







目录
一. 前言
我的上一篇博客中写道,顺序表有下面几个典型的缺陷:
- 顺序表每次扩容都要付出一定的代价,而为了避免频繁扩容,每次扩容一般都是扩到原容量的两倍,这很容易造成空间浪费。
- 若要在顺序表起始位置或顺序表中某个位置插入或删除数据,则需要对一串数据进行移动,效率不高。
针对顺序表的上述缺陷,链表被设计了出来。本文对单链表的相关知识进行了讲解,在第二章介绍了什么是链表以及单链表的基本结构,第三章介绍了但单链表的相关接口函数,第四章介绍了几个典型的单链表问题,最后一章对链表的优缺点进行的总结。
二. 什么是单链表
链表和顺序表都是线性表的一种,但是与顺序表不同,链表中数据的存储不是连续的。链表是通过在每个节点存储下一个节点的地址,从而找到下一个数据的。单链表的逻辑图(想象出来的抽象表达)和物理图(单链表实际在内存中的存储情况)分别间图2.1和2.2。
定义单链表节点:(将其类型重定义为SLTNode)
typedef struct SListNode
{
int data; //单链表中存储的数据
struct SListNode* next; //下一个节点
}SLTNode;


三. 单链表的接口函数
3.1 单链表数据打印函数PrintSList
从头结点开始,通过每个节点的next指针遍历每一个节点,依次打印每个节点中的数据即可。
PrintSList函数代码:
void PrintSList(SLTNode* phead) //链表打印函数
{
SLTNode* cur = phead; //当前的节点位置
while (cur != NULL)
{
printf("%d -> ", cur->data);
cur = cur->next; //通过指针找到下一节点的位置
}
printf("NULL\n"); //打印单链表结束标志(NULL)
}3.2 尾插数据函数SListPushBack
在单链表尾部插入数据,要分两种情况进行讨论
- 单链表中有数据,此时要进行的操作依次为:创建一个新的单链表节点 -> 让该节点存储要尾插的数据,该节点的指针指向NULL -> 原来的单链表尾结点的指针变量的值由NULL改为新节点的地址。
- 单链表中无数据(原来的phead为NULL),此时应当将新创建的节点定义为头结点,即将phead的值更改为新节点的地址。
SListPushBack函数代码:
//pphead为原链表表头指针对应的二级指针
//这里传二级指针是为了在函数内部更改一级指针phead(指向链表头)的值
//x为要尾插的数据
void SListPushBack(SLTNode** pphead, int x)
{
SLTNode* cur = *pphead;
SLTNode* newcode = (SLTNode*)malloc(sizeof(SLTNode)); //创建新节点
if (NULL == newcode)
{
perror("nawcode malloc");
exit(-1);
}
newcode->data = x;
newcode->next = NULL; //新节点指向NULL
if (*pphead == NULL)
{
//如果原单链表无数据,新节点即为表头
*pphead = newcode;
}
else
{
//查找最后一个链表节点
while (cur->next != NULL)
{
cur = cur->next;
}
cur->next = newcode; //链表最后一个节点指向新节点
}
}3.3 头插数据函数SListPushFront
在单链表表头前面插入数据,要进行的操作依次为:创建一个新节点 -> 让这个新节点存储待插入的数据并且指向原来的表头 -> 将单链表表头更改为这个新节点。
SListPushFront函数代码:
void SListPushFront(SLTNode** pphead, DataType x)
{
//生成新节点newcode
