







Hbase的 2.X版本java API 代码开发
hbase-client使用说明
开发可参考《hbase权威指南》
版本说明
要使用 Java API 操作 HBase,需要引入 hbase-client包。
1: 开发API
hbase用java进行编写,利用hbase.client.htable类进行hbase客户端开发。
每个htable实例都会连接zookeeper去扫描.meta元数据表获取表以及region位置和关系。
1.1:主要 API 类和数据模型之间的对应关系
java 类 HBase 数据模型
HBaseConfiguration 用于连接hbase数据库,获取连接connection(DataBase)
connection.get获取对应的操作对象
HBaseAdmin 表操作对象:表对象创建,删除,查看
HTable 表内容操作对象:表内容的增删改查
ColumnFamilyDescriptorBuilder 列簇修饰符(Column Qualifier)
TableDescriptorBuilder 表修饰
四大对数据增删改查api,由HTable对象调用
HTable.
Put
Get
Delete
Scan
处理返回结果集
Result
ResultScanner
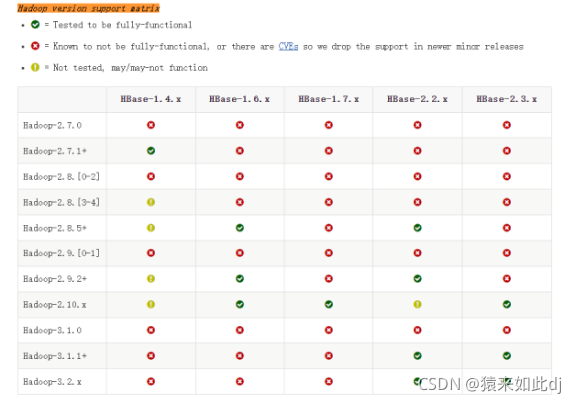
1.2:hbase开发版本对应图
官网:http://hbase.apache.org/book.html
搜索:Hadoop version support matrix 即可找到对应关系
1.3:API介绍
HBase 2.2.2 Jave API 中使用HTableDescriptor与HColumnDescriptor时提示不推荐使用了,并且在3.0.0版本将删除,而是使用TableDescriptorBuilder和ColumnFamilyDescriptorBuilder
1:连接hbase
connection应该是全局唯一的,只加载一次,单例模式或者静态方法初始化。
HBase客户端API中,对HBase的任何操作都需要首先创建HBaseConfiguration类的实例。为HBaseConfiguration类继承自Configuration类,而Configuration类属于Hadoop核心包中实现的类, 该类的主要作用是提供对配置参数的访问途径(加载hbase-site.xml等配置文件或者设置K-V参数)。
1:HBaseConfiguration
关系:org.apache.hadoop.hbase.HBaseConfiguration 作用:对 HBase连接参数 进行配置
返回值 函数 描述
void addResource(Path file) 通过给定的路径所指的文件来添加资源,如hbase.site.xml的加载
addResource类共有4种方式加载指定的配置信息:
1 :String:加载指定文件名的配置文件,该文件须在Hadoop的classpath中。
2 : Path:直接加载本地文件系统上以该参数为完整路径的配置文件。
3 : URL: 指定配置文件的Url路径并加载。
4 : InputStream:从输入流中反序列化所得到的配置对象。
void clear() 清空所有已设置的属性
String getBoolean(String name, boolean defaultValue) 获取为 boolean 类型的属性值,如果其属性值类型部位 boolean,则返回默认属性值
void set(String name, String value) 通过属性名来设置值,以k-v形式
void setBoolean(String name, boolean value) 设置 boolean 类型的属性值
使用demo
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.property.clientPort", "2181");
// 如果是集群 则主机名用逗号分隔
conf.set("hbase.zookeeper.quorum", "hdp01:2181,hdp02:2181,hdp03:2181");
conf.addResource("hbase-site.xml");//文件放在项目conf/目录中即可
该方法设置了"hbase.zookeeper.property.clientPort"的端口号为 2181,zk的集群地址去连接集群。
2:Connection
Connection是线程安全的,开发中应该一个进程共用一个Connection对象,而在不同的线程中使用单独的Table和Admin对象。在HBase访问一条数据的过程中,需要连接三个不同的服务角色:
(1)Zookeeper 的.meta表的table和region关系
(2)HBase Master 获取表的创建删除
(3)HBase RegionServer 进行数据插入
而HBase客户端的Connection包含了对以上三种socket连接的封装。
所以我们在开发时应该用单例模式去创建connection连接实例,保证每个jvm只连接一次,减少zookeeper的连接数压力。由于hbase是分布式数据库,所以在
saprk+hbase中相当于每个executor进程都会维护一个connection实例。
ConnectionFactory.createConnection()参数详解
调用此方法时,可以传入两个参数,conf是连接配置相关,ThreadPoolExecutor是什么?
