






摘要:图像语义分割是一种通过为目标类别中的每个点分配基于其“语义”的标签来区分图像中不同种类事物的技术。目前使用的Deeplabv3+图像语义分割方法计算复杂度高,内存消耗大,难以在计算能力有限的嵌入式平台上部署。在提取图像特征信息时,Deeplabv3+难以充分利用多尺度信息。这可能导致详细信息的丢失和损害分割的准确性。提出了一种基于DeepLabv3+网络的改进图像语义分割方法,以轻量级的MobileNetv2作为模型的主干。将ECAnet通道关注机制应用于底层特征,降低了计算复杂度,提高了目标边界的清晰度。在ASPP模块之后引入极化自注意机制,改善特征图的空间特征表示。在VOC2012数据集上进行验证,实验结果表明,改进模型的MloU和mAP分别达到了69.29%和80.41%,能够预测更精细的语义分割结果,有效地优化了模型复杂度和分割精度。
1.介绍
人工智能(AI)的出现极大地改变了我们生活的方方面面。语义分割的概念很容易理解。当人们看到一张图片时,很容易理解图片的内容。语义分割允许机器理解图片的内容。在现实中的应用也越来越广泛,例如自动驾驶技术的场景识别、医学图像分割领域的手术导航、广告推荐等。图像语义分割的广泛应用具有很高的实用价值(Iftikhar et al, 2022, 2023)。
迄今为止,已经提出了许多不同的语义分割算法,包括传统的和深度学习的语义分割。从传统的方法,如阈值(Otsu, 1979)、基于直方图的捆绑、区域增长(Nock和Nielsen, 2004)、k-means聚类(Dhanachandra等人,2015)和分水岭(Najman等人,1994),到更高级的算法,如活动轮廓(Dhanachandra等人,2015)、图切(Najman等人,1994)、条件和马尔可夫随机场(Kass等人,2004)和基于稀疏的方法(Boykov等人,2001;普拉斯等人,2009)。为了弥补传统方法的不足,深度学习的语义分割方法从模型结构上主要有两种分类方式:基于信息融合和基于编码-解码器(Minaee et al, 2021)。在信息融合方法的基础上,通过增加网络层数来提高模型利用率(Starck et al ., 2005;Minaee et al, 2017)。代表性算法包括全卷积网络(FCN)算法和一系列改进算法(彪等,2018),如FCN - 32s、FCN - 16s和FCN - 8s。基于编码器-解码器方法(Liu et al ., 2018;Fu et al ., 2022),通过采用不同的骨干网形式和金字塔池化模块,提高了网络的准确率。代表性算法包括金字塔场景解析网络(PSPNet)(Sun and Wang, 2018)和DeepLabv系列。