






读入数据

定义特征与目标值
data_x = data.iloc[:,1:-1]
data_y = data[['MPG']]
划分数据集
from sklearn.model_selection import train_test_split
x_train ,x_test, y_train, y_test = train_test_split(data_x, data_y, test_size = 0.25)
对训练数据进行归一化处理。数值的量纲不同甚至相差很大,如果不归一化处理得出的损失函数图像的等高线可能为一个椭圆,计算出来的模型参数就会受影响,最后甚至预测不出较正确的结果。
# 归一化
from sklearn.preprocessing import StandardScaler
# 初始化StandardScaler
sc_x = StandardScaler()
sc_y = StandardScaler()
# 对特征及目标进行训练,训练参数存入 sc_x ,sc_y
x_train_std = sc_x.fit_transform(x_train)
y_train_std = np.ravel(sc_y.fit_transform(y_train)) # np.ravel 将多维数组降位一维
导入sklearn中的SGDRegressor模型进行训练
# 梯度下降的方式求解回归系数
from sklearn.linear_model import SGDRegressor
regressor = SGDRegressor()
regressor.fit(x_train_std, y_train_std)
用测试集测试训练出来的模型
# regressor.predict(x_test_std) 进行预测
# sc_x.transform(x_test) ,用开始训练出来的sc_x对x_test进行标准化
x_test_std = sc_x.transform(x_test)
y_test_pred_std = regressor.predict(x_test_std)
测试集预测出来的值进行反标准化
# 反标准化
sc_y.inverse_transform(y_test_pred_std)
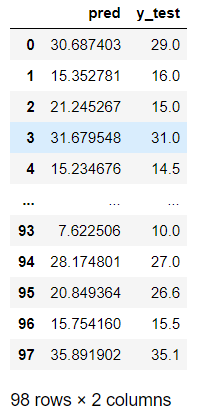
更直观的展示模型预测出来的值与真实值之间的差距
import pandas as pd
data_test=pd.DataFrame()
data_test['pred']=sc_y.inverse_transform(y_test_pred_std)
data_test['y_test']=y_test.values
data_test














 2492
2492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









