






Reducing the Dimensionality of Data with Neural Networks
G. E. Hinton and R. R. Salakhutdinov(28 JULY 2006 VOL 313 SCIENCE)

Abstract
高纬度的数据能被训练好的多层神经网络转化为低纬度的数据,这里的神经网络只需要使用一个小的核心层就能够将高纬度数据重构。梯度下降可以被用在优化这里的神经网络上,但只有当神经网络的初始值接近优秀解的时候梯度下降优化才有效。本文提出了一种初始化权重的方法,使得神经网络能够处理高维数据,在数据降维方面拥有比PCA算法更加优秀的性能。
content
降维可以为分类、可视化、数据传输、输出存储等工作提供助力。在降维领域,PCA算法由于其简单性和实用性被广泛采用。PCA算法会找出最优的部分变量,并且使用这些变量维度来代表原来的高维数据中的数据点,从而达到降维的目的。我们提出了一个非线性的泛PCA网络(nonlinear generalization of PCA)作为转化器进行降维,并且建立了一个类似的解码器网络将降维后的数据进行恢复。
对于上述两个网络,我们先使用随机的权重进行初始化。然后我们使用高维数据和其降维结果作为训练数据,使用梯度下降和反向传播的方法对这两个网络进行训练。整个名为自动解码器(autoencoder)网络结构在Fig1中展示。
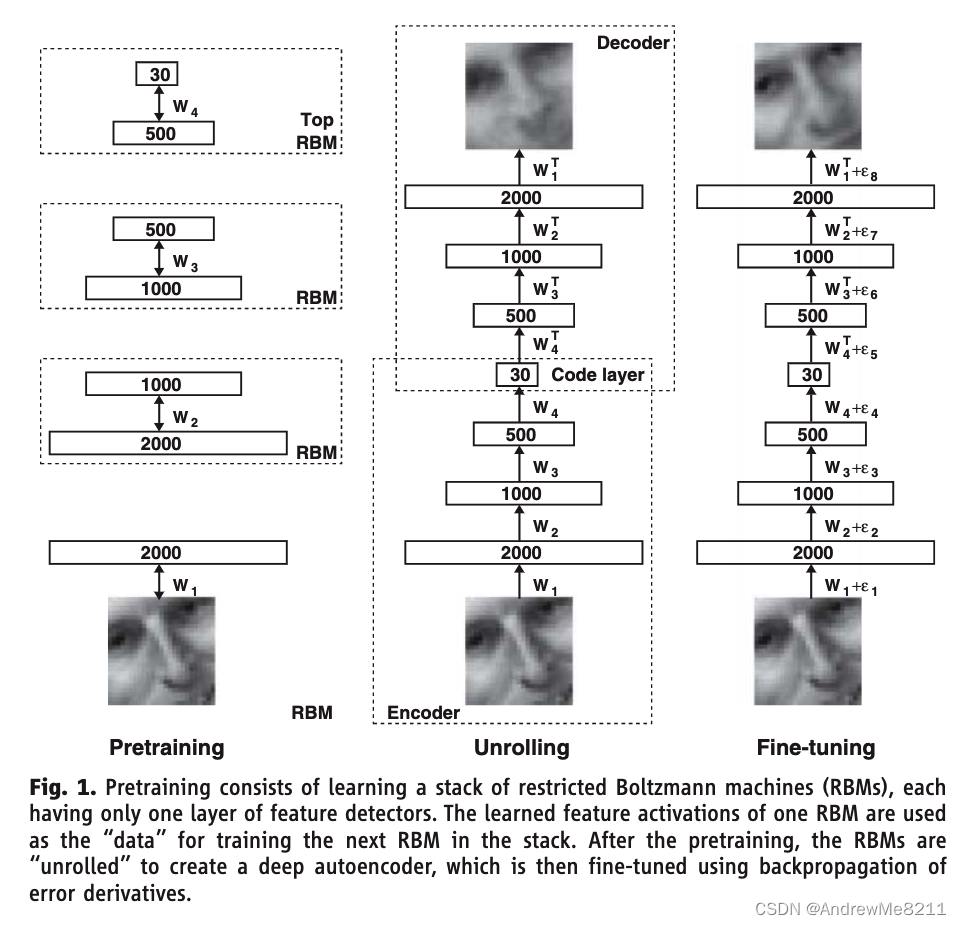
(Fig1:预训练包括训练一系列受限玻尔兹曼机(Restricted Boltzmann Machines,RBM),每一个RBM仅含有一层特征学习层。一个RBM学习到的特征会被用作下一个RBM的训练输入。训练好一系列RBM之后,我们将其展开,构建一个深度自动编码器,这个编码器使用反向传播和梯度进行权重训练。)
训练拥有2到4个隐藏层的非线性自动编码器的权重并非易事。当初始权重太大时,自动编码器常常找到较差的局部最小值。当初始权重过小时,前几层的梯度就会非常小,使得训练自动解码器后续的多个隐藏层变得基本不可能。当初始值接近一个优秀的解时,梯度下降算法工作良好,但是想要找到这样的初始值则需要一种非常不同的算法,能够一次学习一层的特征。我们为二进制数据提出的这种“预训练”过程,能够将数据转化为实数范围的数据。这一过程在多种多样的数据集中展示了良好的运行效果。
使用一个两层的RBM网络就可以对由二进制组成的向量进行建模,其中随机的二进制像素一一对应的(symmetrically weighted connections,这样翻译不知道对不对)连接着随机的二进制特征侦测层(stochastic,binary feature detectors)。这里的像素则相当于经典RBM中的可视单元(“visible” units),而侦测层相当于经典RBM中的隐藏单元(“hidden” units)。可视单元和隐藏单元二者之间关键的连接模块(A joint configuration)
(
v
,
h
)
(\textbf{v}, \textbf{h})
(v,h)由下面的能量计算公式给出:
E
(
v
,
h
)
=
−
∑
i
∈
p
i
x
e
l
s
b
i
v
i
−
∑
j
∈
f
e
a
t
u
r
e
s
b
j
h
j
−
∑
i
,
j
v
i
h
j
w
i
j
E(\textbf{v}, \textbf{h})=-\sum_{i\in pixels}b_iv_i - \sum_{j\in features}b_jh_j-\sum_{i,j}v_ih_jw_{ij}
E(v,h)=−i∈pixels∑bivi−j∈features∑bjhj−i,j∑vihjwij
其中
v
i
v_i
vi和
h
j
