







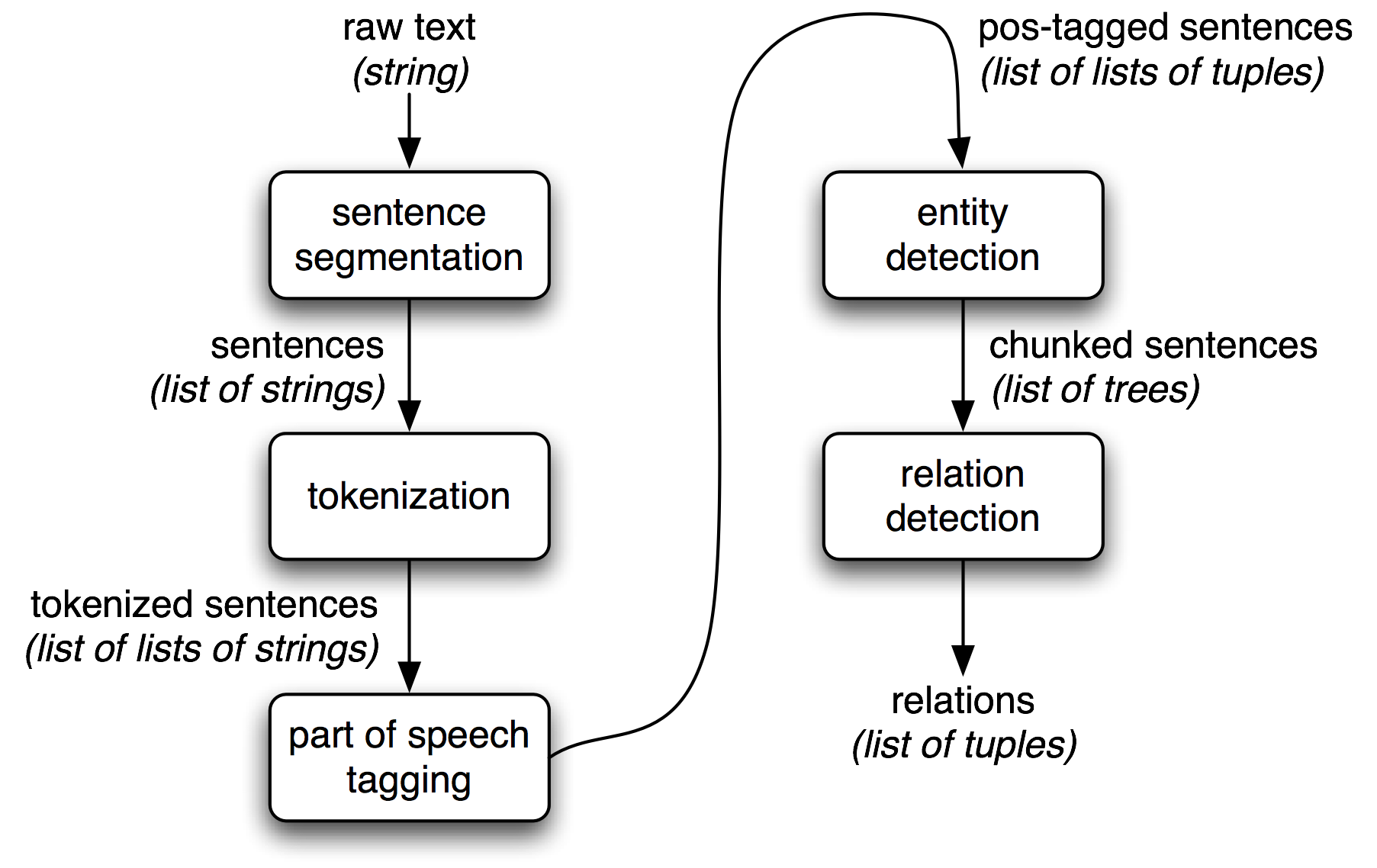
先来一张信息提取流程图
1. NP Trunking
用正则表达式的一个简单例子
>>> sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),
... ("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]>>> grammar = "NP: {<DT>?<JJ>*<NN>}"
>>> cp = nltk.RegexpParser(grammar)
>>> result = cp.parse(sentence)
>>> print result
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
>>> result.draw()

因为这部分比较直观简单,另外一个例子直接抄书了
>>> cp = nltk.RegexpParser('CHUNK: {<V.*> <TO> <V.*>}')
>>> brown = nltk.corpus.brown
>>> for sent in brown.tagged_sents():
... tree = cp.parse(sent)
... for subtree in tree.subtrees():
... if subtree.label() == 'CHUNK': print(subtree)
...
