








安装步骤
csdn有很多步骤,搜索即可
卸载步骤
1、在控制面板\程序\程序和功能中卸载程序
2、在MySQL的安装目录下找到my.ini文件中的datadir=C:\ProgramData\MySQL\MySQL Server 8.0\Data
3、在C盘中找到datadir所在路径下所有的MySQL文件即可
启动
1、使用管理员权限打开cmd窗口
2、输入net start mysql即可启动
3、mysql -uroot -p******
4、exit可以退出mysql
4、输入net stop mysql即可关闭服
MySQL目录结构
MySQL安装目录
bin:二进制的可执行文件
data:数据目录
include:C语言的一些头信息
lib:MySQL需要的一些jar包
share:错误信息
my.ini:MySQL的配置文件
MySQL数据目录
数据库 :文件夹
表:文件
数据
SQL
一、Structured Query Language:结构化查询语言
其实就是定义了操作所有关系型数据库的规则。每一种数据库操作的方式存在不一样的地方,称为“方言”
二、SQL通用语法
1、SQL语句可以单行或多行书写,以分号结尾。
2、可使用空格和缩进来增强语句的可读性。
3、MysQL数据库的 SQL语句不区分大小写,关键字建议使用大写。
4、 三种注释
*单行注释: --注释内容或#注释内容(mysql特有)
*多行注释:/*注释 */
三、SQL分类
1)DDL(Data Definition Language)数据定义语言
用来定义数据库对象:数据库,表,列等。关键字: create,drop,alter等
2)DML(Data Manipulation Language)数据操作语言
用来对数据库中表的数据进行增删改。关键字:insert,delete,update 等
3)DQL (Data Query Language)数据查询语言
用来查询数据库中表的记录(数据)。关键字:select,where 等
4) DCL(Data control Language)数据控制语言(了解)
用来定义数据库的访问权限和安全级别,及创建用户。关键字:GRANT,REVOKE等
DDL
操作数据库:CRUD
1、C(Create):创建
create database db1;//创建一个名为db1的数据库
create database if not exists db1;//如果有db1则不创建,没有则创建
create database db1 character set gbk;//创建db1并设置字符集为GBK
create database if not exists db2 character set gbk;//创建db2数据库,判断是否存在,并指定字符集为gbk
2、R(Retrieve):查询
show databases;//查询所有数据库的名称
show create database mysql;//查看对应数据库的字符集
3、U(Update):修改
alter database db3 character set utf8; //修改数据库db3的字符集
4、D(Delete):删除
drop database db3;//删除数据库db3
drop database if exists db3;//判断是否有db3,然后删除
5、使用数据库
select database();//查询当前正在使用的数据库名称
use db1;//使用db1数据库
操作表:CRUD
1、C(Create):创建
create table 表名(
列名1数据类型1,
列名2数据类型2,
. . ..
列名n数据类型n);
注意:最后一列,不需要加逗号(,)
数据库类型:
1. int:整数类型
age int,
2. double:小数类型
score double(5,2)//999.99
3. date:日期,只包含年月日,yyyy-MM-dd
4. datetime:日期,包含年月日时分秒yyyy-MM-dd HH:mm: ss
5. timestamp:时间戳类型包含年月日时分秒yyyy-MM-ddHH : mm : ss
如果将来不给这个字段赋值,或赋值为null,则默认使用当前的系统时间,来自动赋值
6.varchar:字符串
name varchar(20):姓名最大20个字符
zhangsan 8个字符 张三 2个字符
//创建表
create table student(
id int,
name varchar(32),
age int,
score double(4,1),
birthday date,
insert_time timestamp
);

2、R(Retrieve):查询
show tables;//查询某个数据库中所有的表名称
desc plugin;//查询名称为plugin的表结构
3、U(Update):修改
alter table 表名 rename to 新的表名;//修改表名
alter table 表名 character set 字符集名称;//修改表的字符集
alter table 表名 add 列名 数据类型;//添加一列
alter table 表名 change 列名 新列名 新数据类型;//修改列名称+数据类型
alter table 表名 modify 列名 新数据类型;//修改数据类型
alter table 表明 drop 列名;//删除列
4、D(Delete):删除
drop table 表名;//直接删除表
drop table if exists 表名;//判断表是否存在在删除
5、复制表
create table stu like student;//创建一个stu表让它长得和学生表一样
DML
DML:增删改表中的数据
一、添加数据:
INSERT INTO tab_name (col_name) VALUES (要插入的数据,这里是第一行数据), (要插入的数据,这里是第二行数据)...(要插入的数据,第n行数据);
如果id是自增主键(PRIMARY KEY)这就意味着不需要手动填入,它会跟随表格行数进行自己增加
注意:列名和值要一一对应;如果表明后不定义列名,则默认给所有列添加值;除了数字类型,其他类型需要使用引号(单/双引号都可以)