SLTNode* newcode = (SLTNode*)malloc(sizeof(SLTNode));
if (NULL == newcode) //检验动态空间是否申请成功
{
printf("newcode creat fail\n");
return;
}
newcode->data = x;
newcode->next = *pphead; //插到头部的节点指向原来的起始节点
//将单链表表头改为新节点
*pphead = newcode;
}3.4 尾删数据函数SListPopBack
在单链表的尾部删除一个数据,要分三种情况进行讨论:
- 单链表中没有数据:不进行任何操作(或报错)
- 单链表中有多余一个的数据:先找到链表最后一个节点和倒数第二个节点,释放最后一个节点的内存空间,让倒数第二个节点指向NULL。
- 单链表中只有一个数据:进行尾删后单链表变为空,将表头指针phead置为NULL
SListPopBack函数代码:
void SListPopBack(SLTNode** pphead)
{
assert(pphead); //检验单链表中是否存在数据
if ((*pphead)->next == NULL) //顺序表中只有一个数据
{
//删除数据
//将指向链表起始节点的指针置为空指针
free(*pphead);
*pphead = NULL;
}
else //单链表中有两个及以上数据
{
SLTNode* prev = NULL; //记录单链表前一个节点位置,方便置NULL
SLTNode* cur = *pphead;
while (cur->next != NULL)
{
//寻找最后一个节点和倒数第二个节点
prev = cur;
cur = cur->next;
}
free(cur); //释放最后一个节点的内存空间
cur = NULL;
prev->next = NULL; //倒数第二个节点指向NULL
}
}3.5 头删数据函数SListPopFront
头删数据,也要两种种情况讨论:
- 单链表中原本无数据:不进行任何操作(报错)
- 单链表中有数据: 将表头改为第二个节点(若链表中原本仅有一个节点则链表变为空,即phead = NULL)-> 释放掉头结点的内存空间
SListPopFront函数代码:
void SListPopFront(SLTNode** pphead)
{
assert(*pphead); //检验顺序表中是否存有数据
SLTNode* cur = *pphead;
*pphead = cur->next;
free(cur);
cur = NULL;
}3.6 数据查找函数SListFind
该函数实现的功能为在单链表中查找某个特定数据x首次出现的位置(地址),并将这个地址返回,若单链表中没有x就返回NULL。只需依次比较每个节点的data值是否与x相同即可,相同就返回这个节点的地址。
SListFind函数代码:
SLTNode* SListFind(SLTNode* phead, DataType x)
{
SLTNode* cur = phead; //当前节点位置
while (cur != NULL)
{
//比较节点中的数据是否与x相同
//相同就返回这个节点的地址,不同就去检索下一个节点
if (cur->data == x)
{
return cur;
}
else
{
cur = cur->next;
}
}
//单链表中没有x就返回空指针
return NULL;
}3.7 在指定位置插入数据函数SListInsert
该函一般配合SListFind函数使用,先在链表中查找到某个特定的值,在这个特定值之前插入数据x,取插入数据的位置为pos。该函数的具体实现分两种情况进行讨论:
- pos为单链表表头:等同于进行头插操作
- pos为单链表除表头之外的位置:断开pos位置前面的节点与这个节点之间的连接,使pos之前的节点连接到新创建的节点,新节点连接到pos后面那个位置的节点(详见图3.1)。

