






《OpenShift / RHEL / DevSecOps 汇总目录》
说明:本文已经在 OpenShift 4.18 + RHOAI 2.19.0 的环境中验证
注意:如无特殊说明,和 OpenShift AI 相关的 Blog 均无需 GPU。
文章目录
RHOAI (RHODS) 简介
注意:由于红帽已在 2023/12 将 Red Hat OpenShift Data Science (RHODS) 正式改名为 Red Hat OpenShift AI (RHOAI),因此下文的 RHOAI 等同于 RHODS。
Red Hat OpenShift AI 是一个专注于人工智能的产品组合,为 AI/ML 实验和模型的整个生命周期提供工具。它是红帽驱动的社区开源软件 Open Data hub 的企业版。
RHOAI 是面向混合云的开源 AI/ML 平台。它向数据科学家和开发人员提供了一个完全受支持的环境,以便在部署到生产环境之前进行快速开发、训练和测试ML 模型。RHOAI 提供了 ML 常用的 Jupyter notebooks-as-a-service、TensorFlow 和 PyTorch 等工具环境以及用于模型服务和数据科学管道的 MLOps 组件,而且还对这些组件以及流程进行了集成,使得开箱即用。
RHOAI 是独立于 OpenShift 的产品,它即可在红帽托管的公有云上部署运行,也可在用户自管的 OpenShift 环境中部署运行。
RHOAI 的功能组件
RHOAI 内置的功能组件和相互关系如下图和下文描述:

模型 - 人工智能模型、机器学习模型或简称模型是一种系统或算法,旨在通过执行通常需要人工干预的任务或做出通常需要人工干预的决策来模拟人类的能力。就内部而言,模型通常是一种概率或代数算法(如矩阵)。模型接收输入数据,应用算法(决策树、神经网络、天真贝叶斯等)并产生输出。一般来说,训练过程会反复调整这些算法的系数,直到输出值与训练数据相似。
Jupyter Notebook - Jupyter Notebook 是一种基于网络的应用程序,允许用户交互式地创建包含叙述性文本、可执行代码和可视化内容的实时文档。Jupyter Notebook 是数据科学和机器学习领域的常用工具。
Workbench - Workbench 是在 OpenShift 上运行的容器化、云原生数据科学工作环境。Workbench 通过 pods 运行,包含常用的数据科学工具(如 JupyterLab)、库(如 Tensorflow)或随时可用的 GPU 功能。RHOAI 提供了几种用于创建 Workbench 的预配置容器镜像。
Workbench Image - 运行 Workbench 的容器图像。RHOAI 包含可用于不同工作环境的镜像。每个镜像包含一组不同的库和版本。Pytorch、TensorFlow、Minimal Python 或 Standard Data Science 就是这些映像的例子。用户可以使用提供的 Workbench Image,也可以根据自己的需要创建自定义 Workbench Image。
持久存储 - 可以将不同类型的存储挂载到工作区,以持久化工作成果。
Data connection - Data connection 是将 Workbench 连接到外部云存储提供商(如 AWS S3)的配置值映射,用来从外部向应用提供模型训练数据。。
Data Science Pipeline - 以自动化方式执行脚本或 Jupyter Notebook 的工作流。管道有助于规范数据收集–数据清理–模型训练–模型评估–模型上传的周期。通常管道会在训练好的模型上传到 S3 存储桶或类似云存储后结束。
Model Server - 模型服务器可以读取导出的模型文件,并通过标准 API 提供模型。模型服务器需要 Data connection 才能从云存储中下载模型文件。
AI/ML 项目实施流程
使用 RHOAI 开发部署运行 AI/ML 项目的流程如下:

获取数据 - 在这一阶段,数据科学家将数据载入工作台。例如,数据科学家可以将文件上传到工作台、从 S3 下载文件、从数据库查询数据或读取数据流。RHOAI 在许多 Workbensh 中都包含了 Pandas 库。Pandas 提供从 CSV、JSON 或 SQL 等不同来源加载数据的函数。此外还可以使用 Red Hat Marketplace 上经过认证的 ISV 生态系统应用程序(例如 Starburst 和 Cloudera)来添加特定的数据摄取功能。
预处理数据 - 在这一阶段,数据科学家对数据进行探索、分析和预处理。在 Jupyter Notebook 中,数据科学家使用 Matplotlib、Pandas 和 Numpy 等库绘制可视化图、对数据进行归一化处理或删除异常值。
训练模型 - 在这一阶段,数据科学家使用预处理数据来训练模型。RHOAI 提供了使用 TensorFlow、PyTorch 和 Scikit-learn 等常用库训练模型的 Workbench Image,其中一些 Image 还包括随时可用的 GPU 支持,以加快训练速度。
评估模型 - 训练完成后,数据科学家会评估训练模型在测试和验证数据子集上的性能。这些子集是摄入数据的一部分,用于验证训练好的模型是否有泛化能力,即在未见过的样本上表现良好。通常,数据科学家会重复预处理-训练-评估循环,直到他们对模型评估指标感到满意为止。
导出和上传模型 - 模型训练和评估完成后,数据科学家可将模型文件上传到由 Data Connection 配置的存储空间。
管道执行 - 机器学习工程师可以构建数据科学管道来自动运行前面的一系列步骤,例如,在有新数据时。RHOAI 提供的数据科学管道是 Tekton、Kubeflow Pipelines 和 Elyra 的组合。工程师可以选择是使用 Elyra 创建管道,在可视化的高层次上工作,还是使用 Tekton 和 Kubeflow 的深层知识,在低层次上工作。
部署模型 - 机器学习工程师可以创建模型服务器,从外部 S3 存储获取导出模型,并通过 REST 或 gRPC 接口公开模型。模型服务器使用数据连接从 S3 下载模型文件。
监控模型 - 机器学习工程师和数据科学家可以使用 Prometheus 收集的指标监控生产中模型的性能。
开发和部署应用程序 - 模型在生产中可用后,应用程序开发人员可以通过将其应用程序指向模型服务器的 REST/gRPC 接口,开发和部署使用已部署模型的智能应用程序。
