







 本文概述了SiamFC引领的单目标跟踪技术发展,从全卷积双胞胎网络到引入注意力机制、模板更新、回归预测和深度学习优化。重点介绍了SiamFC-tri、Siam-BM、CFNet、RASNet等算法的创新点和不足,以及DSiam、UpdateNet等在模板更新和网络结构优化上的突破。
本文概述了SiamFC引领的单目标跟踪技术发展,从全卷积双胞胎网络到引入注意力机制、模板更新、回归预测和深度学习优化。重点介绍了SiamFC-tri、Siam-BM、CFNet、RASNet等算法的创新点和不足,以及DSiam、UpdateNet等在模板更新和网络结构优化上的突破。
基于Siamese Network的单目标跟踪持续汇总(Visual Object Tracking)

从SiamFC开始,涌现了一大批基于孪生神经网络(Siamese Network)的跟踪算法,其中包括多目标跟踪和单目标跟踪。本文将以SiamFC为开山之作,介绍后续的部分基于Siamese Network的单目标跟踪算法。
开山之作
SiamFC——Fully-Convolutional Siamese Networks for Object Tracking
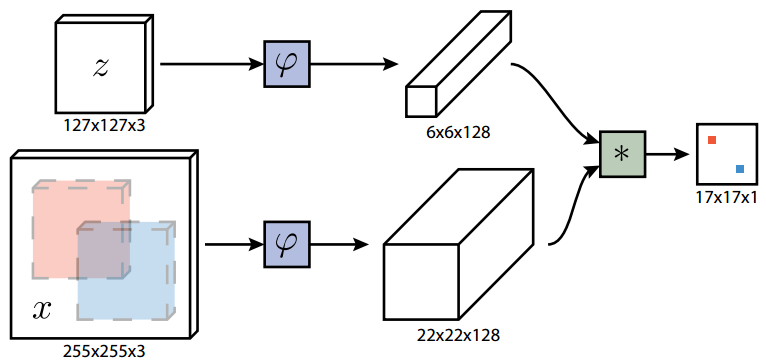
方法:
以孪生神经网络为基础,是孪生神经网络进行单目标跟踪的开山之作。将目标的跟踪方式从在线执行随机梯度下降以适应网络的权重进行跟踪转变为前后帧目标对的形式进行匹配。通过同一网络AlexNet作为backbone,输出模板图像和待查询图像的特征图,并进行互卷积(相关滤波)操作,得到目标响应结果,反向映射到原图,计算当前帧目标位置。
细节可参考另一篇博客:SiamFC论文解读及代码实现
跟踪阶段:
创新点:
- 采用了孪生神经网络用于图像中目标的查询,若图像中的目标相似,则响应结果大,否则小
- 全卷积网络,无全连接层,利用响应图的响应结果,反映射回原图,得到目标bbox
- 端到端训练,参数量少,跟踪速度快
- 跟踪时crop不同大小的待查询区域,再resize到 255 ∗ 255 ∗ 3 255*255*3 255∗255∗3的大小。(从现在看就是图像金字塔,即匹配多个尺度的图像)
以现在的视角看不足:
- 能不能在响应图后面直接输出目标bbox,而不是映射回原图?
- 每一次查询区域都是上一帧的目标中心,能不能多几个查询区域?
- 图像金字塔时间慢,能不能采用特征金字塔的形式?
- 模板只用第一帧的图像而不进行更新,随着时间的推进,目标外观发生变化或遮挡,只用第一帧图像合理吗?
- Backbone使用更深层的网络,如ResNet,GoogleNet等?
针对这些问题,到目前为止,都有很多论文提出方法,进行解决,有的融合了当时时新的trick,有的对网络结构和存在的问题进行了深入探讨并改进。这些工作都很棒,接下来将会分板块进行介绍。
一、网络改进
1. SiamFC-tri——Triplet Loss in Siamese Network for Object Tracking ECCV 2018
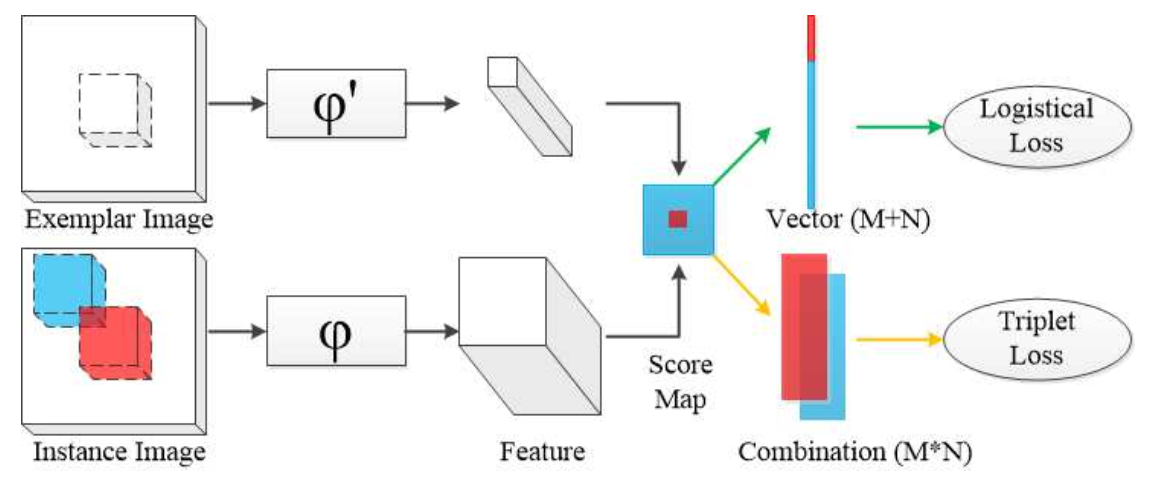
方法:
本文提出了一种新的训练策略,通过训练时在Siamese Network中加入triplet loss提取出目标跟踪的深度表达特征。图中 φ \varphi φ表示特征提取网络,当 φ = φ ′ \varphi=\varphi^{'} φ=φ′时,遵循SiamFC范式,当 φ ≠ φ ′ \varphi\neq\varphi^{'} φ=φ′时,遵循CFNet范式。