h_j
hj是像素
i
i
i和特征
j
j
j的状态,
b
i
,
b
j
b_i,b_j
bi,bj是其对应的偏置。
w
i
j
w_{ij}
wij是
i
j
ij
ij之间的权重。网络为每一个可能的图像赋予一个概率,如(8)中所解释的一样(注:这里的(8)是要在science online上才能看到,所以暂时没办法知道这到底是个啥)。一个训练图像的概率能通过调整上述权重和偏置,从而降低该图片的能量值来提高,同时网络会提高类似的和虚构的图像的能量值,从而使得模型更加喜欢真实的图片。
输入一张训练图像,刚开始的时候,图形的第
j
j
j个特征的二进制值
h
j
h_j
hj被设置为1,其概率为:
σ
(
b
j
+
∑
i
v
i
w
i
j
)
,
σ
(
x
)
=
1
1
+
e
−
x
\sigma{(b_j+\sum_{i}v_iw_{ij})},\sigma(x)=\frac{1}{1+e^{-x}}
σ(bj+i∑viwij),σ(x)=1+e−x1
其中,
b
j
b_j
bj是特征
j
j
j的偏置,
v
i
v_i
vi是像素
i
i
i的状态,
w
i
j
w_{ij}
wij是特征
j
j
j和像素
i
i
i之间的权重。
一旦特征被选中作为隐藏单元时,我们需要设置每一个二进制像素状态
v
i
v_i
vi为1,并且赋予其概率为:
σ
(
b
i
+
∑
j
h
j
w
i
j
)
,
σ
(
x
)
=
1
1
+
e
−
x
\sigma{(b_i+\sum_{j}h_jw_{ij})},\sigma(x)=\frac{1}{1+e^{-x}}
σ(bi+j∑hjwij),σ(x)=1+e−x1
此时隐藏层单元的状态会被更新,从而使得这些隐藏层能代表降维后的图像特征(represent features of the confabulation)。权重的变化量由下式给出:
△
w
i
j
=
λ
(
<
v
j
h
j
>
d
a
t
a
−
<
v
j
h
j
>
r
e
c
o
n
)
\triangle w_{ij}=\lambda(<v_jh_j>_{data}-<v_jh_j>_{recon})
△wij=λ(<vjhj>data−<vjhj>recon)
其中,
λ
\lambda
λ是学习率,
<
v
j
h
j
>
d
a
t
a
<v_jh_j>_{data}
<vjhj>data是模型训练过程中像素
i
i
i和特征
j
j
j同时出现的次数在总次数中的比值(
<
v
j
h
j
>
d
a
t
a
<v_jh_j>_{data}
<vjhj>data is the fraction of times that the pixel i and feature detector j are on together when the feature detectors are being driven by data),
<
v
j
h
j
>
r
e
c
o
n
<v_jh_j>_{recon}
<vjhj>recon是降维阶段像素
i
i
i和特征
j
j
j对应的比值。(
<
v
j
h
j
>
r
e
c
o
n
<v_jh_j>_{recon}
<vjhj>recon is the corresponding fraction for confabulations.)。对于偏置参数,则采用了和上述方法类似的简化版的学习规则。这种学习方法效果很好,即使它不精确的遵守(6)中的训练数据的对数概率。(The learning works well even though it is not exactly following the gradient of the log probability of the training data (6).)
