








 此博客介绍了使用Python脚本结合讯飞API进行OCR手写文字识别的过程,脚本能够自动识别剪切板上的内容,尤其适用于中英文混合文本。脚本运行高效,能保留原文本格式,对于英文单词间自动添加空格。与QQ等其他工具相比,该脚本在识别速度和结果复制方面具有优势。
此博客介绍了使用Python脚本结合讯飞API进行OCR手写文字识别的过程,脚本能够自动识别剪切板上的内容,尤其适用于中英文混合文本。脚本运行高效,能保留原文本格式,对于英文单词间自动添加空格。与QQ等其他工具相比,该脚本在识别速度和结果复制方面具有优势。
脚本说明:
脚本需要修改 APPID 以及 API_KEY的值,请到讯飞api平台获取。
首先截图,然后打开脚本直接运行,该脚本自动识别剪切板上内容,脚本运行结束后,直接crtl+v复制。
# -*- coding: utf-8 -*-
import base64
import hashlib
import time
import keyboard as keyboard
import pyperclip
import requests
#获取剪切板内容
from PIL import ImageGrab
# OCR手写文字识别接口地址
URL = "http://webapi.xfyun.cn/v1/service/v1/ocr/handwriting"
# 应用APPID(必须为webapi类型应用,并开通手写文字识别服务,参考帖子如何创建一个webapi应用:http://bbs.xfyun.cn/forum.php?mod=viewthread&tid=36481)
APPID = ""