创新点:
基于SiamFC框架,在训练过程中修改loss,从SiamFC中的Logistical loss增加到Logistical loss和Triplet loss的和。模型没有大改动,仅在训练时多加了一个triplet loss。
2. Siam-BM——Towards a Better Match in Siamese Network Based Visual Object Tracker ECCV 2018 workshop
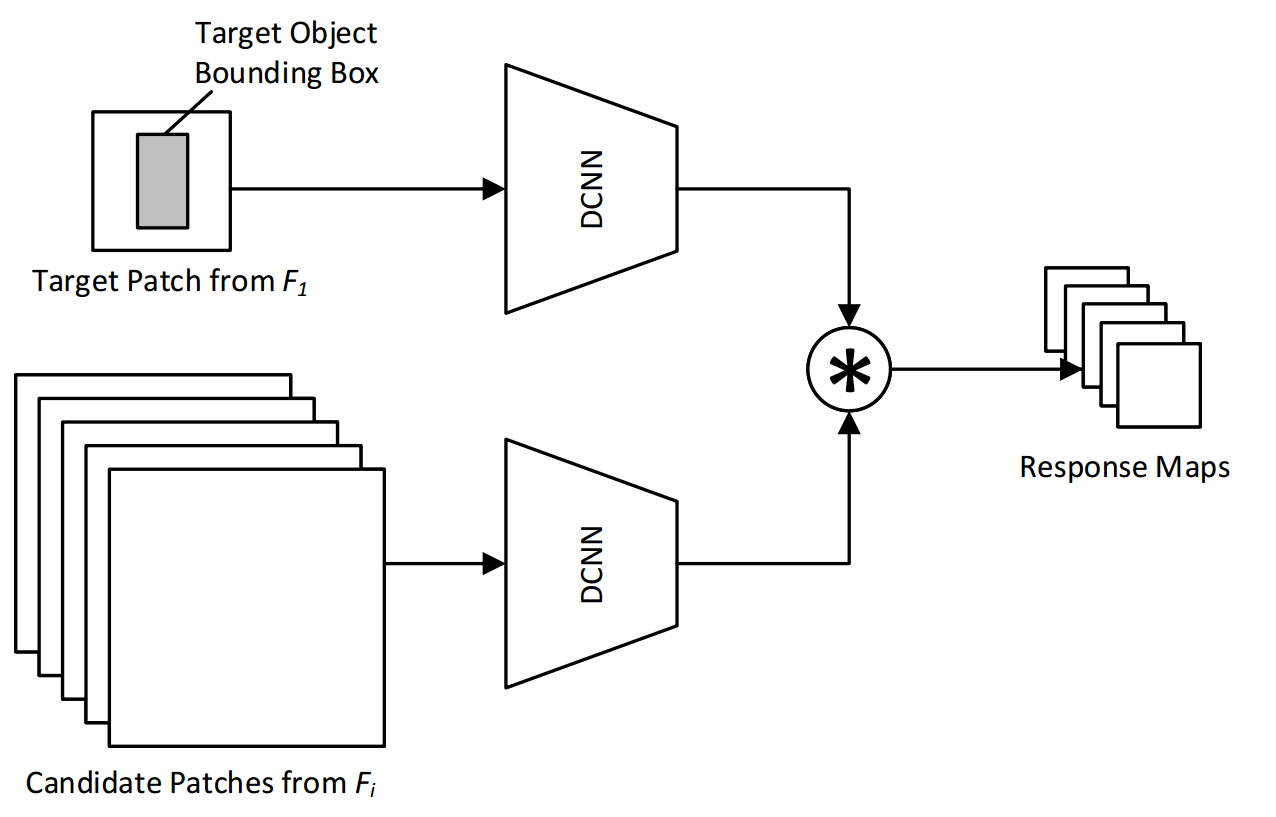
方法:
跟踪阶段由于目标会不断变化,网络直接在跟踪阶段自设置不同变换的待跟踪图像。SiamFC在跟踪阶段使用图像金字塔,但仅仅是crop不同大小的图像区域。Siam-BM则在跟踪阶段,不仅是图像金字塔,同时对每层图片加入了旋转操作。让网络在跟踪时更鲁棒。
创新点:
- 考虑了目标在跟踪时的变化情况,在跟踪时自设置图像旋转操作,从直觉上多了更多变化,跟踪更鲁棒。
3. CFNet——End-to-end representation learning for Correlation Filter based tracking CVPR2017
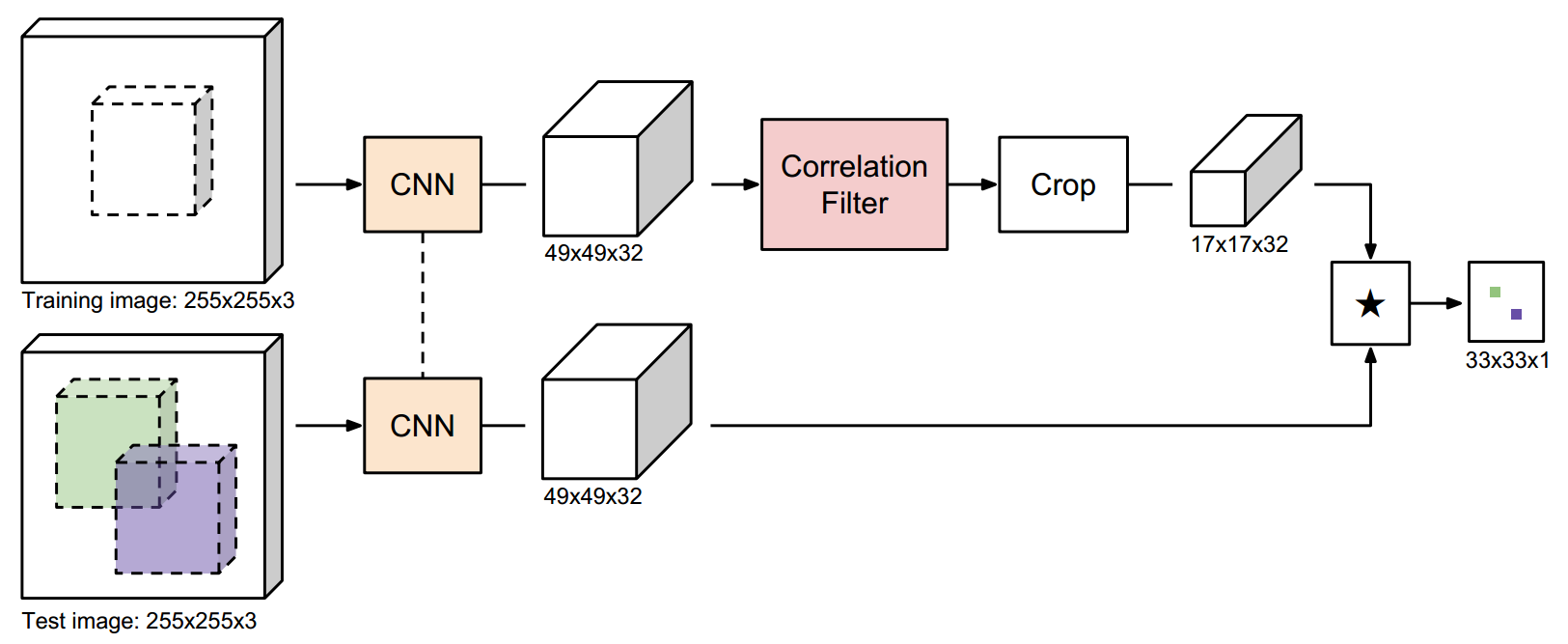
方法:
最初的SiamFC只是将每一帧与对象的初始外观进行比较。相比之下,我们在每一帧中计算一个新的模板,然后与之前帧的模板进行融合。
每一帧计算时,SiamFC公式如下:
f ( z , x ) = γ φ ( z ) ∗ φ ( x ) + b 1 {f(z,x)=\gamma\varphi(z)*{\varphi(x)}+b\mathbb{1}} f(z,x)=γφ(z)∗φ(x)+b1
那么CFNet公式如下:
f ( z , x ) = γ w ( φ ( z ) ) ∗ φ ( x ) + b 1 {f(z,x)=\gamma{w(\varphi(z))*{\varphi(x)}+b\mathbb{1}}} f(z,x)=γw(φ(z))∗φ(x)+b1
CFNet的模板图像输入也是 255 ∗ 255 ∗ 3 255*255*3 255∗255∗3,这样的话, φ ( z ) \varphi(z) φ(z)和 φ ( x ) \varphi(x) φ(x)的输出特征图都是一样大小,为 49 ∗ 49 ∗ 32 49*49*32 49∗49∗32。之后利用相关滤波模块(Correlation Filter)CF Block w = w ( x ) w=w(x) w=w(x)提取在每一帧中的模板。输出 17 ∗ 17 ∗ 32 17*17*32 17∗17∗32的模板特征。与待查询图像互卷积。
CFNet和SiamFC一样,有必要引入标量参数 γ \gamma γ和 b b b,使分数范围适合逻辑回归。
创新点:
- 将SiamFC中加入CF Block,并且融入到网络中,能进行前向传播和反向传播
- 网络不再对称(即对模板图像的提取和对待搜索图像的提取不再采用一模一样的方式,在模板图像提取中加入了CF Block)
- 改变了输入图像大小
- 模板更新,不再一直使用第一帧模板的特征
注:相关滤波看不太懂,还得再学习
4. RASNet——Learning Attentions: Residual Attentional Siamese Network for High Performance Online Visual Tracking CVPR 2018
