






本片笔记仅记录直播课中需要记住的东西
机器学习的局限
- 机器学习算法善于处理低维、分布相对简单的数据
- 而图像数据在几十万维的空间中以复杂的方式"缠绕"在一起,常规的机器学习算法难以处理这种复杂数据分布
在特征工程中,传统方法为:方向梯度直方图(Histogram of Oriented Gradients)在局部区域统计像素梯度的方向的分布,将图像映射成一个相对低维的特征向量,同时保留足够识别物体的信息
在 ImageNet 图像识别挑战赛里,2010 和 2011 年的冠军队伍都使用了经典的视觉方法,基于手工设计的特征 + 机器学习算法实现图像分类,Top-5 错误率在 25% 上下。受限于人类的智慧,手工设计特征更多局限在像素层面的计算,丢失信息过多,在视觉任务上的性能达到瓶颈。
从特征工程到特征学习:
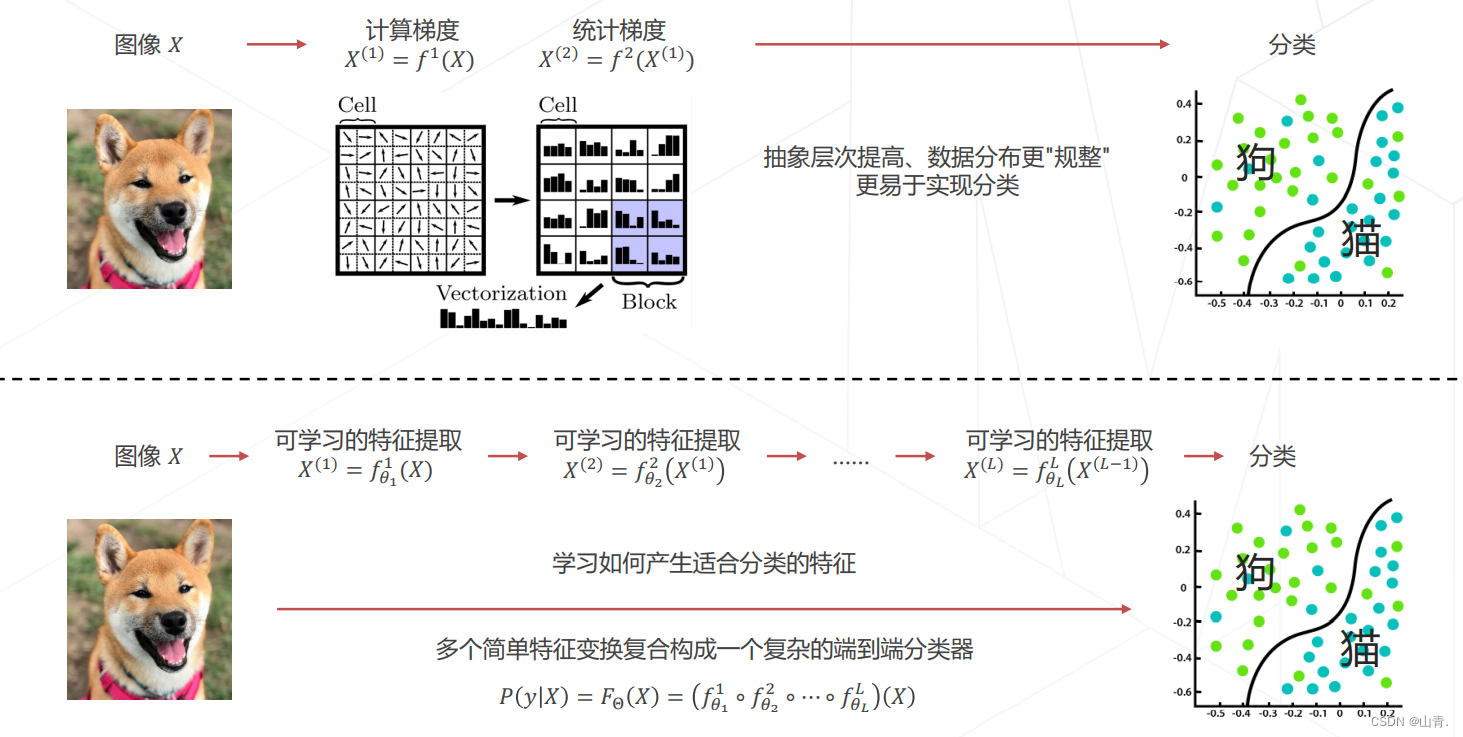

在 2012 年的竞赛中,来自多伦多大学的团队首次使用深度学习方法,一举将错误率降低至 15.3% ,而传统视觉算法的性能已经达到瓶颈,2015 年,卷积网络的性能超越人类
