






一、安装Hadoop前的准备
4台虚拟机配置参数
CentOS Linux release 7.6.1810 (Core)
内存:4G
CPU:8核
硬盘:30G
| hostname | IP | 业务角色 |
|---|---|---|
| node-1 | 192.168.1.20 | DataNode、NodeManager、ResourceManager、NameNode |
| node-2 | 192.168.1.21 | DataNode、NodeManager、SecondaryNameNode |
| node-3 | 192.168.1.22 | DataNode、NodeManager |
| node-4 | 192.168.1.23 | DataNode、NodeManager |
1、安装JDK配置环境变量
解压JDK1.8.0安装包到/opt/下
tar -zxvf jdk-8u221-linux-x64.tar.gz -C /opt
mv jdk1.8.0_221 jdk
配置JDK环境变量到/etc/profile文件中
export JAVA_HOME=/opt/jdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
执行source /etc/proflie使配置生效
2、时间同步
1.查看4台机子的时间,在全部会话框中输入命令
date
2.若发现四台机子的时间相差很多,在全部会话框中输入命令安装“时间同步器”
yum -y install ntp
3.安装执行完成后,在全部会话框中输入下面命令进行时间同步
ntpdate time1.aliyun.com
此时的时间与阿里云服务器时间同步
时间同步步骤完成后,接下来对四台机子的配置文件进行检查
3、查看IP映射
每台设备的/etc/hosts都要配置
cat /etc/hosts

4、关闭防火墙firewalld和selinux
systemctl stop firewalld
systemctl disable firewalld
vi /etc/sysconfig/selinux
SELINUX=disabled
5、免密钥登录
ssh-keygen
# 一直回车
ssh-copy-id node-1
ssh-copy-id node-2
ssh-copy-id node-3
ssh-copy-id node-4
到这里,前期的准备工作已经结束最好每台都reboot后再检查下,接下来进行Hadoop的安装
二、Hadoop的安装
版本:hadoop-3.1.4.tar.gz
#我用的是hadoop-3.1.4编译版本
最好用编译版本,因为本地库需要和linux系统的内核匹配,所以需要重新编译hadoop的本地库
关于hadoop编译可以看我的另一篇文章
基于hadoop-3.1.4在Centos7进行编译过程
1.上传Hadoop安装包
将hadoop-3.1.4.tar.gz安装包通过rz放到node-1中
其他设备同样用rz上传或者通过node-1用scp命令传给其他节点
scp /opt/hadoop-3.1.4.tar.gz root@node-2:/opt
scp /opt/hadoop-3.1.4.tar.gz root@node-3:/opt
scp /opt/hadoop-3.1.4.tar.gz root@node-4:/opt
注:由于之前配置过免秘钥,scp应该是不用输入密码的。如果需要输密码,请检查上面的免秘钥操作
2.解压安装包
tar -zxvf /opt/hadoop-3.1.4.tar.gz -C /opt/
3、配置Hadoop环境变量
cat >> /etc/profile << EOF
export HADOOP_HOME=/opt/hadoop-3.1.4
export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin
EOF
# 使配置生效
source /etc/profile
4.验证
输入hadoop检查下环境变量是否生效
[root@node-1 opt]# source /etc/profile
[root@node-1 opt]# hadoop
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
........
三、修改Hadoop文件配置
注:先配置node-1节点,等所有配置文件都修改完成确认无误后,直接把node-1的配置文件发送到其他节点上,就不用每台都要配置一遍了
1.输入下面命令,进入其目录
cd /opt/hadoop-3.1.4/etc/hadoop/
2.修改hadoop-env.sh文件
vi hadoop-env.sh
约54行,删除这行前面的#
export JAVA_HOME=/opt/jdk
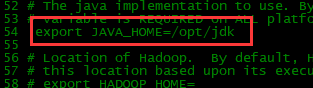
配置完成后,保存退出
3.修改core-site.xml 文件
vi core-site.xml
在标签<configuration>下追加下面内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://node-1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.4/tmp/</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
保存退出
4.修改hdfs-site.xml文件
vi hdfs-site.xml
在标签<configuration>下追加下面内容
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-2:9868</value>
</property>
保存退出
5.修改mapred-site.xml文件
vi mapred-site.xml
在标签<configuration>下追加下面内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
保存退出
6.修改yarn-site.xml文件
vi yarn-site.xml
在标签<configuration>下追加下面内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
保存退出
7.修改worker文件
vi worker
把所有节点添加上去
node-1
node-2
node-3
node-4
保存退出
8.分发配置文件
scp hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml workers root@node-2:`pwd`
scp hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml workers root@node-3:`pwd`
scp hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml workers root@node-4:`pwd`
四、初始化hdfs
输入以下命令
hdfs namenode -format
[注]:只格式化一次,再次启动集群不要执行,否则clusterID会改变
格式化成功后,current目录就会存在一个下面的文件
[root@node-1 current]# ls
edits_0000000000000000001-0000000000000000002
edits_0000000000000000003-0000000000000000003
edits_0000000000000000004-0000000000000000005
edits_0000000000000000006-0000000000000000006
edits_0000000000000000007-0000000000000000008
edits_inprogress_0000000000000000009
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
[root@node-1 current]# pwd
/opt/hadoop-3.1.4/tmp/dfs/name/current
五、一键启动所有集群
执行以下命令,一键启动
start-all.sh
启动成功后通过jps命令查看每个节点的业务角色是否正确
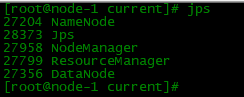
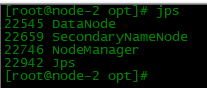
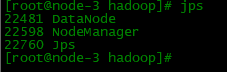
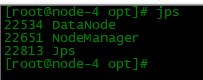
六、web端-HDFS集群
- 地址:http://namenode_host:9870/
- http://192.168.1.20:9870/


七、web端-yarn集群
- 地址:http://resourcemanager_host:8088/
- http://192.168.1.20:8088

大功告成!!!!!!














 2792
2792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









