffer)相比,HeapByteBuffer 的内存分配和回收相对较为简单,且适用于小数据量的读写操作。
2. HeapByteBufferR 是 Java NIO 中 ByteBuffer 类的一种只读实现,它表示在 Java 堆内存中分配的只读字节缓冲区。与 HeapByteBuffer 相比,HeapByteBufferR 只能进行读取操作,无法进行写入操作,但相对地,它可以提供更高的性能和更低的内存占用。通常情况下,HeapByteBufferR 会作为 HeapByteBuffer 的视图(view)而存在,用于实现只读缓冲区的功能。
3. MappedByteBuffer可以将文件中的一部分区域(或整个文件)映射到内存中,以便直接读写文件数据。使用 MappedByteBuffer 可以提高文件 I/O 操作的效率,特别是对于大文件的读写操作。它常常被用于实现高性能的文件传输和数据处理,例如在内存映射文件中搜索和替换文本。
4. DirectByteBuffer 是 Java NIO 中 ByteBuffer 类的一种实现,它表示直接缓冲区,即在操作系统内存中分配的字节缓冲区,而不是在 Java 堆内存中分配。与 HeapByteBuffer 相比,DirectByteBuffer 的内存分配和回收相对较为复杂,但是它可以提供更高的读写性能,特别是对于大数据量的读写操作。通常情况下,DirectByteBuffer 会作为 HeapByteBuffer 的替代方案而存在,用于实现高性能的数据处理和传输。
5. DirectByteBufferR 类,它是 DirectByteBuffer 类的只读版本。与 DirectByteBuffer 类似,DirectByteBufferR 表示在堆外内存中分配的只读字节缓冲区。
-
父类 Buffer 中有几个重要的字段解释:
Buffer 类的 mark、position、limit、capacity 是缓冲区的四个重要属性,表示缓冲区的状态和容量。- capacity:表示缓冲区的容量,即缓冲区能够存储的最大字节数。capacity 一旦被初始化就不能改变。
- limit:表示缓冲区的限制,即缓冲区中数据的有效长度。limit 的初始值等于 capacity。
- position:表示缓冲区的位置,即下一个要读取或写入的数据的位置。position 的初始值为 0。
- mark:表示当前 position 的备忘位置,即标记当前 position 的位置。
这四个属性的值通常是通过 Buffer 对象的方法进行设置和获取的。下面是这四个属性的一些常用方法: - capacity():获取缓冲区的容量。
- limit() 和 limit(int newLimit):获取或设置缓冲区的限制。如果 newLimit 大于 capacity,则抛出 IllegalArgumentException 异常。
- position() 和 position(int newPosition):获取或设置缓冲区的位置。如果 newPosition 大于 limit,则抛出 IllegalArgumentException 异常。
- mark() 和 reset():标记当前 position 的位置,或将 position 的值重置为 mark 的值。
- clear():清空缓冲区,将 position 设为 0,limit 设为 capacity。
- flip():反转缓冲区,将 limit 设为当前 position,将 position 设为 0。用于准备从缓冲区中读取数据。
- rewind():将 position 设为 0,不改变 limit 的值。用于重新读取缓冲区中的数据。
- hasRemaining() 和 remaining():判断缓冲区中是否还有未读取或未写入的数据,以及返回剩余未读取或未写入的数据长度。
这些属性和方法使得 Buffer 类可以方便地实现读写操作,并在读写数据时自动调整缓冲区的状态。在实际应用中,可以通过合理地设置和获取这些属性,来实现对缓冲区中数据的高效处理。