单层的二进制特征不是最好的对图像建模的结构。在学习了一层特征后,当特征层被数据驱动时,我们可以将其训练结果放入下一层特征中进行学习。具体而言,第一层特征层的结果将会变成下一个RBM的可视层进行学习,这种层层叠叠的学习方式能被重复许多次。实验结果表明,当每一层的特征数量不减少并且权重初始化合理时,添加一个新的层常常会使得模型对训练数据计算的对数概率的下限上升。这个限制在更高层有着更少的特征时不会出现,但是这种一层层的训练算法并不是一个很高效的预训练深度自动编码器权重的算法。每一层的特征都会学习到前一层像素和特征之间很强的相关性。因此对于不同的数据集,这是一个逐渐揭示其中低纬度非线性结构的有效途径。
在预训练了多层特征后,模型被展开,从而构建出了编码网络和解码网络,这两个网络一开始都是使用了相同的权重参数。在接下来的全局微调阶段中,我们使用确定性的实数概率值与反向传播过程替换掉了一开始的随机权重赋值过程,通过调整全局参数对模型进行优化。
对于连续的数据,第一个RBM的隐藏层单元是二进制的,但是可视单元被使用高斯噪声的线性单元替换。如果此处的高斯噪声存在单位方差,则对于隐藏单元的随机升级规则不变,而对于可视单元
i
i
i的升级过程则变成单位方差和均值为
b
i
+
s
u
m
j
h
j
w
i
j
b_i+sum_{j}h_jw_{ij}
bi+sumjhjwij的高斯过程。
在我们所有的实验中,每一个RBM的可视单元都是在[0,1]内的真值。当训练之后更高层的RBM时,可视单元被设置为前一层RBM隐藏单元的概率值,但除开最顶层的RBM以外的每一个RBM的隐藏层都有二进制随机值。顶层的RBM的隐藏单元具有随机的真值状态,这一状态由单位方差高斯过程决定。其中,高斯过程的均值由该RBM的可视单元决定。这使得低纬度的数据更好的使用连续变量,从而促进PCA的比较。预训练和微调的细节在(8)中展示。
为了证明我们的预训练算法能够很好的训练深度网络,我们训练了一个非常深的自动编码器,使用了人造的曲线图像数据集。这些数据集中的曲线由二维平面上随机选取的点组成(8)。对于这个数据集,我们已知其内在的重要的维度,并且像素之间的关系以及用于生成曲线的6个数字之间的关系是高度非线性的。每个像素的值在0到1之间,这些值非常具有非高斯性质(The pixel intensities lie between 0 and 1 and are very non-Gaussian),因此我们在自动编码器中使用了二进制输出单元,并且在训练过程中我们最小化了交叉熵误差:
[
−
∑
i
