







-
本文基于Jupyter notebook网页式交互开发环境,前提是配置好相应的软件以及路径,推荐使用Anaconda,它是免费的开源项目,下载方便,并且预置了Jupyter notebook应用程序和Numpy,Scipy,matplotlib,pandas,IPython,scikit-learn等诸多科学计算包
-
分析的对象是一个已经封装好的数据集合,文本重点是对于该对象结构的剖析,以及使用既有算法对其训练,观察,预测和评估的一系列操作。而不涉及如何从其他地方提取数据,生成新的数据集**
初识数据
load_iris()是scikit-learn中包含的典型数据集,供初学者使用。它与字典十分类似,首先提取里面的键值对,再根据我的理解来分析各个成分的作用:
from sklearn.datasets import load_iris
iris_dataset = load_iris()
print("该数据集中,所有键值对的键参数:")
print(iris_dataset.keys())
运行结果:
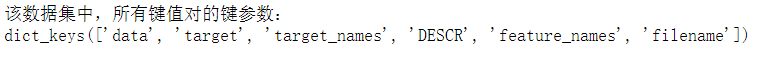
我们分别运行一下每个Key对应的数组,看看会发生什么
print(iris_dataset['DESCR'][:193]+"\n...")
运行结果:

‘DESCR’力求通过文本的方式让使用者更好的了解此数据集
print("花的品种:")
print(iris_dataset['target_names'])
运行结果:

‘target_name’对应的值是对于预测结果的文字描述
print("每束花都是啥类型的?:\n")
print(iris_dataset['target'])
运行结果:
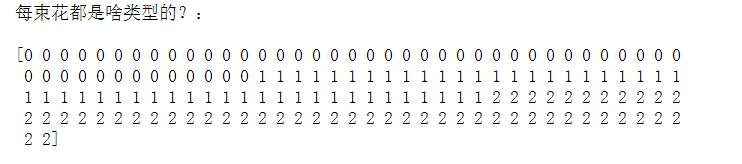
’target‘对应的值是该数据集中所有对象的评判结果
不嫌麻烦的话,可以看出这个值也符合’DESCR‘中的描述
print("花型特征:")
print(iris_dataset["feature_names"])
运行结果:

’feature_names’是对于所以特征值的文字描述
对于数据的处理和可视化有专门的函数,这里为了帮助理解,我们列举出集合中前十个”鸢尾花“的特征。
print("First ten rows of data")
print(iris_dataset['data'][:10])
运行结果:

这个Key叫data更符合机器学习的思想,像target一样叫feature的话,可能会让人觉得摸不着头脑。
print(iris_dataset['filename'])
运行结果:
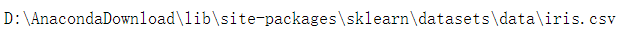
这是该数据集的路径,这也进一步佐证了它是sklearn包下的一个既定文件。自主应用机器学习问题时,所定义的数据也该参考上述格式。
时间实在有限,懒狗一条,后面会陆陆续续完成对整个鸢尾花数据集的机器学习步骤总结。















 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