-
可以进行比较大小
public int compareTo(ByteBuffer that) { int n = this.position() + Math.min(this.remaining(), that.remaining()); for (int i = this.position(), j = that.position(); i < n; i++, j++) { int cmp = compare(this.get(i), that.get(j)); if (cmp != 0) return cmp; } return this.remaining() - that.remaining(); }两个 ByteBuffer 都从自己当前 position 的位置开始,比较到 limit(剩余部分比较) ,可以判断两个 ByteBuffer 是否相同。
初始化
- 实例化 HeapByteBuffer:
allocate 方法源码:
使用的时候直接调用 allocate 方法,方法参数指定分配字节数组大小:public static ByteBuffer allocate(int capacity) { if (capacity < 0) throw new IllegalArgumentException(); return new HeapByteBuffer(capacity, capacity); }
wrap 方法源码:ByteBuffer buffer = ByteBuffer.allocate(10);
使用时可以通过 wrap 方法指定字节数组,字节数组的偏移量,字节数组的长度等:public static ByteBuffer wrap(byte[] array, int offset, int length) { try { return new HeapByteBuffer(array, offset, length); } catch (IllegalArgumentException x) { throw new IndexOutOfBoundsException(); } }
也可以使用 wrap 方法参数带有一个字节数组的,内部实现方式同上面一样:byte[] bytes = new byte[10]; ByteBuffer buffer = ByteBuffer.wrap(bytes, 0, bytes.length);
比如:public static ByteBuffer wrap(byte[] array) { return wrap(array, 0, array.length); }byte[] bytes = new byte[10]; ByteBuffer buffer = ByteBuffer.wrap(bytes); - 实例化 DirectByteBuffer:
使用的时候直接调用 allocateDirect 方法,方法参数指定分配字节数组大小:public static ByteBuffer allocateDirect(int capacity) { return new DirectByteBuffer(capacity); }ByteBuffer buffer = ByteBuffer.allocateDirect(10);
常用方法说明
ByteBuffer 内部实现细节主要都是通过字节数组来实现的, 提供的各种方法内部原理其实就是通过移动数组的索引,来实现读或者写的一个过程。
关于 ByteBuffer 读或者写主要使用 get 和 put 等一系列方法,这里不做赘述,很好理解,参考 API 文档可以很好理解,快速上手。
下面通过一个 demo 来具体说明一下 ByteBuffer 的一些常用使用方法:
@Test
public void bufferMethodsTest() {
ByteBuffer buffer = ByteBuffer.allocate(10);