SListInsert函数代码:
void SListInsert(SLTNode** pphead, SLTNode* pos, int x)
{
//生成新节点,存储x
SLTNode* newcode = (SLTNode*)malloc(sizeof(SLTNode));
if (NULL == newcode)
{
printf("malloc fail\n");
return;
}
newcode->data = x;
newcode->next = NULL;
if (*pphead == pos)
{
//在第一个数据前插入数据,相当于头插
newcode->next = *pphead;
*pphead = newcode;
}
else
{
//在第一个数据之后的数据前插入
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newcode;
newcode->next = pos;
}
}3.8 删除指定位置的数据函数SListErase
SListErase函数的功能为删除pos处的节点,一般也是配合SListFind函数使用,查找到某个特定值的位置,然后通过SListErase函数删除掉链表中的这个值。SListErase函数也要分两种情况进行讨论:
- 若链表中没数据,不进行任何操作(报错)
- 若pos为链表头结点:相当于头删
- 若pos不是链表头结点(一般情况):让pos前方的节点指向pos后方的节点,释放pos节点占用的内存空间(详见图3.2)。

SListErase函数代码:
void SListErase(SLTNode** pphead, SLTNode* pos)
{
assert(pos);
SLTNode* prev = NULL; //用于查找pos前面那个节点
SLTNode* cur = *pphead; //当前节点
if (*pphead == pos)
{
//相当于头删
*pphead = cur->next;
}
else
{
while (cur != pos && cur != NULL)
{
//查找pos前面的那个节点prev及pos
prev = cur;
cur = cur->next;
}
//pos前面的节点指向pos后面的节点
prev->next = cur->next;
}
free(cur); //释放pos节点
cur = NULL;
}3.9 单链表销毁函数SListDestory
依次遍历单链表每个节点,释放每个节点的内存空间,然后将表头指针phead置为空指针即可。
SListDestory函数代码:
void SListDestory(SLTNode** pphead)
{
SLTNode* cur = *pphead;
while (cur != NULL)
{
SLTNode* next = cur->next; //cur的下一个节点
free(cur); //释放当前节点
cur = next;
}
*pphead = NULL; //单链表表头指针置空
}四. 几个典型的单链表问题
4.1 删除单链表中的某个元素
遍历链表中的每个元素,若遇到要删除的元素,则根据元素在链表中所处的位置(链表表头、链表结尾、链表中间三种情况)执行相应的操作删除元素,图解见图4.1。
要删除的元素在链表尾部和链表中间两种情况本质上其实一样,因为链表最后一个节点后面为NULL,尾删要求倒数第二个节点指向NULL,其实就是指向链表最后一个节点后面那个节点(最后一个节点后面的节点理解为NULL)。

删除链表中特定元素代码:
//head为链表表头,val为要删除的元素
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode* cur = head; //当前节点
struct ListNode* prev = NULL; //当前节点的前一个节点
while(cur != NULL)
{
if(cur->val == val) //节点存储的数值等于val,删除
{
if(cur == head)
{
//在链表表头,相当于头删
head = head->next; //更新链表表头
free(cur); //释放当前节点
cur = head;
}
else
{
//在链表中间位置或结尾位置
prev->next = cur->next; //前一个节点指向后一个节点
free(cur); //释放当前节点
cur = prev->next;
}
}
else
{
//节点存储的值不等于val,检索下一个节点
prev = cur;
cur = cur->next;
}
}
return head;
}4.2 单链表翻转
给定单链表头结点,将链表翻转逆序。只需要改变从第二个节点开始的指向即可,让每一个节点的指向变为其前方那个节点,然后将链表表头更改为原链表最后一个节点,图解见图4.2。

链表翻转代码:
//返回新链表的表头
struct ListNode* reverseList(struct ListNode* head)
{
//单链表中只有一个数据或为空链表
if(head == NULL || head->next == NULL)
{
return head;
}
struct ListNode* cur = head->next; //当前节点
struct ListNode* prev = head; //当前节点的前一个
while(cur)
{
struct ListNode* next = cur->next; //记录当前节点的下一节点位置
cur->next = prev; //后面的节点指向前面的节点
prev = cur;
cur = next;
}
//原来的表头变为表尾,指向NULL
head->next = NULL;
//返回原链表尾
return prev;
}还可以通过头插操作来实现单链表的翻转,依次将从第二个节点开始的每个节点头插到新生成的单链表之前即可,每次头插的操作包括:让头插节点指向单链表原来的表头、更改单链表表头为头插节点。完成所有节点的头插后,原单链表表头变表尾,其指向NULL。
通过头插翻转单链表代码:
struct ListNode* reverseList(struct ListNode* head)
{
//单链表中只有一个数据或为空链表
if(head == NULL || head->next == NULL)
{
return head;
}
struct ListNode* cur = head->next; //当前节点
struct ListNode* newhead = head; //新表头
while(cur)
{
//执行头插操作
struct ListNode* next = cur->next; //下一节点
cur->next = newhead; //头插节点指向原表头
newhead = cur; //表头改为头插节点
cur = next;
}
//原来的表头变为表尾,指向NULL
head->next = NULL;
//返回原链表尾
return newhead;
}4.3 寻找单链表的中间节点
方法:快慢指针。
定义一个快指针fast和一个慢指针slow,并将快慢指针均初始化为单链表表头,快指针每次走两步,慢指针每次走一步,当快指针指向单链表尾部时,慢指针就指向单链表的中间节点。