目前基于Deeplabv3+的方法计算复杂度高,内存消耗大,难以在计算能力有限的嵌入式平台上部署。Deeplabv3+在提取图像特征信息时不能充分利用多尺度信息,容易造成细节信息的丢失,导致分割精度受损。进一步提高能力。2的DeepLabv3 plus网络获取关键品类信息,主要基于DeepLabv3 plus进行改进。本文的主要贡献总结如下:
1. 对DeepLabv3+网络进行了改进,使其适合于现实场景的需求。原始特征提取网络参数量过大,模型采用轻量级的MobileNetV2作为骨干网,在此基础上进一步优化,解决了空间细节丢失和特征提取不足的问题。
2. 在DeepLabv3+中,在ASPP模块之后加入极化自注意机制(PSA-P、PSA-S),增强特征图提取细节信息的能力,提高语义分割的准确性。在MobileNetv2底层特征之后加入通道注意机制(ECA-Net),恢复更清晰的分割边界。
3.ASPP模块使用分条池代替原有的全局平均池来有效捕获远程依赖关系,使用混合池代替原有的全局平均池来有效捕获不同位置之间的短程和远程相互依赖关系,从而提高了系统的效率和可靠性
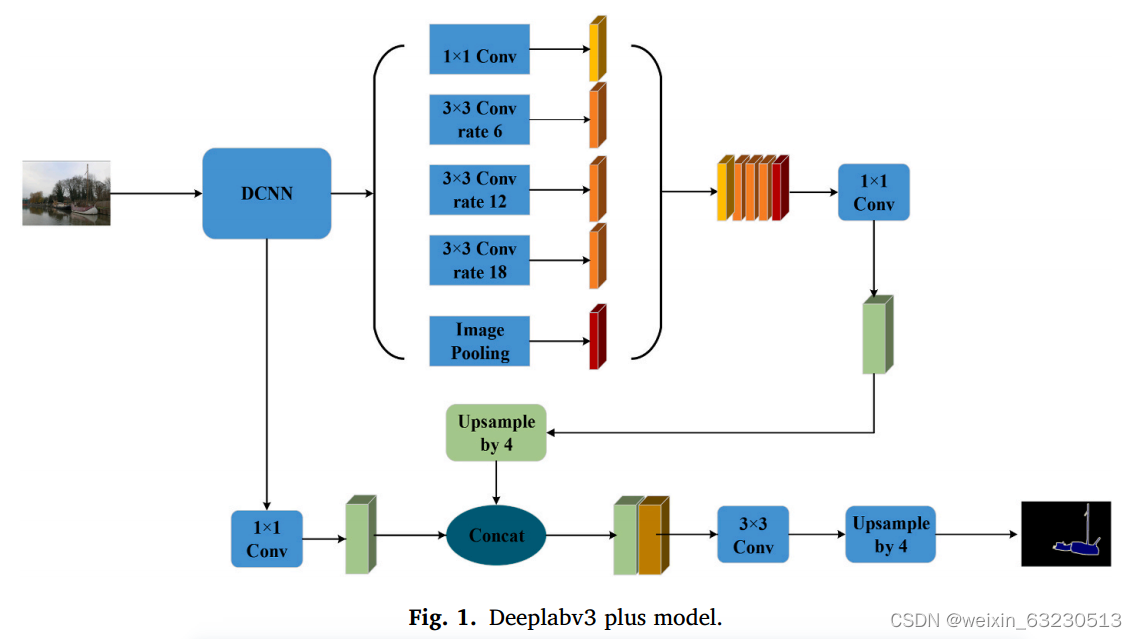
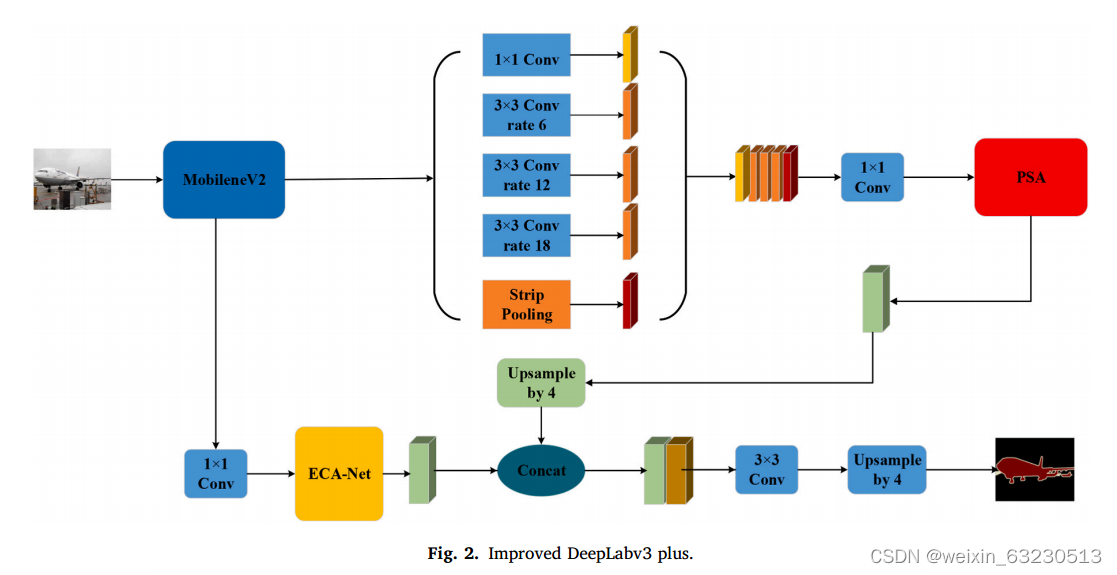
2.DeepLabv3 plus网络
DeepLabv3 plus网络(Yang et al ., 2020)如图1所示。骨干网的作用是提取特征语义信息(Zhao et al ., 2017)。ASPP的功能是从骨干网中重新提取特征信息,以获得足够的特征信息。DCNN通常是一个深度卷积神经网络。ASPP模块主要由5部分组成,1 × 1卷积和孔隙比分别为6次、12次和18次,3 × 3卷积和全球平均池化。这五个部分是并行的,共同构成了ASPP部分。骨干网底层特征后接入1 × 1。然后将卷积和ASPP连接到4次下采样部分进行特征融合,再连接到3 × 3卷积和4次下采样部分恢复图像的大小。
3.改进的v3+网络
以DeepLabv3 plus模型为主体进行改进。在基于DeepLabv3 plus网络的图像语义分割中,本文采用轻量级的MobileNetV2作为骨干网。然后,利用ASPP方法从图像中提取多尺度信息。利用条带池化代替全局池化在骨干网中获得的特征图,保留更详细的信息。引入注意机制,增加极化自注意机制,对ASPP模块得到的特征映射进行加权。加入ECA-Net来融合MobileNetV2和提高图像分割性能。改进后的模型如图2所示。
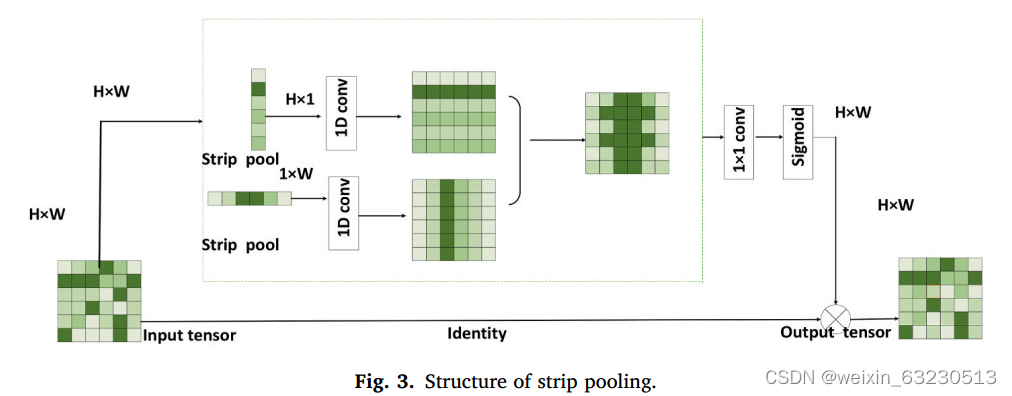