安装 RHOAI 环境
运行环境说明
- 本文使用的是单机版 OpenShift Local 4.18 环境。
- 本文除了要以容器的方式运行部署 RHOAI(包含 Jupyter notebooks、ML 运行监控等)环境,还要部署测试应用(至少分配 8G 内存),因此为整个 OpenShift Local 的虚机提供了 20vCore + 48GB 内存 + 250GB 硬盘。
- 运行 RHOAI 的硬件环境是否需要有 GPU 取决于在其上运行的 ML 模型是否强制需要。如有需要,可在配有 GPU 资源的 OpenShift 上为运行的 ML 声明分配 GPU。但如无强制需要和声明,ML 模型可在 CPU 上运行。由于本文意为演示 RHOAI,所以 OpenShift 运行环境没有配 GPU,ML 直接运行在 CPU 上。
安装依赖环境
- 安装 OpenShift Serverless Opertor 1.35.1
- 安装 OpenShift ServiceMesh Operator 2.6.3
- 安装 Red Hat - Authorino Operatorr 1.2.1
- 如果需要使用 RHOAI 的 Data Science Pipelines 功能,请根据《OpenShift 4 Tekton (1) - OpenShift Pipeline入门-安装Pipeline Operator》一文安装 OpenShift Pipeline。
安装配置 OpenShift AI Operator
- 在 OpenShift 的 OperatorHub 中找到并使用默认配置安装 Red Hat OpenShift AI Operator。
- 进入安装好的 Red Hat OpenShift AI Operator,使用以下配置创建一个 DSC Initialization。
spec:
applicationsNamespace: redhat-ods-applications
monitoring:
managementState: Managed
namespace: redhat-ods-monitoring
serviceMesh:
controlPlane:
metricsCollection: Istio
name: data-science-smcp
namespace: istio-system
managementState: Managed