快慢指针法寻找单链表中间节点代码:
//返回中间节点的地址
struct ListNode* middleNode(struct ListNode* head)
{
//采用快慢指针
//快指针指向尾部时,慢指针指向中间结点
struct ListNode* fast = head;
struct ListNode* slow = head;
while(fast && fast->next)
{
fast = fast->next->next;
slow = slow->next;
}
return slow;
}4.4 寻找单链表的倒数第k个节点
同样采用快慢指针的方法,快指针先向前走k步。快指针走k步后慢指针开始运动,快慢指针均每次走一步,当快指针指向单链表尾部时,慢指针指向倒数第k个节点。
寻找单链表倒数第k个节点代码:
//返回单链表倒数第k个节点的值
int kthToLast(struct ListNode* head, int k)
{
//快慢指针法
struct ListNode* slow = head;
struct ListNode* fast = head;
//快指针比慢指针向前k个节点
while(k--)
{
fast = fast->next;
}
while(fast)
{
fast = fast->next;
slow = slow->next;
}
return slow->val;
}4.5 合并两个有序链表
合并两个升序的单链表,要依次进行如下几步操作:
- 判断两个链表其中之一是否为空,如果其中之一为空,返回另一个链表。
- 选择合并后的单链表表头:比较两个单链表表头数据的大小,选取表头数据较小的那个单链表表头为合并后单链表的表头。
- 在两个单链表均没有到表尾前,依次比较两个单链表的当前位置元素,将较小的插入到新的单链表尾部。
- 当一个单链表到达表尾后,将另一个单链表的剩余元素插到新的单链表尾部
合并两个有序链表函数代码:
//返回新链表的表头
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2)
{
//两个链表之一为空,返回另一个
if(l1 == NULL)
{
return l2;
}
else if(l2 == NULL)
{
return l1;
}
//筛选合并后链表的头结点
//选取头结点数据较小的那个链表的表头为新链表的头结点
struct ListNode* newhead = NULL;
struct ListNode* cur1 = l1; //链表1当前位置
struct ListNode* cur2 = l2; //链表2当前位置
if(l1->val > l2->val)
{
newhead = l2; //链表2的表头为头结点
cur2 = cur2->next;
}
else
{
newhead = l1; //链表1的表头为头结点
cur1 = cur1->next;
}
//依次比较两个链表当前位置的元素,将较小的尾插到新链表
struct ListNode* newtail = newhead;
while(cur1 && cur2)
{
if(cur1->val < cur2->val)
{
//尾插cur1的节点
newtail->next = cur1;
newtail = cur1;
cur1 = cur1->next;
}
else
{
//尾插cur2的节点
newtail->next = cur2;
newtail = cur2;
cur2 = cur2->next;
}
}
//判断那个链表还没有到达尾部,将剩余数据插入到新链表尾部
if(cur1)
{
newtail->next = cur1;
}
else if(cur2)
{
newtail->next = cur2;
}
return newhead;
}4.6 单链表分割
给定一个指定的链表表头head和一个特定的值x,对链表进行分割生成新链表,让小于x的值均出现在大于等于x的值之前,保证链表的相对顺序不变。三步操作即可实现链表分割:
- 创建两个带哨兵卫的头结点的链表lessSList和greaterSList,两个新链表分别存储原链表中小于x的数据和大于等于x的数据。
- 让lessSList链表尾部与greaterSList链表头部连接,将两个链表合并。
- 使合并后链表尾部的节点指向NULL。