insert into
exam_record_before_2021 (uid, exam_id, start_time, submit_time, score)
select
uid,
exam_id,
start_time,
submit_time,
score
from
exam_record
where
year (submit_time) < '2021'
插入记录:
1、关键字NULL 可以用DEFAULT替代。
2、掌握replace into … values的用法
replace into 跟insert into 功能类似,不同点在于:replace into 首先尝试插入数据到表中。
如果发现表中已经有此行数据(根据主键或唯一索引判断)则先删除此行数据,然后插入新的数据。否则,直接插入新数据
要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现 重复数据。
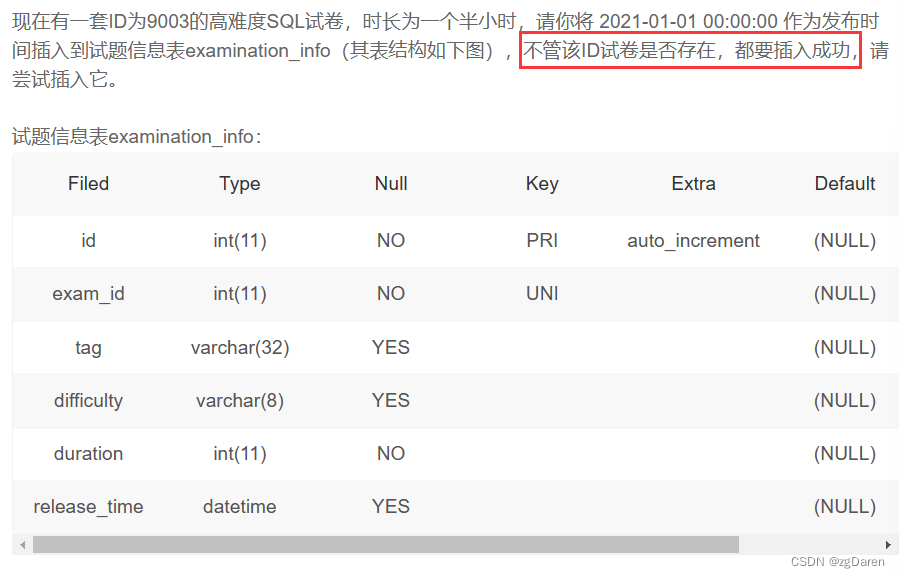
REPLACE INTO examination_info
VALUES(NULL,9003,'SQL','hard',90,'2021-01-01 00:00:00');
二、删除数据:
delete from 表名 where 条件;
注意:如果不加条件,则删除表中所有记录
delete from 表名;//不推荐使用,有多少条记录就会执行多少次删除操作
truncate table 表名;//删除表,然后再创建一个一模一样的空表
时间差
TIMESTAMPDIFF(interval,time_start,time_end)可用于计算time_start-time_end的时间差,单位以指定的interval为准,常用可选:
SECOND秒
MINUTE分钟(返回秒数差除以60的整数部分)
HOUR(返回秒数差除以3600的整数部分)
DAY(返回秒数差除以3600*24的整数部分)
MONTH 月数
YEAR 年数
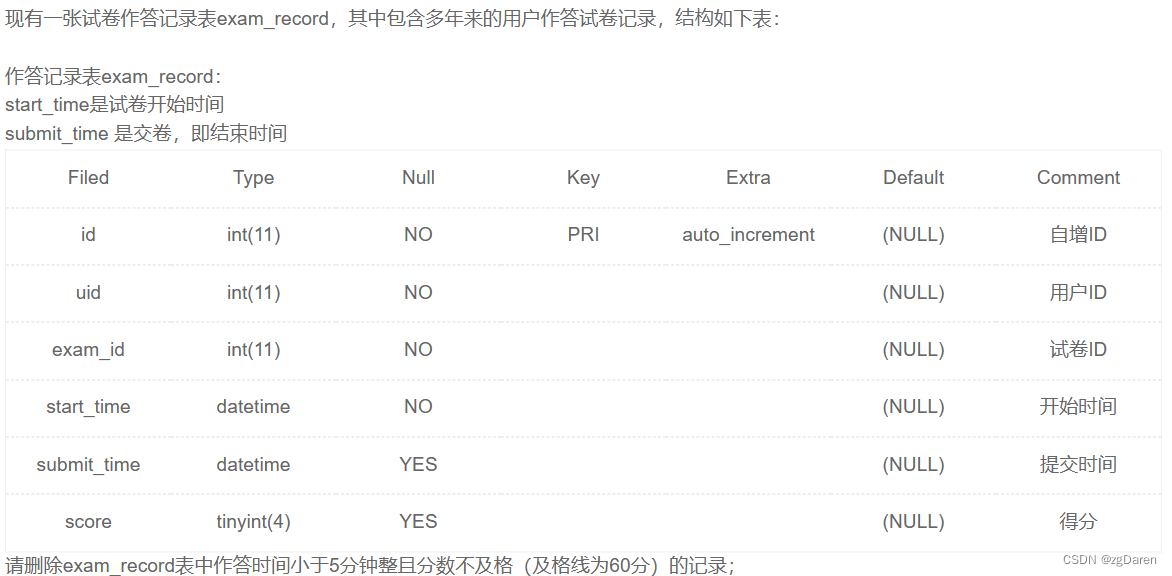
delete from exam_record where TIMESTAMPDIFF(MINUTE,start_time,submit_time)<5 and score<60
处理显示前几条数据案例
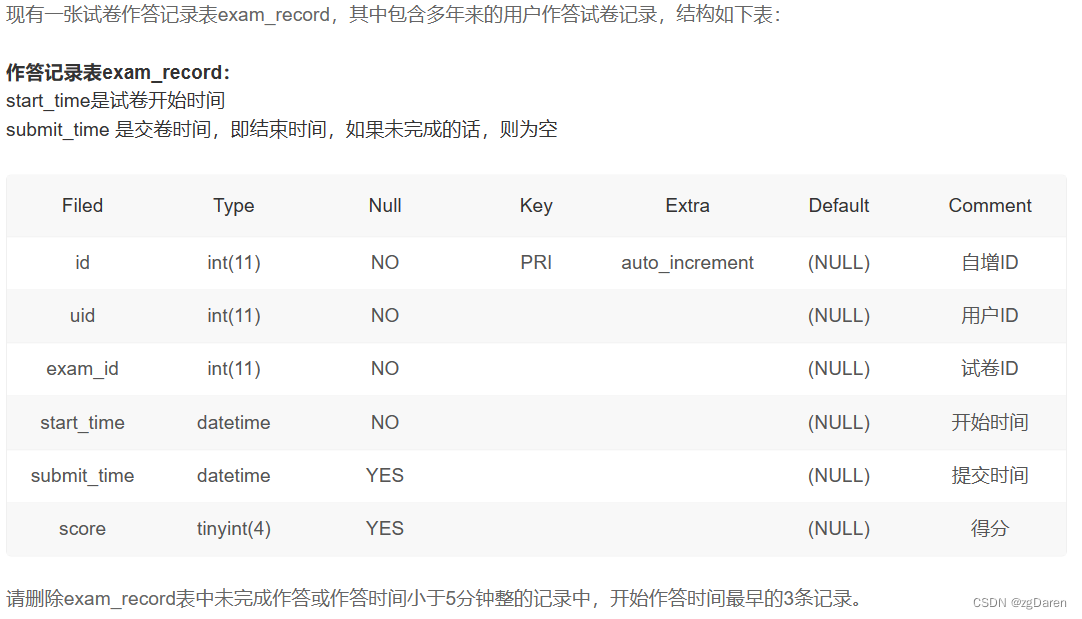
DELETE FROM
exam_record
WHERE
submit_time IS NULL
OR TIMESTAMPDIFF (MINUTE, start_time, submit_time) < 5
ORDER BY
start_time
LIMIT
3;
清空表中数据并重置主键