根据解释是用于批处理操作的线程个数,文档较模糊,默认值是1建议自行测试
2:表的操作HBaseAdmin
getTable() 和 getAdmin() 都是轻量级,所以不必担心性能的消耗,同时建议在使用完成后显示的调用 close() 方法来关闭它们。
1、 HBaseAdmin
作用:提供了一个接口来管理 HBase 数据库的表信息。它提供的方法包括:创建表,删除表,列出表项,使表有效或无效,以及添加或删除表列簇成员等。
获取实例Connection.getAdmin()并在完成时调用close(),不适宜一直进行缓存
addColumn(String tableName, HColumnDescriptor column) :向一个已经存在的表添加列
checkHBaseAvailable(HBaseConfiguration conf) :静态函数,查看 HBase是否处于运行状态createTable(HTableDescriptor desc) 创建一个表,同步操作
deleteTable(byte[] tableName) 删除一个已经存在的表
enableTable(byte[] tableName) 使表处于有效状态
disableTable(byte[] tableName) 使表处于无效状态
HTableDescriptor[] listTables() 列出所有用户控件表项
modifyTable(byte[] tableName, HTableDescriptor htd) 修改表的模式,是异步的操作,可能需要花费时间
boolean tableExists(String tableName) 检查表是否存在
2、TableDescriptorBuilder
作用:表的列簇操作,增加删除列簇,设置表级别的参数,入表的压缩级别,存储时间等
addColumnFamily(ColumnFamilyDescriptor family)
将在 HBase 3.0.0 中删除。使setColumnFamily(ColumnFamilyDescriptor)替代
用法示例demo
HTableDescriptor htd = new HTableDescriptor(table);
htd.addFamily(new HcolumnDescriptor("family"));
在上述例子中,通过一个 HColumnDescriptor 实例,为 HTableDescriptor 添加了一个列簇:family
3、ColumnFamilyDescriptorBuilder
作用:维护着关于列簇的信息,例如版本号,压缩设置等。它通常在创建表或者为表添加列 簇的时候使用。列簇被创建后不能直接修改,只能通过删除然后重新创建的方式。列簇被删
除的时候,列簇里面的数据也会同时被删除。
ColumnFamilyDescriptorBuilder c = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(ColumnFamilys));
c.setMaxVersions(1);
c.setBlocksize(131072);//add in 20161024
c.setCompressionType(Compression.Algorithm.SNAPPY);
c.setBloomFilterType(BloomType.ROW);
c.setBlockCacheEnabled(false);
3:HTable操作数据
HTable可以用来和 HBase 表直接通信。此方法对于更新操作来说是非线程安全的,所以每个线程应该有自己的htable,不应该是作为全局变量进行线程共享。
返回值 函数 描述
void checkAdnPut(byte[] row, byte[] family, byte[] qualifier, byte[] value, Put put :自动的检查row/family/qualifier 是否与给定的值匹配
void close() 释放所有的资源或挂起内部缓冲区中的更新
Boolean exists(Get get) 检查 Get 实例所指定的值是否存在于 HTable 的列中
Result get(Get get) 获取指定行的某些单元格所对应的值
byte[][] getEndKeys() 获取当前一打开的表每个区域的结束键值
ResultScanner getScanner(byte[] family) 获取当前给定列簇的 scanner实例
HTableDescriptor getTableDescriptor() 获取当前表的HTableDescriptor 实例
byte[] getTableName() 获取表名
static booleanisTableEnabled(HBaseConfiguration conf, String tableName) 检查表是否有效
void put(Put put) 向表中添加数据
1:Put
作用:用来对单个行执行添加操作
返回值 函数 描述
Put add(byte[] family, byte[] qualifier, byte[] value)将指定的列和对应的值添加到Put 实例中
Put add(byte[] family, byte[] qualifier, long ts, byte[] value)将指定的列和对应的值及时间戳添加到 Put 实例中
byte[] getRow() 获取 Put 实例的行
RowLock getRowLock() 获取 Put 实例的行锁
long getTimeStamp() 获取 Put 实例的时间戳
boolean isEmpty() 检查 familyMap 是否为空
Put setTimeStamp(long timeStamp) 设置 Put 实例的时间戳
2:Get
作用:用来获取单个行的相关信息
返回值 函数 描述
Get addColumn(byte[] family, byte[] qualifier) 获取指定列簇和列修饰符对应的列
Get addFamily(byte[] family) 通过指定的列簇获取其对应列的所有列
Get setTimeRange(long minStamp,long maxStamp)获取指定取件的列的版本号
Get setFilter(Filter filter) 当执行 Get 操作时设置服务器端的过滤器
3:Delete
作用:用来封装一个要删除的信息
4、Scan
作用:用来封装一个作为查询条件的信息
4:Result结果处理
1:Result
作用:reset存储 Get 或者 Scan 操作后获取表的单行值。使用此类提供的方法可以直接获取值或
者各种 Map 结构(key-value 对)
返回值 函数 描述
boolean containsColumn(byte[] family, byte[] qualifier) 检查指定的列是否存在
NavigableMap<byte[],byte[]getFamilyMap(byte[] family) 获取对应列簇所包含的修饰符与值的键值对
byte[] getValue(byte[] family, byte[] qualifier) 获取对应列的最新值
2:ResultScanner
ResultScanner类把扫描操作转换为类似的get操作,它将每一行数据封装成一个Result实例,并将所有的Result实例放入一个迭代器中。
当使用完ResultScanner之后调用它的close()方法,同时,当把close()方法放到try/finally块中,以保证其在迭代获取数据过程中出现异常和错误时,仍然能执行close()。
1.4:maven依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hbase.version>2.2.2</hbase.version>
</properties>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.2.4</version>