单链表分割代码:
struct ListNode* partition(struct ListNode* head, int x)
{
//链表无数据或仅有一个数据,返回本身
if(head == NULL || head->next == NULL)
{
return head;
}
//创建两个带哨兵卫头结点的链表,分别存储小于x和大于等于x的数据
struct ListNode *lessSListHead, *lessSListTail;
struct ListNode *greaterSListHead, *greaterSListTail;
lessSListHead = lessSListTail = (struct ListNode*)malloc(sizeof(struct ListNode));
lessSListHead->next = NULL;
if(lessSListHead == NULL) //检验哨兵卫节点是否创建成功
{
exit(-1);
}
greaterSListHead = greaterSListTail = (struct ListNode*)malloc(sizeof(struct ListNode));
greaterSListHead->next = NULL;
if(greaterSListHead == NULL)
{
free(lessSListHead);
exit(-1);
}
//比较链表中的每一个数据
//判断数据是否大于x,尾插到相应的链表
struct ListNode* cur = head;
while(cur)
{
struct ListNode* next = cur->next;
if(cur->val < x) //数据小于x尾插到lessSList链表
{
lessSListTail->next = cur;
lessSListTail = cur;
}
else //数据大于等于x尾插到greaterSList链表
{
greaterSListTail->next = cur;
greaterSListTail = cur;
}
cur = next;
}
//将两个新创建的链表进行连接
lessSListTail->next = greaterSListHead->next;
greaterSListTail->next = NULL;
//返回的新链表表头
struct ListNode* newhead = lessSListHead->next;
//释放哨兵卫头结点空间
free(lessSListHead);
free(greaterSListHead);
return newhead;
}4.7 单链表的回文结构
判断一个链表是否为回文链表,回文链表就是指从头到尾读和从尾到头读是一样的的链表,如单链表:1 -> 2 -> 3 -> 3 -> 2 -> 1,就是典型的回文链表。这里要通过代码判断一个单链表是否为回文链表,思路如下:
- 通过快慢指针的方法找到单链表的中间节点
- 翻转单链表的后半部分
- 依次比较翻转后的单链表前半部分和后半部分的每个数据是否相同,若每个数据均相同,则该单链表为回文链表
- 再次翻转单链表后半部分,使单链表恢复原状。

判断是否为回文链表函数代码:
bool isPalindrome(struct ListNode* head)
{
//空链表或链表只有一个元素,返回链表本身
if(head == NULL || head->next == NULL)
{
return true;
}
bool ret = true; //返回值
//快慢指针法找链表中间节点
struct ListNode* fast = head;
struct ListNode* slow = head;
while(fast && fast->next)
{
fast = fast->next->next;
slow = slow->next;
}
struct ListNode* mid = slow; //中间节点
//翻转链表的后半部分
struct ListNode* cur = mid->next;
struct ListNode* newhead_later = mid;
while(cur)
{
struct ListNode* next = cur->next;
cur->next = newhead_later;
newhead_later = cur;
cur = next;
}
mid->next = NULL;
//比较翻转后链表前半部分和后半部分每个元素是否相同
struct ListNode* cur_front = head;
struct ListNode* cur_later = newhead_later;
while(cur_front && cur_later)
{
if(cur_front->val != cur_later->val)
{
ret = false;
break;
}
cur_front = cur_front->next;
cur_later = cur_later->next;
}
//再次翻转单链表后半部分,使单链表恢复原状
newhead_later->next = NULL;
cur = newhead_later->next;
struct ListNode* prev = newhead_later;
while(cur)
{
struct ListNode* next = cur->next;
cur->next = prev;
prev = cur;
cur = next;
}
return ret;
}4.9 链表相交
判断两链表是否相交并返回相交的起始点。图4.6为典型的相交链表,其中c1节点为两链表首个相交的节点。