方式一:TRUNCATE exam_record;
方式二:DELETE FROM exam_record; ALTER TABLE exam_record auto_increment=1;
这里使用到了truncate和delete,下面详细解说区别
关于truncate和delete的区别
1、truncate:删除表中的内容,不删除表结构,释放空间
2、delete:删除内容,不删除表结构,但不释放空间
| 区别 | 详细解释 |
|---|---|
| 内存空间 | truncate删除数据后重新写数据会从1开始,而delete删除数据后只会从删除前的最后一行续写;内存空间上,truncate省空间 |
| 处理速度 | 因为truncate是直接从1开始的,即全部清空开始,而delete需要先得到当前行数,从而进行续写,所以truncate删除速度比delete快 |
| 语句类型 | delete数据DML语句,而drop和truncate都属于DDL语句,这造成了他们在事务中的不同现象:delete在事务中,因为属于DML语句,所以可以进行回滚和提交操作,truncate和drop则属于DDL语句,在事务中,执行后会自动commit,所以可以不回滚 |
| 语法 | delete可以在后续加上where进行针对行的删除 ,truncate和drop后面只能加上表名,直接删除表,无法where |
| drop和truncate不能够激活触发器,因为该操作不记录各行删除; |
三、修改数据:
update 表名 set 列名1 = 值1,列名2 = 值2,...where 条件;
update student set age = 177 where id = 1;
注意:如果不加任何条件,则会将表中所有记录全部修改
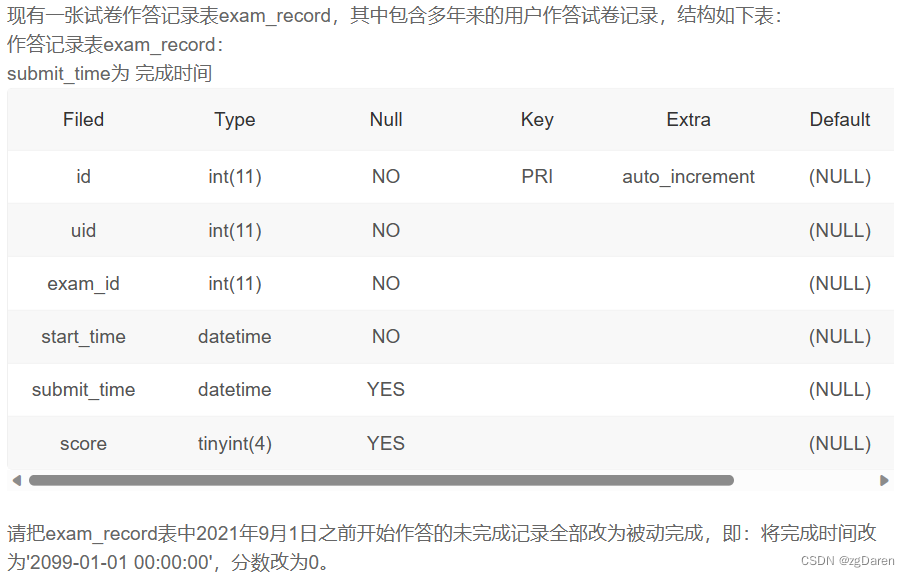
update exam_record set submit_time='2099-01-01 00:00:00',score=0 where start_time<'2021-09-01 00:00:00' and score is null
DQL
语法:
select 字段列表
from 表名列表
where条件列表
group by 分组字段
having 分组之后的条件
order by 排序
limit 分页限定
基础查询:
1、多个字段的查询
如果查询所有字段,则可以使用*来代替字段列表
2、去除重复
distinct
3、计算列
一般可以使用四则运算计算一些列的值(一般只会进行数值型的计算)
ifnull:null参与的结果都为null,所以使用ifnull
4、起别名
as:as也可省略
#查询姓名和年龄
SELECT NAME,age FROM student;
#查询所有的字段名
select * from student;
#查询地址
select address from student;
#去除重复的结果集DISTINCT
select DISTINCT address from student;
#计算math和english的分数之和
select NAME,math,english,math+english from student;
#如果有null参与的运算,计算结果都为null
#如果遇到null,让其为0
select NAME,math,english,math+ IFNULL(english,0) from student;
#起别名 起别名时也可使用空格代替AS
select NAME,math,english,math+ IFNULL(english,0) AS 总分 from student;
条件查询:
#条件查询
#年龄大于20岁
select * from student where age > 20;
#年龄大于等于20岁
select * from student where age >= 20;
#查询年龄等于20岁
select * from student where age = 20;
#查询年龄不等于20岁
select * from student where age != 20;
select * from student where age <> 20;
#查询年龄大于等于20小于等于30
select * from student where age >=20 && age <=30;
select * from student where age >=20 and age <=30;
select * from student where age between 20 and 30;
#查询22岁,19,25岁信息
select * from student where age = 20 or age = 19 or age = 25;
select * from student where age in (22,18,25);
#查询英语成绩为null,
#select * from student where english = null;
#null 值不能使用= (!=)来判断
select * from student where english is null;
#查询英语成绩不为null
select * from student where english is not null;
模糊查询
#模糊查询
#查询姓马的有哪些?like
select * from student where NAME like '马%';
#查询第二个字是化的人
select * from student where NAME like '_化%';
#查询姓名是三个字的人
select * from student where NAME like '___';
#查询姓名中包含马的人
select * from student where NAME like '%德%';
排序查询
#排序 默认升序排列
select * from student order by math;
#ASC为升序 DESC降序
select * from student order by math desc;
select * from student order by math asc;
#按照数学成绩排名,如果数学成绩一样,则按照英语成绩升序排名
select * from student order by math asc,english asc;
聚合函数
#聚合函数:将一列数据作为一个整体,进行列的纵向计算
#注意:聚合函数的计算会排除null的值,一般选择主键统计
#count:计算个数
select count(NAME) from student;
select count(ifnull (english,0)) from student;
#max:计算最大值
