







在 ZooKeeper 中,数据存储分为两部分: 内存数据存储与磁盘数据存储。
内存数据
我们已经提到, ZooKeeper 的数据模型是一棵树,而从使用角度看, ZooKeeper就像一个内存数据库一样。在这个内存数据库中,存储了整棵树的内容,包 括所有的节点路径、节点数据及其 ACL 信息等, ZooKeeper 会定时将这个数据存储到磁 盘上。接下来我们就一起来看看这棵“树”的数据结构
DataTree
DateTree 是 ZooKeeper 内存数据存储的核心,是一个“树”的数据结构,代表了内存 中的一份完整的数据。 DataTree 不包含任何与网络、客户端连接以及请求处理等相关 的业务逻辑,是一个非常独立的 ZooKeeper 组件。

DataNode
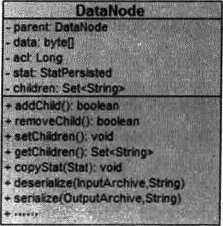
DataNode 是数据存储的最小单元,其数据结构如图 7-43 所示。 DataNode 内部除了 保存了节点的数据内容 (data[]) 、 ACL 列表 (acl) 和节点状态 (stat) 之外,正 如最基本的数据结构中对树的描述,还记录了父节点 (parent) 的引用和子节点列表 (children) 两个属性。同时, DataNode 还提供了对子节点列表操作的各个接口:
public synchronized boolean addChild(String child) {
if (children = null) {
// let's be conservative on the typical number of children children = new
HashSet<String>(8);
}
return children.add(child);
}
public synchronized boolean removechild(St ring child) {
if (children = null) {
return false;
}
return children.remove(child);
}
public synchronized void setchildren(HashSet<String> children) (
this.children = children;
}
public synchronized Set<String> getChildren() {
return children;
}
nodes
DataTree 用于存储所有 ZooKeeper 节点的路径、数据内容及其 ACL 信息等,底层的 数据结构其实是一个典型的 ConcurrentHashMap 键值对结构:
private final ConcurrentHashMap<String, DataNode> nodes = new ConcurrentHashMap<String, DataNode>();
在 nodes 这个 Map 中,存放了 ZooKeeper 服务器上所有的数据节点,可以说,对于 ZooKeeper数据的所有操作,底层都是对这个 Map 结构的操作。 nodes 以数据节点的 路径 (path) 为 key, value则是节点的数据内容: DataNode 。
另外,对于所有的临时节点,为了便于实时访问和及时清理, DataTree 中还单独将临 时节点保存起来:
private final MapcLong, HashSet<String» ephemerals = new ConcurrentHashMapvLong, HashSet<String>>();
ZKDatabase
ZKDatabase, 正如其名字一样,是 ZooKeeper 的内存数据库,负责管理 ZooKeeper 的 所有会话、DataTree 存储和事务日志。 ZKDatabase 会定时向磁盘 dump 快照数据, 同时在 ZooKeeper 服务器启动的时候,会通过磁盘上的事务日志和快照数据文件恢复成 一个完整的内存数据库。
2 事务日志
在后面的内容中,我们会多次提到 ZooKeeper 的事务日志。在本节中,我 们将从事务.日志的存储、日志格式和日志写入过程几个方面,来深入讲解 ZooKeeper 底 层实现数据一致性过程中最重要的一部分。
文件存储
我们提到在部署 ZooKeeper 集群的时候需要配置一个目录: dataDir 。 这个目录是ZooKeeper 中默认用于存储事务日志文件的,其实在 ZooKeeper 中可以为事 务日志单独分配一个文件存储目录: dataLogDir 。
如果我们确定 dataLogDir 为 /home/admin/zkData/zk_log, 那么 ZooKeeper 在运行过程 中会在该目录下建立一个名字为 version-2 的子目录,关于这个目录,我们在下面的“日 志格式”部分会再次讲解,这里只是简单提下:该目录确定了当前 ZooKeeper 使用的事 务日志格式版本号。也就是说,等到下次某个 ZooKeeper 版本对事务日志格式进行变更 时,这个目录也会有所变更。
运行一段时间后,我们可以发现在 /home/admin/zkData/zk_log/version-2 目录下会生成类 似下面这样的文件:

这些文件就是 ZooKeeper 的事务日志了。不难发现,这些文件都具有以下两个特点。
- 文件大小都出奇地一致:这些文件的文件大小都是 67108880KB, 即 64MB 。
- 文件名后缀非常有规律,都是一个十六进制数字,同时随着文件修改时间的推移, 这个十六进制后缀变大。
关于这个事务日志文件名的后缀,这里需要再补充一点的是,该后缀其实是一个事务 ID: ZXID,并且是写入该事务日志文件第一条事务记录的 ZX1D 。使用 ZXID 作为文件后缀, 可以帮助我们迅速定位到某一个事务操作所在的事务日志。同时,使用 ZXID 作为事务 日志后缀的另一个优势是, ZXID 本身由两部分组成,高 32 位代表当前 Leader 周期 (epoch), 低 32 位则是真正的操作序列号。因此,将 ZX1D 作为文件后缀,我们就可以 清楚地看出当前运行时 ZooKeeper 的 Leader周期。例如上述 4 个事务日志,前两个文件 的 epoch 是 44 (十六进制 2c 对应十进制 44), 而后面两个文件的 epoch 则是 45 。
日志格式
下面我们再来看看这个事务日志里面到底有些什么内容。为此,我们首先部署一个全新 的 ZooKeeper 服务器,配置相关的事务日志存储目录,启动之后,进行如下一系列操作。
- 创建 /testJog 节点,初始值为 “v 1” 。
- 更新 /testjog 节点的数据为 “v2” 。
- 创建〃 es,_/og/c 节点,初始值为 “v 1" 。
- 删除 /testjog/c 节点。
经过如上四步操作后,在 ZooKeeper 事务日志存储目录中就可以看到产生了一个事务日 志,使用二进制编辑器将这个文件打开后,就可以看到类似于如图 7-44 所示的文件内 容一这就是序列化之后的事务日志了。