</dependency>
2:API开发demo
2.X版本API开发示例
2.1:创建连接Configuration,connection
static final Log LOG = LogFactory.getLog(HBaseService.class);
static final long TABLE_BUFFER_SIZE = 16777216;
private static Map<String, HBaseService> serviceMap = new ConcurrentHashMap();
//private Map<String,HTableInterface> tableMap=new HashMap<String,HTableInterface>();
/*创建实例,用于单例中创建*/
private static Configuration conf = null;/*创建Configuration用于包装配置信息*/
private static Connection hConnection = null;
/*用于缓存客户端的admin实例,避免spark时频繁从服务端获取减少运行时间,提高效率*/
private static Map<String, Admin> adminMap = new ConcurrentHashMap();
/*连接方式1:通过Configuration配置集群地址等参数进行连接*/
public static Connection getConnection() throws Exception {
conf = HBaseConfiguration.create();
/*创建Configuration用于包装配置信息*/
conf.set("hbase.zookeeper.property.clientPort", "2181");
// 如果是集群 则主机名用逗号分隔
conf.set("hbase.zookeeper.quorum", "hadoop001");
//Connection conn = null;
ThreadPoolExecutor pool = null;
hConnection = ConnectionFactory.createConnection(conf);
return hConnection;
}
/*连接方式2:通过Configuration加载配置文件*/
public static Connection getConnection(String confxml) throws Exception {
HBaseConfiguration.create();
conf = HBaseConfiguration.create();
conf.addResource(confxml);
ThreadPoolExecutor pool = null;
hConnection = ConnectionFactory.createConnection(conf);
return hConnection;
}
/*关闭连接释放资源*/
public void closeConnection() {
if (hConnection != null) {
try {
hConnection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (conf != null) {
conf.clear();
}
}
2.2:创建表
利用admin实例进行创建表,删除表
获取admin实例
/*获取表操作对象:线程不安全*/
public static synchronized Admin getHBaseAdmin() {
Admin admin = null;
try {
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
return admin;
}
创建表
public static void createTable(Admin admin, String tableName, Map<String, String> tableconfig)
throws IOException {
if (HBaseService.exitsTable(tableName)) {
System.out.println("table already existed");
return;
}
TableDescriptorBuilder tableDesc = TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName));
tableDesc.setDurability(Durability.SKIP_WAL);
ColumnFamilyDescriptorBuilder b = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("A"));
//HColumnDescriptor b = new HColumnDescriptor(Bytes.toBytes("B")); 这是1.x版本方法已经被删除
b.setMaxVersions(1);
b.setBlocksize(131072); //设置最终存在hdfs上的hfile的文件块大小。建议64kb-1mb。大块适合顺序访问,小块适合随机访问
b.setCompressionType(Algorithm.SNAPPY); //设置压缩器
b.setBloomFilterType(BloomType.ROW);
ColumnFamilyDescriptor build = b.build();
tableDesc.setColumnFamily(build);
ColumnFamilyDescriptorBuilder c = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("B"));
c.setMaxVersions(1);
c.setBlocksize(131072);//add in 20161024
c.setCompressionType(Algorithm.SNAPPY);
c.setBloomFilterType(BloomType.ROW);
c.setBlockCacheEnabled(false);
tableDesc.setColumnFamily(c.build());
int splitNum = Integer.valueOf(tableconfig.get("regions"));
//创建表方式1:直接创建
admin.createTable(tableDesc.build());
//创建表方式2:预分区创建,指定分区数,rowkey算法
// admin.createTable(tableDesc.build(), new RegionSplitter.HexStringSplit().split(splitNum));
LOG.info(tableName + " is created");
}
2.3:删除表
只有表被disable时,才能被删除掉,所以deleteTable常与disableTable,enableTable,tableExists,isTableEnabled,isTableDisabled结合在一起使用。
public static boolean deleteTable(String tableName) {
try {
HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
// 删除表前需要先禁用表
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
// truncate 清空表
admin.truncateTable(TableName.valueOf("tablename"), true);