System.out.println("===============初始化获取 capacity , limit , position 的值 ======================");
System.out.println(buffer.capacity());
System.out.println(buffer.limit());
System.out.println(buffer.position());
buffer.put((byte) 1);
buffer.put((byte) 2);
buffer.put((byte) 3);
buffer.put((byte) 4);
System.out.println("===============写入数据获取 limit , position 的值 ======================");
System.out.println(buffer.limit());
System.out.println(buffer.position());
buffer.flip();
System.out.println("===============flip()以后获取 limit , position 的值 ======================");
System.out.println(buffer.limit());
System.out.println(buffer.position());
byte a = buffer.get();
byte b = buffer.get();
System.out.println("===============读取数据 position 的值,并且调用 mark()方法 ======================");
System.out.println(buffer.position());
buffer.mark();
int c = buffer.get();
int d = buffer.get();
System.out.println("===============继续读取数据获取 position 的值,然后调用 reset()方法 ======================");
System.out.println(buffer.position());
buffer.reset();
System.out.println("===============调用 reset()方法以后,获取 position ======================");
System.out.println(buffer.position());
System.out.println("===============因为调用 reset()方法以后,可以重复获取之前的值 ======================");
c = buffer.get();
d = buffer.get();
System.out.println("===============调用 rewind()方法以后,重新读取写入的值 c= "+ c +" ,d = "+ d + " ======================");
buffer.rewind();
System.out.println(buffer.limit());
System.out.println(buffer.position());
System.out.println("===============调用 clear()方法以后,获取 position, limit,然后重新写值=====================");
buffer.clear();
System.out.println(buffer.limit());
System.out.println(buffer.position());
buffer.put((byte)10);
buffer.put((byte) 9);
}
