






 本文探讨了在面试中常见的数组第k大数问题,通过快排加二分、堆排序和优先级队列三种方法求解,并对比了它们的时间复杂度,提供了详细的代码示例和理论分析。
本文探讨了在面试中常见的数组第k大数问题,通过快排加二分、堆排序和优先级队列三种方法求解,并对比了它们的时间复杂度,提供了详细的代码示例和理论分析。
问题描述
最近很多人提到在面试的时候会考到求一个数组中的第k大的数,方法有很多,从各种排序算法排完取下标的暴力到在排序算法中加入条件得到结果的简便,应有尽有,本文对于暴力的求解方法不作赘述,主要来探讨快排加二分、堆排序、优先级队列的求解方法以及它们之间的对比。
问题求解
快排加二分求解
这种做法也是比较普遍的,具体做法就是,不需要快排整个数组,而是根据目标下标和当前pivot枢轴位置的差异来判断向左递归还是向右递归。具体代码如下:
/**
* @Author:zxp
* @Description:快排加二分求第k大的数
* @Date:20:23 2024/4/29
*/
public class QuickSort {
public static void main(String[] args) {
int[] arr = {2, 3, 8, 1, 4, 9, 10, 7, 16, 14};
System.out.println(getKth(arr, 5));
}
public static int getKth(int[] arr,int k){
int n=arr.length;
quick(arr,0,arr.length-1,k);
return arr[n-k];
}
public static void quick(int[] arr,int left,int right,int k){
if(left>=right)
return;
int l=left,r=right;
int pivot=arr[left];
int n=arr.length;
while (l<r){
while (l<r&&arr[r]>=pivot)
r--;
if(l<r)
arr[l]=arr[r];
while (l<r&&arr[l]<=pivot)
l++;
if(l<r)
arr[r]=arr[l];
if(l==r)
arr[r]=pivot;
}
if(r==n-k)
return;
else if(r>n-k)
quick(arr,left,r-1,k);
else
quick(arr,r+1,right,k);
}
}测试运行结果是8,它是这个无序数组中第5大的数。这个方法通俗来说,就是对本该左右都递归的形式进行了左右阉割,使得执行速度比全排一遍的快排更快,总体的时间复杂度为O(nlogn)。
堆排序算法求解
我们知道堆排序算法在建堆完成之后,每次交换可以得到剩余数中的最大或者最小的值并放到数组最后,基于这个想法,我们可以在取到第k个数的时候就结束,也就是在堆排序中作简单判断就可以得到第k大的数。具体代码如下:
/**
* @Author:zxp
* @Description:堆排序求第k大的数
* @Date:20:23 2024/4/29
*/
public class HeapSort {
public static void main(String[] args) {
int[] arr = {2, 3, 8, 1, 4, 9, 10, 7, 16, 14};
System.out.println(getKth(arr, 5));
}
public static void heapfy(int[] arr,int n,int i){
int left=2*i+1;
int right=2*i+2;
int largest=i;
if(left<n&&arr[left]>arr[largest])
largest=left;
if(right<n&&arr[right]>arr[largest])
largest=right;
if(largest!=i){
int temp=arr[i];
arr[i]=arr[largest];
arr[largest]=temp;
heapfy(arr,n,largest);
}
}
public static int getKth(int[] arr,int k){
int n=arr.length;
for(int i=n/2-1;i>=0;i--){
heapfy(arr,n,i);
}
int curK=0;
for(int i=n-1;i>=0;i--){
int temp=arr[0];
arr[0]=arr[i];
arr[i]=temp;
curK++;
if(curK==k)
return temp;