如要实现判断两链表是否相交并且返回首个相交的节点,应进行的操作包括:
- 遍历两个链表,找到两链表的尾结点,并统计量链表的长度(存储数据个数)
- 判断两链表的尾结点是否相同,若相同则两链表相交,不同则不相交
- 定义两个链表表头longList和shortList,分别表示较长的链表表头和较短的链表表头,longList先走两链表的长度差步,之后shortList和longList同步运动,他们首次相遇的节点就是首个相交的节点。
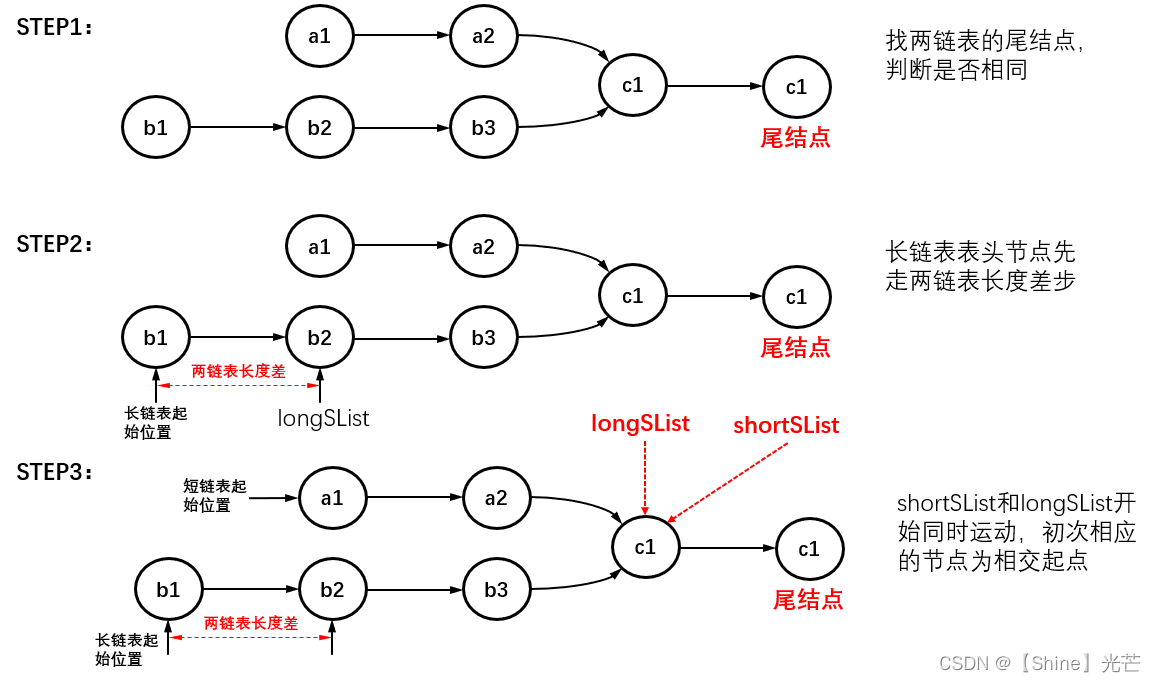
链表相交函数代码:
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{
if(headA == NULL || headB == NULL)
{
return NULL;
}
//两链表若尾部节点相同,则相交
struct ListNode* curA = headA;
struct ListNode* curB = headB;
int lenA = 1; //链表A的长度
int lenB = 1; //链表B的长度
//找链表A的尾
while(curA->next)
{
curA = curA->next;
++lenA;
}
//找链表B的尾
while(curB->next)
{
curB = curB->next;
++lenB;
}
if(curA != curB) //尾节点不同则两链表不相交,返回NULL
{
return NULL;
}
int gap = abs(lenA - lenB); //长度差
//让较长的链表先走长度差步
struct ListNode* longlist = headA;
struct ListNode* shortlist = headB;
if(lenA < lenB)
{
longlist = headB;
shortlist = headA;
}
while(gap--) //长链表先走长度差步
{
longlist = longlist->next;
}
//长短链表相遇的位置即为相交点
while(longlist != shortlist)
{
shortlist = shortlist->next;
longlist = longlist->next;
}
return shortlist;
}4.10 环形链表
4.10.1 判断某个链表是否为环形链表
环形链表指没有结尾的链表,链表内部连接成环(见图4.8)