- capacity() 方法获取的就是 ByteBuffer 中数组的容量,这个在 ByteBuffer 初始化成功的时候就不变, 比如上面的案例中初始化是 10 ,那么 capacity 始终是 10 。
- position() 就是获取当前正要读取或者写入的位置。
- limit() 方法获取的是 ByteBuffer 在读取或者写入的时候的最后位置, 数据写入的时候写入到 limit (也就是当前的 position = limit )的位置就结束了,读取的时候同理。
- flip() 方法是一个常用的方法,通常 ByteBuffer 写入数据后需要读取数据,在读取数据之前需要使用 flip() 方法,它的作用是:
- 改变 position 的位置 ,position 的位置归 0 ,position = 0;
- 改变 limit 的位置,limit 位置变成写入数据的总长度(这里 limit 等于最后写入数据时候的 position 位置),在上面的例子中 ByteBuffer 中写入了四个数据,调用 flip() 的时候,limit = 4;
flip() 方法通常的使用场景是在需要读取数据的时候。 - mark() 和 reset() 方法是一组方法,通常用了 mark() ,就会出现 reset() , mark 是记录当前的 position 位置,当调用 reset() 方法的时候可以返回 mark 的位置,重新读或者重新写。这两个方法通常用在读取数据的时候,需要重复读取数据的场景。
- rewind() 方法的目的仅仅是改变 position 的值,使 position = 0, 从头开始。 这个方法的使用场景是需要重复读取数据的时候,从头开始重新读取一遍。
- clear() 方法,从方法的名称来看,本意是清除 ByteBuffer 中的数据(这里需要知道一点,在使用该方法后,数据其实并没有清除)。它的作用是:
- positon = 0;
- limit = capacity;
ByteBuffer 的状态回到类似刚初始化的时候的状态。该方法的常用使用场景是从头开始重新写入数据。
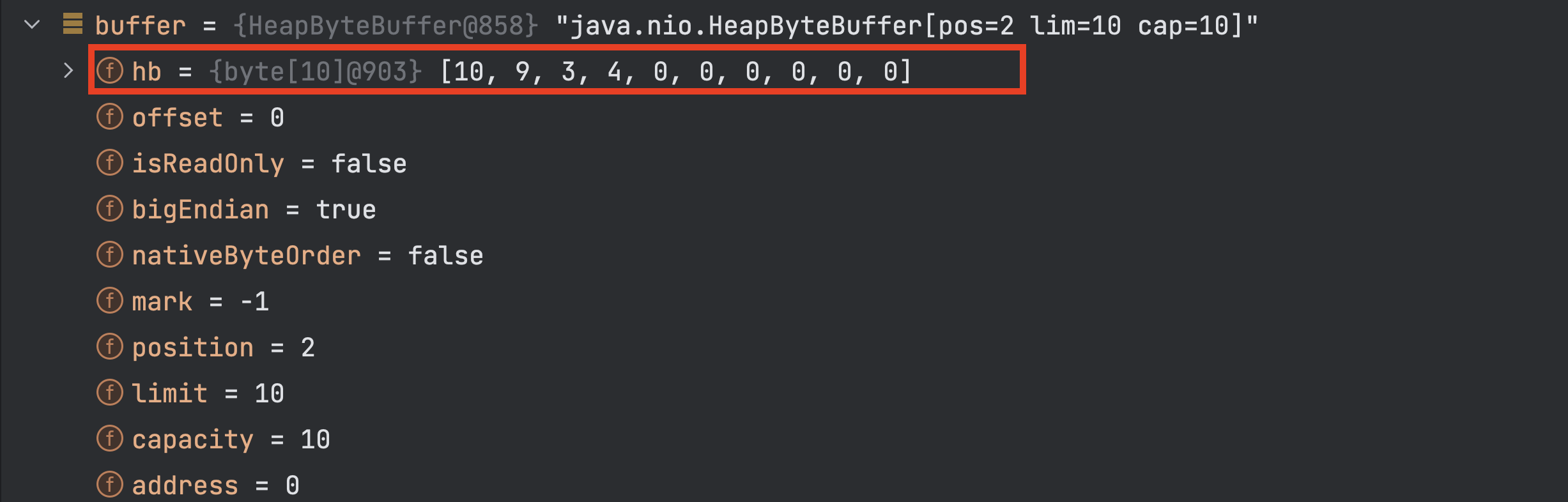
代码测试结果如下:

调用 clear 方法之后(这里可以说明调用 clear() 方法实际上并没有清除 ByteBuffer 中的数据),执行万测试程序以后 ByteBuffer 中的数据截图如下:
- compact() 方法详解
compact 作用可以理解成压缩数组,该方法的作用就是舍弃已经读取过或者写入过的数据,把未操作的数据向前移动,通过上面的案例我们可以看到调用 compact 以后,重新获取数组的数据改变了,position 的位置改变了,当前 position 会调整成 ByteBuffer 中剩余未操作数据的个数(这里内部调用了一个 ByteBuffer 的 remaining() 方法),limit 位置回设置成数组总容量。@Test public void compactTest() { byte[] bytes = new byte[]{1, 2, 3, 4, 5, 0, 0, 0, 0, 0}; ByteBuffer buffer = ByteBuffer.wrap(bytes); byte first = buffer.get(); byte second = buffer.get(); byte third = buffer.get(); buffer.compact(); System.out.println(Arrays.toString(bytes)); System.out.println(buffer.position()); System.out.println(buffer.limit()); buffer.flip(); first = buffer.get(); System.out.println(first); }
该方法的内部逻辑如下:[4, 5, 0, 0, 0, 0, 0, 0, 0, 0] 7 10 4- 改变内部数组的值,移动数组,丢弃前面已经操作的数据,未操作的数据向数组的头部移动;