select max(math) from student;
#min:计算最小值
select min(math) from student;
#sum:计算和
select sum(math) from student;
select sum(english) from student;
#avg:计算平均数
select avg (math) from student;
分组查询
#分组查询
#按照性别分组,分别按照男、女同学的平均分
#分组之后查询的字段:分组字段,聚合字段
select sex,avg(math)from student group by sex;
#按照性别分组,分别按照男、女同学的平均分,分别的人数
select sex,avg(math),count(id) from student group by sex;
#按照性别分组,分别按照男、女同学的平均分,分别的人数,分数低于70分的人不参与分组
select sex,avg(math),count(id) from student where math>70 group by sex;
#按照性别分组,分别按照男、女同学的平均分,分别的人数,分数低于70分的人不参与分组,分组之后人数大于2个人
select sex,avg(math),count(id) from student where math>70 group by sex having count(id) > 2;
#where在分组之前进行限定,如果不满足条件不参与分组
#having在分组之后进行限定,如果不满足结果则不会被查询出来
#where后不可以跟聚合函数,而having可以跟聚合函数
分页查询
#分页查询limit
#每页显示三条数据
select * from student limit 0,3;--第一页
select * from student limit 3,3;--第二页
#公式:开始的索引= (当前的页码-1)*每页显示的条数
#limit是mysql的方言
表的约束
概念:对表中的数据进行限定,保证数据的正确性,有限性和完整性
分类:
1、主键约束:primary key
2、非空约束:not null
3、唯一约束:unique
4、外键约束:foreign key
主键约束
非空并唯一:一张表只能有一个字段为主键,主键就是表中记录的唯一标识
#创建表时,添加主键约束
create table stu(
id int primary key,--添加了id为主键约束
phone_number varchar(20)
);
#删除主键约束
alter table stu drop primary key;
#创建表之后,添加主键约束
alter table stu modify id int primary key;
自动增长
如果某一列是数值类型的,使用auto_increment可以来完成值的自动增长
在创建表时,添加主键约束,并且完成主键自增长,而且自动增长只会和上一条数据有关系
#创建表时,添加主键约束
create table stu(
id int primary key auto_increment,
phone_number varchar(20)
);
select * from stu;
#当添加id为空时,也是会自动增长的
insert into stu values(null,'ccc');
#删除自动增长
alter table stu modify id int;
#添加自动增长
alter table stu modify id int auto_increment;
非空约束
1、创建表时添加约束
create table stu(
id int,
name varchar(20) not null --name为非空
);
#删除约束
alter table stu modify name varchar(20);
2、创建完表后,添加非空约束
alter table stu modify name varchar(20) not null;
唯一约束
注意:mysql中,唯一约束限定的列的值可以有多个null
#创建表时,添加唯一约束
create table stu(
id int,
phone_number varchar(20) unique --添加了唯一约束
);
#删除唯一约束
alter table stu drop index phone_number;
#创建表之后,添加唯一约束
alter table stu modify phone_number varchar(20) unique;
外键约束
foreign key,让表与表产生关系,从而保证数据的正确性
1、在创建表时,可以添加外键
create table 表名(
...
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称);
2、删除外键
alter table 外键所在的表名称 drop foreign key 外键名称;
3、添加外键
alter table 外键所在的表名称 add constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称);
级联操作
级联更新:on update cassade
级联删除:on delete cassade
1、添加级联操作
级联更新
alter table 外键所在的表名称 add constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称) on update cassade;
级联删除
alter table 外键所在的表名称 add constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称) on delete cassade;
多表操作
多表之间的关系
一对一:人和身份证 (一个人只有一个身份证,一个身份证只能对应一个人)
一对多:部门和员工(一个部门对应多个员工,一个员工只能对应一个部门)
多对多:学生和课程(一个学生可以选择很多课程,一个课程也可以被很多学生选择)
实现关系:
一对一:可以在任意一方添加唯一外键指向另一方的主键
一对多:在多的一方建立外键,指向一的一方的主键
多对多:需要建立一个中间表,中间表至少包含两个字段,作为中间表的外键,分别指向两张表的主键。(primary key(rid,uid)–联合主键)
三大范式
概念:设计数据库时需要遵循的一些规范,要尊选后边的范式要求,必须先遵循前边的所有范式要求。
设计关系型数据库时,遵循不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有6中范式,第一范式1NF、第二范式2NF、第三范式3NF、巴斯-科德范式BCNF、第四范式4NF、第五范式5NF
第一范式:每一列都是不可分割的原子数据项