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
2.4:put插入数据
HBase是一个面向列的数据库,一行数据,可能对应多个列族,而一个列族又可以对应多个列。通常,写入数据的时候,我们需要指定要写入的列(含列族名称和列名称)
// put 一条数据
public static boolean putRow(String tableName, String rowKey, String columnFamilyName,
String qualifier,String value) {
try {
//获取table
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(qualifier), Bytes.toBytes(value));
table.put(put);
table.close();
} catch (IOException e) {
e.printStackTrace();
}
return true;
}
/*put list数据*/
public static boolean putList(String tablename, List<HbaseMessage> listMessage) {
Table table = null;
//用于存放失败数据
List<Row> errorList = new ArrayList<Row>();
try {
table = hConnection.getTable(TableName.valueOf(tablename));
ArrayList<Put> puts = new ArrayList<>();
for (HbaseMessage message : listMessage) {
Put put = new Put(Bytes.toBytes(message.getKVmessagr().get("ID").toString()));
Map kVmessagr = message.getKVmessagr();
Iterator iterator = kVmessagr.keySet().iterator();
while (iterator.hasNext()) {
String key = iterator.next().toString();
put.addColumn(Bytes.toBytes(message.getCloumnFamil()), Bytes.toBytes(key), Bytes.toBytes(kVmessagr.get(key).toString()));
}
puts.add(put);
}
table.put(puts);
} catch (IOException e) {
e.printStackTrace();
/*
如果是RetriesExhaustedWithDetailsException类型的异常,
说明这些数据中有部分是写入失败的这通常都是因为
1:HBase集群的进程异常引起
2:有时也会因为有大量的Region正在被转移,导致尝试一定的次数后失败
*/
if (e instanceof RetriesExhaustedWithDetailsException) {
RetriesExhaustedWithDetailsException ree =
(RetriesExhaustedWithDetailsException) e;
int failures = ree.getNumExceptions();
for (int i = 0; i < failures; i++) {
errorList.add(ree.getRow(i));
}
}
} finally {
if (table != null) {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return true;
}
/*批量put,性能更好*/
public static boolean batchput(String tableName, List<HbaseMessage> listMessage) {
Table table = null;
List<Row> errorList = new ArrayList<Row>(); //用于存放失败数据
try {
table = hConnection.getTable(TableName.valueOf(tableName));
ArrayList<Put> puts = new ArrayList<>();
for (HbaseMessage message : listMessage) {
Put put = new Put(Bytes.toBytes(message.getKVmessagr().get("ID").toString()));
Map kVmessagr = message.getKVmessagr();
Iterator iterator = kVmessagr.keySet().iterator();
while (iterator.hasNext()) {
String key = iterator.next().toString();
put.addColumn(Bytes.toBytes(message.getCloumnFamil()), Bytes.toBytes(key), Bytes.toBytes(kVmessagr.get(key).toString()));
}
puts.add(put);
}
table.put(puts);
} catch (IOException e) {
e.printStackTrace();
if (e instanceof RetriesExhaustedWithDetailsException) {
RetriesExhaustedWithDetailsException ree =
(RetriesExhaustedWithDetailsException) e;
int failures = ree.getNumExceptions();
for (int i = 0; i < failures; i++) {
errorList.add(ree.getRow(i));
}
}
} finally {
if (table != null) {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return true;
}
2.5:get获取数据
/**
* 根据 rowKey 获取指定行的数据
*/
public static Result getRow(String tableName, String rowKey) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
return table.get(get);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 获取指定行指定列 (cell) 的最新版本的数据
*/
public static String getCell(String tableName, String rowKey, String columnFamily, String qualifier) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
if (!get.isCheckExistenceOnly()) {
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier));
Result result = table.get(get);
byte[] resultValue = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier));
return Bytes.toString(resultValue);
} else {
return null;