p
i
log
p
i
^
−
∑
i
(
1
−
p
i
)
log
(
1
−
p
i
^
)
]
[-\sum_i p_i \log \hat{p_i}-\sum_i(1-p_i)\log(1-\hat{p_i})]
[−i∑pilogpi^−i∑(1−pi)log(1−pi^)]
其中,
p
i
p_i
pi是像素
i
i
i的值(intensity),
p
i
^
\hat{p_i}
pi^是像素
i
i
i重构后的值(intensity)。
自动编码器包含一个编码器,这个编码器有着
(
28
×
28
)
−
400
−
200
−
100
−
50
−
25
−
6
(28\times 28)-400-200-100-50-25-6
(28×28)−400−200−100−50−25−6的结构,同时还有一个与编码器对称的解码器。编码层的6个单元都是线性的,其他的单元都是二进制的。网络使用了20000张图片进行训练,并且在10000张图片上进行了测试。我们的自动编码器发现了如何将784像素大小的图片转化为6个数字,并且能够通过这6个数字重构原来的图片(Fig2A)并且达到最好的效果。PCA算法的效果就要差得多。
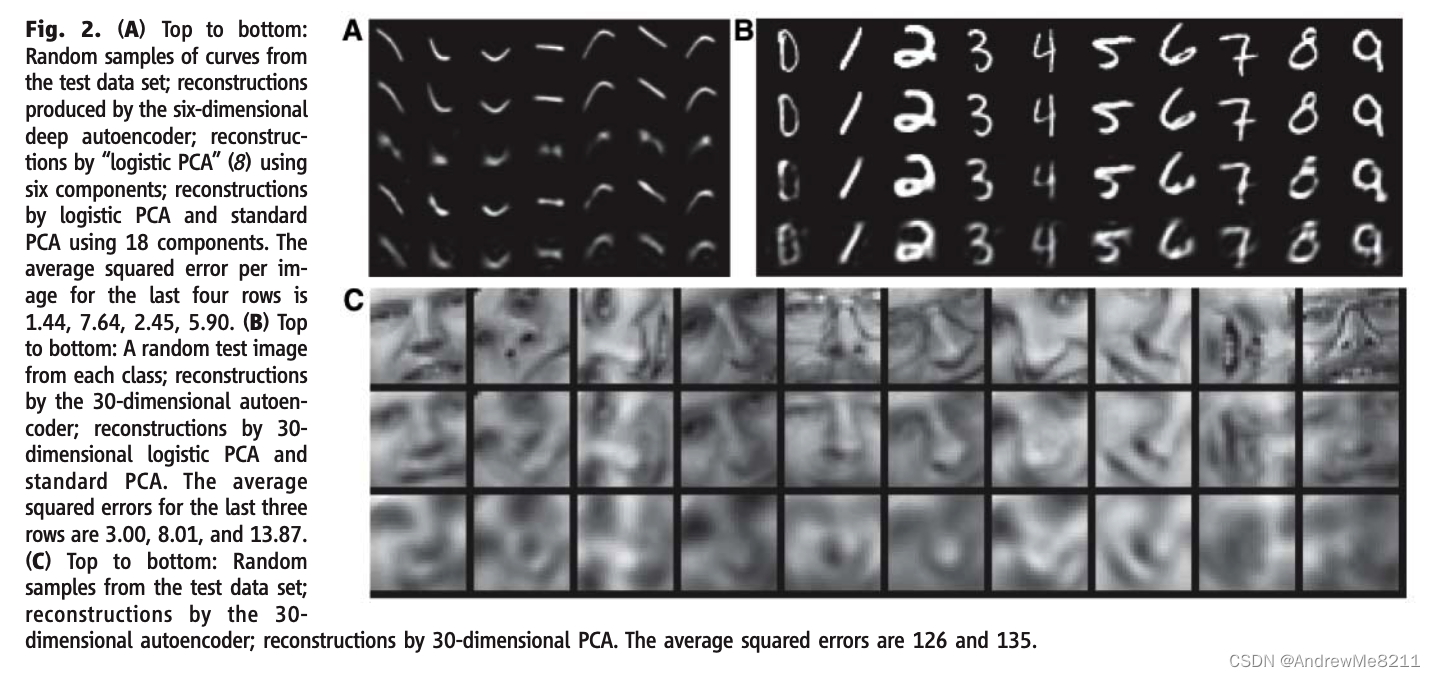
(Fig2A:从上到下依次是:随机的测试集曲线、6维度深度自动编码器重建的曲线、6维度“二值化PCA”重建的曲线、使用18个组成部分和二值化PCA和标准PCA重建的曲线。这四种方法的方差分别为1.44、7.64、2.45、5.90)
在没有预训练的情况下,深度自动编码器常常将孙连数据的平均值重构出来。只有一个隐藏层的浅的自动编码器能够在没有预训练的情况下进行学习,但是预训练能很大程度的减少训练的时间。当参数的数量相同时,相比起浅的编码器而言,深度自动编码器能使用更低的误差重建图片,但这种优势在参数变多的情况下消失。
接下来我们使用结构为
784
−
1000
−
5000
−
250
−
30
784-1000-5000-250-30
784−1000−5000−250−30的自动编码器来提取MNIST数据集中的所有手写数字的降维表示(code)。我们使用的matlab代码能在(8)中找到。和之前类似,除了编码层的30个单元,其他的单元都是二进制的。在所有的60000张图片上训练后,自动编码器在10000张图片上进行了测试,实现了比PCA好得多的重构效果(Fig2B)。