- 改变 position 的值, position = remaining (剩余未操作的数据个数);
- 改变 limit 的值, limit = capacity。
compact() 方法适用于以下场景: - 需要多次写入缓冲区的数据,而不想每次都创建新的缓冲区对象。
- 读取缓冲区中的部分数据后,需要向缓冲区中继续写入数据。
- 缓冲区中已经读取的数据不再需要,需要清除已读取的数据并腾出缓冲区空间。
- slice() 方法详解
@Test
public void sliceTest() {
byte[] bytes = new byte[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
ByteBuffer buffer = ByteBuffer.wrap(bytes);
buffer.position(5);
buffer.limit(10);
ByteBuffer sliceBuffer = buffer.slice();
System.out.println(sliceBuffer.position());
System.out.println(sliceBuffer.limit());
System.out.println(Arrays.toString(bytes));
//byte a = sliceBuffer.get();
//System.out.println(a);
}
slice() 方法生成的是一个新的 ByteBuffer , 这个新的 ByteBuffer 我们可以看成是原来 ByteBuffer 的一个子集,这个子集中包含的数据是原来 ByteBuffer 中剩下未操作的数据。
我们先来分析一下源码:
public ByteBuffer slice() {
return new HeapByteBuffer(hb,
-1,
0,
this.remaining(),
this.remaining(),
this.position() + offset);
}
调用 slice 方法的时候生成的是一个新的 ByteBuffer , 这个新的 ByteBuffer 的底层数组和调用它的 ByteBuffer 底层数组是同一个数据,区别是新的 ByteBuffer 的 offset 的值改变了,offset 值等于调用 slice 方法的 ByteBuffer 的 position 值。
上面的一个测试案例我们运行看一下数据如下:
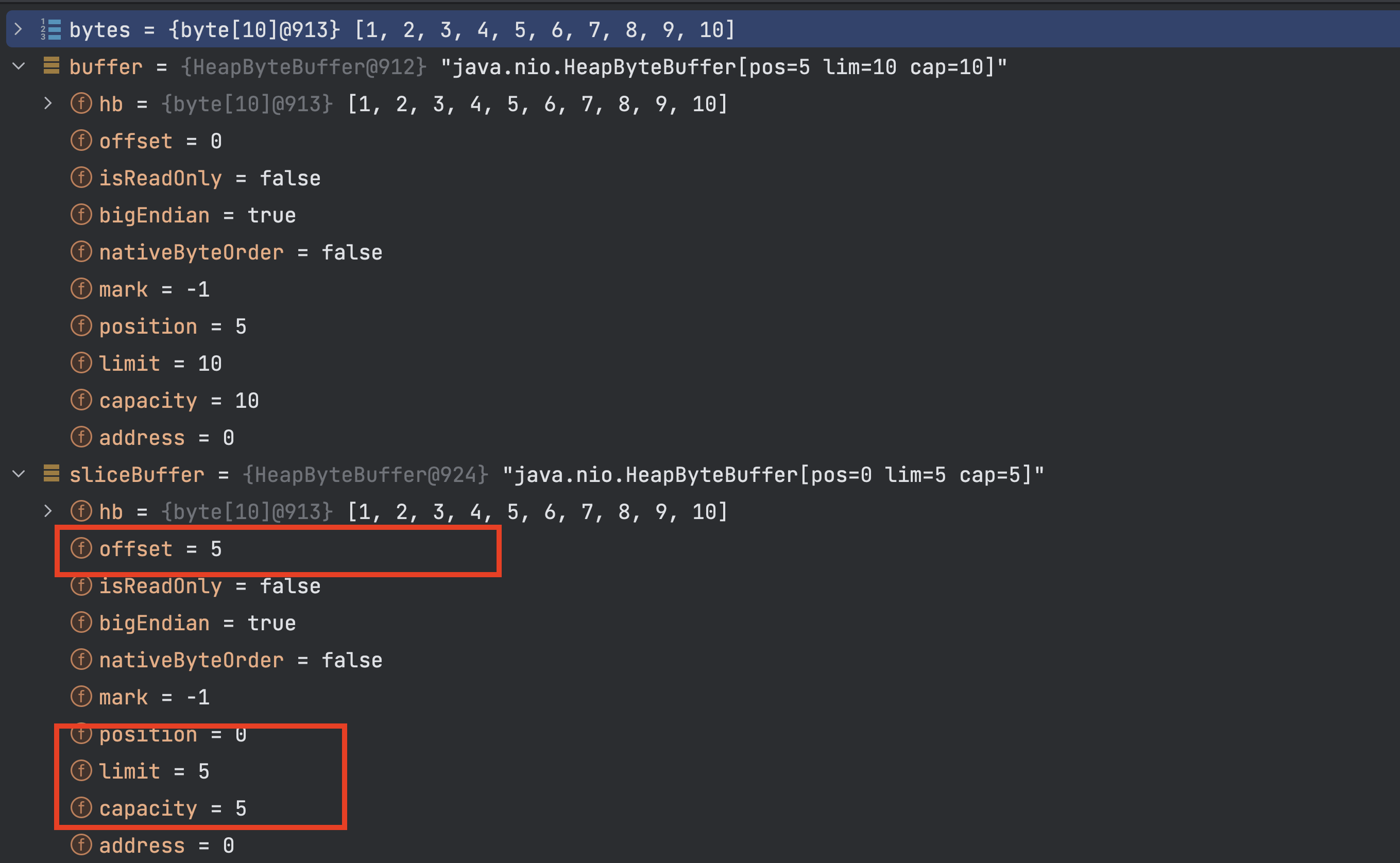
测试代码中的 buffer 和 sliceBuffer 底层的 hb 数组是同一个,底层数据是一样的,区别的是新的 ByteBuffer 的 offset 值改变了,不再是 0 ,而是 5 。
调用 slice() 方法的 ByteBuffer 和获取到的新的 ByteBuffer 底层数组是同一个,数据都是一样的。
这里我曾经有一个问题:ByteBuffer 中有一个属性 offset , 这个 offset 属性是不是多余的,它是干嘛用的呢?
通过 slice() 方法的分析,我的问题得到了解决。
上面的代码实例中当我们操作新的 sliceBuffer 的时候,底层会从数组索引 offset + position 处开始操作,比如上面我注释掉的这两行,测试 a 的结果是 6:
byte a = sliceBuffer.get();
System.out.println(a);
综上: slice() 方法的功能,就是获取一个新的 ByteBuffer ,这个新的 ByteBuffer 中的数据是原来剩下来的未操作数据而已,我们可以想象成新的 ByteBuffer 底层有一个新的数组,这个数组中的数据是原来 ByteBuffer 中未操作的数据。














 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