第二范式:在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)

1、函数依赖:A->B,如果通过A属性(属性组)的值,可以确定唯一B属性的值,则称B依赖于A。
如,学号->姓名(学号,课程名称)->分数
2、完全函数依赖:A->B,如果A是一个属性组,则B属性值的确定需要依赖A属性组中所有的属性值。
如:(学号,课程名称)->分数
3、部分函数依赖:A->B,如果A是一个属性组,则B属性值的确定只需要依赖A属性组中某一些值即可。
如:(学号,课程名称)->姓名
4、传递函数依赖:A->B,B->C,如果通过A属性(属性组)的值,可以确定唯一B属性的值,然后通过B属性(属性组)的值,可以确定唯一C属性的值,则程C传递函数依赖于A
如:学号->系名->系主任 系主任传递依赖于学号
5、码:如果在一张表中一个属性或属性组被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
如:(学号,课程名称)为码
主属性:码属性组中的所有属性
非主属性:除过码属性组的属性
第三范式:在2NF基础上,任何非主属性不依赖其他非主属性(在2NF基础上消除传递依赖)

数据库的备份和还原
命令行
备份:mysqldump -u用户名 -p密码 数据库名称>保存的路径
还原:登录数据库、创建数据库、使用数据库、执行文件(source 文件路径)
#备份到d://a.sql
mysqldump -uroot -proot db1>d://a.sql
#登录数据库进行查看
mysql -uroot -proot
#查看数据库
show databases;
#删除db1
drop database db1;
#再次查看数据库已没有了db1
show databases;
#创建一个名为db1的数据库
creat database db1;
#使用db1数据库
use db1;
#进行还原
source d://a.sql
图形化工具直接CSDN搜索对应的让软件就行
多表查询
笛卡尔积:有两个集合A,B,取这两个集合的所有组成情况。要完成多表查询,需要消除无用的数据,就需要使用以下三种多表查询
内连接查询
1、隐式内连接:使用where条件消除无用数据
#查询所有员工信息和对应部门信息
SELECT * from emp,dept where emp.dept_id = dept.id;
# 查询员工表的名称,性别,部门表的名称
# 两个表中都有name属性需要在属性名前加对应的表名
select emp.NAME ,gender, dept.name from emp,dept where emp.dept_id = dept.id;
# 使用别名进行替换表名
select
t1.name,t1.gender,t2.name
from
emp t1,dept t2
where
t1.dept_id = t2.id;
2、显式内连接:
#查询所有员工信息和对应部门信息
select * from emp inner join dept on emp.dept_id = dept.id;
#inner是可以省略的
select * from emp join dept on emp.dept_id = dept.id;
#起别名的操作和隐式连接是一样的
外连接查询
1、左外连接
#查询所有员工信息,如果员工有部门,则查询部门名称,没有部门则不显示部门名称
# 查询的是左表所有数据以及其交集部分
select t1.*,t2.name from emp t1 left join dept t2 no t1.dept_id = t2.id;
2、右外连接
# 查询的是右表所有数据以及其交集部分
select * from dept t2 right join emp t1 on t1.dept_id = t2.id;