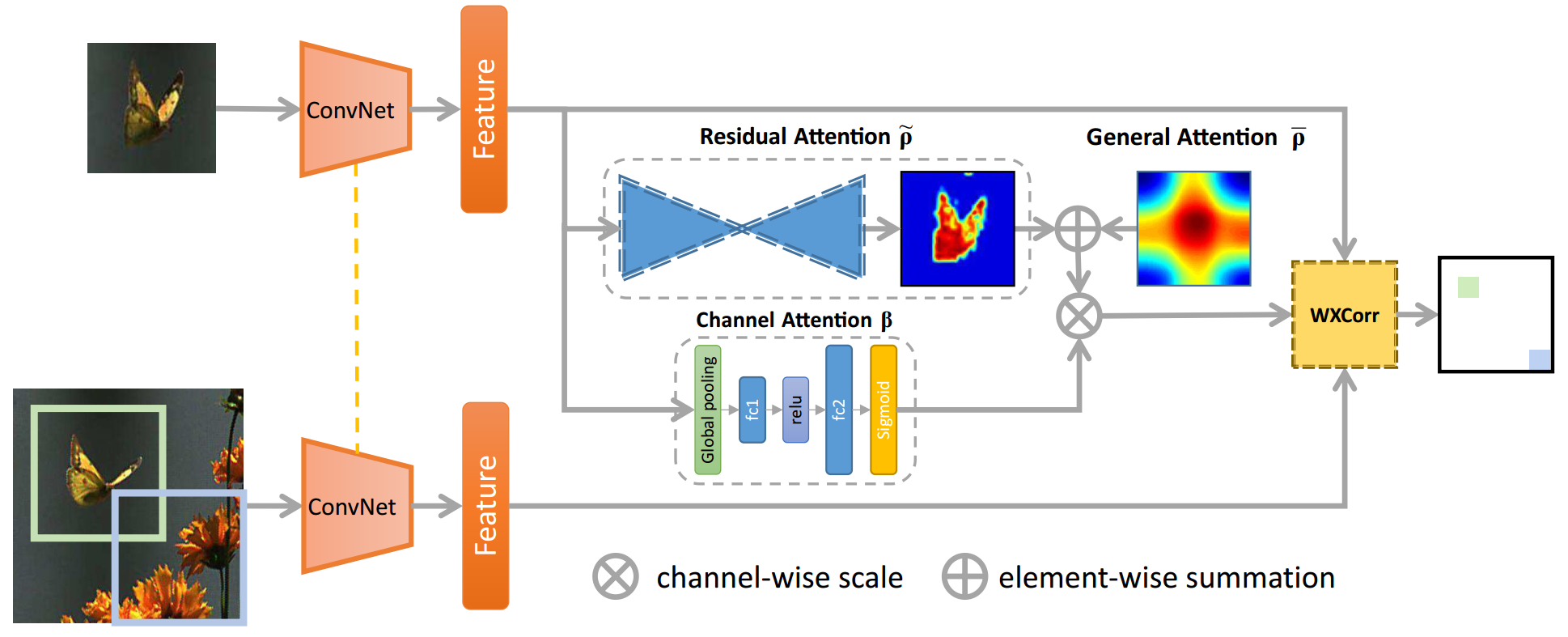
方法:
以SiamFC为基础,在backbone提取模板图像和待跟踪图像的特征后,模板特征后加入了残差注意力(Residual Attention)、通道注意力(Channel Attention)和通用注意力(General Attention),同时将互卷积更改为加权互相关层(WXCorr)。
当一张模板和一张待搜索图像流入网络时,通过backbone生成特征图。基于模板特征,使用三种注意力机制提取了模板信息。模板、待搜索特征、作为权重的attention输出,被输入到WXCorr,并最终转换为响应图。
WXCorr公式:
f ( z , x ) = ( γ ⊙ ϕ ( z ) ) ∗ ϕ ( x ) + b 1 f(z,x)=(\gamma\odot\phi(z))*\phi(x)+b\mathbb{1} f(z,x)=(γ⊙ϕ(z))∗ϕ(x)+b1
相比于SiamFC中的XCorr公式:
f ( z , x ) = ϕ ( z ) ∗ ϕ ( x ) + b 1 f(z,x)=\phi(z)*\phi(x)+b\mathbb{1} f(z,x)=ϕ(z)∗ϕ(x)+b1
只增加了 γ ⊙ \gamma\odot γ⊙, γ \gamma γ表示注意力机制得到的权重。 ⊙ \odot ⊙表示对模板特征做了权重的点乘,对应模板特征上每一个点都有一个权重,再进行互卷积操作。
创新点:
- 在SiamFC中加入了时新的注意力机制,各种注意力机制。作用于模板图像,企图提点。。。。。。
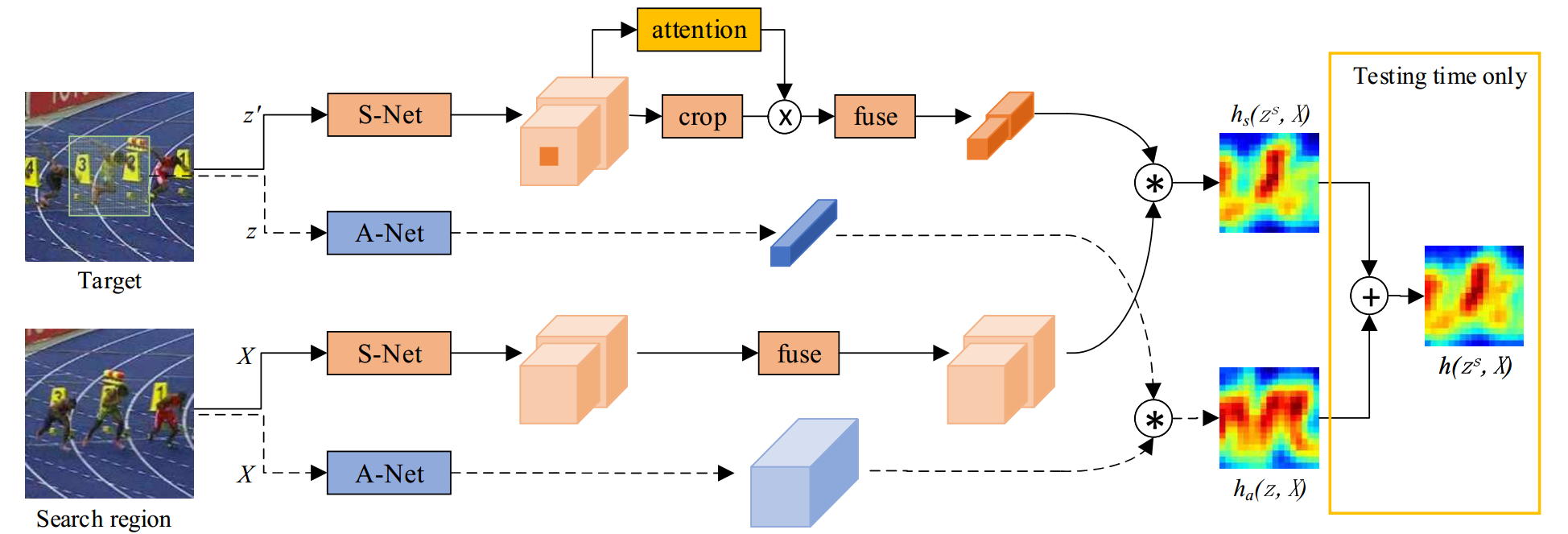
5. SASiam——A Twofold Siamese Network for Real-Time Object Tracking CVPR2018
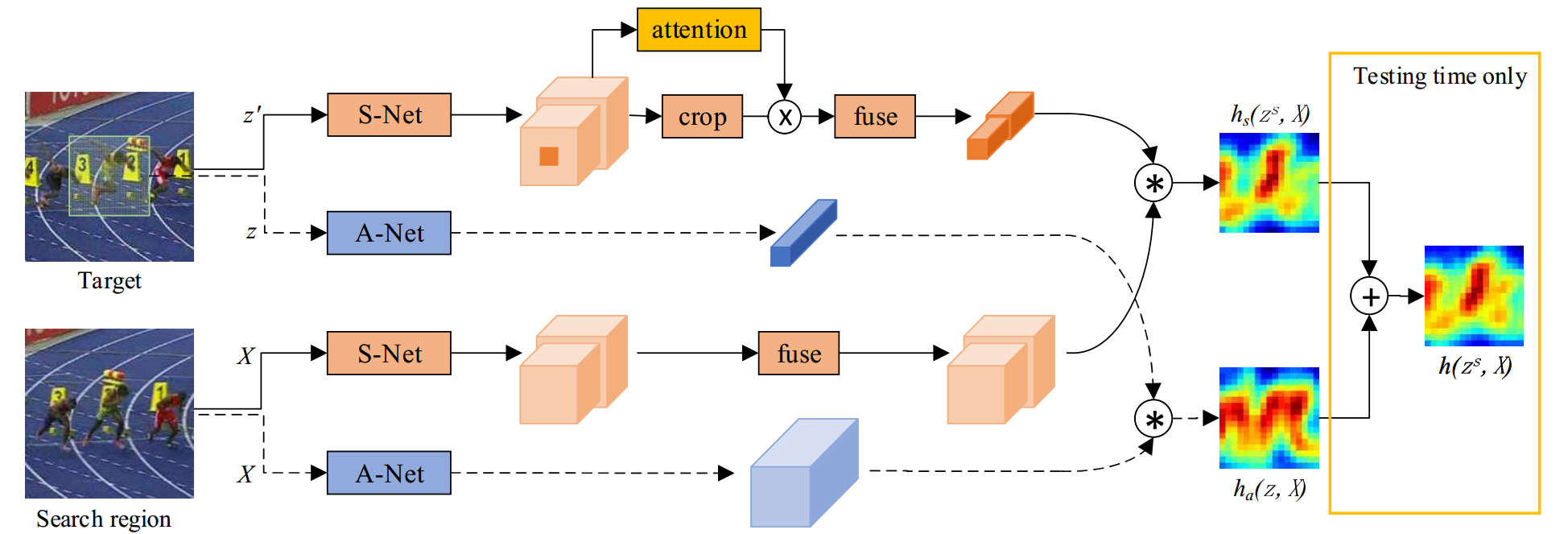
方法:
观察到在图像分类任务中学习到的语义特征和在相似性匹配任务中学习到的外观特征相辅相成,我们构建了一个双分支网络。SASiam由Semantic branch语义分支和Appearance branch外观分支两部分构成,语义分支中还加入了通道注意力机制SEBlock。分别训练这两个网络,将特征图加权输出。
外观特征网络:加入了SEBlock的SiamFC
语义特征网络:Alexnet在ImageNet上训练的权重,并不再跟踪数据集上fine-tune,直接拿过来用。
外观特征更像对于同一个目标外观的相似程度,而语义特征更像是对于同一类目标的相似程度,两者相辅相成。
创新点:
- 加入了衡量语义特征和外观特征的两种网络分支,但两个网络只能各自单独训练。
- 加入了时新的通道注意力机制SEBlock
6. MBST——Multi-Branch Siamese Networks with Online Selection for Object Tracking ISVC 2018
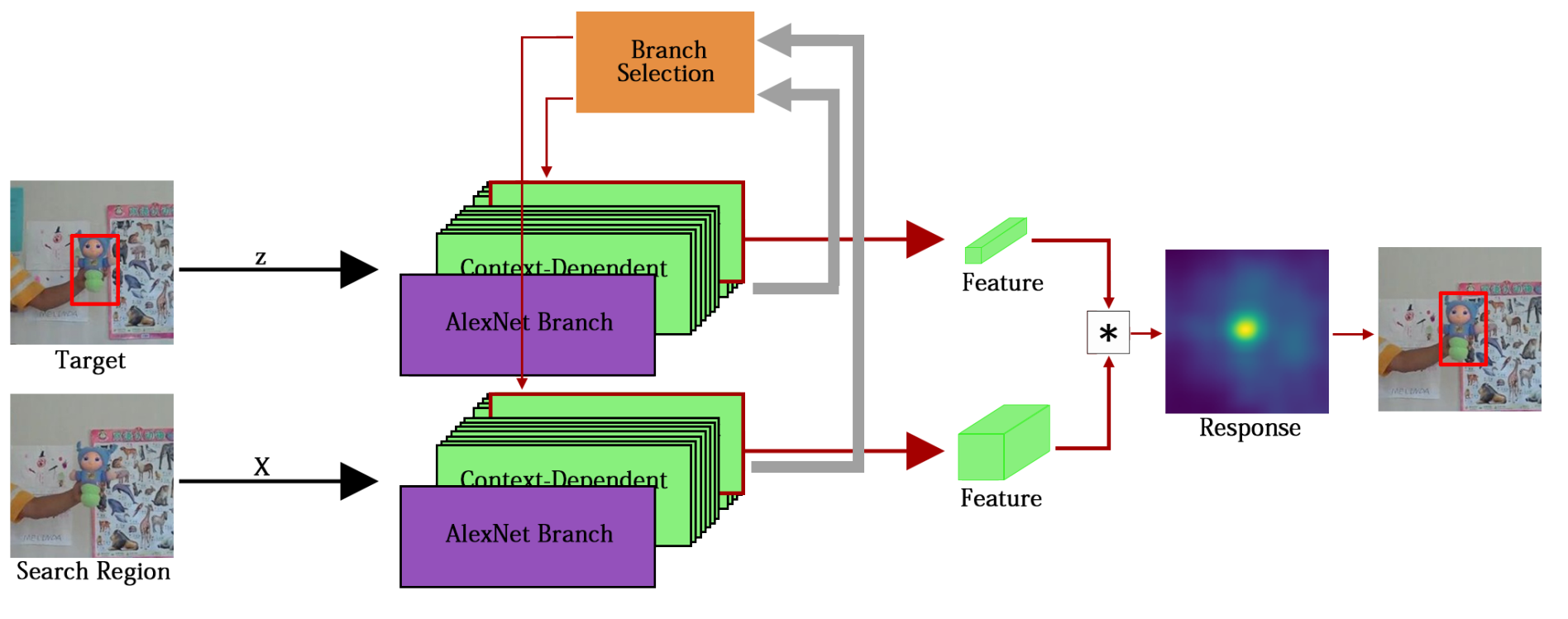
方法:
SASiam的堆料版本。。这里放一张SASiam的网络结构图做对比。
MBST中有两个分支,其中一条是AlexNet分支,另外一条有很多结构一模一样的Context Dependent分支,通过一个分支选择结构,选择输出结果更好的一个Context Dependent。