全局平均池化的池化窗口是方形的,有一定的局限性,难以获得不同方向图尺度的相关性。条带池化比全局平均池化具有更多的优点。条形池化的池化窗口为矩形,条形池化的设计可以从水平和垂直两个维度获取全局信息,扩大了获取特征信息的范围(Hou et al ., 2020)。与全球平均池化计算方法不同,条带池化是根据水平和垂直空间维度同时进行的。此外,当两个空间维度被池化时,列或行的特征值是加权平均值。模型结构如下图3所示。
对于输入图像,行向量输出的计算公式如下:
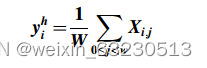
列向量输出的计算公式如下:
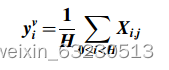
对于输入X∈RC×H×W,其中C表示通道数,H和W分别表示高度和宽度。X进入池化的水平和垂直路径,垂直和水平方向的输出分别为yh∈RC×H和yv∈RC×W。两者结合后,输出计算如下:
![]()
通过卷积和sigmoid函数得到特征图像,与原始图像融合得到输出z,输出z的计算公式为:
![]()
上式中,scale()表示乘法,σ表示sigmoid函数,f表示1 × 1卷积。
3.2 极化自注意力机制
我们都熟悉注意力的概念(Zeng et al, 2020)。当人们观看一幅画时,他们无法注意到整幅画。一定是眼睛更倾向于对画中感兴趣的部分,而人会忽略自己不感兴趣的部分。基于这一特点,神经网络中的注意机制利用了这一特点,即从复杂信息中筛选出有效信息(Chen et al ., 2017a)。对于图像处理,将目标锁定在图像的一部分而忽略其他区域,这样可以提高图像处理的效率,省去不必要的麻烦。随着注意机制的快速发展,越来越多的神经网络模型加入了注意机制(Zhang et al ., 2020;Honarbakhsh et al ., 2023)来提高模型的效率,已经显示出良好的效果。本文主要在DeepLabv3 +网络中加入极化自注意机制和信道注意机制。这两种注意机制分别添加在网络的不同位置,均表现出良好的性能。
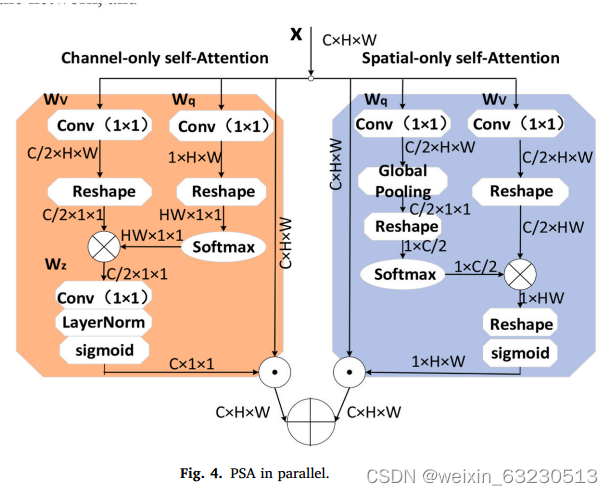
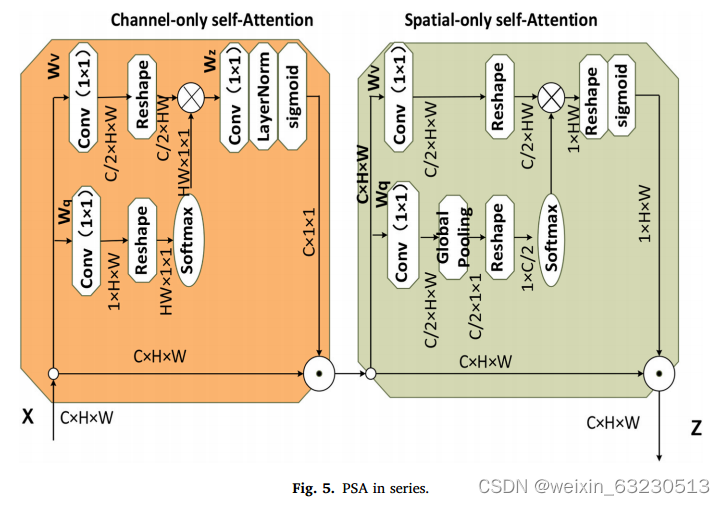
极化自我注意机制(Hridoy et al ., 2021;Liu et al ., 2021)主要有串联和并联两种形式。序列形式是指通道自注意机制和空间自注意机制的序列形式。平行形式是指通道自注意机制与空间自注意机制的平行形式。这两种方式共同构成了两极分化的自我注意机制。在ASPP模块中插入极化自注意机制后(Yang, 2020;Zhu et al ., 2019),该模型可以增加重要信息的提取,提高模型的利用率。PSA_p和PSA_s可以在通道和空间维度上保持较高的分辨率,这是它们存在的原因越来越广泛地应用于深度学习网络。模型示意图如下图4和图5所示。