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/*get查询某条某列数据:指定表,rowkey,列*/
public static String getCell(String tableName, String rowKey, String columnFamily, String qualifier) {
try {
Table table = hConnection.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
//校验数据是否存在
if (!get.isCheckExistenceOnly()) {
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier));
Result result = table.get(get);
byte[] resultValue = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier));
return Bytes.toString(resultValue);
} else {
return null;
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
2.6:scan扫描数据
/**
* 查询全表
* @param tableName 表名
*/
public static ResultScanner getScanner(String tableName) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
return table.getScanner(scan);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 查询表中用过滤器指定数据
* @param tableName 表名
* @param filterList 过滤器
*/
public static ResultScanner getScanner(String tableName, FilterList filterList) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
scan.setFilter(filterList);
return table.getScanner(scan);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 检索表中根据rowkey范围指定数据
* @param tableName 表名
* @param startRowKey 起始 RowKey
* @param endRowKey 终止 RowKey
* @param filterList 过滤器
*/
public static ResultScanner getScanner(String tableName, String startRowKey, String endRowKey, FilterList filterList) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes(startRowKey));
scan.withStopRow(Bytes.toBytes(endRowKey));
scan.setFilter(filterList);
return table.getScanner(scan);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
2.7:删除数据
/**
* 删除指定行记录
*
* @param tableName 表名
* @param rowKey 主键
*/
public static boolean deleteRow(String tableName, String rowKey) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowKey));
table.delete(delete);
} catch (IOException e) {
e.printStackTrace();
}
return true;
}
/**
* 删除指定行指定列
*
* @param tableName 表名
* @param rowKey 主键
* @param familyName 列族
* @param qualifier 列名
*/
public static boolean deleteColumn(String tableName, String rowKey, String familyName, String qualifier) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowKey));
delete.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(qualifier));
table.delete(delete);
table.close();
} catch (IOException e) {
e.printStackTrace();
}
return true;
}
}
2.8:结果集处理
结果集包括两种类型:Result和ResultScanner
public void processResult{
for(Result r : ResultScanner){
/**
for(KeyValue kv : r.list()){
String family = new String(kv.getFamily());
System.out.println(family);
String qualifier = new String(kv.getQualifier());
System.out.println(qualifier);
System.out.println(new String(kv.getValue()));
} */
//直接从result中取到某个特定的value
byte[] value = r.getValue(Bytes.toBytes("base_info"), Bytes.toBytes("name"));
System.out.println(new String(value));
} }
3:问题汇总
3.1:HBase开发错误记录(一):java.net.UnknownHostException: unknown host: hbase
使用docker部署的hbase,此时连接时没有映射,需要在本地的C:\Windows\System32\drivers\etc\hosts文件中加入映射ip hbase
3.2:HADOOP_HOME and hadoop.home.dir are unset
windwos配置配置hadoop的环境变量
1、先解压下载好的winutils-master,进入bin目录,将winutils.exe和hadoop.dll复制到C:\Windows\System32\下
2、配置HADOOP_HOOME和path中的环境变量
3:cmd中执行hadoop version保证配置完毕
4:重启idea运行
3.3:Exception in thread “main” java.lang.NoSuchMethodError: org.apache.hadoop.security.HadoopKerberosName.setRuleMechanism(Ljava/lang/String;)V
hbase启动时缺少依赖,引入hadoop-auth依赖包,hbase2.x版本对应该包的3.x版本。

















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