AlexNet Branch对应了A-Net(appearance net)
单个Context Dependent对应了S-Net(Semantic net),但没有注意力机制,只是普通的SiamFC。
同SASiam一样,AlexNet Branch从ImageNet上训练后直接在网络中使用。
创新点:
- 堆网络模型十足,个人感觉速度应该不快。。。。。。
7. DenseSiam——DensSiam: End-to-End Densely-Siamese Network with Self-Attention Model for Object Tracking ISVC 2018
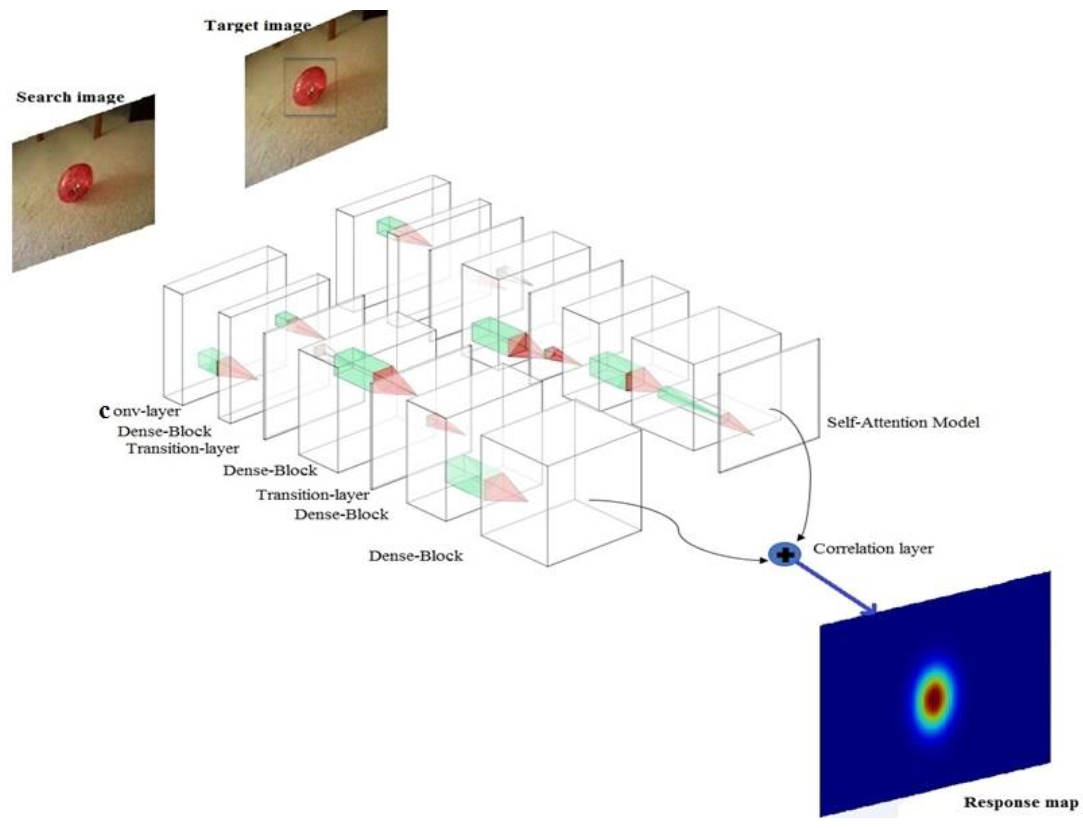
方法:
基于SiamFC,不再采用AlexNet作为Backbone,而是设计的新的网络结构,网络中有Dense Block,Block结构如下。并在网络提取到target image,加入自注意力机制,强化模板特征。
创新点:
- 从提取特征出发,修改网络结构,提取更优质的特征
- 加入时新的self-attention机制
8. StructSiam——Structured Siamese Network for Real-Time Visual Tracking ECCV 2018
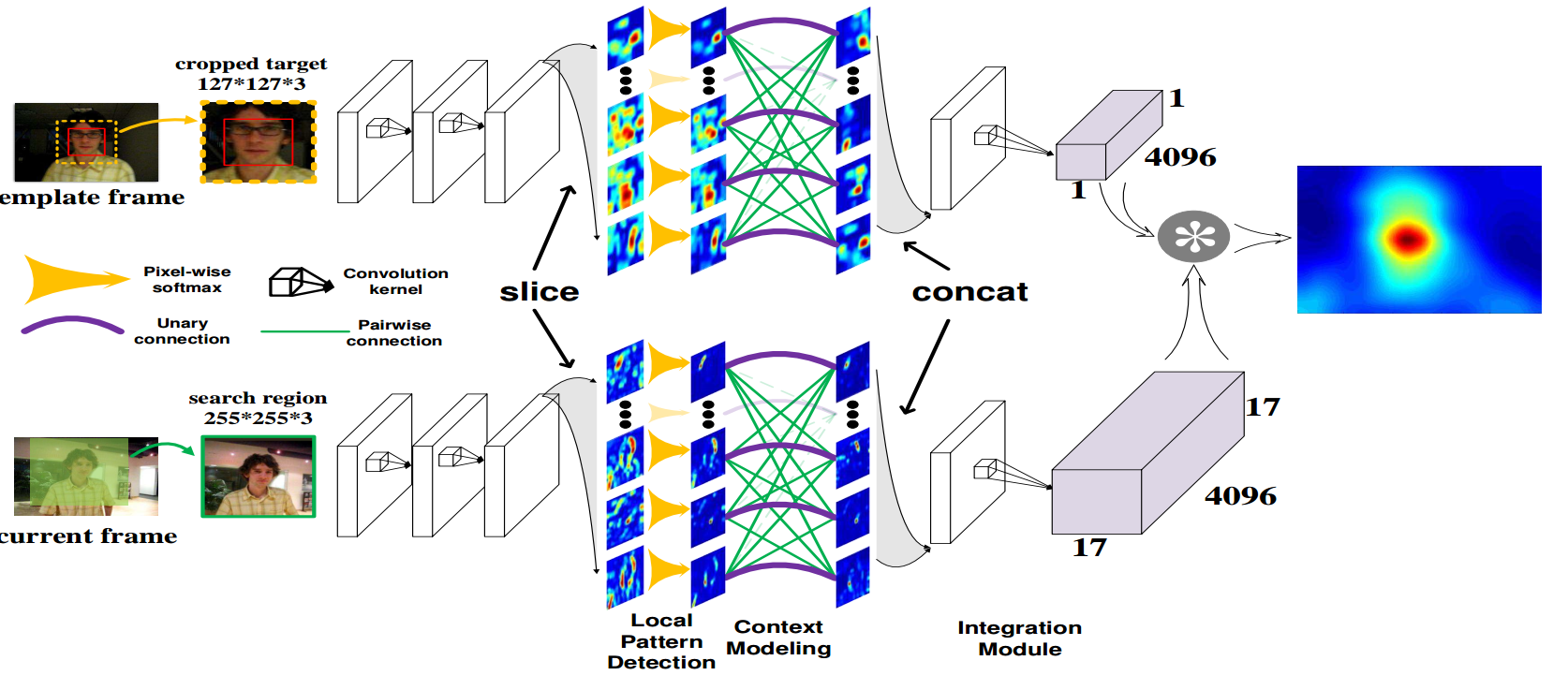
方法:
基于SiamFC范式,修改网络backbone的后几层,对其进行一定的处理。文中提到,处理的方法就是,局部模式检测和上下文建模两种方式。
局部模式检测:
对每个特征图切片后,对每个特征图单独操作,即对每个局部(特征图切片)检测( 11 ∗ 11 11*11 11∗11卷积->BN层->ReLU层-> 3 ∗ 3 3*3 3∗3最大池化-> 5 ∗ 5 5*5 5∗5卷积->BN层->ReLU层-> 3 ∗ 3 3*3 3∗3最大池化)其模式(Sigmoid输出结果)。原文中这里的特征图切片有256个,对每一片特征图都有单独的一个检测。。。。。
上下文建模:
我们将条件随机场(CRF)近似引入到我们的网络中。使用一个图Graph来描述目标的局部模式检测问题,并通过CRF对前一阶段生成的局部模式之间的联合概率关系进行建模
创新点:
- 对网络中的特征图切片进行一定融合操作,取名之“局部模式检测”和“上下文建模”,但又都是同一层的特征图切片。像特征融合吧,又不太像,但又有特征融合的影子,不知道作者怎么想出来这么个融合特征图的方法的。。。个人感觉对这么多特征图操作,速度应该快不到哪去。。
9. EAST——Learning Policies for Adaptive Tracking with Deep Feature Cascades ICCV 2017
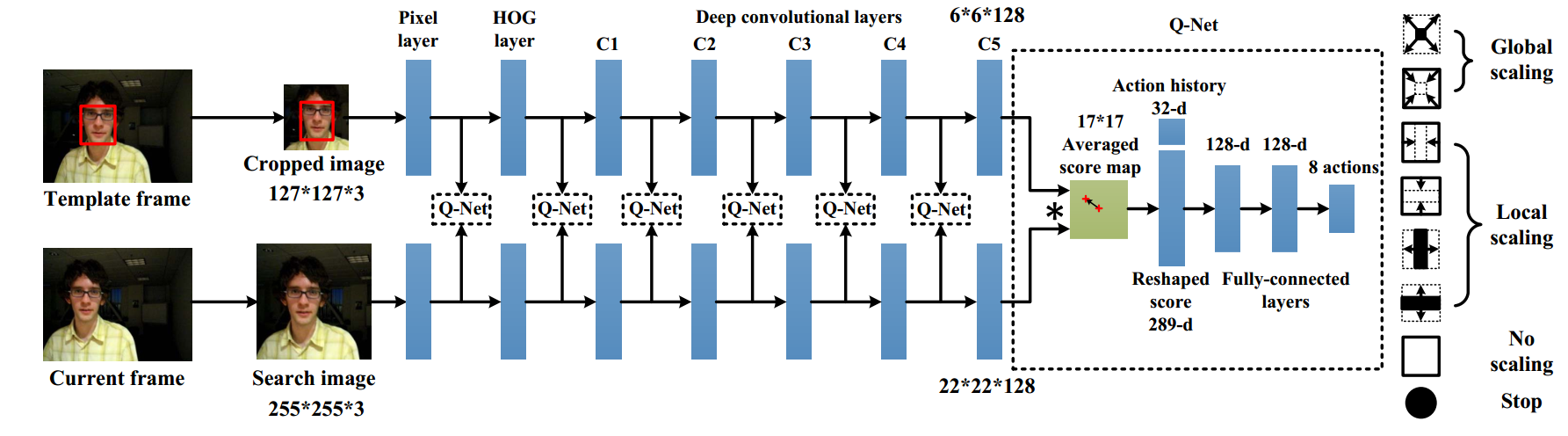
方法:
本文致力于在不减小精度的情况下,提高网络速度
EAST全名:early stop。从名字中可以看出,网络在浅层的时候若发现比较容易跟踪,则直接输出结果,而不再前向传播。即使用廉价的特征(DCF、HOG)处理简单的帧,使用昂贵的深层特征(SiamNet)处理具有挑战性的帧。在网络浅层加入HOG和DCF方法,在网络每一层都利用Q learning加入8个actions,利用强化学习学习并输出bbox的8种不同结果,如图所示。
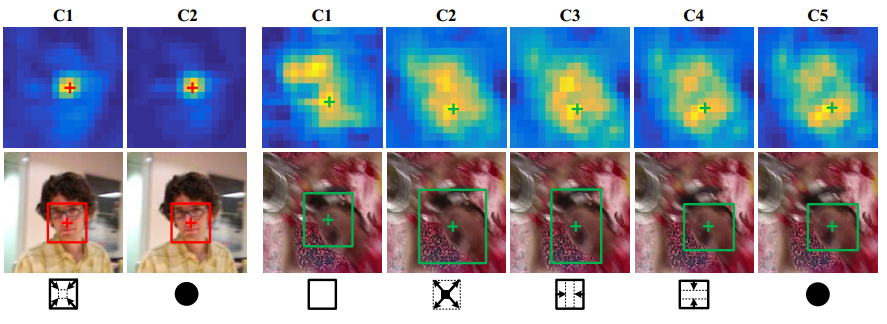
