







上一节我们简单说到可以通过requests库来发送get请求或者post请求来直接获取页面资源,但这仅仅是考虑到我们所需要的所有的资源都已经包含在页面中了。事实上,由于AJAX技术的实现,很多网页为了调高效率,采用了动态局部刷新的方法,这意味着网站上的内容并不一定包含我们所需要的全部资源。于是,为了解决这个问题,我们采用了动态爬取的方法。
动态爬取主要采用两种方法:一种是通过浏览器解析真实地址,另一种是通过Selenium动态模拟浏览器抓取。
一、直接通过浏览器解析真实资源地址
通过实际观察,我们发现,虽然有些网页中的资源并没有直接放在html标签中,但其实他们也跟着浏览器一起被加载到本地了,而我们只需要通过浏览器的“检查”功能来调出来。
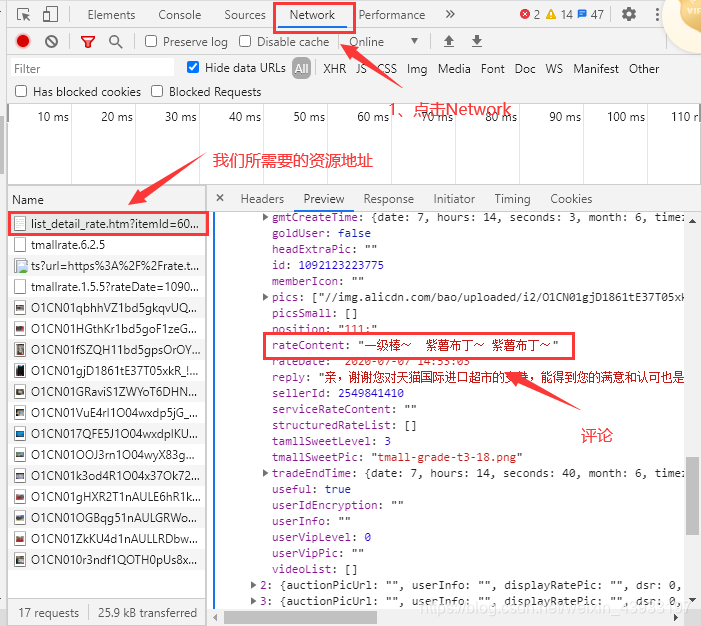
结合上图,我们需要在右边列表中自行寻找到包含资源的文件(一般是json文件),然后将其路径名称记住。之后只需要将requests发送请求的路径地址更换为该地址就可以获取到我们所需要的资源了。这么分析来,其实与静态获取相比就多了一步人工寻找资源的步骤,剩下的处理都是一样的。
二、selenium动态浏览器获取
虽然使用浏览器来协助我们检索资源地址是可行的方法,但并不是一个一直都很有效的方法。有些网页的资源很难找,有些的路径会特别长,更有的会为了反爬虫将地址进行加密。于是我们需要别的办法来进一步实现爬取。
简单思考之后,就可以发现,问题的根源在于如何同步“动”的过程,即动态的将后台的资源一点一点的从前端访问出来。没有爬虫的时候,我们需要人工点击浏览器按钮进行翻页或者发送请求,那是否可以将这样的过程通过python脚本来实现呢?答案是肯定的,selenium库就帮我们实现了这一方案。
首先,我们需要先安装selenium库,使用命令:
pip install selenium
同时,我们还需要一个浏览器的驱动程序(一个exe文件),以Chrome为例,我们之间在百度上搜索chromedriver(这是淘宝的镜像链接http://npm.taobao.org/mirrors/chromedriver/),注意下载的时候要保证驱动程序和你所安装的浏览器版本号对应。
然后就是对selenium的初始化,首先需要导入webdriver,这是一个模拟浏览器的库,它包含了模拟浏览器所需要的众多方法。之后再生成我们所需要的驱动对象driver,以后的大部分浏览器操作都是基于该对象完成的。
from selenium import webdriver
driver = webdriver.Chrome(r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe') #找到我们下载的exe文件所在的目录
driver.implicitly_wait(20) #设置隐式等待为20s,等待数据加载以及程序运行,非必要代码,可以忽略
driver.get(url) #url为实际访问的地址
如果上述代码运行无误,则会弹出一个模拟网页对话框,并加载出url所导向的网站页面。至此,动态访问资源就已经实现了一半了,剩下的就是进一步解析网站内容,从中找到我们需要的内容并获取存储。
幸运的是,selenium已经帮我们实现了这样的函数功能,如前面所说,我们可以直接通过driver来调用这些功能。
几种常见且重要的:
# 寻找第一个<div class="classname">text</div>
driver.find_element_by_css_selector('div.classname')
# 寻找第一个<div id="div_Id">text</div>
driver.find_element_by_id('div_id')
# 寻找第一个<input name="password" type="text"/>
driver.find_element_by_name('password')
# 寻找第一个<a href="index.html>Index</a>
driver.find_element_by_link_text("Index")
# 寻找第一个<h1> welcome</h1>
driver.find_element_by_tag_name('h1')
# 寻找第一个<div class="content">text</div>
driver.find_element_by_class_name('content')
# 如果需要寻找所有满足相同条件的dom元素,直接将element改为复数elements即可,例如
driver.find_elements_by_css_selector("div.classname")
将返回一个集合
# 注意没有driver.find_elements_by_id方法,因为id在HTML中是唯一的
此外,还可以通过selenium进行一些元素控制操作。
clear: 清除元素的内容
send_keys:模拟按键输入
click:单击元素
submit:提交表单
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear #清除用户名输入框
user.send_keys("小橙爱编程") #输入用户名
pw = driver.find_element_by_name("password") #找到密码输入框
pw.clear #清除密码框内容
w.send_keys("******") #在输入框中输入密码
driver.find_element_by_id("loginBtn").click() #单击登录
事实上,selenium的功能十分强大,除了上述提及功能之外,还可以实现双击、拖拽等复杂操作;同时还可以获取网页中各个元素的大小,甚至可以模拟键盘操作,因为过于详细,所以不再过多深讲。
三、最后提及
由于selenium相较于使用浏览器检查的方法来说需要将整个网站加载完毕,所以速度往往会慢一点。为了对其效率进行提高,selenium可以实现局部加载页面的功能,例如当我们只需要价格的时候,就可以将评论、图片等其他内容过滤掉,不用浏览器加载;还可以将一些CSS文件、JS文件一并过滤掉。因为他们的存在通常都是起美化或者动态化的修饰作用,对我们单纯需要的数据没什么影响。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









