







定义与架构
- 定义:知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。
- 三元组的基本形式:实体1,关系,实体2 或者 概念,属性,属性值
- 逻辑架构:在逻辑上可以分为模式层与数据层。数据层主要由一系列的事实组成,只是将以事实为单位进行存储;模式层构建在数据层之上。
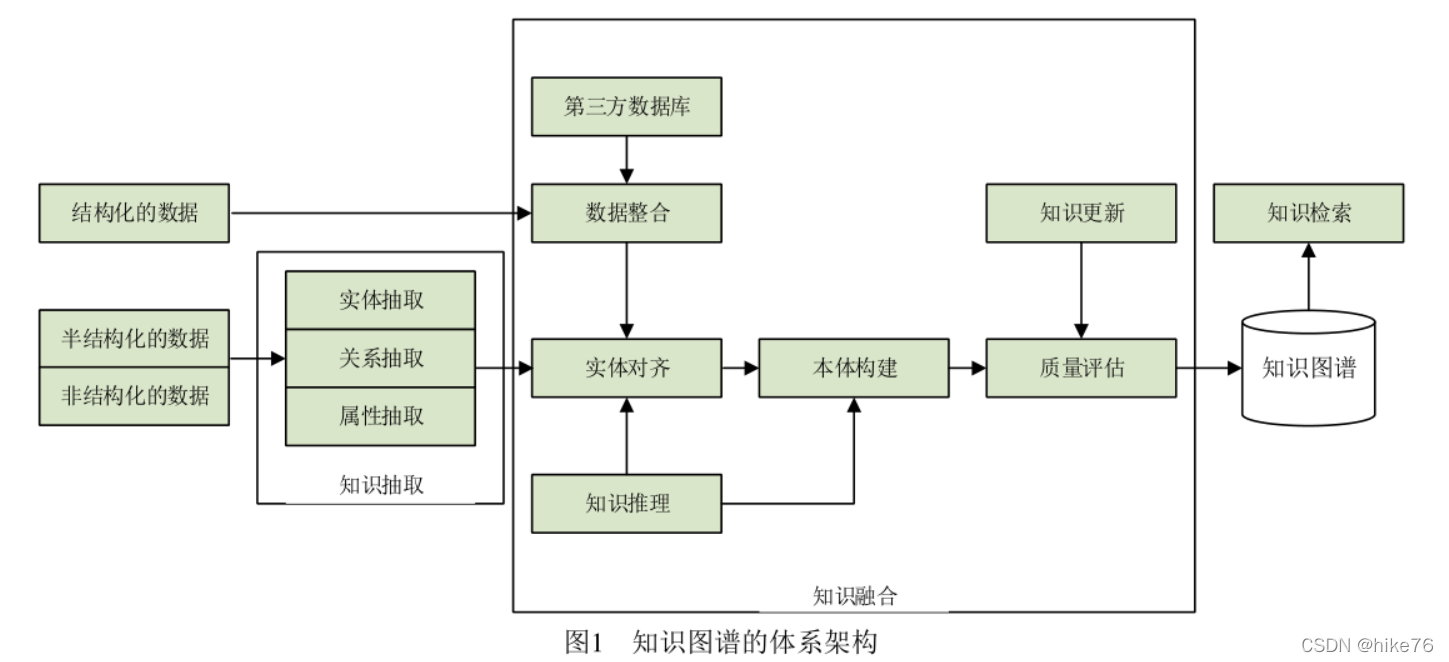
- 体系结构:指知识图谱的构建模式结构,有top-down,bottom-up(从一些开放链接数据中心提取出实体,选择置信度较高的加入到知识库,再构建顶层的本体模式。)两种构建方式,后者使用较多。
关键技术
- 知识抽取:从公开的半结构化、非结构化的数据中心提取出实体、关系、属性等知识要素;面向开放的链接数据,通过自动化技术抽取出可用的知识单元(包括3个知识要素实体(概念的外延)、关系、属性),并以此为基础,形成一系列高质量的事实表达,为上层模式层的构建奠定基础。
- 实体抽取:也称命名实体学习或命名实体识别,从原始语料中自动识别出命名实体;实体是知识图谱中最基本元素,所以实体抽取是知识抽取中最为关键的一步。
- 基于规则:通常需要为目标实体编写模板,然后在原始语料中进行匹配;需要大量的专家来编写规则或模板,覆盖的领域范围有限,很难适应数据变化的新需求。
- 基于统计机器学习:通过机器学习的方法对原始语料进行训练,然后再利用训练好的模型去识别实体;单纯的监督学习算法在性能上受到训练集合的限制,而且算法的准确率与召回率不理想;将监督学习算法与规则相结合,取得不错的效果。
- 面向开放域:面向海量的Web语料,给海量文本的实体做分类与聚类,【34】通过迭代方式扩展实体语料库(通过少量的实体实例建立特征模型,再通过该模型应用于新的数据集得到新的命名实体)【35】通过无监督学习的开放域聚类算法(用已知实体的语义特征去搜索日志中识别出命名的实体,然后进行聚类)。
- 关系抽取:目标是解决实体间语义链接的问题,
- 开放式实体关系抽取:
- 实体抽取:也称命名实体学习或命名实体识别,从原始语料中自动识别出命名实体;实体是知识图谱中最基本元素,所以实体抽取是知识抽取中最为关键的一步。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