创新点:
- 在Bockbone网络结构前,加入了DCF(Pixel layer)和HOG(HOG layer)。浅层若能判定结果,则直接浅层输出减少计算时间(在现在看来,深度的神经网络基本能适应端到端而不用人工提取特征的方法)
- 网络每一层都利用Q learning输出action,判定是否继续前向传播(感觉推理时会更慢)
- 加入了时新的强化学习方法自适应输出bbox结果(在现在看来,有点杀鸡焉用牛刀的感觉,后续有非强化学习方法直接输出bbox的方法)
二、模板更新
1. DSiam——Learning Dynamic Siamese Network for Visual Object Tracking ICCV 2017
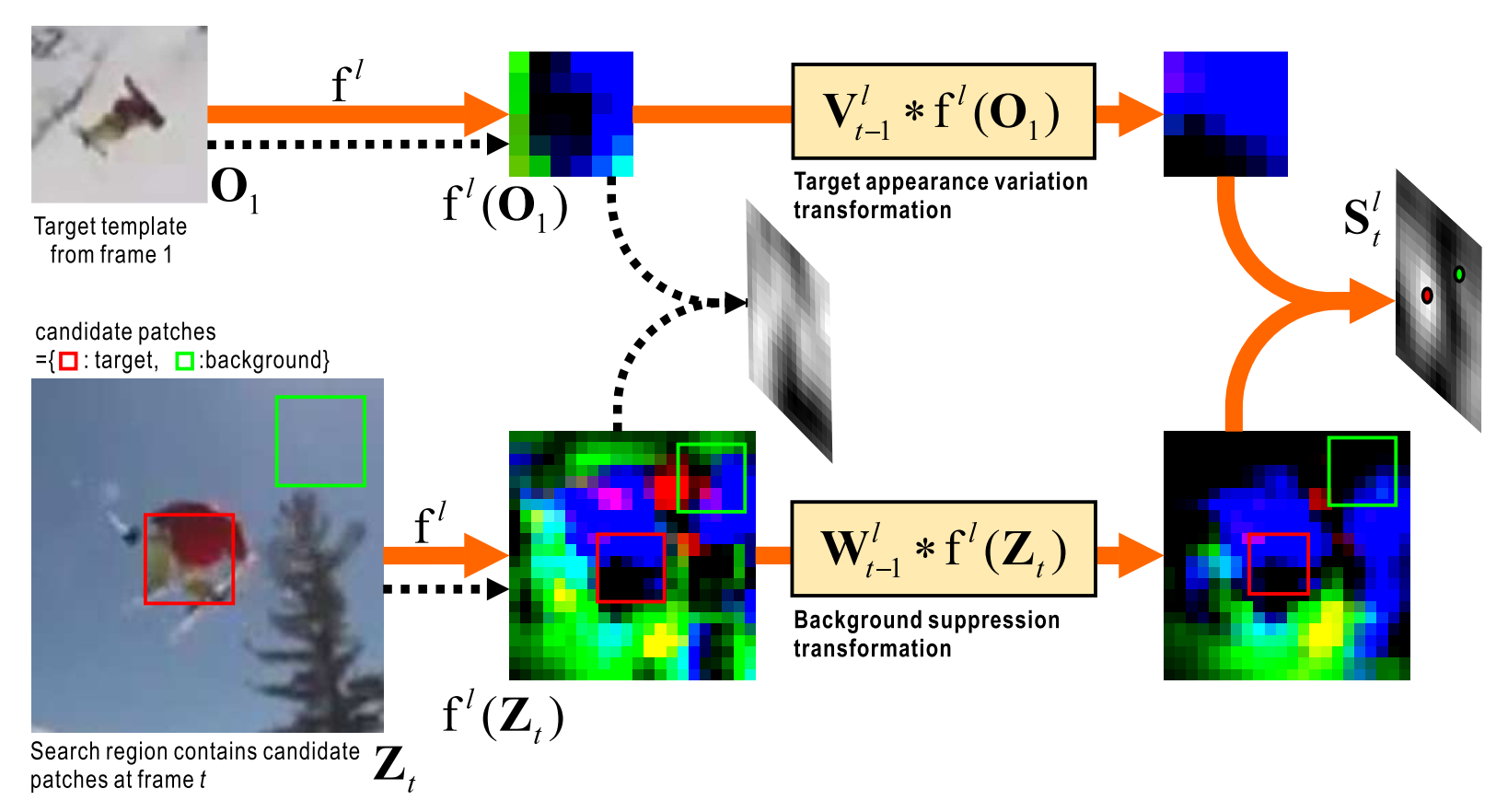
方法:
如何1)有效地学习目标外观的时间变化,2)在保持实时响应的同时排除杂波背景的干扰,是视觉目标跟踪的一个基本问题。本文围绕这个问题提出了目标外观变换层和背景抑制层,名字为动态孪生神经网络(Dynamic Siamese Network, DSiam),即对template image使用目标外观变换层,让其更趋进于当前帧的目标外观,对current image使用背景抑制层,抑制背景带来的跟踪干扰。
目标外观变换层和背景抑制层都是使用的相关滤波方法。
创新点:
-
加入了相关滤波方法的目标外观变换层和背景抑制层
-
模板更新,不再一直使用第一帧模板的特征,有相关滤波的更新过程
-
网络自适应地集成了多层深层特征融合
2. UpdateNet——Learning the Model Update for Siamese Trackers ICCV 2019
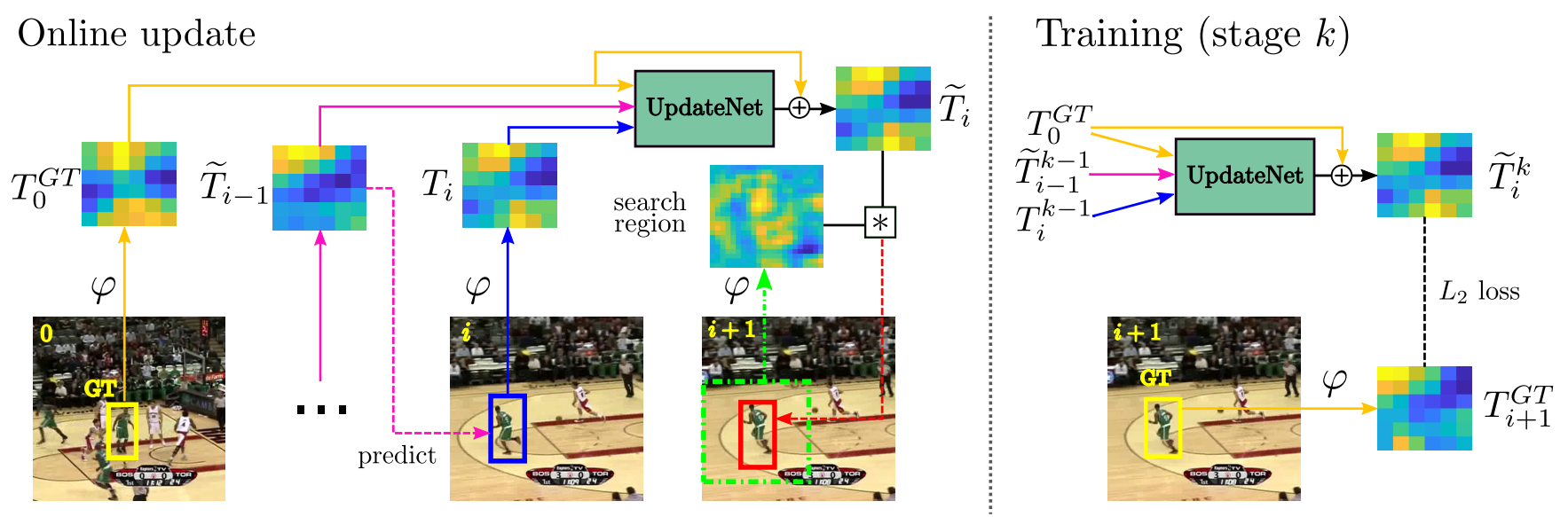
方法:
Siamese方法通过从当前帧中提取一个外观模板来解决视觉跟踪问题,该模板用于在下一帧中定位目标。通常,此模板与前一帧中累积的模板线性组合(最初的SiamFC有且仅使用第一帧目标外观作为模板),导致信息随时间呈指数衰减。虽然这种更新方法已经带来了更好的结果,但它的简单性限制了通过学习更新可能获得的潜在收益。因此,我们建议用一种学习更新的方法来取代线性加权。我们使用卷积神经网络,称为UpdateNet,它给出初始模板、累积预测模板和当前帧的模板,目的是估计下一帧的最佳模板。
不更新模板:
T i ~ = T 0 G T \widetilde{T_i}=T^{GT}_0 Ti =T0GT
线性加权更新模板:
T i ~ = ( 1 − γ ) T ~ i − 1 + γ T i \widetilde{T_i}=(1-\gamma)\widetilde{T}_{i-1}+\gamma{T_i} Ti =(1−γ)T i−1+γTi
UpdateNet更新模板:
T i ~ = ϕ ( T 0 G T , T ~ i − 1 , T i ) \widetilde{T_i}=\phi{(T^{GT}_0,\widetilde{T}_{i-1},T_i)} Ti =ϕ(T0GT,T i−1,Ti)
(左)对象模板的在线更新由UpdateNet执行,UpdateNet接收groundtruth、上次累积模板和当前预测模板作为输入,并输出更新后的累积模板。(右)在下一帧中使用groundtruth模板训练UpdateNet。
创新点:
- 思考了模板更新中存在的问题,提出了一个专门用于更新模板的网络。思考本质性问题很重要!