(Fig2B:从上到下依次是:每一类数字的测试图片、30维度的自动编码器的重构图片、30维度的二进制PCA和标准PCA的重构图片。其方差分别为3.00、8.01、13.87)
同时,一个两个维度的自动编码器在数据可视化上的效果比使用数据的两个主要维度可视化的效果要好(Fig3)。
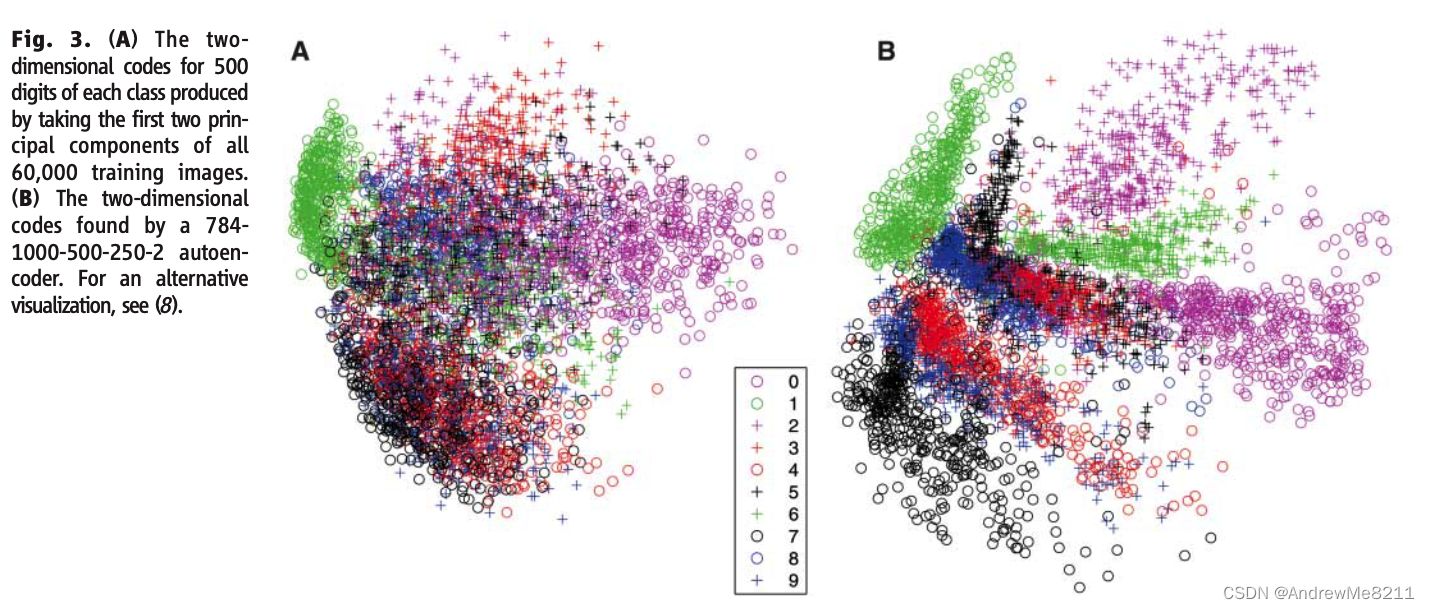
(Fig3:A图是使用所有的60000张图片的两个主要维度进行可视化的结果;B图是使用结构为
784
−
1000
−
5000
−
250
−
2
784-1000-5000-250-2
784−1000−5000−250−2的自动编码器进行的可视化结果)
我们同时还是用了结构为
625
−
2000
−
1000
−
500
−
30
625-2000-1000-500-30
625−2000−1000−500−30的自动编码器,使用线性的输入单元,来探究Olivetti face data set中的灰度人脸图像(12)。在实验中,自动编码器的表现显著优于PCA(Fig2C)。
(Fig2C:从上到下依次是:原数据集的图片、使用30维度的自动编码器重构的图片、使用30维度的PCA进行重构的图片。方差分别为126和135)
当在文档上训练时,自动编码器能够计算出能够快速检索文档的编码。我们提取了2000个基本词干,使用向量的方式表示了804414篇文档,并且在此基础上使用一半的数据训练了一个结构为
2000
−
500
−
250
−
125
−
10
2000-500-250-125-10
2000−500−250−125−10的自动编码器,使用交叉熵误差作为误差公式进行训练和微调。最后的10个编码单元是线性的,剩下的隐藏单元是二进制的。我们使用两个编码之间的余弦值作为衡量相似性的度量时,自动编码器的效果显著优于LSA(14)(Fig4)。
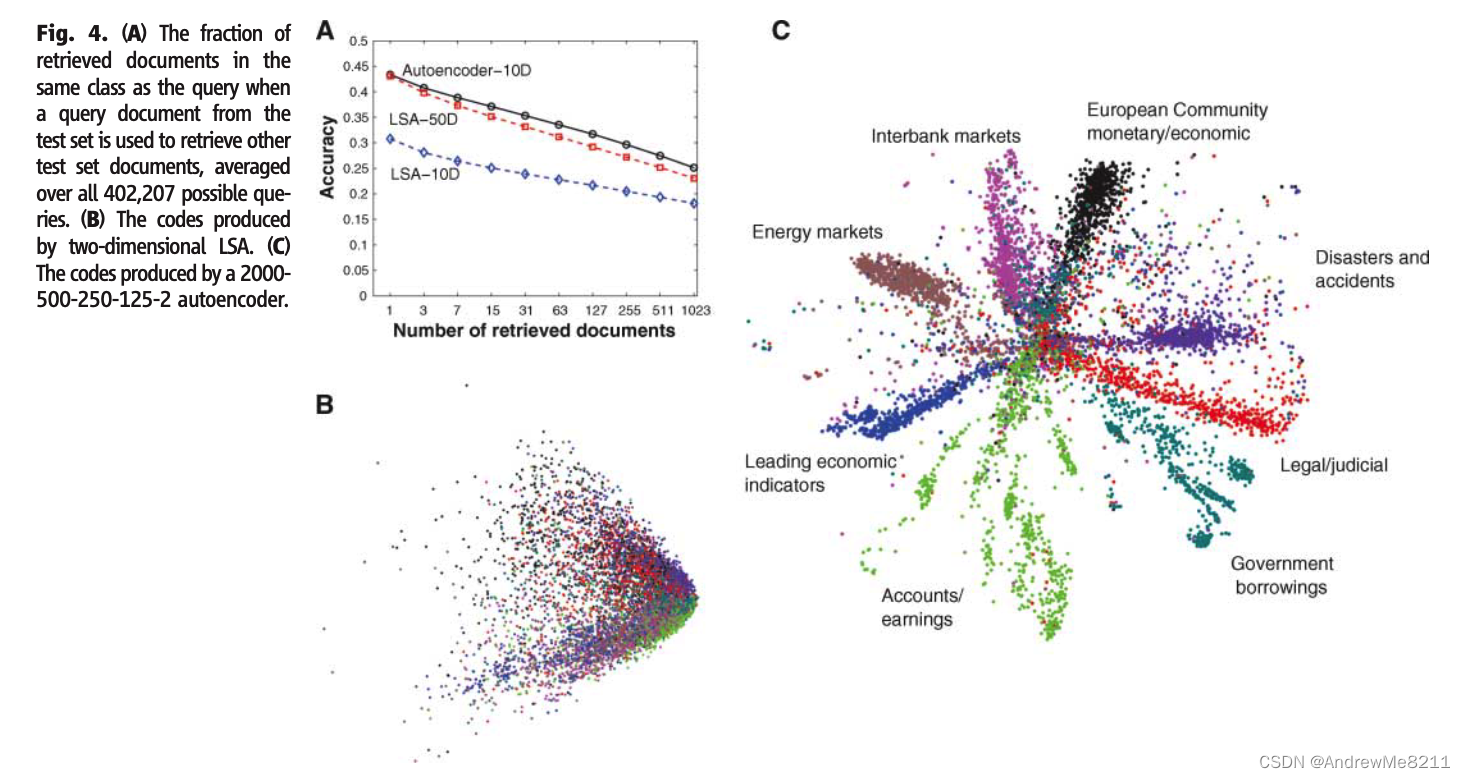
(Fig4:A图表示能被正确编码和索引的文献所占总文献的比例数、B图是LSA降维的可视化结果、C图是自动编码器的可视化结果。)
自动编码器也具有比最近提出的非线性降维算法local linear embedding更有效(15)。
层与层相连接的预训练方法能够被用在分类和回归问题上。在MINST手写数字数据集的一个更加广为人知的版本中,随机初始化的反向传播算法能达到1.6%的错误率,SVM能达到1.4%的错误率。当使用了结构为
784
−
500
−
500
−
2000
−
10
784-500-500-2000-10