left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
inner join(等值连接) 只返回两个表中联结字段相等的行
子查询
子查询:查询中嵌套查询,称嵌套查询为子查询
#查询工资最高的员工信息
#查询最高的工资是多少?
select max(salary) from emp;
#查询员工信息,并且工资等于9000的
select * from emp where emp.salary = 9000;
# 使用一条sql完成以上操作 子查询
select * from emp where emp.salary = (select max(salary) from emp);
子查询的不同情况
1、子查询的结果是单行单列的:
子查询可以作为条件,使用运算符去判断
#查询员工工资小于平均工资的人
select * from emp where emp.salary < (select avg (salary) from emp);
2、子查询的结果是多行单列的:
#查询财务部所有员工信息
select id from dept where name = '财务部' ;
select * from emp where dept_id = 3;
#查询财务部和市场部所有员工信息
select id from dept where name = '财务部' or name = '市场部';
select * from emp where dept_id = 3 or dept_id = 2;
#使用一条sql完成以上操作,使用运算符in来判断
select * from emp where dept_id in (3,2);
select * from emp where dept_id in (select id from dept where name = '财务部' or name = '市场部');
3、子查询的结果是多行多列的:
多行多列子查询可以作为一个虚拟表进行查询
#子查询
# 查询员工入职日期是2011-11-11日之后的员工信息和部门信息
select * from emp where emp.join_date > '2011-11-11';
select * from dept t1,(select * from emp where emp.join_date > '2011-11-11') t2 where t1.id = t2.dept_id;
# 普通内连接
select * from emp t1,dept t2 where t1.dept_id = t2.id and t1.join_date > '2011-11-11';
union和union all的区别
union和union all的区别是,union会自动压缩多个结果集合中的重复结果,而union all则将所有的结果全部显示出来,不管是不是重复。
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。
实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了
使用union组合查询时,只能使用一条order by字句,他必须位于最后一条select语句之后,因为对于结果集不存在对于一部分数据进行排序,而另一部分用另一种排序规则的情况。
查找山东大学或者性别为男生的信息
SELECT
device_id,
gender,
age,
gpa
FROM
user_profile
WHERE
university = '山东大学'
UNION ALL
SELECT
device_id,
gender,
age,
gpa
FROM
user_profile
WHERE
gender = "male"
CASE 函数
CASE函数是一种多分支的函数,可以根据条件列表的值返回多个可能的结果结果表达式中的一个。
可用在任何允许使用表达式的地方,但不能单独作为一个语句执行。
简单CASE函数
CASE 测试表达式
WHEN 简单表达式1 THEN 结果表达式1
WHEN 简单表达式2 THEN 结果表达式2 …
WHEN 简单表达式n THEN 结果表达式n
[ ELSE 结果表达式n+1 ]
END
计算测试表达式,按从上到下书写顺序将测试表达式的值与每个WHEN子句的简单表达式进行比较。
如果某个简单表达式的值与测试表达式的值相等,则返回第一个与之匹配的WHEN子句所对应的结果表达式的值。
如果所有简单表达式的值与测试表达式的值都不相等,若指定了ELSE子句,则返回ELSE子句中指定的结果表达式的值。
若没有指定ELSE子句,则返回NULL。
1、查询班级表中的学生的班级号、班名、系号和班主任号,并对系号作如下处理。
当系号为1,显示“计算机系”
当系号为2,显示“软件工程系”
当系号为3,显示“物联网系”
SELECT 班号 ,班名,
CASE 系号
WHEN 1 THEN '软件工程系'
WHEN 2 THEN '计算机系'
WHEN 3 THEN '物联网系'
END AS 系号,班主任号
FROM 班级表
搜索CASE函数
CASE
WHEN 布尔表达式1 THEN 结果表达式1
WHEN 布尔表达式2 THEN 结果表达式2 …
WHEN 布尔表达式n THEN 结果表达式n
[ ELSE 结果表达式n+1 ]
END
按从上到下的书写顺序计算每个WHEN子句的布尔表达式
返回第一个取值为TRUE的布尔表达式所对应的结果表达式的值
如果没有取值为TRUE的布尔表达式,则当指定了ELSE子句时,返回ELSE子句中指定的结果。
如果没有指定ELSE子句,则返回NULL。
用搜索CASE来做上面的例子
SELECT 班号 ,班名,
CASE
WHEN 系号=1 THEN '软件工程系'
WHEN 系号=2 THEN '计算机系'
WHEN 系号=3 THEN '物联网系'
END AS 系号,班主任号
FROM 班级表
计算25岁以上和以下的用户数量
运营想要将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户的数量。