- 在 redhat-ods-operator 项目中使用以下配置创建一个 Data Science Cluster。
spec:
components:
codeflare:
managementState: Removed
kserve:
defaultDeploymentMode: Serverless
managementState: Managed
nim:
managementState: Managed
rawDeploymentServiceConfig: Headless
serving:
ingressGateway:
certificate:
type: OpenshiftDefaultIngress
managementState: Managed
name: knative-serving
modelregistry:
managementState: Removed
registriesNamespace: rhoai-model-registries
trustyai:
managementState: Removed
ray:
managementState: Removed
kueue:
managementState: Removed
workbenches:
managementState: Managed
dashboard:
managementState: Managed
modelmeshserving:
managementState: Managed
datasciencepipelines:
managementState: Managed
trainingoperator:
managementState: Removed
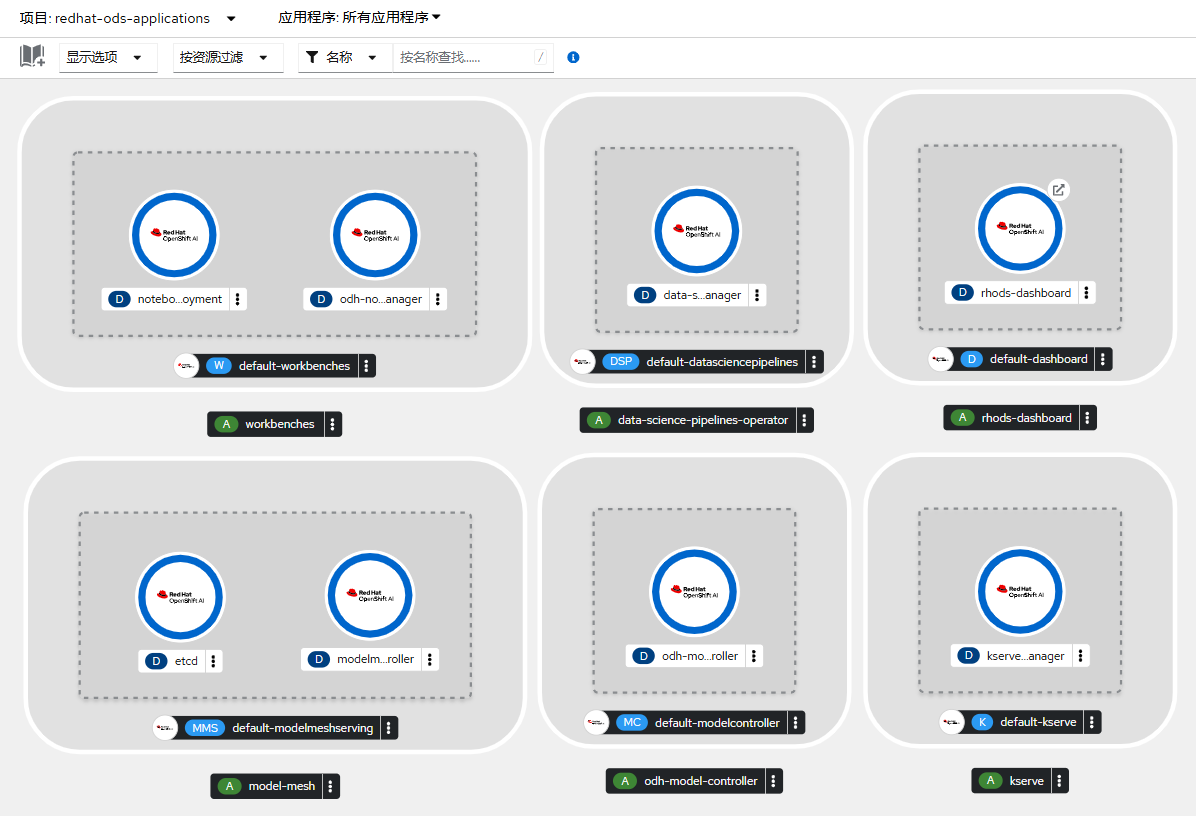
- 安装完后在 redhat-ods-applications 项目中部署的资源如下图:
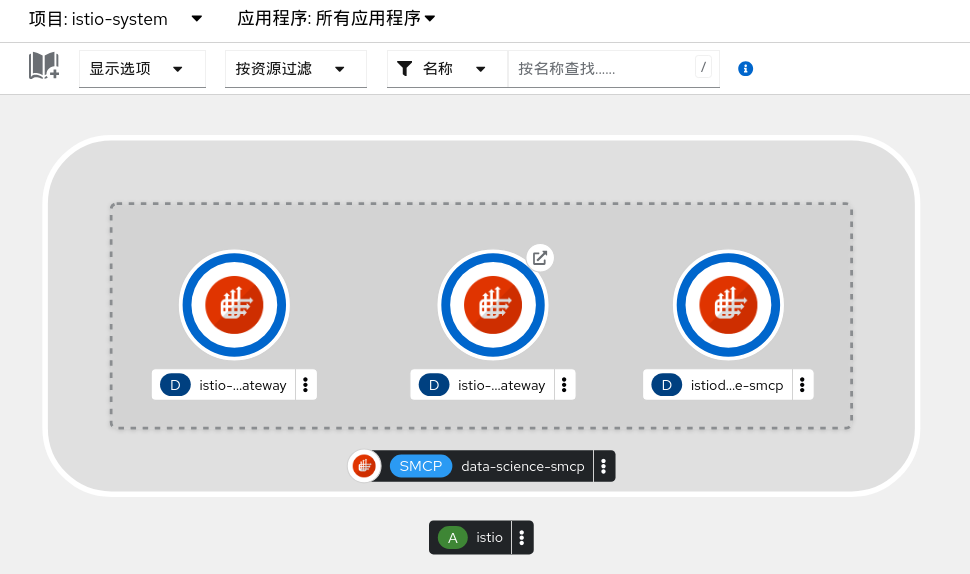
在 istio-system 项目中部署的资源如下图:
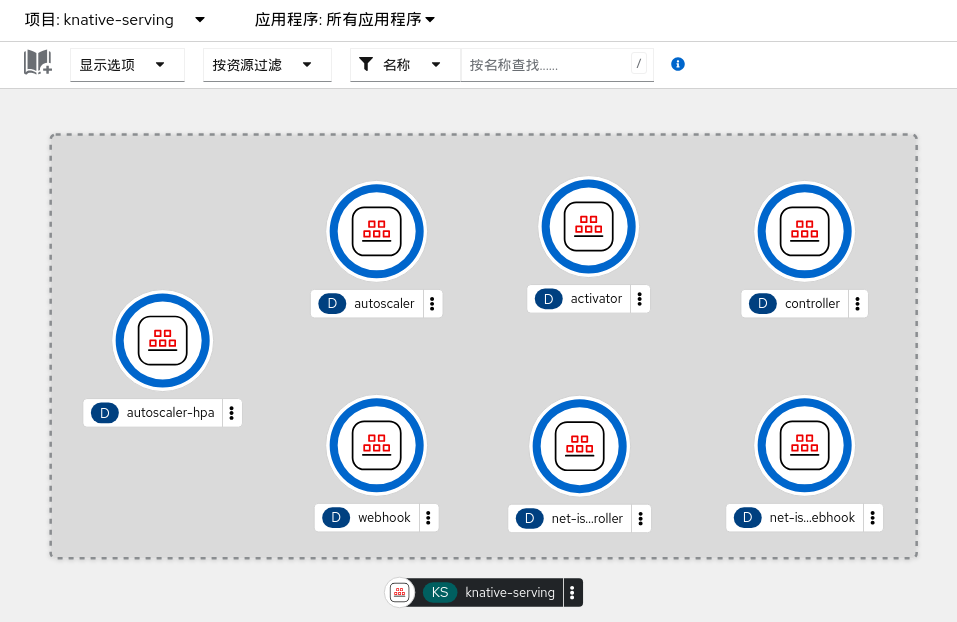
在 knative-serving 项目中部署的资源如下图:
在 redhat-ods-applications-auth-provider 项目中部署的资源如下图:
- 从 OpenShift 控制台的菜单中进入 Red Hat OpenShift AI。