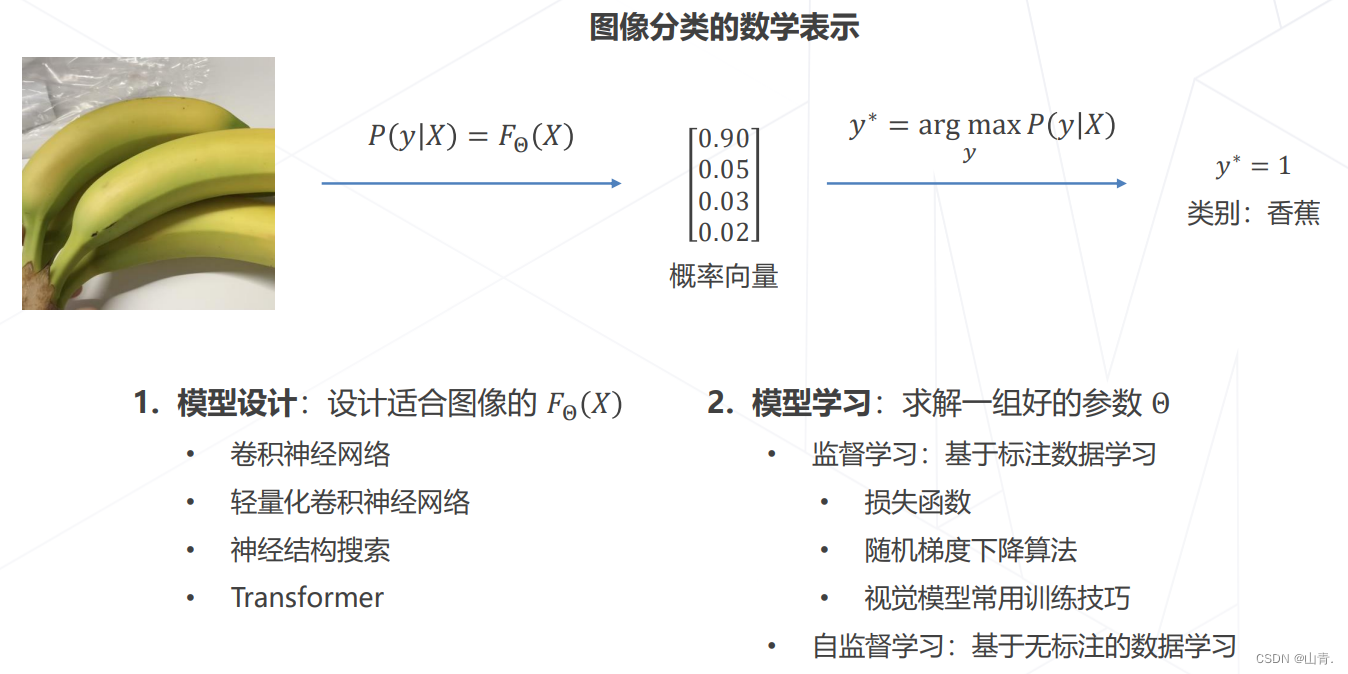
从AlexNet之后,模型在不断加深,也带来了新问题:模型层数增加到一定程度后,分类正确率不增反降

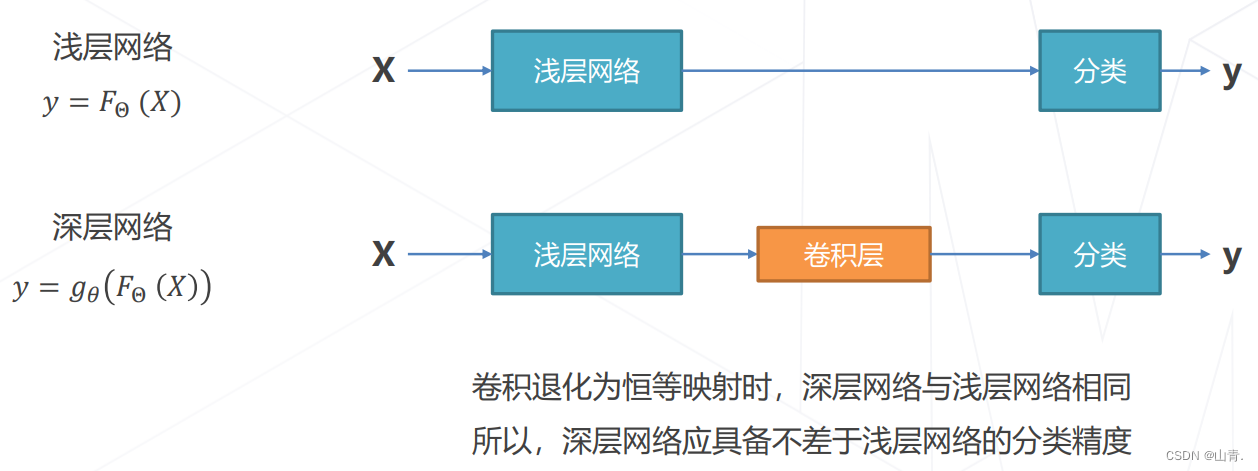
猜想:虽然深层网络有潜力达到更高的精度,但常规的优化算法难以找到这个更优的模型。即,让新增加的卷积层拟合一个近似恒等映射,恰好可以让浅层网络变好一点。