使用搜索CASE完成
SELECT CASE WHEN age < 25 OR age IS NULL THEN '25岁以下'
WHEN age >= 25 THEN '25岁及以上'
END age_cut,COUNT(*)number
FROM user_profile
GROUP BY age_cut
使用if判断
SELECT
IF (age >= 25, "25岁及以上", "25岁以下") AS age_cut,
count(*) AS number
FROM
user_profile
GROUP BY
age_cut;
extract()函数
EXTRACT()函数用于返回日期/时间的单独部分,比如年、月、日、小时、分钟等。
EXTRACT(unit from date) date参数是合法的日期表达式,unit参数可以是下列的值。
MISCROSECOND、SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER、YEAR、SECOND_MICROSECOND、MINUTE_MICROSECOND、MINUTE_SECOND、HOUR_MICROSECOND、HOUR_SECOND、HOUR_MINUTE、DAY_MICRO、YEAR_MONTH
假设我们有如下表

计算用户8月天的练题数量
现在运营想要计算出2021年8月每天用户练习题目的数量,请去除相应数据。

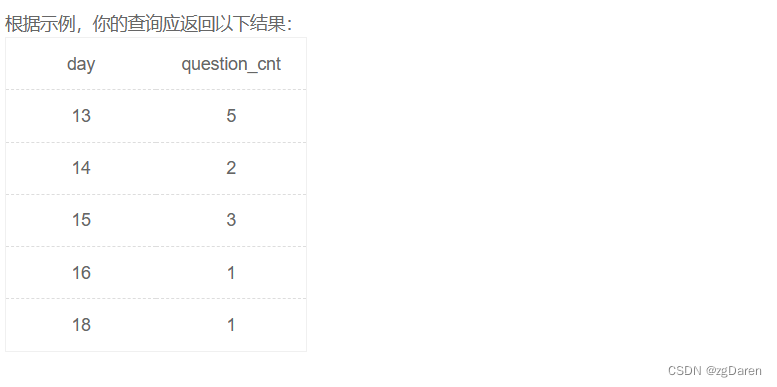
select
EXTRACT(day from date) day,
count(question_id) question_cnt
from
question_practice_detail
where
month (date) = 8
and year (date) = 2021
group by
date
字符串截取之substring_index
substring_index(str,delim,count) str:要处理的字符串,delim:分隔符,count:计数
例如:某个字段为 str=www.zgdaren,com
substring_index(str,'.',1) 结果是:www
substring_index(str,'.',2) 结果是:www.zgdaren
也就是说,如果count是正数,那么就是从左往右数,第N个分隔符的左边的全部内容相反,如果是负数,那么就是从右边开始数,第N个分隔符右边的所有内容,如:
substring_index(str,'.',-2) 结果是zgdaren.com
如果要取中间的zgdaren,则需要从两个方向取
从右数第二个分隔符的右边全部,再从左数的第一个分隔符的左边:
substring_index(substring_index(str,'.',-2),'.',1);
1、字符串截取:substring(字符串,起始位置,截取字符数)
2、字符串的拼接:concat(字符串1,字符串2,字符串3,…)
3、字母大写:upper(字符串) 字母小写:lower(字符串)

select
cust_id,
cust_name,
upper(
concat (
substring(cust_name, 1, 2),
substring(cust_city, 1, 3)
)
) user_login
from
Customers
统计每种性别的人数
现在运营举办了一场比赛,收到了一些参赛申请,表数据记录形式如下所示,现在运营想要统计每个性别的用户分别由多少参赛者,请取出相应结果。

SELECT SUBSTRING_INDEX(profile,",",-1) gender,COUNT(*) number
FROM user_submit
GROUP BY gender;

select
-- 替换法 replace(string, '被替换部分','替换后的结果')
-- device_id, replace(blog_url,'http:/url/','') as user_name
-- 截取法 substr(string, start_point, length*可选参数*)
-- device_id, substr(blog_url,11,length(blog_url)-10) as user_nam
-- 删除法 trim('被删除字段' from 列名)
-- device_id, trim('http:/url/' from blog_url) as user_name
-- 字段切割法 substring_index(string, '切割标志', 位置数(负号:从后面开始))
device_id, substring_index(blog_url,'/',-1) as user_name
from user_submit;
在数据库中统计常用的函数是count()和sum()
1、count:count是用来计数的,是求行的和。例如:分页中的总条数。
SELECT count(*) FROM 表名
2、sum:sum只会把结果为true也就是1的数据进行求和,sum是求列的和。例如:求某列的值等于1的数量。
SELECT SUM(列名 = 1) as 别名 FROM 表名
IF 表达式
IF( expr1 , expr2 , expr3 )
expr1 的值为 TRUE,则返回值为 expr2
expr1 的值为FALSE,则返回值为 expr3
IFNULL 表达式
IFNULL( expr1 , expr2 )
判断第一个参数expr1是否为NULL:
如果expr1不为空,直接返回expr1;
如果expr1为空,返回第二个参数 expr2
NULLIF 表达式
NULLIF(expr1,expr2):如果两个参数相等则返回NULL,否则返回第一个参数的值expr1
locate函数和instr(filed,str)函数和not like