heapfy(arr,i,0);
}
return 0;
}
}这里我们根据当前的curK值与目标的k值作比较作为交换结束的条件,此处的建堆和交换的逻辑不再赘述。这个做法的时间复杂度比全排序的时间复杂度低很多,条件是k比较小但是n特别大的时候,它的时间复杂度为O(klogn)。
优先级队列求解
优先级队列底层使用到了大根堆或者小根堆,该队列是一个有序的队列,根据底层的实现从队首向后元素递增或者递减。在这里,由于求的是第k大的数,因此只需要维护大小为k的优先级队列就可以了,最后获取队首元素就是最后的结果,因为遍历结束之后,队列中留下的是前k个最大的数,而我们这里的优先级队列实现的是从队首向后递增的队列,底层是小根堆,因此队首元素是这k个最大元素中的最小的,也就是总体的第k大数。具体代码如下:
/**
* @Author:zxp
* @Description:优先级队列求第k大的数
* @Date:20:24 2024/4/29
*/
public class PriorityQueueTest {
public static void main(String[] args) {
int[] arr = {2, 3, 8, 1, 4, 9, 10, 7, 16, 14};
System.out.println(getKth(arr, 5));
}
public static int getKth(int[] arr,int k){
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
int n=arr.length;
for(int i=0;i<n;i++){
if(priorityQueue.size()<k)
priorityQueue.offer(arr[i]);
else {
if(arr[i]>priorityQueue.peek()){
priorityQueue.poll();
priorityQueue.offer(arr[i]);
}
}
}
return priorityQueue.poll();
}
}由于我们这边的优先级队列底层是一个小根堆,大小为看,每次加入元素需要维护这个小根堆,因此维护的成本为O(logk),而有因为需要遍历整个数组,所以总的时间复杂度为O(nlogk)。
方法比较
第一种快排加二分,它的时间复杂度总体上来说还是O(nlogn),因此接下来我们将从堆排序和优先级队列的角度进行时间复杂度的分析比较。
堆排序的时间复杂度为O(klogn),优先级队列的时间复杂度为O(nlogk),乍一看好像没啥区别,无非就是换了个k和n的位置,其实这个交换影响还是比较大的。我们从数学的角度来作一些简单的分析并结合图像来作解释:
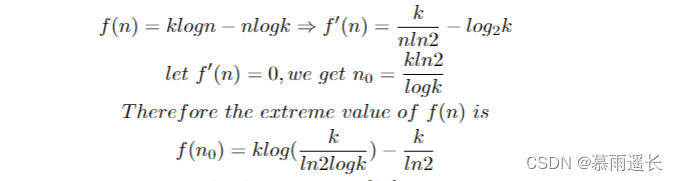
因为CSDN的公式模板好像不太好用,这边我在Latex里写的一段分析。我们构造一个关于n,k的函数,先认为k为常数并对n求导,令导数为零求极值得到结果如上显示,这边对数的底数我们暂时取2,方便计算。我们从导数中发现原函数是一个先增后减的函数,极大值如上所示,和k有关。从这个极值可以进行定性分析,k取一定的值的时候,klogn会在 n0的左侧比nlogk大,然后随着n增大,klogn会比nlogk小;而且k取一定的值的时候,这个极大值可能小于零,意味着至始至终都是klogn小于nlogk。这边的结论是从上述式子中推演出来的,具体是否属实还需要对最后一行这个关于k的函数作分析,但是本人数学能力有限,目前只能做这么多定性分析,如果这边感兴趣的同学可以继续深挖它们的关系,我们根据不同的n,k还做了一幅图像用于辅助理解二者时间复杂度之间的差异,图像如下:
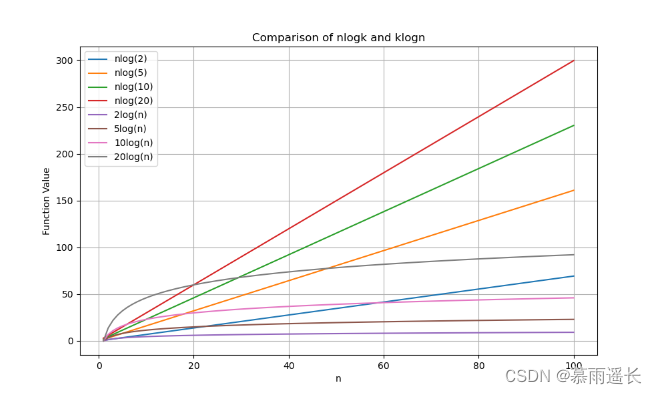
这个图中,我们分别取了n,k为2,5,10,20的交换情况,并作了函数图像。从整体上来看,klogn的时间复杂度相对较低,这一现象在n变大的时候尤为明显,其实很好理解,对数函数的增长速度远低于一次函数的增长函数,但是为了理论依据更充分点,我们在上面也作了数学上的简单分析。
总结
本文针对频繁出现的手撕题:求第k大的数从三个简便算法作了求解,并分析了它们的时间复杂度,对于堆排序和优先级队列的时间复杂度我们还做了进一步的分析,结合理论和图像加深我们对二者复杂度比较的理解。本文我们不仅关注做出此题,还关注了算法的时间复杂度,额外还从导数的角度和图像的角度出发关注了时间复杂度之间的对比,从全方位理解一个算法。最后,大伙如果有什么想法,欢迎评论区留言!!!















 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