(CHUNK combined/VBN to/TO achieve/VB)
(CHUNK continue/VB to/TO place/VB)
(CHUNK serve/VB to/TO protect/VB)
(CHUNK wanted/VBD to/TO wait/VB)
(CHUNK allowed/VBN to/TO place/VB)
(CHUNK expected/VBN to/TO become/VB)
...
(CHUNK seems/VBZ to/TO overtake/VB)
(CHUNK want/VB to/TO buy/VB)2. Chinking
(汗颜啊,正则表达式里经常用自己却不知道这个词。还是直接上code)
>>> grammar = r"""
... NP:
... {<.*>+} # Chunk everything
... }<VBD|IN>+{ # Chink sequences of VBD and IN
... """
>>> sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),
... ("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
>>> cp = nltk.RegexpParser(grammar)
>>> print(cp.parse(sentence)
... )
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
3. Tags VS trees
三种特殊tag: I (inside), O (outside), or B (begin)
文本形式的
We PRP B-NPsaw VBD O
the DT B-NP
yellow JJ I-NP
dog NN I-NP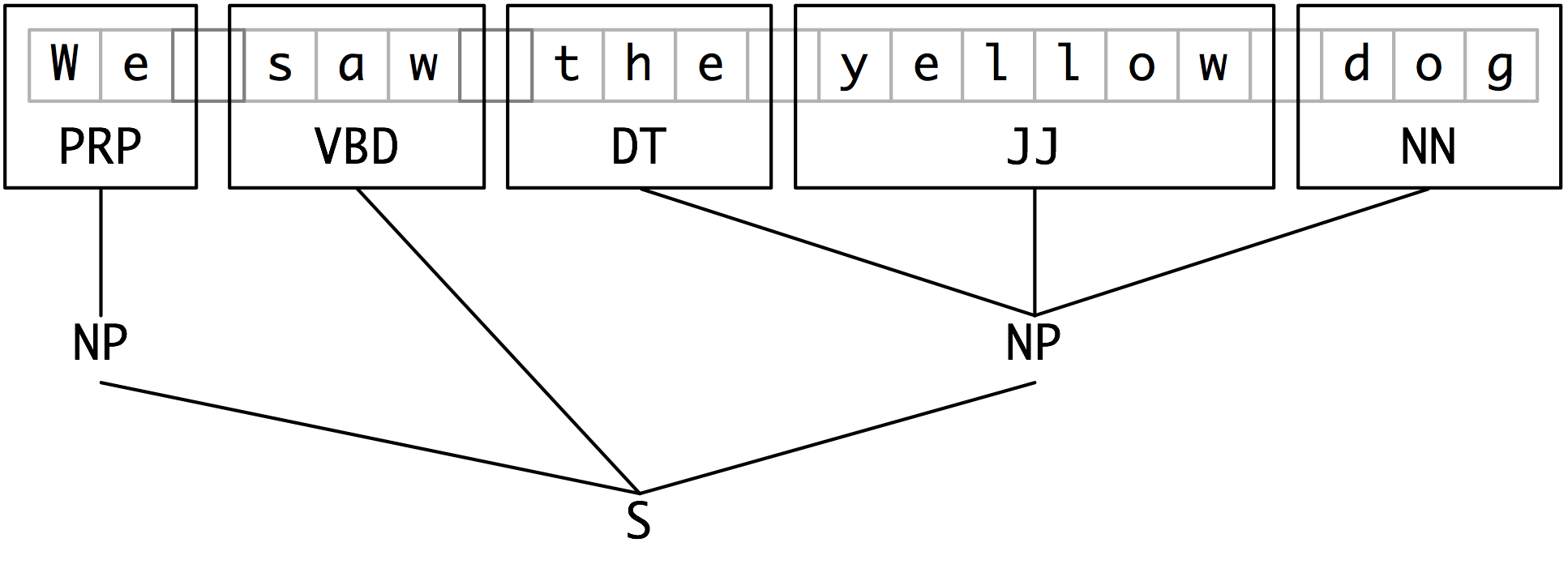
4. Evaluating chunkers
Using the corpus module we can load Wall Street Journal text that has been tagged then chunked using the IOB notation. The chunk categories provided in this corpus are NP, VP and PP. As we have seen, each sentence is represented using multiple lines, as shown below:
he PRP B-NP
accepted VBD B-VP
the DT B-NP
position NN I-NP
...5.一个使用Maxent分类器建分块器的例子
class ConsecutiveNPChunkTagger(nltk.TaggerI):
def __init__(self, train_sents):
train_set = []
for tagged_sent in train_sents:
untagged_sent = nltk.tag.untag(tagged_sent)
history = []
for i, (word, tag) in enumerate(tagged_sent):
featureset = npchunk_features(untagged_sent, i, history)
train_set.append( (featureset, tag) )
history.append(tag)
self.classifier = nltk.MaxentClassifier.train(
train_set, algorithm='megam', trace=0)
def tag(self, sentence):
history = []
for i, word in enumerate(sentence):
featureset = npchunk_features(sentence, i, history)
tag = self.classifier.classify(featureset)
history.append(tag)
return zip(sentence, history)
class ConsecutiveNPChunker(nltk.ChunkParserI):