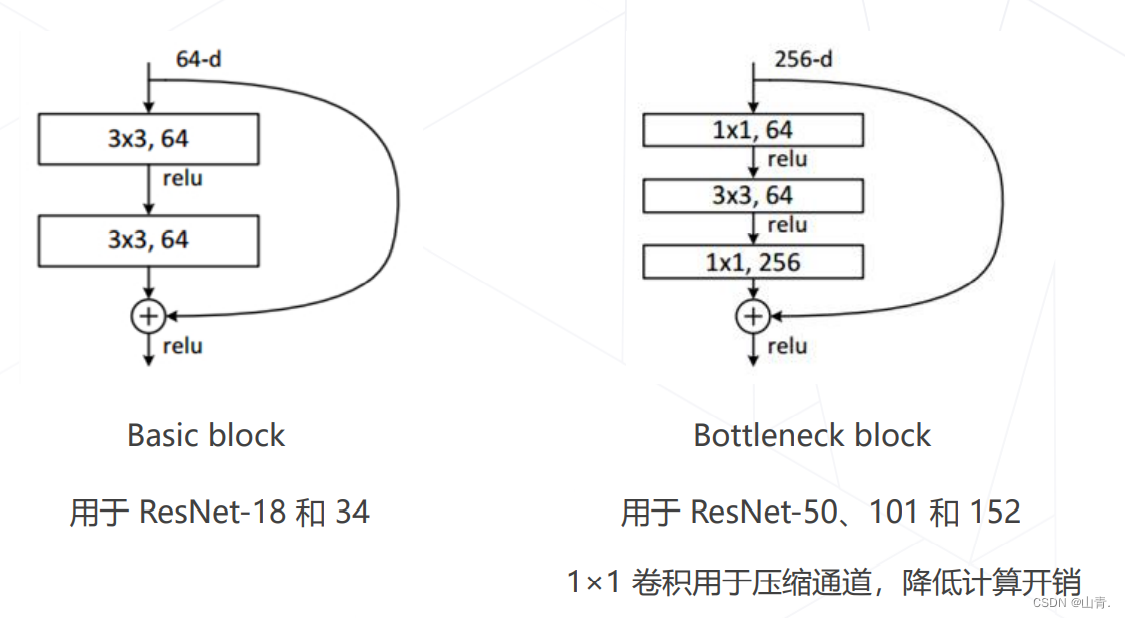
残差建模:让新增加的层拟合浅层网络与深层网络之间的差异,更容易学习梯度可以直接回传到浅层网络监督浅层网络的学习没有引入额外参入,让参数更有效贡献到最终的模型中

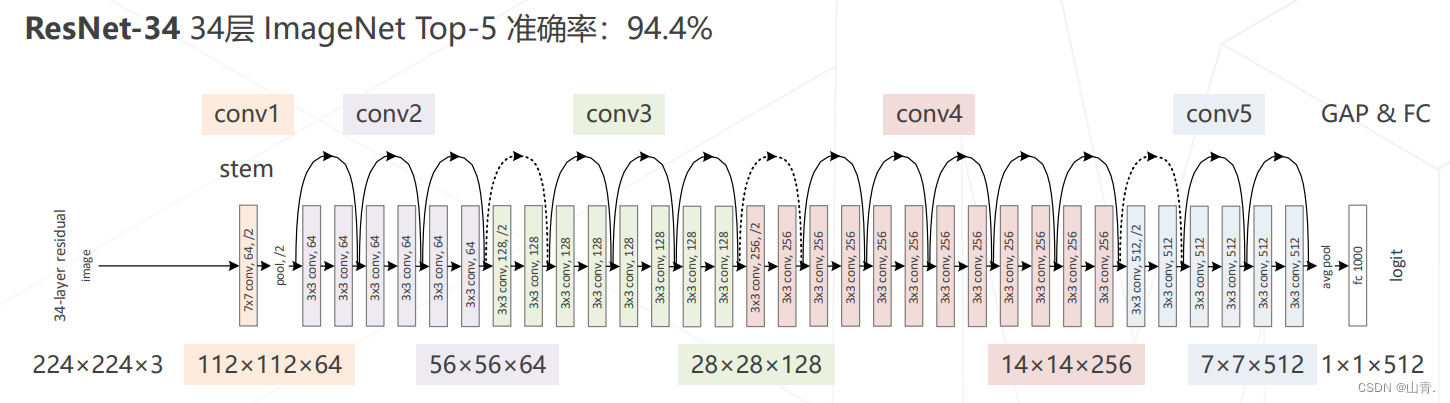
- 5 级,每级包含若干残差模块,不同残差模块个数不同 ResNet 结构
- 每级输出分辨率减半,通道倍增
- 全局平均池化压缩空间维度