将极化自注意机制的串联和并联形式正式分为通道分支和空间分支两个分支。通道权值的计算公式如下:Ach(X) = FSG[Wz|θ1 ((σ1(Wv(X))) × FSM(σ2 (Wq(X))))))](5)其中,σ1σ2表示1 × 1的卷积。FSM代表softmax功能部分。WZ|θ1表示1 × 1卷积,LN将通道上C/2的维数提升到C。FSG表示sigmoid函数。
空间权值计算公式为:Asp(X) = FSG [σ3(FSM(σ1(FGP(Wq(X)))) × (X)))](6)],其中σ1σ2和σ3表示1 × 1的卷积。FSM代表softmax功能。FGP代表全局池化。FSG表示sigmoid函数。
上式为两个分支权值的计算公式。基于分支权值融合极化自注意机制。并联和串联只是分流权值的两种简单计算,类似于加法和乘法。
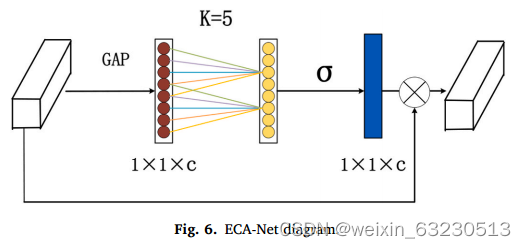
3.3 ECA注意力机制
ECA-Net (Liu, 2020)的优点是利用全局池化将空间矩阵转化为一维向量(见图6),然后根据网络通道的数量得到一维卷积核的大小。然后,使用自适应大小的卷积核进行卷积运算,通过加权形式得到输入图像的特征映射;
最后,将输入图像与卷积计算后得到的特征映射相乘,提取感兴趣的信息。由于网络采用骨干网的预训练方法,在MobileNetV2中插入ECA-Net会破坏骨干网的网络结构。因此,在MobileNetV2的浅层特征中插入ECA-Net可以在不破坏网络的情况下提高分割效果。
4.实验
4.1 数据集
PASCAL VOC2012数据集应用广泛,可以有效地应用于图像处理领域。一个可用于图像语义分割的数据集。该数据集中有四种主要类型:室内家具、人、车辆和普通动物。四大类共21类,随机抽取3200张图片,按9:1:1的比例进行划分。总共使用2616张图像作为训练集,292张图像作为验证集,292张图像作为测试集。
4.2 实验设备及评价指标
操作系统为Ubuntu 20.04,使用Python 1.2.0深度学习开源框架和CUDA 10.0版本。操作系统的编程语言为Python 3.6,硬件配置如下:CPU为i7-9600, GPU为NVIDIA 3060-Ti。将平均交联比(MloU)和平均像素精度(mAP)作为图像语义分割的性能评价系数。式中k表示k个类别,Pij表示真实值为i,预测值为j;Pji表示真实值为j,预测值为i, Pii表示真实值和预测值均为i。mou和mPA的计算公式为