784−500−500−2000−10的网络后,反向传播算法使用了最陡峭的收敛速率和一个很小的学习率,在这个数据集上达到了1.2%的错误率(8)。预训练有助于归纳总结,因为它能保证大部分权重中的信息来源于图像的建模。标签中的非常有限的信息仅仅用来细微调整预训练中获取的权重。
很显然,自从1980年代以来,对深度自动编码器进行反向传播算法成为了非常高效的非线性降维算法。当然这一切的前提是计算机够快,数据集够大,并且初始值够接近一个优秀的解。现在这三个条件都满足了。和非参数方法(15,16)不同,自动编码器能给每个方向的数据和编码空间计算映射。并且这种自动编码器能被应用到非常大的数据集中,因为预训练和微调过程的时间开销和空间开销都随着训练集的样本数量线性增长。
References and Notes
- D. C. Plaut, G. E. Hinton, Comput. Speech Lang. 2, 35 (1987).
- D. DeMers, G. Cottrell, Advances in Neural Information Processing Systems 5 (Morgan Kaufmann, San Mateo, CA, 1993), pp. 580–587.
- R. Hecht-Nielsen, Science 269, 1860 (1995).
- N. Kambhatla, T. Leen, Neural Comput. 9, 1493 (1997).
- P. Smolensky, Parallel Distributed Processing: Volume 1: Foundations, D. E. Rumelhart, J. L. McClelland, Eds. (MIT Press, Cambridge, 1986), pp. 194–281.
- G. E. Hinton, Neural Comput. 14, 1711 (2002).
- J. J. Hopfield, Proc. Natl. Acad. Sci. U.S.A. 79, 2554 (1982).
- See supporting material on Science Online.
- G. E. Hinton, S. Osindero, Y. W. Teh, Neural Comput. 18, 1527 (2006).
