






一、基本介绍
本节课主要是讲了一些图像分类的内容和基础的视觉模型,那我们马上开始吧。
我们做图像分类,首先就是要先明确图像分类是什么——就是给定一张图片,让计算机自己识别图片中的物体是什么,并输出。计算机中输入的图像一般是数字图像,即由许多数字构成的矩阵,每一个数值代表一个像素值,一般灰度图像有单个通道,彩色图像有三个通道(RGB),所以在计算机中,图像的内容是所有的像素整体呈现的结果。
一般的机器学习规则就是:①收集数据→②定义模型→③训练→④预测,对于图像问题也是这个流程,但机器学习有算法效率低的问题,一般只用来处理数据量不大的情况,如果数据超高维度和分布复杂时,机器学习就有些相形见绌。如下图所示:

后面逐渐由特征工程转为特征学习:
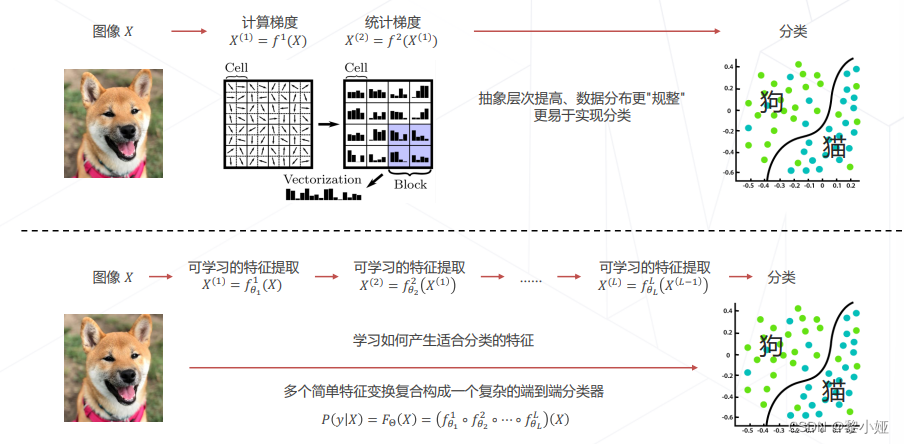
之后随着卷积神经网络和Transformer的出现,进一步发展为层次化的特征实现,提高了运行的效率:

二、卷积神经网络
AlexNet(2012):5个conv、3个fc、60M可学习参数、ReLU激活
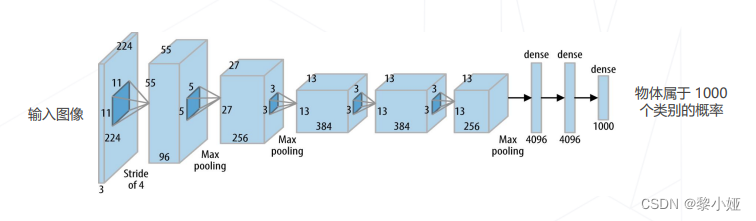
Going Deeper(2012-2014)
VGG19 19层 将卷积拆成3×3的小卷积,可以显著减少参数
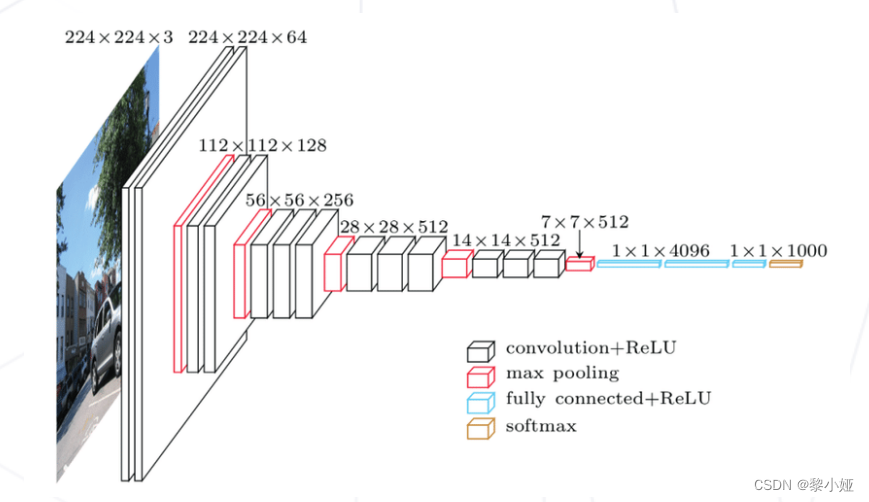
GoogleNet 22层 Inception块堆叠,分类使用单层全连接层
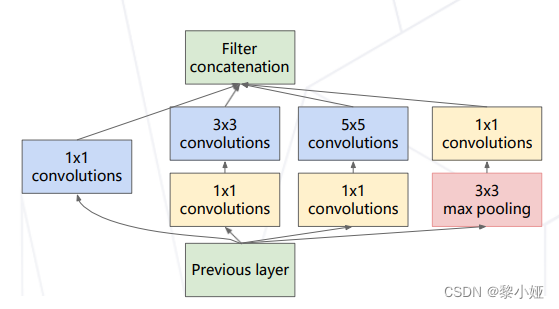