方法:快慢指针,快指针每次走两步,慢指针每次走一步,若两指针相遇,则为环形链表,快指针到达链表末尾则不是环形链表。
证明:(参考图4.9)
- 假设快指针每次走两步,慢指针每次走一步,快指针先入环。
- 当慢指针入环时,假设此时快慢指针相距X(见图4.9),此时快指针开始追赶慢指针。
- 快慢指针同时运动,每运动一次,他们之间的距离减小1,运动过程中快慢指针的距离的变化为:X、X-1、X-2、...... 、1、0。
证得:若快指针一次走两步,慢指针一次走一步,则在环形链表中快慢指针一定会相遇。

判断某个链表是否为环形链表代码:
bool hasCycle(struct ListNode *head)
{
if(head == NULL)
{
return false;
}
//快慢指针
//快指针每次走2步,慢指针每次走一步
//若两指针相遇,则为环形链表
struct ListNode* fast = head->next;
struct ListNode* slow = head;
while(fast && fast->next)
{
if(fast == slow)
{
return true;
}
else
{
fast = fast->next->next;
slow = slow->next;
}
}
return false;
}延伸问题:若慢指针每次走一步,快指针每次走n步(n > 2),在环形链表中快慢指针是否一定相遇?
结论:n>2时,带环链表中快慢指针不一定相遇
证明:
以n=3为例进行证明,假设慢指针入环时快慢指针相距X,分X为奇数和偶数两种情况讨论。
- 若X为偶数,随着快慢指针的运动,他们之间的距离依次变为:X、X-2、X-4、...、2、0,此时快慢指针会相遇。
- 若X为奇数,随着快慢指针的运动,他们之间的距离依次变为:X、X-2、X-4、...、3、1、-1,相距-1就是两指针相距C-1,这里的C为环长。此时若C-1为奇数,则两指针永远不会相遇。
当n=4、n=5、... 时,证明与n=3原理相同,略去证明。
4.10.2 判断某个链表是否为环形链表并确定环的起点
方法:先采用快慢指针判断是否为环形链表,并记录快慢指针相遇的节点。再让两个指针分别从相遇节点和链表表头同时出发,每次走一步,这两个指针初次相遇的节点就是环的起点。
方法的证明:
- 设从链表起点到环起点的距离为L,环起点到快慢指针相遇点的距离为X,环长为C。
- 当快慢指针相遇时,快指针走过的距离为
,其中N为慢指针进入环前快指针走过的圈数,
,慢指针走过的距离为
。
- 相遇前快指针走过的距离是慢指针的两倍,因此有:
,整理公式得
,
是环长的整数倍加
,而此时meetNode与环起点相距

图4.10 链表头、环起点、快慢指针相遇点相对位置图解
判断链表是否有环并寻找环起点代码:
//若函数存在环则返回环起点
//若函数没有环则返回NULL
struct ListNode *detectCycle(struct ListNode *head)
{
//链表中只有一个数据或者没数据,没环,返回NULL
if(head == NULL || head->next == NULL)
{
return NULL;
}
//快慢指针,快指针一次走两步,慢指针一次走一步
//找快慢指针的相遇点
struct ListNode* fast = head;
struct ListNode* slow = head;
struct ListNode* meetNode = NULL;
while(fast && fast->next)
{
fast = fast->next->next;
slow = slow->next;
if(fast == slow)
{
meetNode = slow;
//两指针分别从相遇点和起点同步开始运动
//他们相遇的地点为环的起点
struct ListNode* startPos_meet = meetNode;
struct ListNode* startPos_head = head;
while(startPos_meet != startPos_head)
{
startPos_meet = startPos_meet->next;
startPos_head = startPos_head->next;
}
return startPos_meet; //返回环起点
}
}
return NULL;
}五. 链表的优缺点
链表的优点:
- 按需申请空间,不存在空间浪费。
- 在链表头部或中间插入数据,不需要挪动数据。
链表缺点:
- 每存储一个数据,都需要存一个指针去连接后面的数据节点。
- 不支持随机访问(通过下标访问数据)
全文结束,感谢大家的阅读,敬请批评指正。














 1482
1482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