- 能够非常容易的加入到已有的目标跟踪网络
三、引入回归
1. GOTURN——Learning to Track at 100 FPS with Deep Regression Networks ECCV 2016
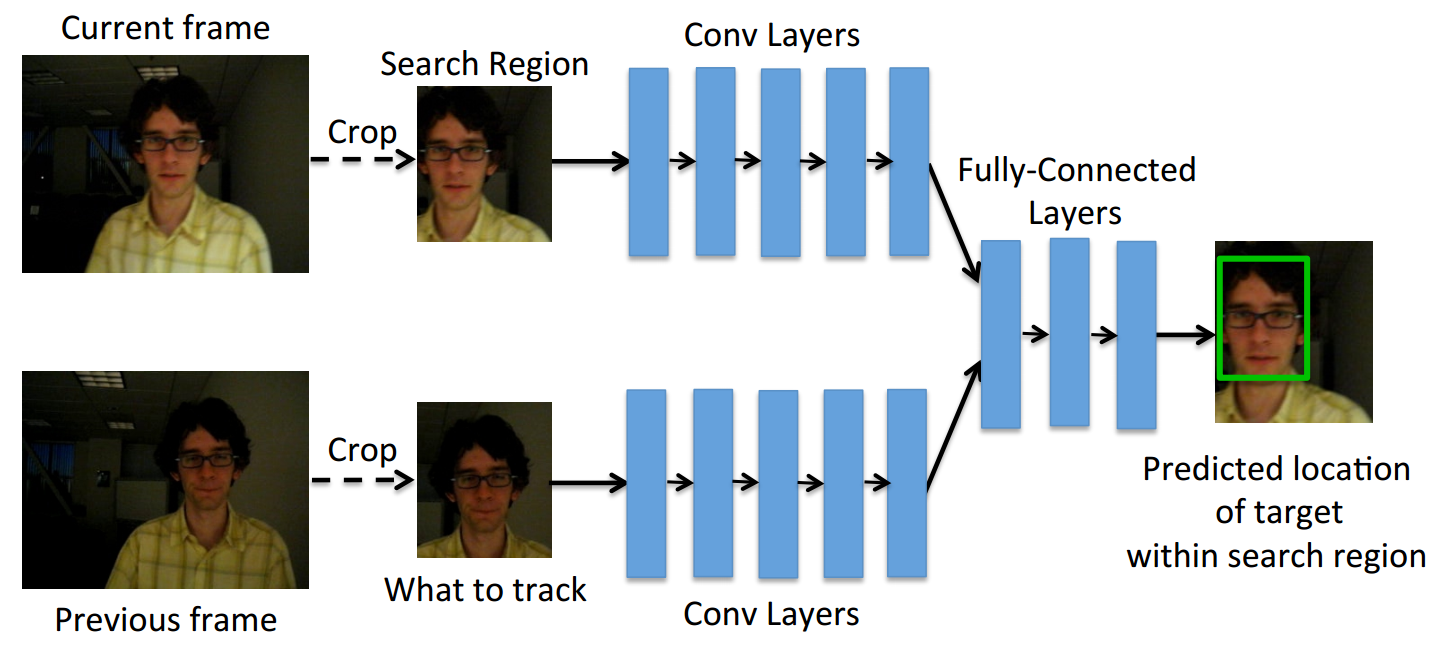
方法:
方法都在图里!仍然是SiamFC范式,在响应图后加入全连接层,直接预测目标位置。FC层的作用是将目标对象中的特征与当前帧中的特征进行比较,以找到目标对象移动的位置。
公式如下:
c x ′ = c x ′ + △ x c^{'}_x=c_x'+\triangle{x} cx′=cx′+△x
c y ′ = c y ′ + △ y c^{'}_y=c_y'+\triangle{y} cy′=cy′+△y
w ′ = γ w × w w^{'}=\gamma_w\times{w} w′=γw×w
h ′ = γ h × h h^{'}=\gamma_h\times{h} h′=γh×h
网络预测 [ △ x , △ y , γ w , γ h ] [\triangle{x},\triangle{y},\gamma_w,\gamma_h] [△x,△y,γw,γh],在SiamFC手动预测 [ △ x , △ y ] [\triangle{x},\triangle{y}] [△x,△y]的基础上,GOTURN网络直接输出偏移量和变换比例,简洁又舒服!!
创新点:
- 结构创新!!!直接输出目标的bbox。GOTURN网络直接输出偏移量和变换比例,简洁又舒服!!(要注意这还是2016的文章)
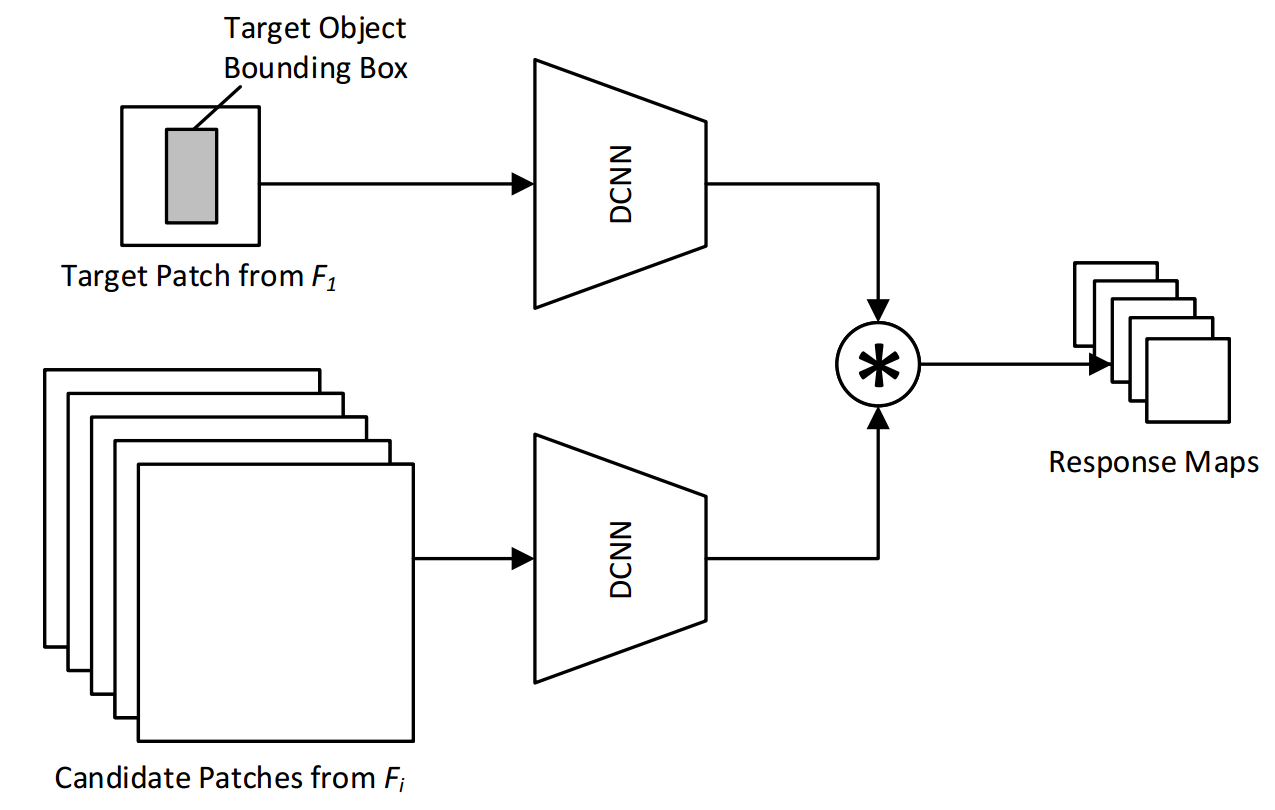
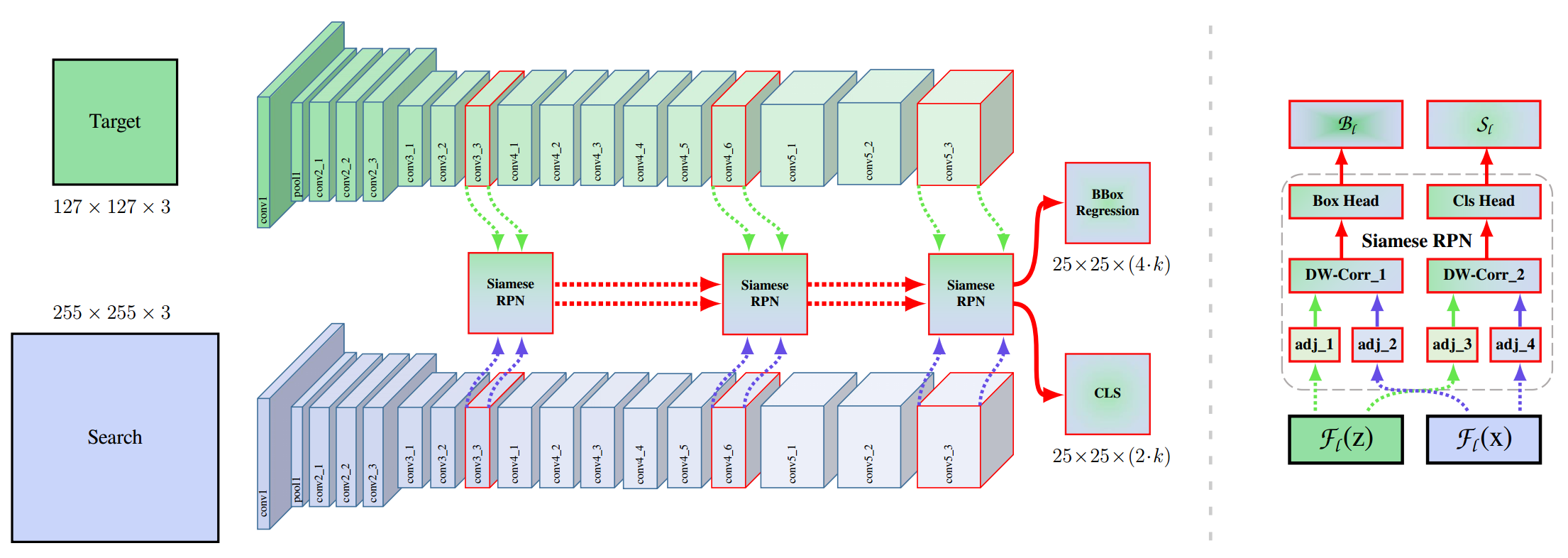
2. SiamRPN——High Performance Visual Tracking with Siamese Region Proposal Network CVPR 2018
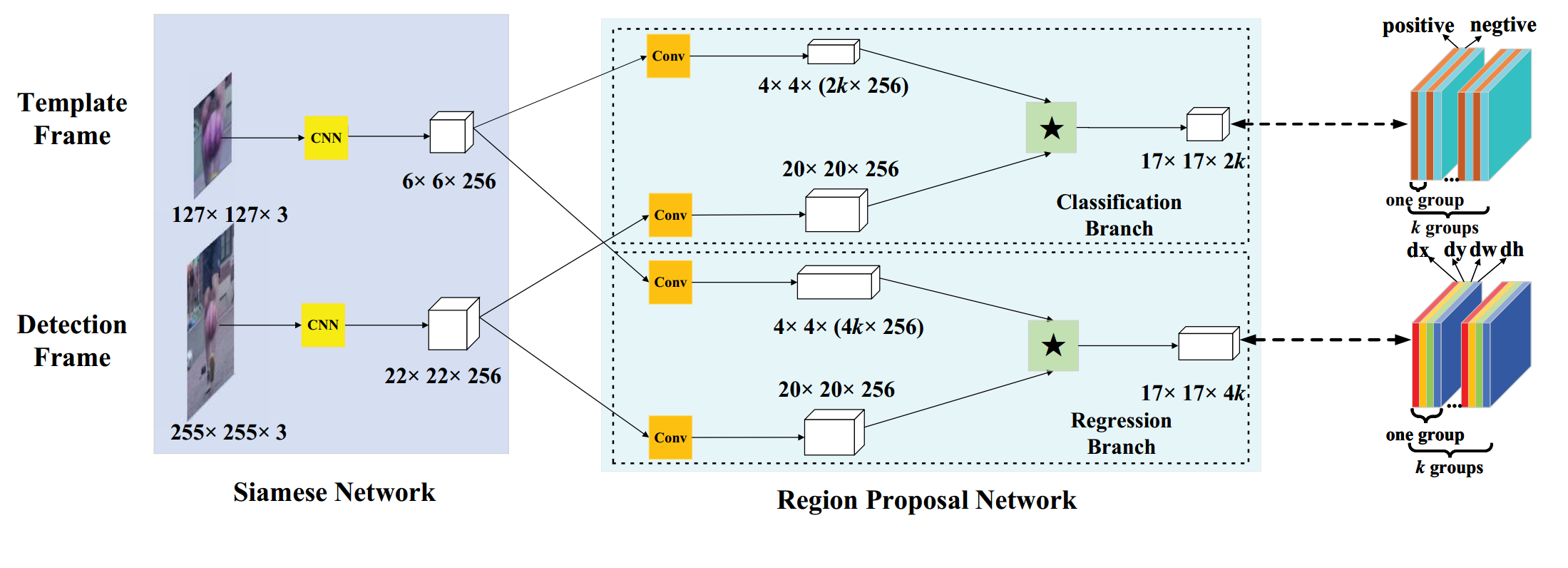
方法:
图中为SiamRPN的框架:左侧是孪生网络(Siamese Network)提取特征。中间是RPN网络(Region Proposal Network),RPN网络有两个分支,一个分支用于回归,另一个分支用于分类。两个分支输出两个互相关的响应图,再通过卷积层分别输出 [ 17 , 17 , 2 k ] [17,17,2k] [17,17,2k]的类别分数, [ 17 , 17 , 4 k ] [17,17,4k] [17,17,4k]的anchor偏移量。
k k k表示anchor的数量
2 k 2k 2k表示每个anchor在分类上有2个输出,即是目标(positive)和非目标(negtive)的分数
4 k 4k 4k表示每个anchor在偏移量上有4个输出,即每个anchor对应真实目标位置d的 [ d x , d y , d w , d h ] [dx,dy,dw,dh] [dx,dy,dw,dh]
[ 17 , 17 ] [17,17] [17,17]表示特征图的大小,也即有 17 ∗ 17 17*17 17∗17个anchor,特征图上每一个点都对应一个anchor
创新点:
- 加入了anchor机制,类似fastercnn的RPN和yolov3系列,网络直接输出特征图上多个不同尺度的anchor的置信度分数和边框回归结果
- 一次训练,端到端,优美之优美,简洁之简洁
3. C-RPN——Siamese Cascaded Region Proposal Networks for Real-Time Visual Tracking CVPR 2019
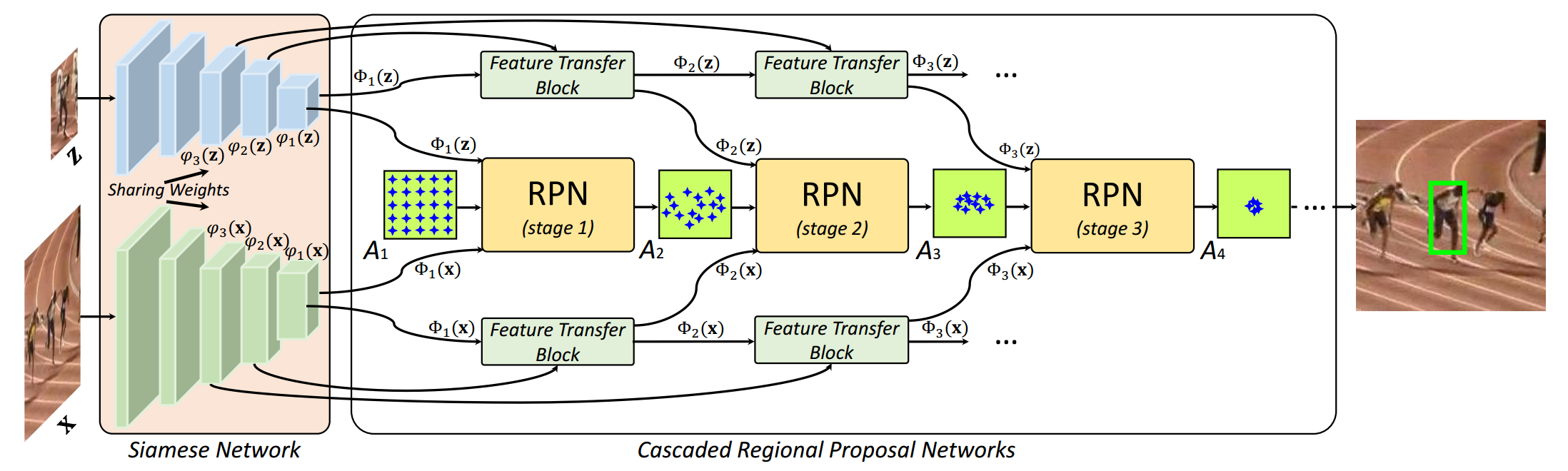
方法:
SiamRPN在存在类似干扰物和大的变化(形变、光照等原因)时,效果不佳,为了应对此问题,文章提出了Siamese Cascaded RPN(C-RPN),即在SiamRPN基础上,多层特征图上都进行了RPN操作,并一级接一级连在一块,称为级联。
- 每个RPN都使用前一阶段的RPN输出进行训练,这样的过程会促进难例负样本的采样(hard negative sampling),从而平衡训练样本。因此,RPN在区分困难背景(即类似的干扰因素)方面具有更高的辨别力。
- 提出feature transfer block,可以利用多级特征,提高网络可分辨性,同时使用高层和低层信息。
- 通过多次回归,边框定位更准确。
创新点:
- 使用多层特征进行跟踪,有点类似特征金字塔的感觉,即高层特征和低层特征关注的内容不同,使用多尺度特征能提取出更多信息
- 这种RPN结果的级联有点faster rcnn二阶段的感觉,即RPN提取后再回归和识别一次,多次回归和识别,定位更精准。
- 由于有多层RPN网络,需要先训练第一层,再训练下一层,以此类推。。如果说faster rcnn是两阶段算法,那SiamRPN就是N阶段算法。
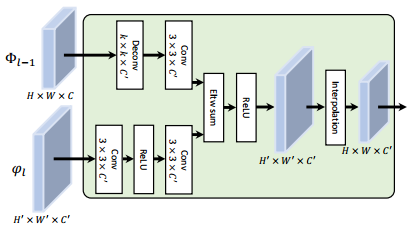
4. SiamRPN++——SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks CVPR 2019
方法:
文章提到,当网络过深时,反而会影响跟踪性能。发现潜在的原因主要是由于孪生网络跟踪的内在限制,因此,在引入所提出的孪生跟踪网络模型之前,我们首先对孪生跟踪网络进行了更深入的分析。原因如下:
-
深层网络中的padding操作会破坏严格的平移不变性,RPN需要不对称的特征来进行分类和回归——提出了空间感知采样策略,即不再以图像中心为groundtruth进行训练,而是在中心周围进行均匀分布的偏移。文中取便宜量 [ 0 , 16 , 32 ] [0, 16, 32] [0,16,32]来进行验证,证明此方法有效地缓解了padding方法对严格平移不变性的破坏
-
普通的互卷积例如SiamFC中search image的 [ 128 , 22 , 22 ] [128,22,22] [128,22,22]与exemplar image的 [ 128 , 6 , 6 ] [128,6,6] [128,6,6]的互卷积操作,每个 [ 1 , 6 , 6 ] [1,6,6] [1,6,6]卷积核都要和128个特征切片进行卷积,这样的卷积操作会进行128*128次。因此文中提出采用Depth-wise的卷积方法,即逐通道卷积,这样的话就只需要进行128次卷积,即一个exempalr特征切片对应一个search特征切片。复杂度大大降低。
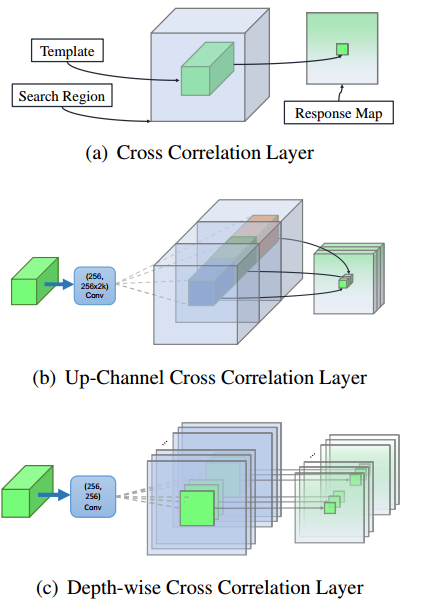
创新点:
- 和C-RPN很像,都采用了RPN的级联操作
- 提出了Depth-wise Cross Correlation Layer,能有效减少卷积时的复杂度,应该比C-RPN中的Feature Transfer Block复杂度要低
- 探讨了网络深度不能加深的问题,只面问题,提出了空间感知采样策略
5. SiamMask——Fast Online Object Tracking and Segmentation: A Unifying Approach CVPR 2019
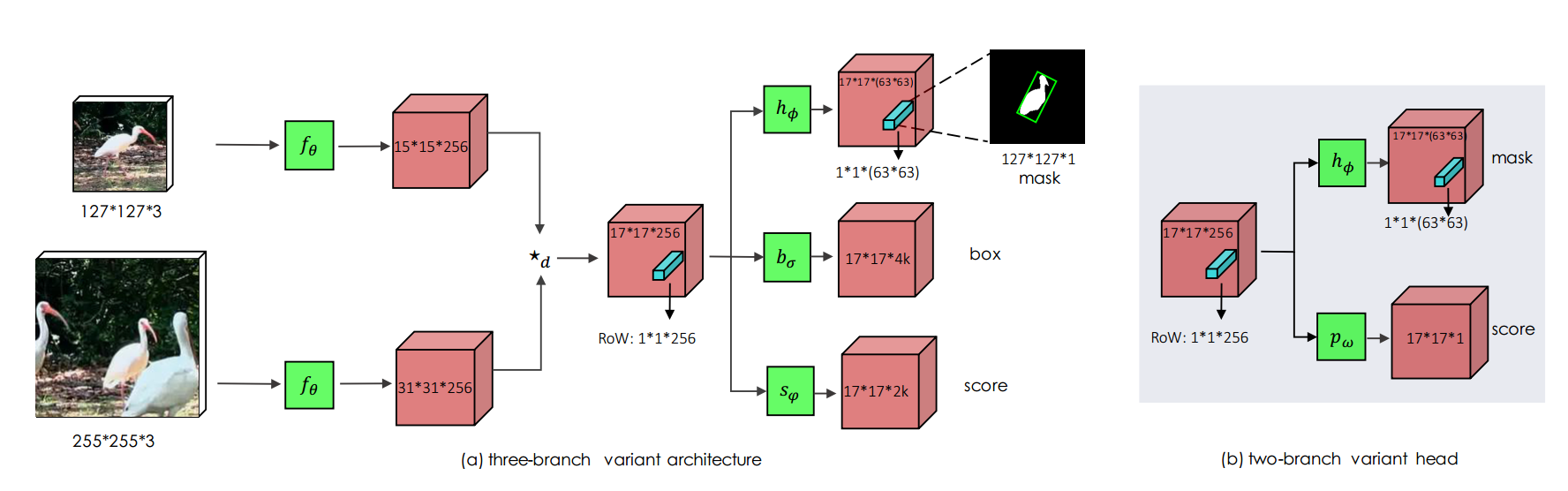
方法:
- 互卷积操作采用SiamRPN++中的Depth-wise Cross Correlation Layer
- 以SiamRPN为基础,加入mask head,由于只有一层RPN,可以一次端到端训练
- mask head不仅能用于分割,也能帮助跟踪
创新点:
- 能分割!之前那么多的论文都没有能分割的!这个能!