# 接口密钥(webapi类型应用开通手写文字识别后,控制台--我的应用---手写文字识别---相应服务的apikey)
API_KEY = ""
def getHeader():
curTime = str(int(time.time()))
param = "{\"language\":\""+language+"\",\"location\":\""+location+"\"}"
paramBase64 = base64.b64encode(param.encode('utf-8'))
m2 = hashlib.md5()
str1 = API_KEY + curTime + str(paramBase64, 'utf-8')
m2.update(str1.encode('utf-8'))
checkSum = m2.hexdigest()
# 组装http请求头
header = {
'X-CurTime': curTime,
'X-Param': paramBase64,
'X-Appid': APPID,
'X-CheckSum': checkSum,
'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8',
}
return header
#图片转换为base编码
def getBody(filepath):
with open(filepath, 'rb') as f:
imgfile = f.read()
data = {'image': str(base64.b64encode(imgfile), 'utf-8')}
return data
#英文判断
def isEnglish(keyword):
#return keyword.isalpha() #判断纯单词 是否是英文
return all(ord(c) < 128 for c in keyword)
# 写入到剪切板
def settext(aString):
# importing the module
# copies all the data the user has copied
pyperclip.copy(aString)
# paste the copied data from clipboard
pyperclip.paste()
#保存剪切板数据图片
def get_pic():
# 按ctrl+后才执行下面的语句
#keyboard.wait(hotkey='ctrl+alt+a')
# ctrl+c保存截图至剪切板, ImageGrab从剪切板读取图片
img1 = ImageGrab.grabclipboard()