- 单层全连接层产生类别概率
更强的图像分类模型
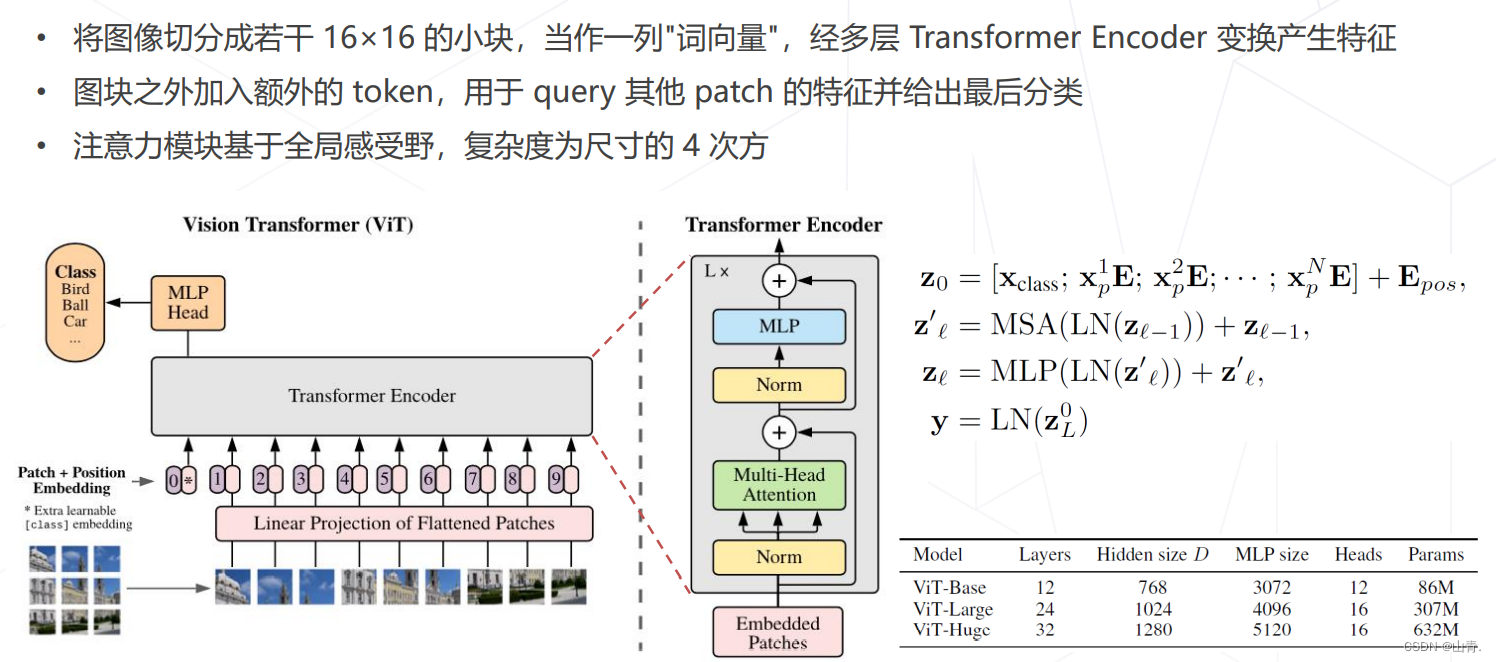
使用 Transformer 替代卷积网络实现图像分类,使用更大的数据集训练,达到超越卷积网络的精度
代表工作:Vision Transformer (2020),Swin-Transformer (2021 ICCV 最佳论文)

实现Attention:
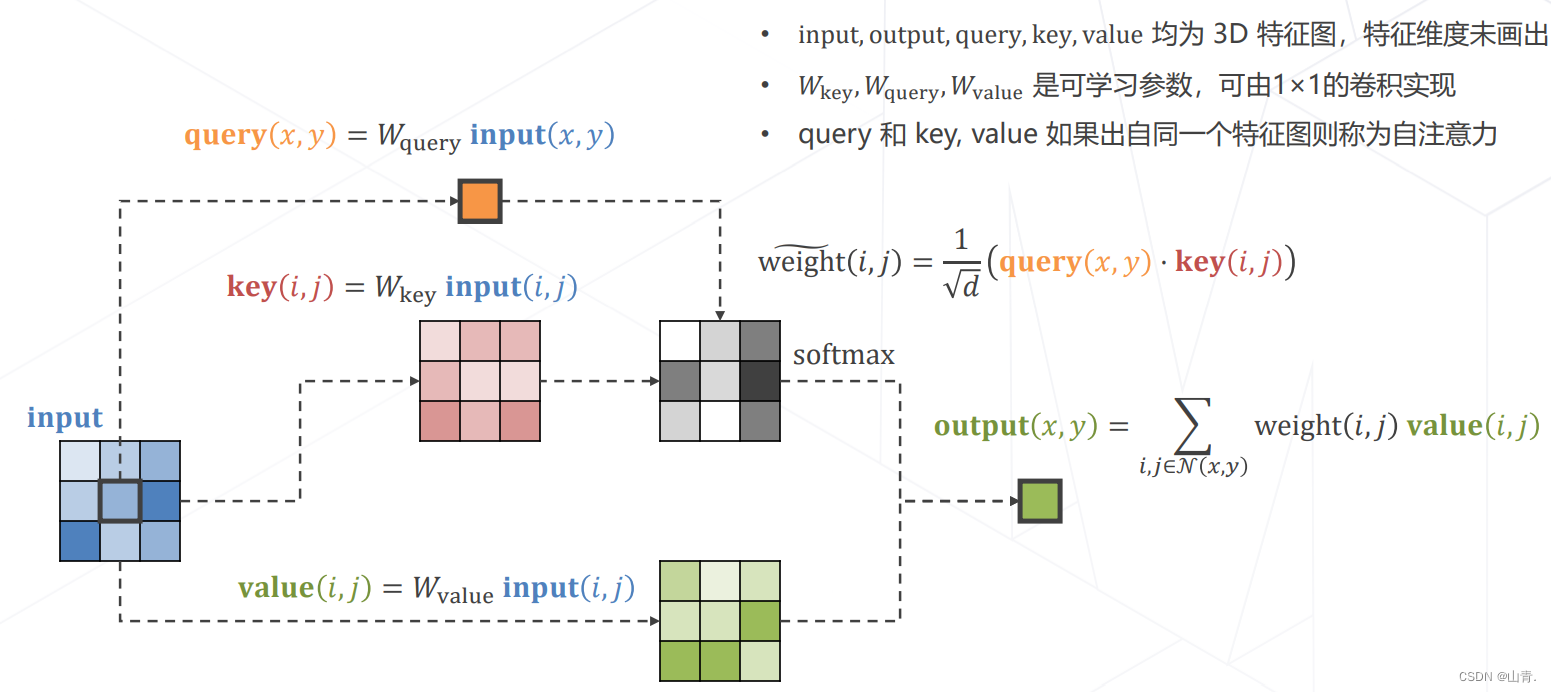