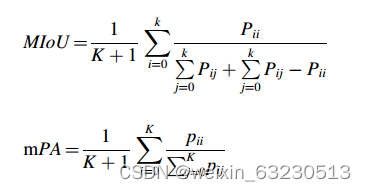
4.3 实验比较
本文提出的算法基于原始DeepLabv3 plus模型,重新设计了ASPP模块,引入了关注机制,使模型的浅层和深层特征更加关注重要的语义信息(He et al ., 2016;Chen等,2017b, 2018;Sehar and Naseem, 2022)-(He et al, 2016;Chen等,2017b, 2018;Sehar和Naseem, 2022)。使用Adam网络模型优化器对算法进行100次训练,达到拟合效果。训练分为两个阶段:冻结阶段和解冻阶段。在冷冻阶段使用0.005的学习率,批量大小设置为8。解冻阶段的学习率为0.0005,批量大小设置为4。为了防止过拟合,权重衰减率设置为0.005。Epoch是指所有进入网络的数据完成一次正向计算和反向传播的过程,Epoch数设置为100,其中冻结阶段50轮,解冻阶段50轮。50发,解冻50发。前后改进。本文采用MloU和MAP评价指标体系,在PASCAL VOC2012上进行了ASPP模块优化、注意机制添加和相互融合实验,验证了模型的性能。
4.3.1 ASPP改进实验
在ASPP模块中引入了分条池模块SP (stripe pooling module),其中Deeplabv3 + SP表示在ASPP模块中使用分条池而不是全局池。为了证明分条池的适用性,MloU在改进前后将DeepLabv3 plus网络提高了1.09%。如下表1所示。
4.3.2 不同注意力实验的介绍
基于MobileneV2骨干网和ASPP模块,介绍了不同的关注机制。在ASPP模块之后,引入了串联和并联形式的极化自注意机制。在MobileneV2的浅层之后引入ECA-Net。加入PSA和ECA-Net后,mou增加了0.79%。PSA_s的性能优于PSA_p。特别是加入PSA_s后,mou增加了1.68%。如下表2所示。
4.3.3 不同模型的对比实验
为了验证条纹池化模块、极化自注意机制模块和ECA Net模块的有效性,并验证改进算法的准确性,建立了5个控制实验。其中①指DeepLabv3 +网络。
②在DeepLabv3 plus的ASPP模块中,将全局平均池化改为分条池化,并在ASPP模块之后并行增加极化自关注机制。它指的是在ASPP模块中将全局池改为分条池。DeepLabv3 plus,并在ASPP模块之后以连接形式添加极化自关注机制。④在DeepLabv3 plus的ASPP模块中将全局池化改为条池化,在ASPP模块之后增加并行形式的极化自关注机制,在MobileneV2的浅特征之后增加ECA-Net模块。⑤指将DeepLabv3 plus的ASPP模块中的全局池化改为条池化,在ASPP模块之后增加一种级联形式的极化自关注机制,以及在MobileneV2的浅层特性基础上增加ECA-Net模块。
