







文章目录
前言
Spark SQL是一个用来处理结构化数据的Spark组件,前身是Shark,Spark SQL拜托了Shark对Hive的依赖。
需要格外注意的是,Spark SQL提供了基于RDD的、名字叫DateFrame的这个数据结构,是一个分布式的Row对象集合。
Spark SQL底层依赖Spark Core,而Spark Core底层依赖RDD。

Spark和Hive
-
Spark SQL可以兼容Hive以便Spark SQL支持Hive表访问
-
Hive基于MapReduce,后者是中间操作是基于磁盘IO的,而Spark SQL基于内存
-
Spark SQL 拥有Catalyst 优化器
-
Spark SQL能够支持不同数据源
Spark SQL能替代Hive吗?
- Spark SQL没有自己的数据存储,需要依赖第三方
- Spark SQL没有元数据管理,要依赖Hive
- Hive有多种数据源同步配套组件,例如Sqoop和Flume等等
Spark SQL不可替代Hive,但是能够整合Hive实现更高的效率。
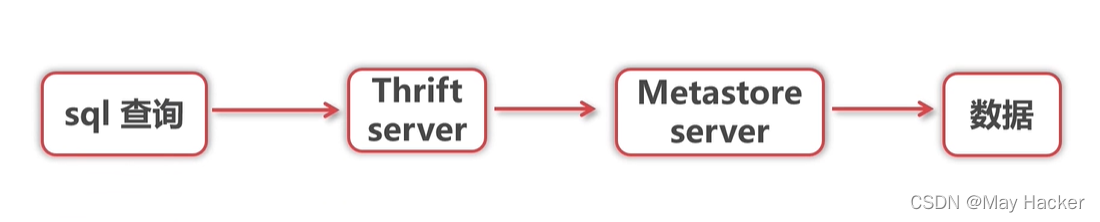
Spark SQL访问仓库
Spark SQL基于Thrift server访问Hive仓库
DataFrame、DataSet、RDD有什么区别
- DF是基于RDD的分布式数据库,是Row对象的集合,相比RDD有更高效的性能,提供丰富的API。
- DS可以看作是DF的一个特例,DS是一个强类型的数据集。
- DF相比RDD,知道数据的结构类型,定制化内存管理,将数据保存在JVM堆外管理,摆脱了Java GC的管理。
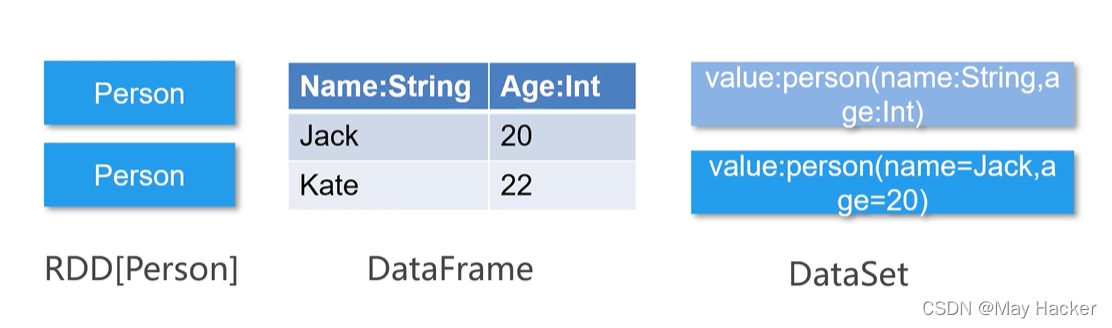
- DS 提供Encoder,能够在不反序列化整个对象的情况下,进行操作
Parquet数据格式
Parquet是专门针对大数据的一种数据格式。
- 它是列式存储格式
- 是大数据时代文件存储的首选标准
- 同时,Parquet是Spark默认的存储格式
在之前我们保存的日志文件是很有可能存在如下图所示的嵌套数据格式的,传统操作就是把嵌套的对象Json序列化,需要使用的时候再反序列化,然而序列化是耗时的,有没有既能存储,又不需要序列化、反序列化呢?Parquet可以!

DataFrame API介绍
创建DataFrame
1.结构化数据创建DataFrame
支持Parquet文件和JSON文件
- 对于Parquet,可以用load()
- 对于JSON,还需要使用format(),之后再load,例如
context.read.fomrat(json).load(url)
2.外部数据库创建DataFrame
Spark SQL可以从外部数据库创建DF,方法是基于JDBC或者ODBC,下面以JDBC为例
val jdbcDF = sqlContext.read.format("jdbc").options(数据库连接相关参数)
3.基于RDD创建DataFrame
Spark SQ可以基于RDD创建DataFrame,从数据源导入文件为RDD之后,对RDD可以map处理之后再toDF()
4. 基于Hive表创建DataFrame
使用本方式,需要先创建HiveContext,执行hiveContext.sql(),返回结果即为DF。
DF常用查询方法
- where :条件查询
- groupby:分组
- orderby:排序
- join :连接
- limit : 限制n条记录
- filter:与where功能相同














 1480
1480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