- 登录后即可看到如下图的 OpenShift AI 的控制台。
创建 Jupyter Notebook 运行环境
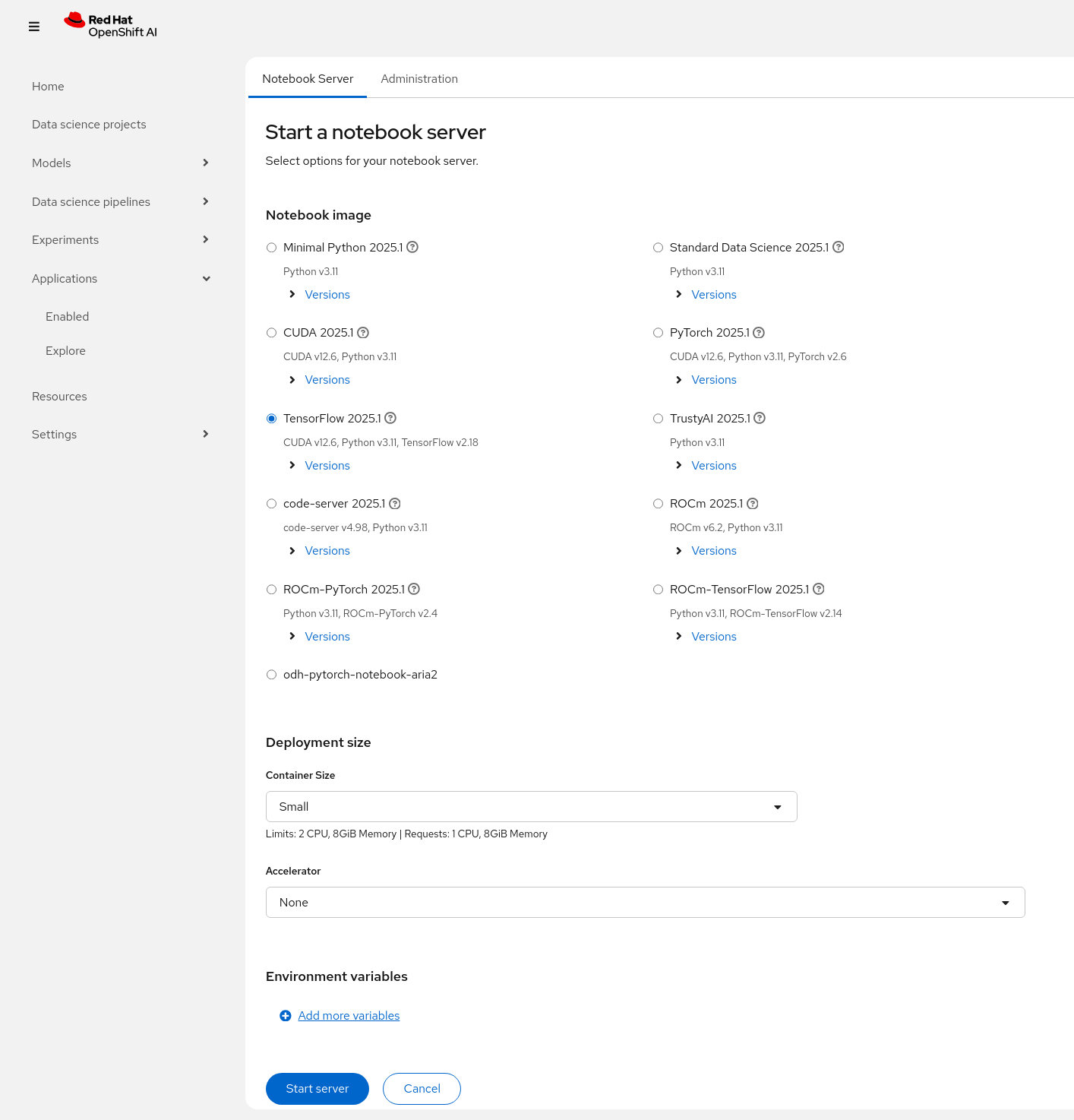
- 点击上图的 Jupyter 的 Launch application 进入Start a notebook server 页面,
- 在 Start a notebook server 页面中选中 TensorFlow 2023.2(该环境支持运行 CUDA、Python 和 TensorFlow),Container Size 选择 Small。说明:如果 OpenShift 已经配置好 NVDIA GPU,则在下图 Acclelrator 的下拉框中得以显示,否则不会显示 Acclelrator。
- 点击 Start Server 按钮后会出现 Starting server 窗口显示创建环境的进度。由于这个过程会下载相应的 Image,所以需要等一段时间。完成后会显示下图:

- 点击上图的 Open in new tab 后会出现 Jupyter 页面。

运行 Jupyter Notebook
-
点击上图 Git 图标,然后再选择 Clone a Repository。

-
在弹出的 Clone a repo 窗口中提供 https://github.com/rh-aiservices-bu/licence-plate-workshop.git,然后点击 Clone。完成 Clone 后可以在 Jupyter 中看到如下图的 license-plate-workshop 应用的文件和目录。

-
依次打开开头为 01 到 04 的 Jupyter 文件,然后点击 Start the selected the cells and advance 按钮逐步执行。

注意1:运行 02_Licence-plate-recognition.ipynb 第一行的时候会遇到下图的错误提示。可以根据提示,将 keras==2.11.0 改为 keras==2.13.1 即可。

注意2:在 03_LPR_run_application.ipynb 中引用了 requirements.txt 文件,可以按下文修改 requirements.txt 文件引用的依赖环境的版本。
Flask==2.3.2
gunicorn==20.1.0
opencv-python-headless==4.7.0.72
keras==2.13.1
tensorflow==2.13.1
scikit-learn==1.2.2
h5py==3.8.0
protobuf==3.20.3
- 在完成下一节 “部署运行 AI/ML 应用” 后再打开开头 05 的 Jupyter 文件。先将 my_image 和 my_route 改为 car.jpg 和应用的路由地址。

其中 car.jpg 为下图:

- 然后运行即可看到从 car.jpg 文件中识别的车牌。

部署运行 AI/ML 应用
- 在 OpenShift 的 “开发者” 视图中,创建 ai-app 项目。
- 进入“添加”,再进入 Git 仓库。
- 在 Git Repo URL 中提供 https://github.com/rh-aiservices-bu/licence-plate-workshop.git。
- 为“构建器镜像”选择“3.9-ubi8”。
- 将“应用程序名称”设为 licence-plate-app,“名称”设为 licence-plate。
- 在 “显示高级路由选项” 里去掉 “安全路由” 选项。
- 最后点击 “创建”。
- OpenShift 会创建一个 “构建” 来生成该 ML 应用的镜像,然后再部署生成的 ML 应用镜像。

- 在完成部署后,可以通过上图的 “路由” 打开 ML 应用页面,会显示下图运行状态。

- 最后可继续完成上一节的第 4 步,运行 05 文件,从客户端调用应用。
参考
https://redhatquickcourses.github.io/rhods-intro/rhods-intro/1.33/index.html
https://redhatquickcourses.github.io/rhods-admin/rhods-admin/1.33/index.html
https://ai-on-openshift.io/getting-started/openshift-data-science
https://redhat-scholars.github.io/rhods-lp-workshop
https://redhat-scholars.github.io/cloudnative-tutorials/openshift-data-science-object-detection.html
https://cloud.redhat.com/blog/scaling-model-serving-with-red-hat-openshift-data-science
https://developers.redhat.com/learn/openshift-data-science
https://developers.redhat.com/learn/openshift-data-science/configure-jupyter-notebook-use-gpus-aiml-modeling
https://myopenshiftblog.com/installing-openshift-data-science-ods-in-self-managed-environment
https://medium.com/@contact.av.rh/unleashing-the-full-potential-of-rhods-for-model-fine-tuning-and-inferencing-99a67b65e74e
https://access.redhat.com/documentation/en-us/red_hat_openshift_ai_self-managed/2.5/html/working_on_data_science_projects/serving-large-language-models_serving-large-language-models#about-the-single-model-serving-platform_serving-large-language-models
https://docs.redhat.com/en/documentation/red_hat_openshift_ai_self-managed/2.19/html/installing_and_uninstalling_openshift_ai_self-managed/installing-the-single-model-serving-platform_component-install#creating-a-knative-serving-instance_component-install

















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