def __init__(self, train_sents):
tagged_sents = [[((w,t),c) for (w,t,c) in
nltk.chunk.tree2conlltags(sent)]
for sent in train_sents]
self.tagger = ConsecutiveNPChunkTagger(tagged_sents)
def parse(self, sentence):
tagged_sents = self.tagger.tag(sentence)
conlltags = [(w,t,c) for ((w,t),c) in tagged_sents]
return nltk.chunk.conlltags2tree(conlltags)注意:这部分注解比较多,需要看原文才能深入了解。
有没有参数binary=True,决定了NE还是PERSON, ORGANIZATION,或者 GPE.
>>> sent = nltk.corpus.treebank.tagged_sents()[22] >>> print(nltk.ne_chunk(sent, binary=True))
(S The/DT (NE U.S./NNP) is/VBZ one/CD ... according/VBG to/TO (NE Brooke/NNP T./NNP Mossman/NNP) ...)
>>> print(nltk.ne_chunk(sent)) (S The/DT (GPE U.S./NNP) is/VBZ one/CD ... according/VBG to/TO (PERSON Brooke/NNP T./NNP Mossman/NNP) ...)
7. Relation Extraction
有了NER,Relation Extraction就简单多了。
>>> IN = re.compile(r'.*\bin\b(?!\b.+ing)') #ignoring phrases like "success in supervising the transition of" >>> for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'): ... for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, ... corpus='ieer', pattern = IN): ... print(nltk.sem.rtuple(rel)) [ORG: 'WHYY'] 'in' [LOC: 'Philadelphia'] [ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo'] [ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington'] [ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington'] [ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles'] [ORG: 'Open Text'] ', based in' [LOC: 'Waterloo'] [ORG: 'WGBH'] 'in' [LOC: 'Boston'] [ORG: 'Bastille Opera'] 'in' [LOC: 'Paris'] [ORG: 'Omnicom'] 'in' [LOC: 'New York'] [ORG: 'DDB Needham'] 'in' [LOC: 'New York'] [ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York'] [ORG: 'BBDO South'] 'in' [LOC: 'Atlanta'] [ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']
(之后的Dutch那个完全看不懂个,略过)















 8198
8198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









