






NLTK学习笔记(二)
一、N-gram标注器训练
1-gram:在基于一元处理一个语言处理任务时,我们使用上下文中的一个项目。标注的时候,我们只考虑当前的词符,与更大的上下文隔离。给定一个模型,我们能做的最好的是为每个词标注其先验的最可能的标记。这意味着我们将使用相同的标记标注一个词,如 wind,不论它出现的上下文是the wind还是to wind。
一个n-gram tagger标注器是一个一元标注器的一般化,它的上下文是当前词和它前面n-1个标识符的词性标记,如下图所示。要选择的标记是圆圈里的
t
n
t_n
tn,灰色阴影的是上下文。在图中所示的n-gram 标注器的例子中,n=3;即考虑当前词的前两个词的标记。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i4UqdXgM-1595848707550)(./gram.png)]
brown_tagged_sents = brown.tagged_sents(categories='news')
train_num = len(brown_tagged_sents) // 5 * 4
train_set = brown_tagged_sents[:train_num]
test_set = brown_tagged_sents[train_num:]
tagger = nltk.DefaultTagger('NN')
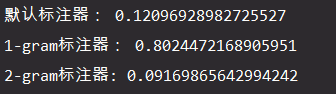
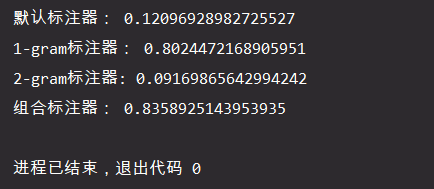
print('默认标注器:', tagger.evaluate(test_set))
tagger = nltk.UnigramTagger(train=train_set)
print('1-gram标注器:', tagger.evaluate(test_set))
tagger = nltk.BigramTagger(train=train_set)
print('2-gram标注器:', tagger.evaluate(test_set))
N-gram标注器不考虑跨越句子边界的上下文。因此,NLTK的标注器被设计用于句子列表,其中一个句子是一个词列表。在一个句子的开始,
t
n
t_n
tn和前面的标记被设置为None。
二元标注器的成功率偏小的原因在于因为要考虑前面的词的词性。因此如果前面的词标记为None,训练过程中也从来没有见过它前面有None标记的词,因此标注器也无法标注句子的其余部分当n越大的时候,上下文的特异性就会增加,要标注的数据中包含训练数据中不存在的上下文几率也增大,这被称为数据稀疏问题。组合标注器可以较好地解决此问题。
步骤如下:
- 1.使用bigram标注器标注标识符
- 2.如果bigram标注器无法找到标记,回退使用unigram标注器
- 3。如果unigram标注器也无法找到标记,使用默认标注器
t0 = nltk.DefaultTagger('NN')
t1 = nltk.UnigramTagger(train=train_set, backoff=t0)
t2 = nltk.BigramTagger(train=train_set, backoff=t1)
print('组合标注器:', t2.evaluate(test_set))
二、朴素贝叶斯分类器
贝叶斯分类器的分类原理是通过先验概率,利用贝叶斯公式计算出后验概率,选择最大后验概率所对应的分类结果。
贝叶斯准则:
P
(
c
∣
x
)
=
P
(
c
)
P
(
x
∣
c
)
P
(
x
)
P(c|x) = \frac{P(c)P(x|c)}{P(x)}
P(c∣x)=P(x)P(c)P(x∣c)
对于朴素贝叶斯分类器,朴素(naive)的含义是各个特征属性之间是相互独立的。例如,在计算
p
(
w
∣
c
i
)
p(w|ci)
p(w∣ci)时,将特征向量
w
w
w展开为独立子特征,则转化为
p
(
w
0
,
w
1
,
⋅
⋅
⋅
,
w
N
∣
c
i
)
p(w_0,w_1,···,w_N|c_i)
p(w0,w1,⋅⋅⋅,wN∣ci),若所有特征都独立,即等价于
p
(
w
0
∣
c
i
)
p
(
w
1
∣
c
i
)
p
(
w
2
∣
c
i
)
⋅
⋅
⋅
p
(
w
N
∣
c
i
)
p(w_0|c_i)p(w_1|c_i)p(w_2|c_i)···p(w_N|c_i)
p(w0∣ci)p(w1∣ci)p(w2∣ci)⋅⋅⋅p(wN∣ci),这就是利用了朴素的原则。
因此,朴素贝叶斯分类器的训练过程就是基于训练集D来估计类先验概率
p
(
c
)
p(c)
p(c),并为每个特征属性估计条件概率
p
(
x
i
∣
c
)
p(x_i|c)
p(xi∣c)。对于类先验概率,在有足够独立同分布训练样本的条件下,通过计算各类样本占总样本数的比例来计算。
在NLTK的朴素贝叶斯实现之中,它的输入的训练集的输入是类似于以下的形式:
[
({‘attr1’:val1, ‘attr2’: val2, ‘attr3’: val3 … ‘attrn’: valn}, label1),
({‘attr1’:val1, ‘attr2’: val2, ‘attr3’: val3 … ‘attrn’: valn}, label2),
…
]
NLTK的实现过程如下:
- 1.数据准备:通过nltk_data从文件中导入训练数据,并为原始数据打好标签
- 2.数据置乱:随机打乱打好标签的数据集的顺序,保证训练集抽取的随机性
- 3.特征提取:构造features()函数,从原始数据及中提取特征
- 4.模型训练:调用nltk.NaiveBayesClassifier.train()训练模型
- 5.性能测试:利用nltk.classify.accuracy()测试模型的准确性
2.1 利用贝叶斯实现性别判断
# 特征取的是最后一个字母
def gender_features(word):
return {'last_2letters': word[-1] +word[1]}
name = [(n, 'male') for n in names.words('male.txt')] + [(n, 'female') for n in names.words('female.txt')] # 数据准备
random.shuffle(name) # 打乱数据的分类顺序
features = [(gender_features(n), g) for (n, g) in name] # 特征提取
classifier = nltk.NaiveBayesClassifier.train(features[:len(name)//2]) # 训练模型
print(classifier.classify(gender_features('Mussness'))) # 测试
print(classify.accuracy(classifier, features[len(name)//2:])) # 性能测试
print(classifier.show_most_informative_features(5))

在数据集中采用1/2作为训练集,1/2作为测试集,最后的测试性能可以达到77.39%的准确率。
2.2 利用贝叶斯分析文章情感
def word_features(words):
return dict([(word, True) for word in words])
neg_texts = movie_reviews.fileids('neg')
pos_texts = movie_reviews.fileids('pos')
random.shuffle(neg_texts)
random.shuffle(pos_texts)
neg_features = [(word_features(movie_reviews.words(fileids=[f])), 'neg') for f in neg_texts]
pos_features = [(word_features(movie_reviews.words(fileids=[f])), 'pos') for f in pos_texts]
train_features = neg_features[:len(neg_features)//2] + pos_features[:len(pos_features)//2]
test_features = neg_features[len(neg_features)//2:] + pos_features[len(pos_features)//2:]
classifier = classify.NaiveBayesClassifier.train(train_features)
print(classify.accuracy(classifier, test_features))
print(classifier.show_most_informative_features(5))
在数据集中采用1/2作为训练集,1/2作为测试集,最后的测试性能可以达到81.1%的准确率。

2.3 总结
特性如果选择的太多则会导致算法在训练集上正确率很高,而在测试集上较差的情况,此时就出现了过拟合。尤其是训练数据集较小的情况下更容易出现。因此要平衡特征的选取,以取得算法在未知数据上更好泛化能力。过拟合的反面是欠拟合,由于训练集数据量较少导致的不足。















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