- M. Welling, M. Rosen-Zvi, G. Hinton, Advances in Neural Information Processing Systems 17 (MIT Press, Cambridge, MA, 2005), pp. 1481–1488.
- The MNIST data set is available at http://yann.lecun.com/ exdb/mnist/index.html.
- The Olivetti face data set is available at www. cs.toronto.edu/ roweis/data.html.
- The Reuter Corpus Volume 2 is available at http:// trec.nist.gov/data/reuters/reuters.html.
- S. C. Deerwester, S. T. Dumais, T. K. Landauer, G. W. Furnas, R. A. Harshman, J. Am. Soc. Inf. Sci. 41, 391 (1990).
- S. T. Roweis, L. K. Saul, Science 290, 2323 (2000).
- J. A. Tenenbaum, V. J. de Silva, J. C. Langford, Science290, 2319 (2000).
- We thank D. Rumelhart, M. Welling, S. Osindero, and S. Roweis for helpful discussions, and the Natural Sciences and Engineering Research Council of Canada for funding. G.E.H. is a fellow of the Canadian Institute for Advanced Research.
Supporting Online Material
www.sciencemag.org/cgi/content/full/313/5786/504/DC1
Materials and Methods
Figs. S1 to S5
Matlab Code
20 March 2006; accepted 1 June 2006
10.1126/science.1127647


















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