但在图像处理问题不断发展的时候,人们发现当模型层数增加到一定程度后,其实分类的正确率反而会下降,即精度退化问题,如下图所示:

残差学习:在深层网络中,常规的训练其实没法找到很好的模型,故而设想使卷积层拟合一个近似的恒等映射,优化浅层网络。
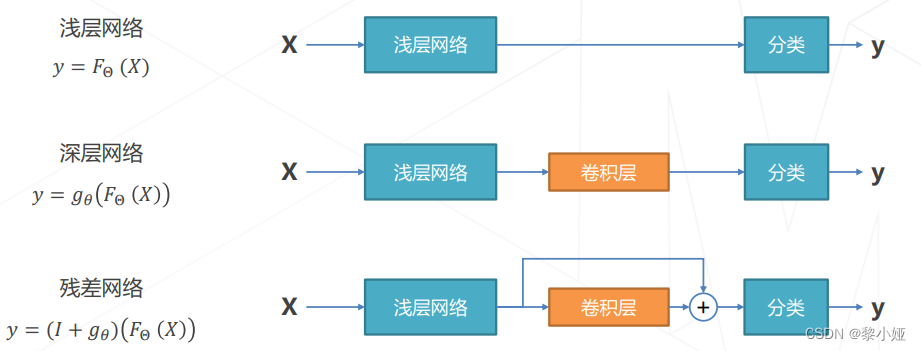
让新增加的层拟合浅层网络与深层网络之间的差异,更容易学习;梯度可以直接回传到浅层网络监督浅层网络的学习;不引入额外参入,让参数更有效贡献到最终的模型
两种残差模块:

ResNet是深浅层模型的集成,表现良好的一个原因也在于集合了多个模型,也因为Loss Surface 更加平滑,更容易收敛到局部/全局最优解;而后面新发展出来ResNet B/C/D、ResNeXt、SEResNet则在不同层面上对残差网络进行改进。
三、图像分类模型进一步发展
神经结构搜索:借助强化学习等方法搜索表现最佳的网络。如NASNet (2017)、MnasNet (2018)、EfficientNet (2019) 、RegNet (2020) 等。
Vision Transformers (2020+):使用 Transformer 替代卷积网络实现图像分类,使用更大的数据集训练,达到超越卷积网络的精度。如:Vision Transformer (2020),Swin-Transformer (2021 ICCV 最佳论文)。
ConvNeXt (2022):将 Swin Transformer 的模型元素迁移到卷积网络中,性能反超 Transformer。
图像分类 & 视觉基础模型的发展:

轻量化卷积神经网络
提出轻量化卷积的原因是在于卷积计算中的可学习参数有:卷积核+偏置

而想要减小计算量,可以从降低通道数和减小卷积核尺寸两个方面入手,下面叙述的几个实现也基本可以归类到这两个大方向。
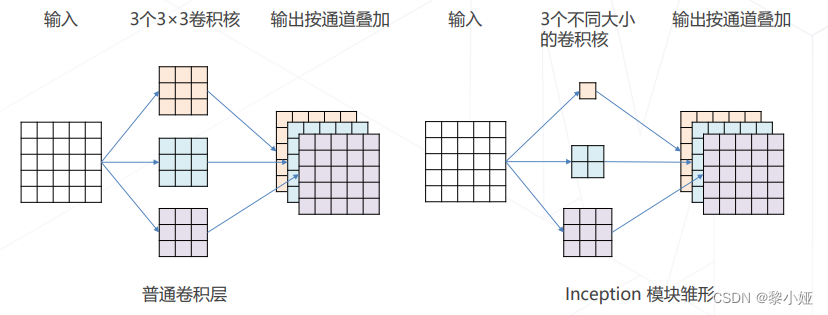
①GoogLeNet [使用不同大小的卷积核]
并不是所有特征都需要同样大的感受野,在同一层中混合使用不同尺寸的特征可以减少参数量。
②ResNet [使用1×1卷积压缩通道数]
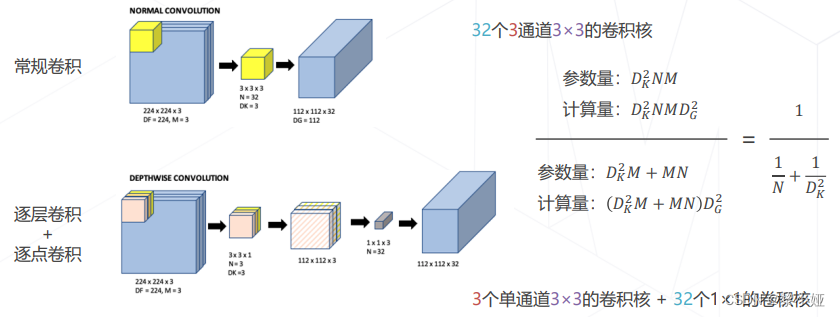
③可分离卷积
将常规卷积分解为逐层卷积和逐点卷积,降低参数量和计算量。
④MobileNet V1/V2/V3 [GoogLeNet轻量版本]
MobileNet V1 使用可分离卷积,只有 4.2M 参数
MobileNet V2/V3 在 V1 的基础上加入了残差模块和 SE 模块
⑤ResNeXt 中的分组卷积
ResNeXt 将 ResNet 的 bottleneck block 中 3×3 的卷积改为分组卷积,降低模型计算量。
可分离卷积为分组卷积的特殊情形,组数=通道数。

Vision Transformers
注意力机制,通俗来讲就是对特征施加权重,权重越大,越重要,并且这个权重是输入的函数,不局限于该特征附近,可以建立远距离关系。
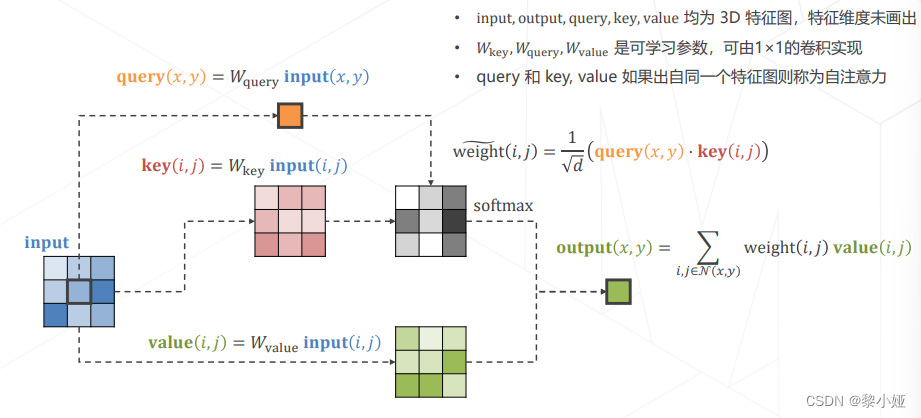
多头注意力
使用不同参数的注意力头产生多组特征,沿通道维度拼接得到最终特征,Transformer Encoder 的核心模块

1D数据上的Attention

2020年提出的Vision Transformer采用NLP的思想那个,将图像切分成若干 16×16 的小块,当作一列"词向量",经多层 Transformer Encoder 变换产生特征;在图块之外加入额外的 token,用于 query 其他 patch 的特征并给出最后分类
2021年ICCV best paper提出的Swin Transformer,首次使用金字塔结构,特征图是直接下采样16倍得到,相对于 Vision Transformer 中直接对整个特征图进行 Multi-Head Self-Attention,Swin Transformer 将特征图划分成了多个不相交的区域(Window),将 Multi-Head Self-Attention 计算限制在窗口内,这样能够减少计算量的,尤其是在浅层特征图很大的时候。
跨窗口传递信息
提出了 Shifted Windows Multi-Head Self-Attention (SW-MSA) 的概念,即第 𝑙 + 1 层的窗口分别向右侧和下方各偏移了半个窗口的位置。如下图所示:

整个Swin Transformer结构

模型学习
![]()
有监督学习和自监督学习两类,主要是根据数据集是否有标注来划分。出现自监督的原因就是数据集非常多但数据标注代价昂贵。
监督学习
已知数据集、损失函数,训练一个模型解决一个最优化问题,常使用交叉熵损失。

针对神经网络,𝐿 为 Θ 的非凸函数,通常采用随机梯度下降算法(SGD)求解;也可以增加动量因子(MomentumSGD)缓解随机梯度下降的波动,避免了局部最小和鞍点的情况。
基于梯度下降训练神经网络的整体流程:

训练技巧的重要性:

学习率与优化器策略
权重初始化,常见的有随机初始化、Xavier方法、Kaiming方法等等。
学习率会对训练过程造成影响,学习率过低训练速度过慢、学习率偏高会始终无法收敛到最优点,所以应当选择合适的学习率。在实际实践中,学习率可以先设定一个较小的学习率,再微调。
常见的学习率策略有:学习率退火、学习率升温,都是训练初始阶段学习率改变,训练稳定之后学习率也稳定。
此外,自适应梯度算法、正则化与权重衰减、早停、模型权重平均也都是比较常见的策略。
数据增强
通过原始比较少的图形数据进行一系列变换,产生复杂的副本,可以增加数据量。
操作有:几何变换、色彩变幻、随机遮挡、组合数据增强、组合图像、标签平滑等。
模型相关策略
Dropout丢弃策略增加了模型训练中的随机性,随机破坏了神经元之间的关联,便于学习独立的特征;
Stochastic Depth随即深度,通过一个随即变换的变量b,对整个 ResBlock 卷积部分做了随机丢弃,其实也是增加了模型训练中的随机性。
自监督学习

常见基于代理任务、对比学习、掩码学习等类型。
由ICCV2015提出的Relative Location、ICML 2020 提出的SimCLR、MAE, CVPR 2022提出的Masked autoencoders等等实际文献体现。其实归根结底就是设计好模型再进行学习,只是自监督是基于无标注的数据进行学习。
四、MMClassification 介绍
首先做个简单介绍,MMClassification是用来做图像分类的工具包,由丰富的模型(上述提到的模型都有)、常用数据集、训练技巧与策略、易用的工具、模块化设计等等。
命令:
推理工具:单张图像推理、测试(单卡&多机多卡)
Getting Started — MMClassification 0.25.0 documentation
训练工具:单卡训练、多卡训练(单机&多机)、任务调度器、从 checkpoint 恢复训练
Getting Started — MMClassification 0.25.0 documentation
使用MIN工具实现训练和测试
MIM 为所有 OpenMMLab 工具提供了统一的命令行接口
流程:下载配置文件和预训练权重→训练→测试
GitHub - open-mmlab/mim: MIM Installs OpenMMLab Packages
OpenMMLab环境构建:
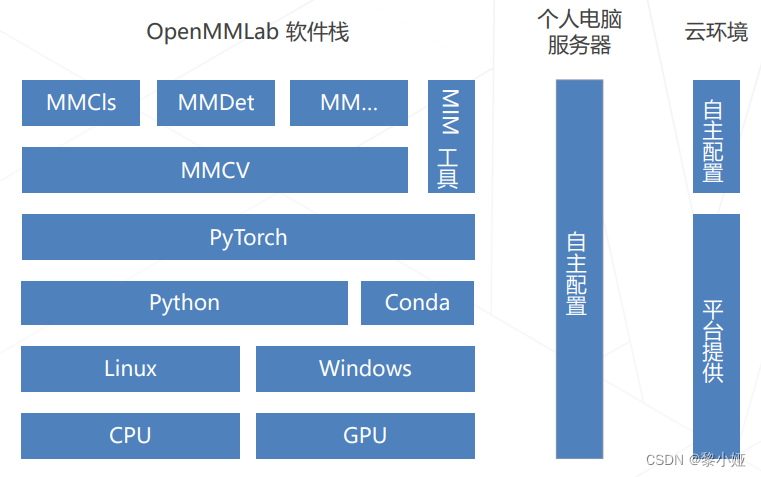
图像分类模型构成:

图像分类模型构建(代码详见官网,这里简述流程)
主干网络→颈部→分类头
数据集构建(代码详见官网,这里简述流程)
加载数据DataLoader→数据集Dataset
定义数据加载流水线
对图像读取并处理(裁剪、缩放、格式转换)
配置学习策略
优化器、学习率、运行器
预训练模型库















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