额。。。。分割的论文没咋看,还不了解分割的具体过程
6. SiamFC++——SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines AAAI 2020
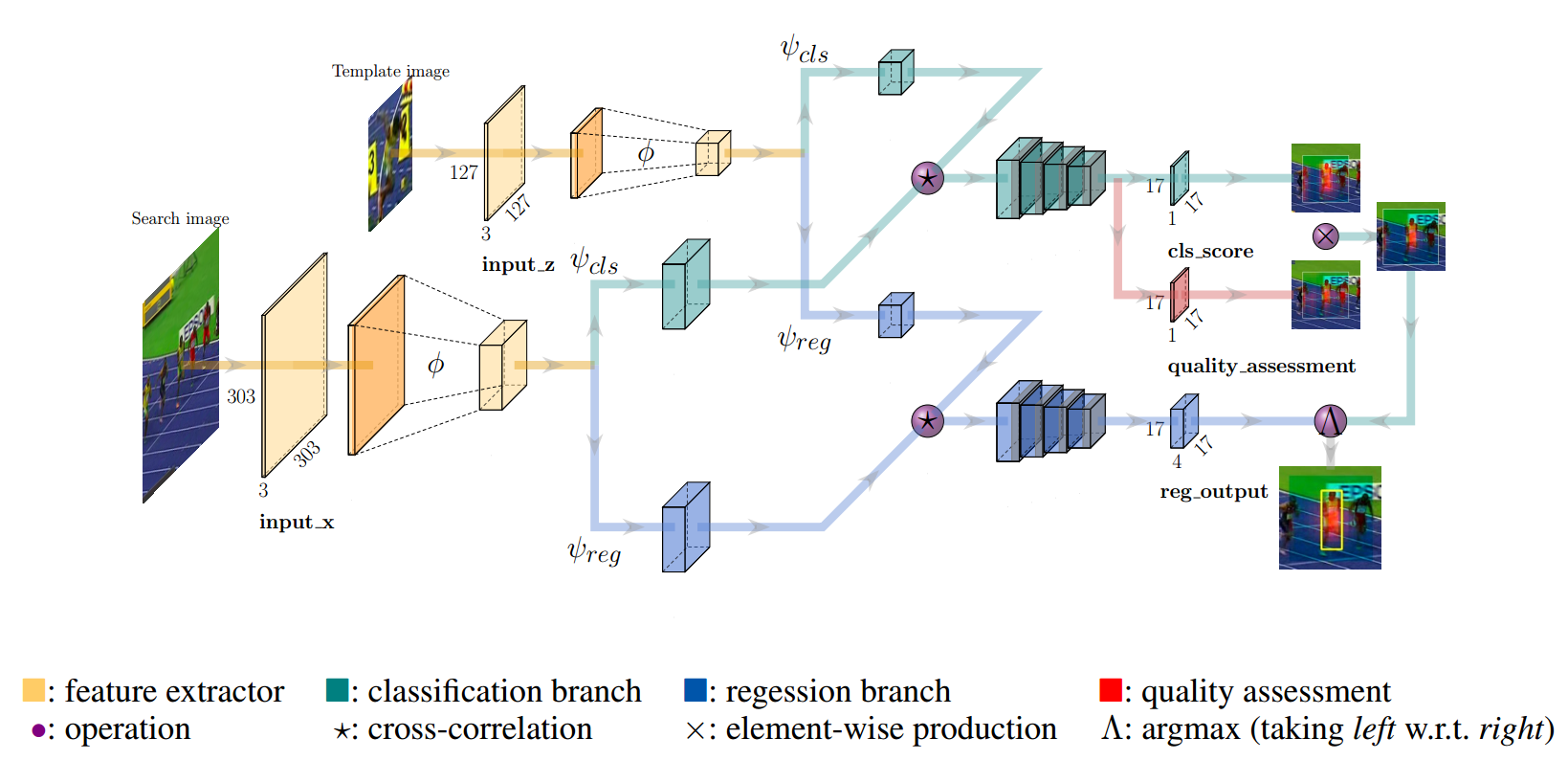
方法:
- 整体结构和SiamRPN类似,都是先提取特征,再互卷积,再添加卷积层输出回归和类别结果,但增加了quality assessment分支,强化回归效果(目标检测中的anchor free算法的FCOS中也有类似结构)
创新点:
- 很像FCOS,很像。。。很像。。。将FCOS的trick用于跟踪
- 加入了FCOS中的中心度公式,增加网络辨别能力
四、网络分析
1. DaSiamRPN——Distractor-aware Siamese Networks for Visual Object Tracking ECCV 2018

方法:
作者提出,高质量的训练数据对于视觉跟踪中端到端表征学习的成功至关重要,主要解决了正负样本不均衡和样本丰富性的问题。有以下三点:
- 不同类别的positive pairs可以提高泛化能力——从目标检测数据集中生成图像对用于训练
- 语义的negative pairs可以提高判别能力——加入更具有训练意义的semantic negative pairs。构建的negative pairs由相同类别和不同类别的目标组成。来自不同类别的negative pairs可以帮助跟踪器避免在视野之外、完全遮挡情况下漂移到任意对象,而来自相同类别的negative pairs使跟踪器专注于细粒度表示。
- 为视觉跟踪定制有效的数据增强——为了充分发挥孪生网络的潜力,我们为训练定制了几种数据增强策略。除了常见的平移、尺度变化和光照变化外,我们观察到网络中的浅层可以很容易地模拟运动模式。我们在数据增强中引入了运动模糊。
创新点:
深度学习包含数据和模型两部分,该论文从数据出发,发现数据中的缺漏,并查漏补缺。
2. Siam-DW——Deeper and Wider Siamese Networks for Real-Time Visual Tracking CVPR 2019
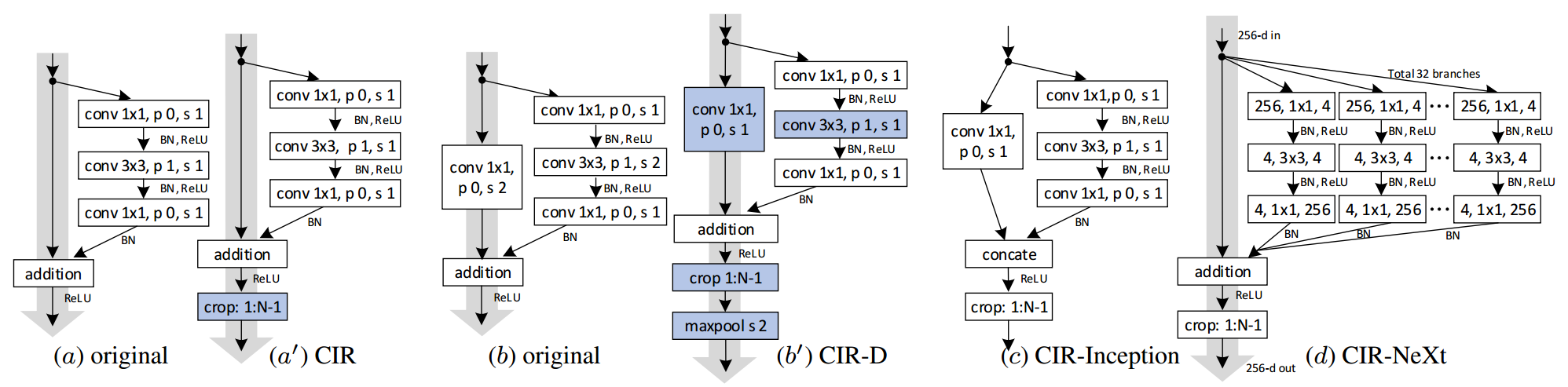
方法:
和SiamRPN++有共同之处,即思考了网络无法加深的具体原因,得出结论:
- 神经元感受野的大幅度增加导致特征辨别能力和定位精度降低
- 卷积的padding操作会导致学习中的位置出现偏差。
和SiamRPN++的数据增强方式不同,网络提出了一种网络中的块结构,修改了ResNet中的Residual块和GoogleNet中的Inception块。具体方法是怎么填充的怎么删,网络中填充了1padding,那么在块结构输出中,将特征图的大小crop出1padding操作的大小。
The cropping operation removes features whose calculation is affected by the zero-padding signals
裁剪操作将删除其计算受零填充信号影响的特征
创新点:
- 思考了网络无法加深的原因,并给出了具体的解答

















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









