







目录
Title:Multi-scale self-guided attention for medical image segmentation
PAM(Position attention module)--空间注意模块
CAM(Channel attention module)--通道注意模块
Title:Multi-scale self-guided attention for medical image segmentation
Abstract--摘要
目前的用于医学图像分割的方法主要是多尺度方法也就是U-Net编码器-解码器结构,但是这种结构存在着以下的缺点(即需要解决的问题)
1)使用多尺度方法也就是编码器解码器结构会导致信息的冗余使用,一些低级特征会在多个不同的尺度上被多次提取
2)远程特征依赖没有被有效建模,导致与每个语义类相关的非最优判别特征表示
在本文中通过使用引导式自我注意机制来捕获更丰富的上下文依赖关系,这种方法能够将局部特征与其相对应的全局依赖关系集成,并以自适应的方式突出相互依赖的通道图--解决问题2)
不同模块之间的额外损失引导注意力机制忽略不相关的信息,并通过强调相关的特征关联来关注图像更加判别性的区域--解决问题1)
Introduction
本文提出的是一种用于医学图像分割的多尺度引导注意网络,首先多尺度方法生成包含不同语义的不同分辨率的堆栈。虽然较低级别的堆栈专注于局部外观,但较高级别的堆栈将编码全局表示。这种多尺度的策略鼓励以不同分辨率生成的注意力图对不同的语义信息进行编码,然后每个尺度上注意力模块会逐渐去除噪声区域,并强调那些与目标语义描述更相关的区域。
每个注意力模块包含两个独立的自注意力机制,分别专注于建模位置和通道特征依赖关系。这种双重的注意力机制允许对更广泛更丰富的上下文表示进行建模,并且可以改善通道映射之间的依赖关系,从而增强了特征表示
注意力机制旨在强调在局部特征中捕获的重要局部区域并过滤由全局特征传递的无关信息,从而改进远程依赖关系建模
方法-Method
A:方法概括
存在的问题:医学图像的目标结构在大小,形状,纹理上呈现出类内和类间的多样性。用于分割的CNN具有局部感受野,这会导致生成局部特征表示,使得远程上下文信息没有被正确编码。而局部特征表示可能会导致与具有相同标签的像素相对应特征之间存在潜在的差异。这可能会引入最终影响分割性能的类内不一致。
其结构如下图所示:
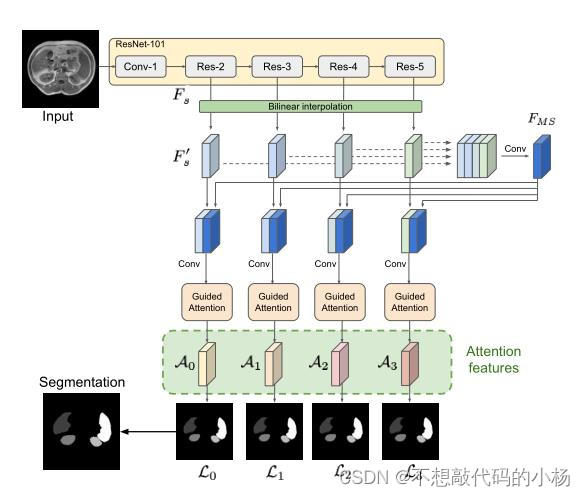
总体来说,首先通过多尺度策略来捕获全局上下文,然后将多个尺度的学习特征输入到引导注意模块当中,这些引导注意模块由多个空间和通道自注意力机制组成。空间和通道自注意力模块有助于自适应的将局部特征和其全局依赖性相结合。并且其有助于在强调相关信息的情况下逐渐去除噪声。
B:多尺度注意力图
在网路的整体架构图中,多个尺度的特征表示为Fs,其中s表示在整体网络架构中的级别,每个级别s的特征图都有其不同的分辨率。通过双线性插值将他们上采样到一个共同的分辨率。从而得到放大的特征图F's,然后连接所有尺度的F's形成一个张量Fms,这个张量经过一个卷积以创建公共的多尺度特征图。因此形成的特诊图Fms既包含来自浅层的空间细节信息,也包括来自高层的高级语义信息。
然后再将生成的Fms与不同尺度s的每个特征图合并并输入到引导注意模块中生成注意特征As(s=1,2,....n)
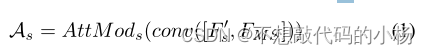
其中AttMod代表引导注意力模块
C:空间注意模块和通道注意模块
传统的方法限制了建模更广泛更丰富的上下文表示,为了解决这些限制提出了位置和通道注意力模块,这两个模块的整体结构图:
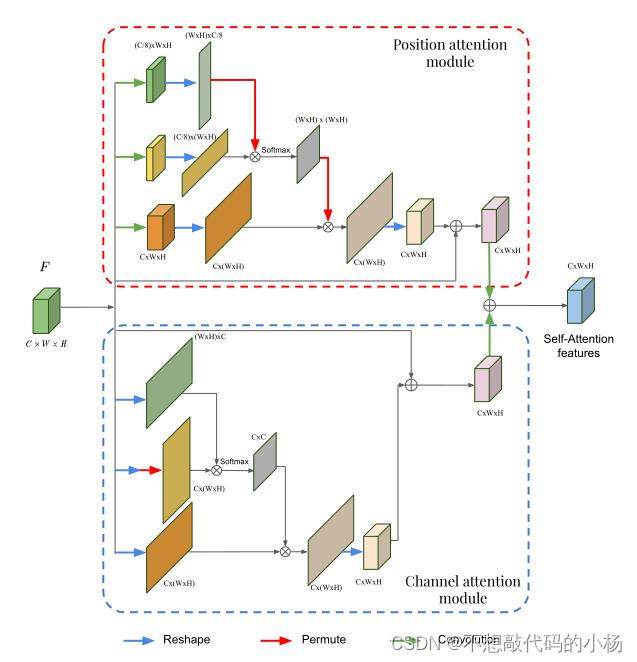
PAM(Position attention module)--空间注意模块
上图中的上半部分是空间注意块,F是引导注意模块的输入,F在第一个分支中首先通过一个卷积块得到一个特征图Fp0 ∈ RC'×W ×H,其中通道数变为原来的1/8,然后再将这个特征图重塑为(W × H) × C'。
在第二个分支中执行同样的操作,只不过这次将特征图重塑为Fp1 ∈ RC'×(W ×H)。然后将这两个分支的特征图相乘,再对其应用softmax以生成空间注意力图。记为以下式子:
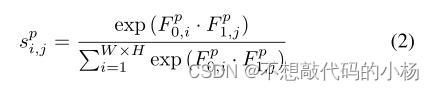
这个变量评估的是第i个位置对第j个位置的影响
F输入第三个分支产生 Fp2 ∈ RC×(W ×H)其形状和F相同,并且被重置为Fp2 ∈ RC×(W ×H)然后将其乘以空间注意力图的转置其输出被重塑为RC×(W ×H)用公式表示为:

式子中的S是由前两个分支得到的空间注意力图,第一个F是第三个分支处理后的特征图,第二个分支是原始输入F的残差连接。
总之位置注意模块在空间注意图的指导下选择性的将全局上下文聚合到学习的特征
CAM(Channel attention module)--通道注意模块
输入F在前两个分支均Reshape分别得到两个尺寸不同的特征图分别为Fc0 ∈ R(W ×H)×C和Fc1 ∈ RC×(W ×H),然后将这两个不同尺寸的特征图相乘再送入softmax得到通道注意力图。通道注意力图的计算式子如下:

这个变量代表的是第i个 通道对第j个通道的影响,通道注意模块最终的特征图计算式表示为
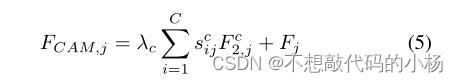
当以上这两个模块处理结束后新生成的特征图送入卷积层处理,然后逐元素求和生成空间通道注意特征
D:引导注意力模块
通过顺序细化将逐渐加权不同局部区域的重要性,同时掩盖一些不相关的噪声,给定引导注意模块的输入特征图F(通过连接Fms和F's),通过多步细化生成注意力特征。引导注意力模块结构如下图:
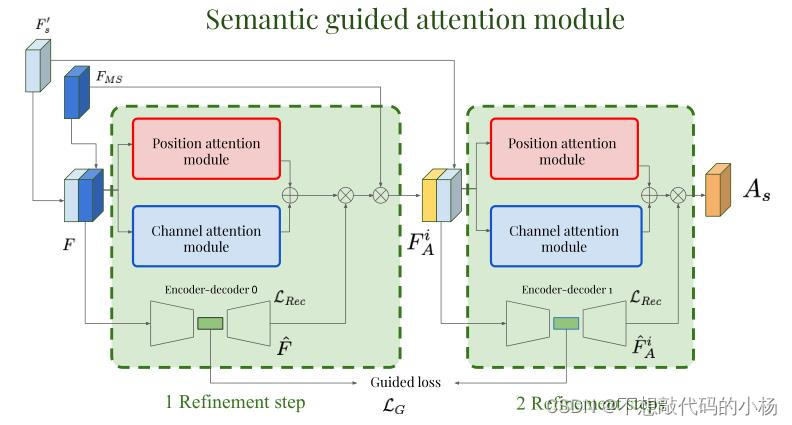
空间和通道注意力模块使用F来生成自注意力特征,同时集成了一个编码器解码器网络。这个网络将输入特征F压缩为潜在空间中的压缩表示。目标是通过迫使编码器和解码器的潜在表示相互接近。可以将类别信息嵌入到后续的引导注意模块当中。用公式表示为:

式子中的Ei()是第i个编码器-解码器网络的编码表示,FiA表示的是经过第i个双注意模块之后生成的注意特征。M表示迭代的次数。F i−1A是语义引导注意模块的输入处特征。具体来说第一个编码器解码器网络中重构的特征映射通过矩阵乘法与第一个注意模块生成的自注意特征组合以生成Fsa。此外为了确保重构的特征对应于位置通道注意力模块输入端的特征,编码器的输出被迫接近于其输入端。用公式表示为:
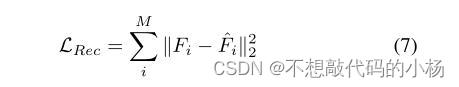
其中ˆFi是其重构的特征,并且由于引导注意模块应用于多个尺度,所有模块的组合引导损失和总的重建损失为:

E:深监督
在每个尺度上使用额外的监督损失可以提高模型的分割性能,则总的分割损失为:
 、
、
其中第一项是原始特征处的分割结果,第二项是由关注特征提供的分割结果。则模型总的损失函数为:
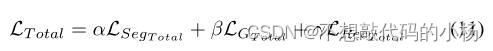
总结
本文的模型结合了多尺度策略,将不同级别的语义信息和自我注意模块结合起来,从而逐步聚合相关的上下文信息,最后引导细化模块过滤噪声区域并帮助网络关注图像中的相关类别的特定区域。














 2388
2388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