#print(type(img1))
# 文件保存的名字
img_path = str(int(time.time()))+"javachuan"+".png"
img1.save(img_path)
return img_path
# 语种设置
language = "cn|en"
# 是否返回文本位置信息
location = "true"
r = requests.post(URL, headers=getHeader(), data=getBody(get_pic()))
resp=r.json()
result=""#每一行的数据
content="" #每一行某个数据 某个文字/某个单词
for i in range(0,len(resp["data"]["block"][0]["line"])):
for j in range(0,len(resp["data"]["block"][0]["line"][i]["word"])):
content=resp["data"]["block"][0]["line"][i]["word"][j]["content"]
if isEnglish(content):
result+=content+" " #英文单词 需要 空格
else:
result+=content
result+="\n" #换行
#添加到剪切板
settext(result)
print(result)
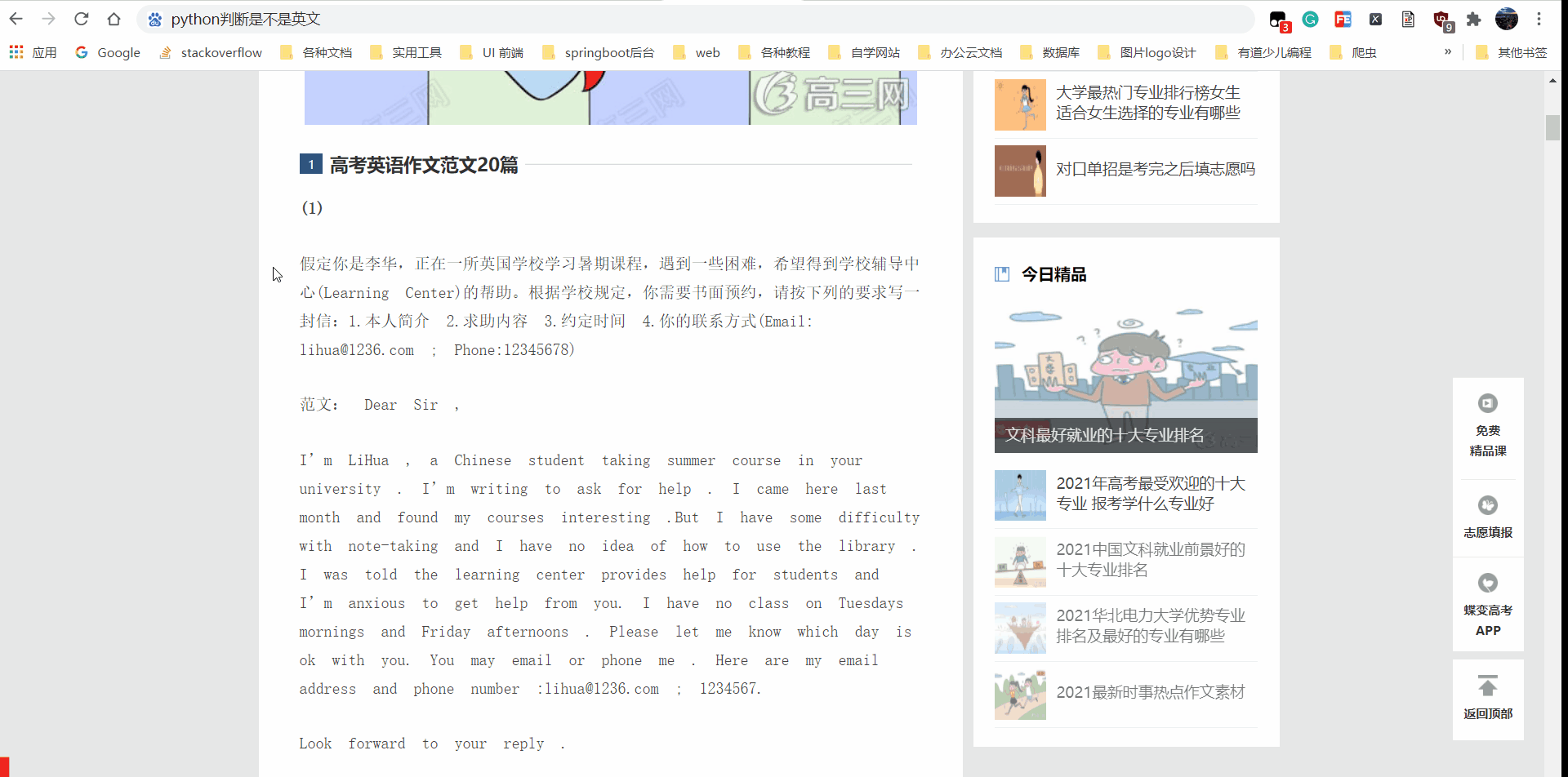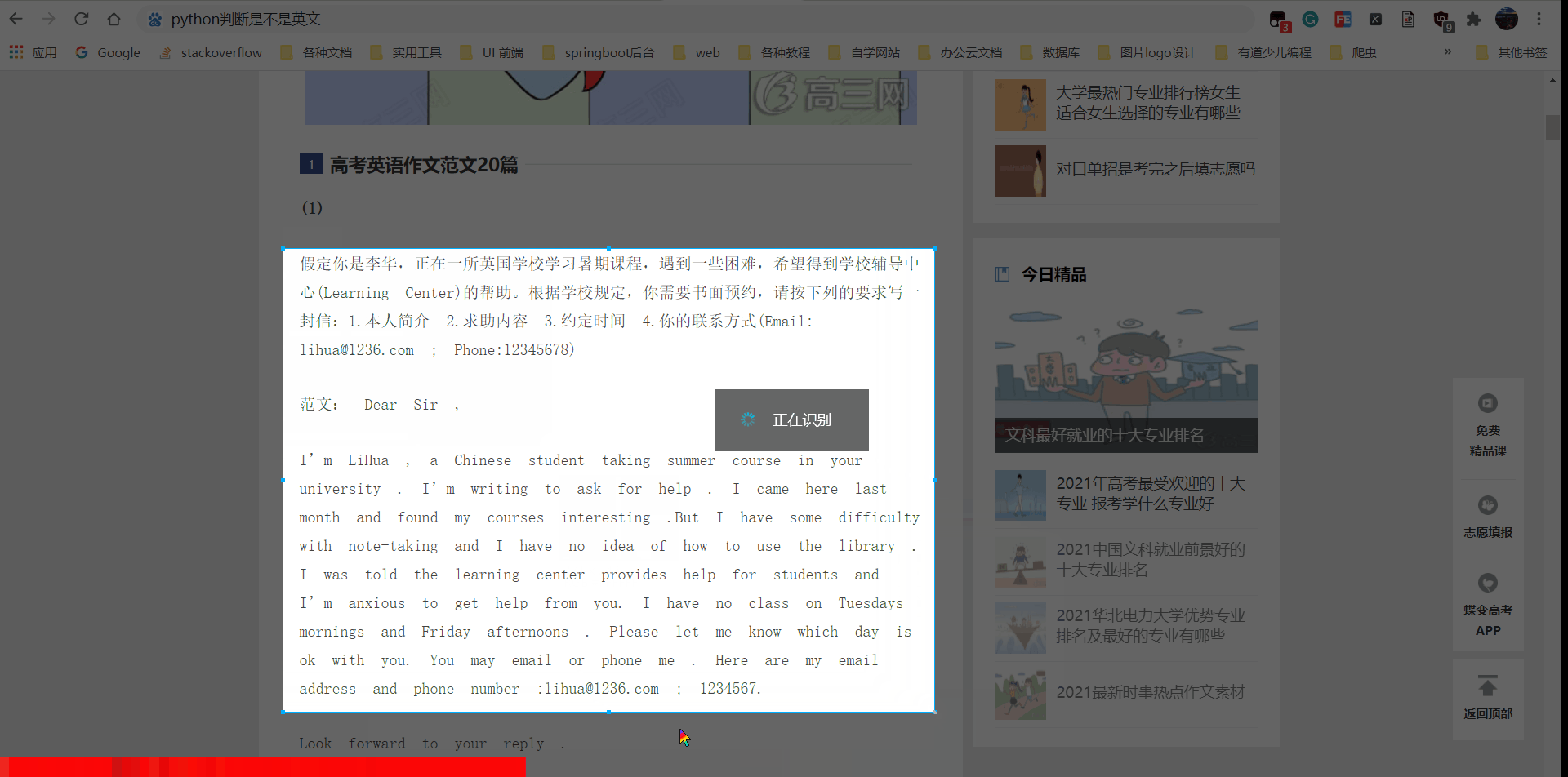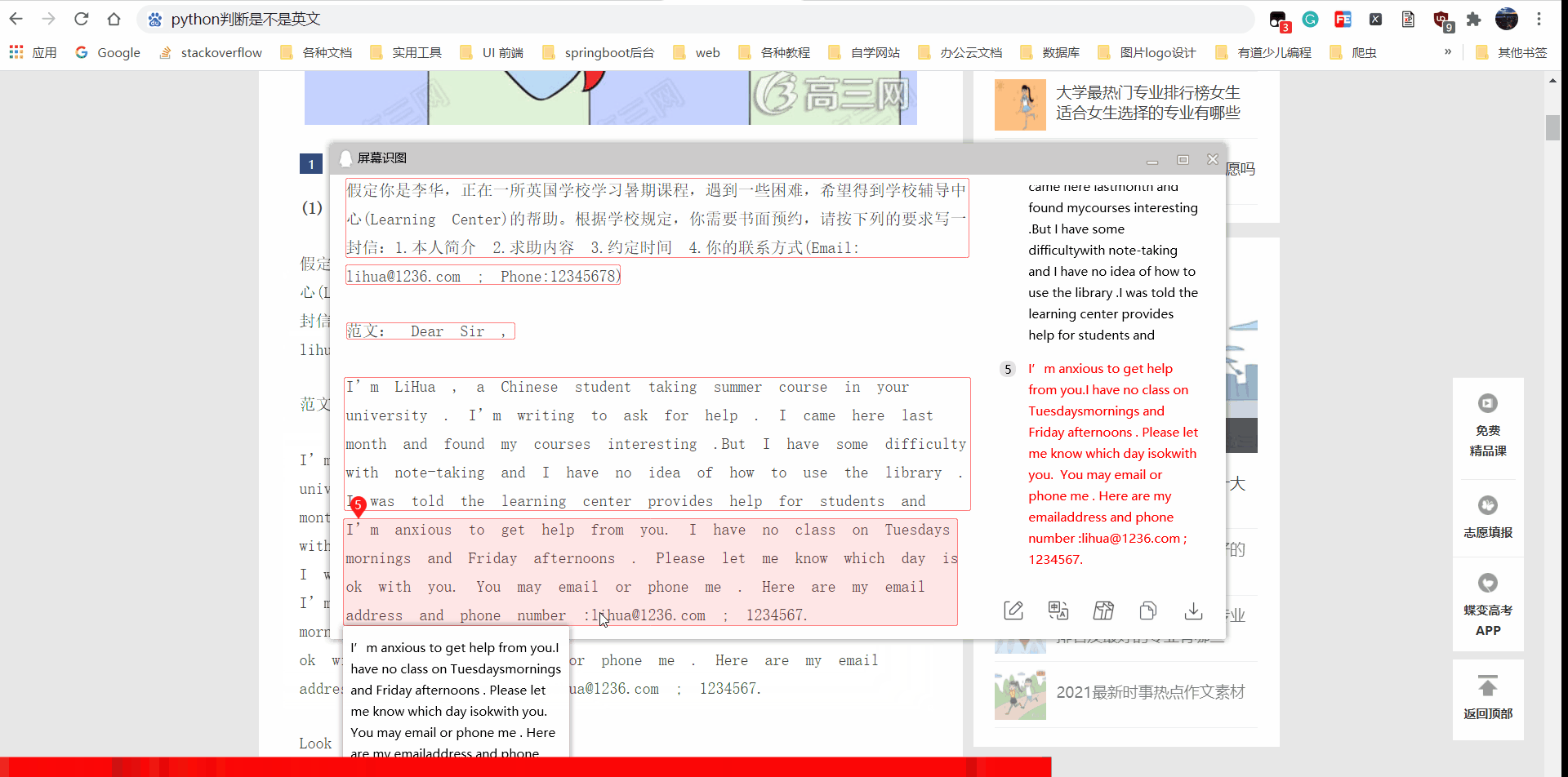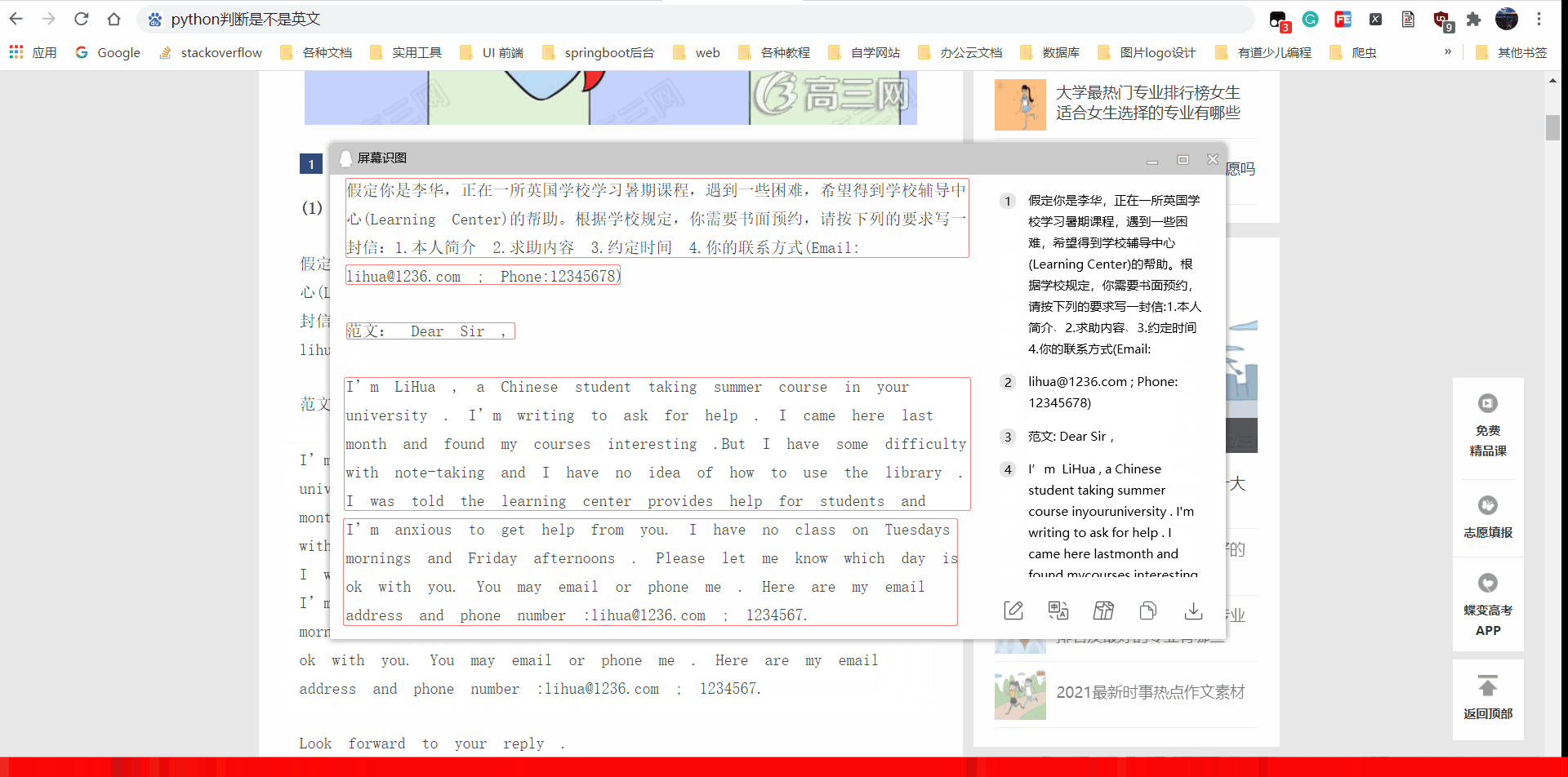