多头注意力 Multi-head (Self-)Attention
使用不同参数的注意力头产生多组特征,沿通道维度拼接得到最终特征,是Transformer Encoder 的核心模块

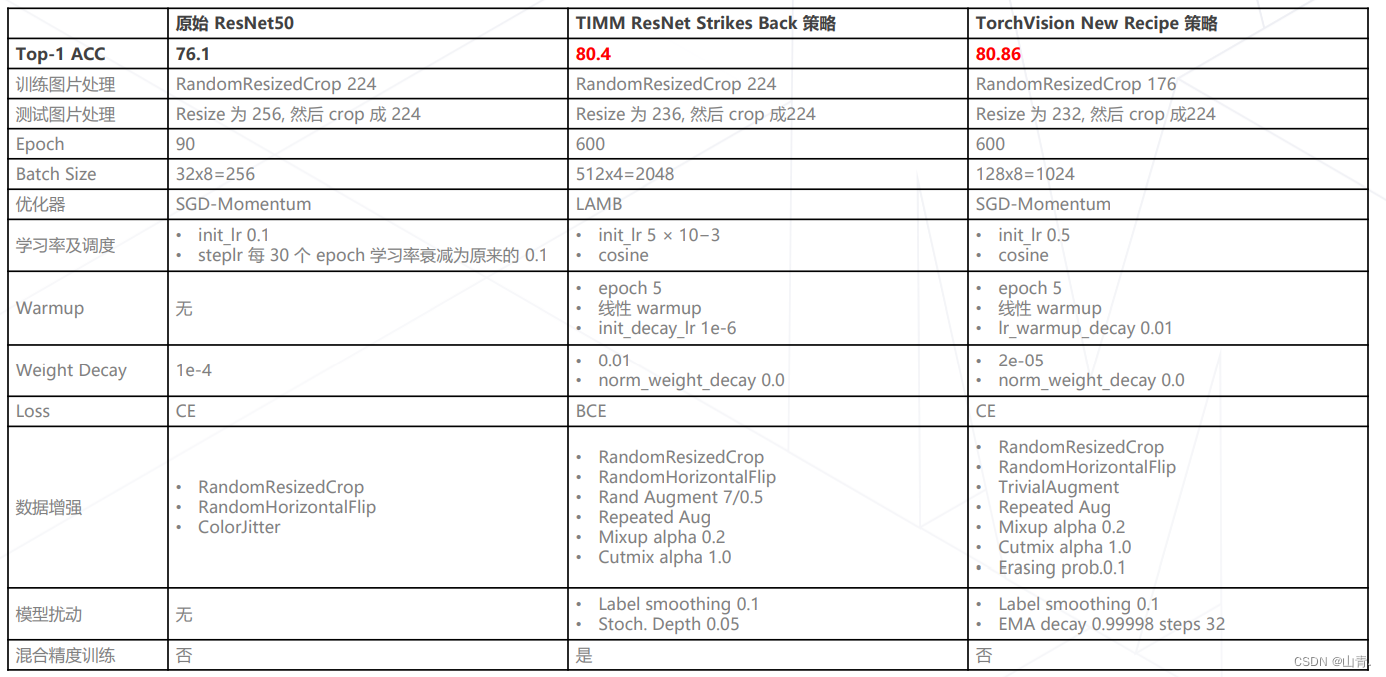
训练技巧
目前学习到这里,剩下的在后续笔记中记录。















 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