表3比较了表中的①和②以及表中的①和③。通过使用条纹池代替全局平均池并引入极化自关注机制,Mlou算法分别提高了2.51%和2.89%。比较表中的①和④,①和⑤。在ASPP模块中,采用条形池代替全局平均池,引入极化自关注机制和ECA-Net,使mou分别增加2.58%和3.61%。通过对上表的分析,可以验证各个模块都发挥了作用,以上的改进都可以大大提高算法的精度。
4.4 不同类别的分割结果比较
在语义分割中,最重要的准确率评价指标是平均交并比,从21个类别的图中可以看出。改进后的模型只有6个分类低于原算法,且这6个分类的准确率与原算法没有显著差异。其余15个类别均高于原算法。特别是对于房屋、狗、猫、火车、羊等品类,显示出更好的优势。在加入注意机制后,提高了关键类别的准确率,可以在一定程度上提高原算法的准确率。分类分割结果如图7所示。
为了更清楚地看到改进前后的效果,我们将DeepLabv3 plus网络与改进后的DeepLabv3 plus网络的分割预测图进行比较。式中(a)为原始图像,(b)为图像标签,(c)为DeepLabv3 +分割图像,(d)为改进后的DeepLabv3 +分割图像。从结果可以看出,集成了条纹池并引入注意机制的模型分割相对来说更加流畅和完整。原来的DeepLabv3 plus网络存在误分类和不连续分割的问题。优化后的网络提高了语义分割效果,提高了分辨率,细化了目标的分割边界,取得了较好的分割精度。所选择的分割预测图如图8所示。
5.总结
本文提出了一种基于注意机制的DeepLabv3 +网络。ASPP模块将全局池化改为条带池化,捕获全局上下文信息,同时加入极化自注意机制,增强了对图像空间特征的利用。最后,通过在MobileNetV2的底层特征之后加入ECA-Net,提高了浅层特征的获取。
实验结果表明,将注意力模块作为网络嵌入DeepLabv3 plus中,可以提高关键类别的准确性,有效提高网络对图像中物体的分割精度。客观指标MIoU提高了约2%。我们的工作提高了图像语义分割的性能,为自动驾驶、医学成像等领域提供了新的思路,为计算机视觉领域提供了方向。
改进后的算法虽然有了很好的改进,但仍然存在不足。由于注意机制的引入在一定程度上增加了模型的复杂性,因此在模型复杂性和参数数量方面还需要进一步的研究。在未来,我们将考虑使用模型压缩方法来优化网络,使模型能够平衡高精度和轻量级。














 774
774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