# not like
select prod_name,prod_desc from Products
where prod_desc not like "%toy%"
order by prod_name asc
Locate 函数
# 1.locate函数:Locate(str,sub) > 0,表示sub字符串包含str字符串;Locate(str,sub) = 0,表示sub字符串不包含str字符串。
select prod_name,prod_desc from Products
where locate("toy",prod_desc) = 0
order by prod_name asc
instr(filed,str)函数
# 2.instr(filed,str)函数:返回str子字符串在filed字符串的第一次出现位置
select prod_name,prod_desc from Products
where instr(prod_desc,"toy") = 0
order by prod_name asc
事务
事务的基本介绍
1、概念:如果一个包含多个步骤的业务操作,被事务管理,那么这些操作要么同时成功要么同时失败。
2、操作:
开启事务:start transaction;
回滚:rollbac;
提交:commit;
#设置原有账户为1000
UPDATE account set balance = 1000;
#张三给李四转账500
#张三账户-500
#开启事务
start TRANSACTION;
UPDATE account set balance = balance-500 where name = 'zhangsan';
#李四账户+500
#出错了。。。
UPDATE account set balance = balance+500 where name = 'lisi';
#提交事务
COMMIT;
#回滚事务
ROLLBACK;
SELECT * from account;
3、MySQL数据库中事务默认自动提交
一条DML(增删改)语句会自动提交事务
事务提交的两种方式:自动提交、手动提交
自动提交:mysql就是自动提交
手动提交:需要先开启事务,再提交
修改事务的默认提交方式:查看事务的默认提交方式
select @@autocommit;#1代表自动提交0代表手动提交
set @@autocommit = 0;#修改事务的默认提交方式为手动
#当设置事务的默认提交方式为手动后需要commit进行提交事务
#设置原有账户为1000
UPDATE account set balance = 1000;
commit;
事务的四大特征
1、原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败
2、持久性:如果事务一旦提交或回滚,数据库就会持久化的保存
3、隔离性:多个事务之间,相互独立。(但真实情况下事务会产生相互的影响)
4、一致性:事务操作前后,数据总量不变
事务隔离级别
概念:多个事务之间是隔离的,相互独立的,但如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就可以解决这些问题
存在问题
脏读:一个事务,读取到另一个事务中没有提交的数据
不可重复度:在同一个事务中,两次读取到的数据不一样
幻读:一个事务操作(DML)数据表示所有记录,另一个事务添加了一条数据,则第一个事务查询不到自己的修改。
隔离级别
1、read uncommitted:读未提交(产生的问题:脏读、不可重负读、幻读)
2、read committed(Oracle默认):读已提交(产生的问题:不可重负读、幻读)
3、repeatable read(MySQL默认):不可重复读
4、serializable:串行化,可以解决所有问题
注意:隔离级别从小到大安全性却来越高,但是效率越来越低。
数据库查询隔离级别 select @@tx_isolation;
数据库设置隔离级别:set global transaction isolation level 级别字符串;
用户管理和权限管理
DCL:用来管理用户,授权操作
DBA:数据库管理员
DCL:管理用户,授权
管理用户
1、添加用户
#切换到mysql数据库
use mysql;
#查询user表
select * from user;
#创建用户
create user '用户名'@'主机名' identified by'密码';
#如果需要在任意电脑都能访问将主机名改为通配符%
create user '用户名'@'%' identified by'密码';
2、删除用户
#删除用户
drop user'用户名‘@'主机名';
3、修改用户密码
#修改lisi用户密码为abc
update user set password = password('新密码')where user = '用户名';
update user set password = password('abc')where user = 'lisi';
set password for '用户名'@'主机名' = password('新密码');
set password for 'root'@'loaclhost' = password('123');
== 忘记root密码==(需要管理员运行该cmd)
a、cmd–>net stop mysql
b、使用无验证方式启动mysql服务:mysqld --skip-grant-tables或mysqld --shared-memory --skip-grant-tables
c、重新打开一个管理员的cmd:启动mysql net start mysql ,输入mysql -uroot -p 直接回车可看到welcome
d、 alter user ‘root’@‘localhost’ identified by ‘newpassword’; newpassword是要设的新密码。
e、提示成功后flush privileges;回车然后exit退出
f、使用新密码重新登录即可
4、查询用户
#切换到mysql数据库
use mysql;
#查询user表
select * from user;
授权
1、查询权限
show grants for '用户名'@'主机名';
2、授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
grant select,update,... on db3.account to 'lisi'@'%';
#给张三用户授所有权限,在任意数据库任意表上
grant all on *.* to'zhangsan'@'localhost'
3、撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
#撤销lisi对db3中account表的修改权限
revoke update on db3.account from 'lisi'@'%';
















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