我的ocr python脚本效果演示:
中英文可以有效识别,并且尽可能保持原字体格式,英文单词之间有 空格,
原本是同一行,就是同一行。
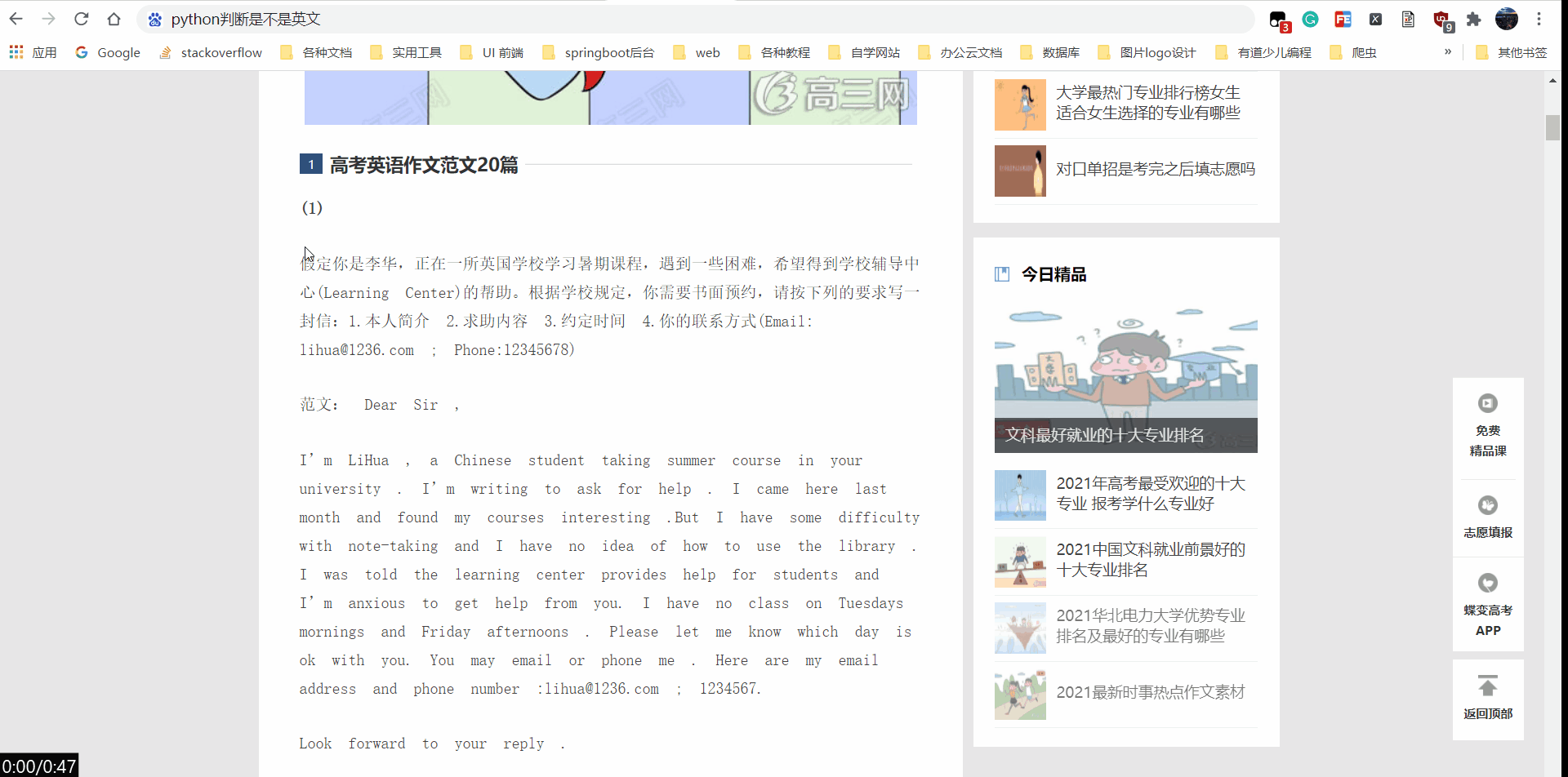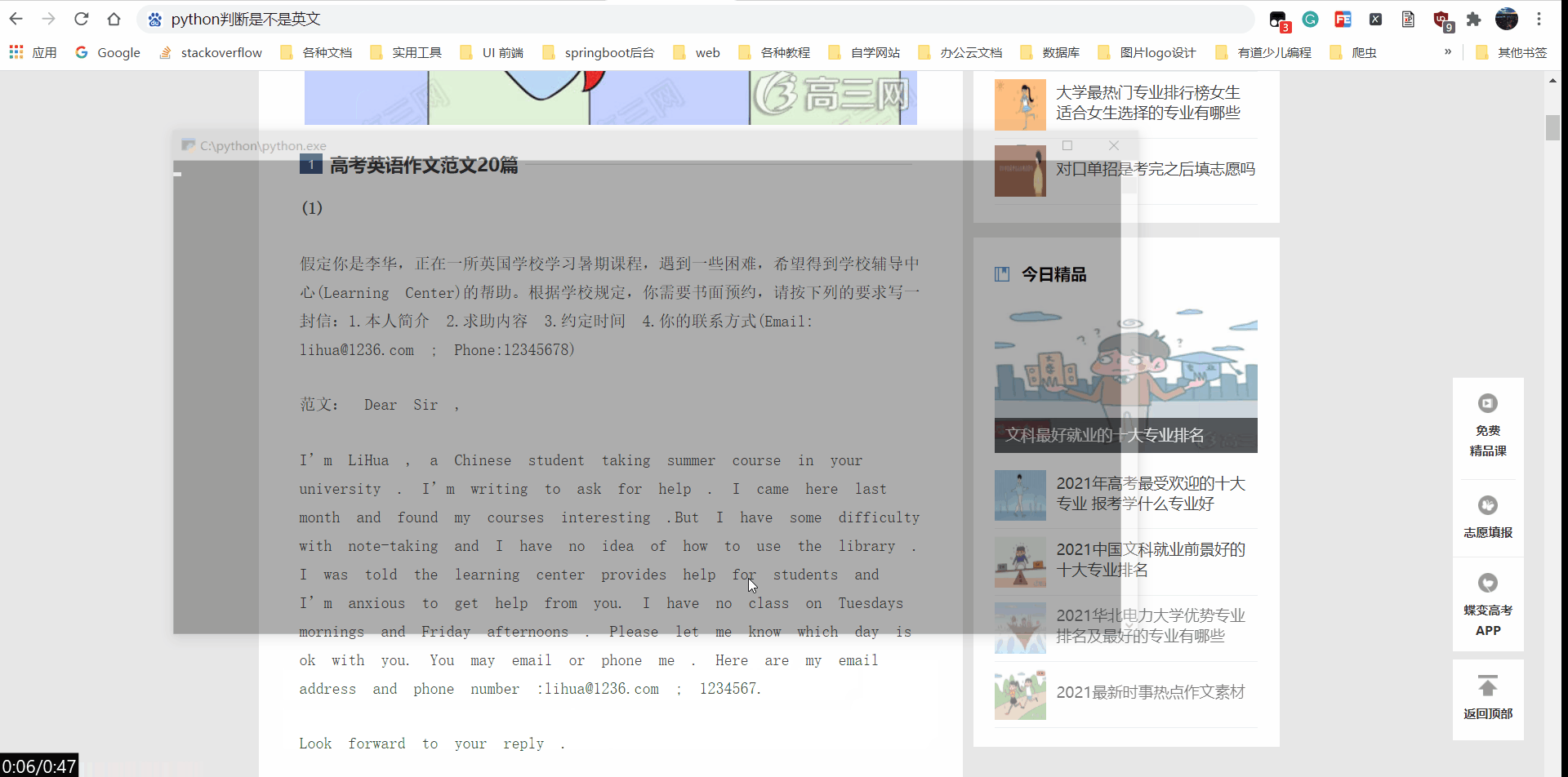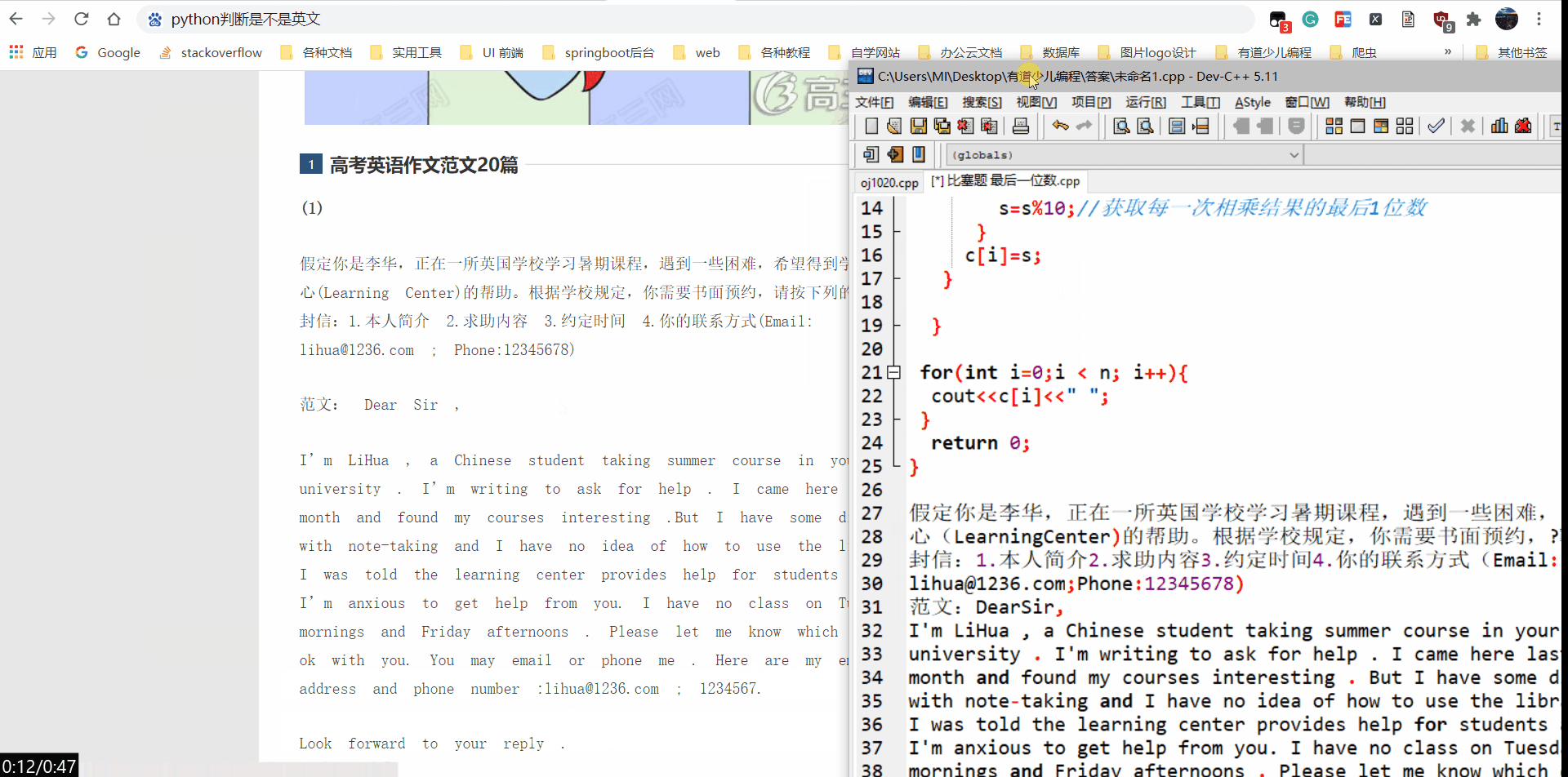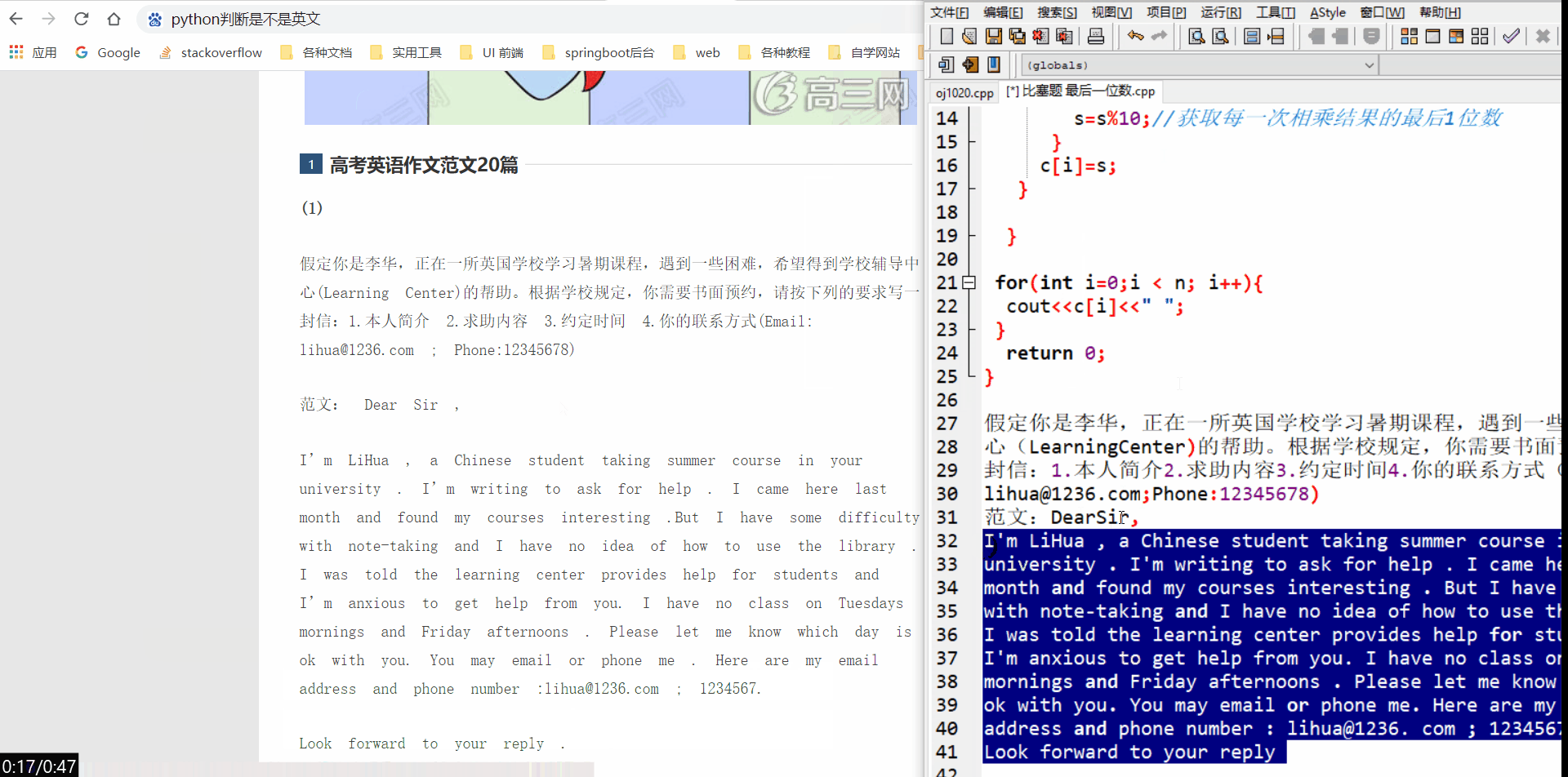
qq的文字识别效果演示
是恶速度慢,并且识别后不好复制,不能保持原样。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









