







Tensorflow学习笔记4
第四讲 神经网络优化
这一讲的知识点很多,难度也一下子增大了,许多函数都没有讲解,需要一个一个去查,坚持就是胜利ヾ( ̄v ̄)X
激活函数、神经网络的复杂度的简单介绍
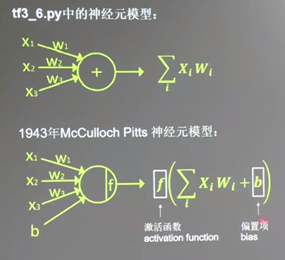
接下来将以第二种神经元模型为单位构建神经网络
激活函数(activation function):有效避免纯线性组合,使模型更具有区分度。引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。
常见的几个激活函数如下图:

神经网络(包含输入层、隐藏层、输出层)的复杂度:多用NN层数和NN参数的个数表示
- 层数=隐藏层层数+1个输出层(有计算能力的层)
- 总参数=总W+总b
神经网络优化的四大部分
神经网络的优化主要包含四个部分:
损失函数loss、学习率learning_rate、滑动平均ema、正则化regularization
接下来会一一介绍,同时附上代码
1、损失函数loss
- 损失函数loss:预测值(前向传播的计算结果)y与已知答案y_的差距
NN优化目标就是loss值最小(即y与y_无限接近)主要表现形式有mse均方误差、自定义、ce交叉熵(Cross Entropy)
补充:
-
噪声影响
就像声音的波形会受到噪声的干扰,最终所得到的叠加的波形一般是输入的数据,所以我们要模拟噪声,对数据加上噪声的影响。噪声影响的方式有很多种,比如随机分布与高斯分布。 -
随机分布:简单来说,对生成的因变量数据加上一个纵向随机小范围的偏移量,主要保证如下的特点:
• 随机性
• 小范围的偏移
• 整体线性不会有变化
使用NP.RANDOM.RAND来生成随机噪声(通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。)
举例:X=NP.LINSPACE(0,1,100) Y1=2*X + NP.RANDOM.RAND(*X.SHAPE) + 1
什么场合适合什么损失函数呢?
MSE作为损失函数,默认认为预测多与预测少损失是一样的,然而如果预测商品销量,预测多了损失的是成本,预测少了损失的是利润,如果利润不等于成本,那么MSE产生的loss无法将利益最大化。
这里我们引入自定义损失函数:

所以自定义为分段函数更加合理。
此外还有交叉熵ce(Cross Entropy):表征两个概率分布之间的距离,交叉熵越大,表示两个概率分布越远,反之越近。

根据交叉熵的值可以预测哪个结果与标准答案更接近。

可以用这两行代码,替换上图中的那一句,最终输出就是当前计算出的预测值与标准答案的差距,也就是损失函数。
2、学习率learning_rate
学习率learning_rate:每次参数更新的幅度

举例:

目的是找到图中函数的w=-1的点(损失函数梯度最小)
此时学习率设置多少合适呢?以上述为例,当设置学习率为1时,w参数在5和-7之间跳跃,即震荡不收敛,学习率为0.001时,w缓慢减小,未到达-1。可见,学习率大了震荡不收敛,学习率小了收敛速度慢。所以我们采用指数衰减学习率:(根据BATCH_SIZE的轮数动态设置学习率)


这里首先要理解的是什么是BATCH_SIZE
Batch Size定义:一次训练所选取的样本数。
Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点。适当Batch Size使得梯度下降方向更加准确。
Batch Size从小到大的变化对神经网络的影响:
1、没有Batch Size,梯度准确,只
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