事务日志内容初探 对于这个事务日志,我们无法直接通过肉眼识别出其究竟包含了哪些事务操作,但可以 发现的一点是,该事务日志中除前面有一些有效的文件内容外,文件后面的绝大部分都 被 “0”(\0) 填充。这个空字符填充和 ZooKeeper 中事务日志在磁盘上的空间预分配有关,在“日志写入”部分会重点讲解 ZooKeeper 事务日志文件的磁盘空间预分配策略。
在图中我们已经大体上看到了 ZooKeeper 事务日志的模样。显然,除了一些节点路径我们可以隐约地分辨出来之外,就基本上无法看明白其他内容信息了。 那么我们不禁要问,是否有一种方式,可以把这些事务日志转换成正常日志文件,以便 让开发与运维人员能够清楚地看明白 ZooKeeper 的事务操作呢?答案是肯定的。
ZooKeeper 提供了一套简易的事务日志格式化工具 org. apache, zookeeper. Server.LogFormatter, 用于将这个默认的事务日志文件转换成可视化的事务操作日志,使用 方法如下:Java LogFormatter 事务日志文件
例如,我们针对执行上述系列操作之后产生的事务日志文件,执行以下代码:java LogFormatter log.300000001
执行后的输出结果如图所示。
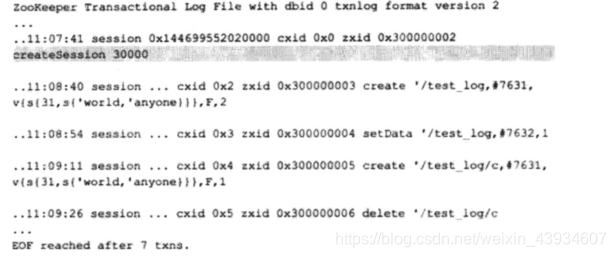
我们可以发现,所有的事务操作都被可视化显示出来了,并且每一行都 对应了一次事务操作,我们列举几行事务操作日志来分析下这个文件。
第一行:
- ZooKeeper Transactional Log File with dbid 0 txnlog format version 2
- 这一行是事务日志的文件头信息,这里输出的主要是事务日志的 DBID 和日志格式版本 号。
第二行:
- …11:07:41 session 0x144699552020000 cxid 0x0 zxid 0x300000002 createSession 30000
- 这一行就是一次客户端会话创建的事务操作日志,其中我们不难看出,从左向右分别记 录了事务操作时间、客户端会话 ID 、 CXID (客户端的操作序列号)、 ZXID, 操作类型 和会话超时时间。
第三行(图中用 … 代替了 “0x144699552020000” ):
- …11:08:40 session 0x144699552020000 cxid 0x2 zxid 0x300000003 create ,/test_log,#7631,v{s{31,s{'world,'anyone}}},F,2
- 这一行是节点创建操作的事务操作日志,从左向右分别记录了事务操作时间、客户端会 话 ID, CXID, ZXID, 操作类型、节点路径、节点数据内容 (#7631, 在上文中我们提 到该节点创建时的初始值是 vl 。在 LogFormatter 中使用如下格式输出节点内容:#+ 内容的 ASCII 码值)、节点的 ACL 信息、是否是临时节点 (F 代表持久节点, T 代表临 时节点)和父节点的子节点版本号。
- 其他几行事务日志的内容和以上两个示例说明基本上类似,这里就不再赘述,读者可以 对照ZooKeeper 的源代码(类 org.apache. zookeeper. server. LogFormatter) 自行分析。通过可视化这个文件,我们还注意到一点,由于这是一个记录事务操作的日 志文件,因此里面没有任何读操作的日志记录。
日志写入
FileTxnLog 负责维护事务日志对外的接口,包括事务日志的写入和读取等,首先来看日 志的写入。将事务操作写入事务日志的工作主要由 append 方法来负责:
public synchronized boolean append(TxnHeader hdr, Record txn)
从方法定义中我们可以看到, ZooKeeper 在进行事务日志写入的过程中,会将事务头和 事务体传给该方法。事务日志的写入过程大体可以分为如下 6 个步骤。
-
确定是否有事务日志可写。
当 ZooKeeper 服务器启动完成需要进行第一次事务日志的写入,或是上一个事务 日志写满的时候,都会处于与事务日志文件断开的状态,即 ZooKeeper 服务器没 有和任意一个日志文件相关联。因此,在进行事务日志写入前, ZooKeeper 首先 会判断 FileTxnLog 组件是否已经关联上一个可写的事务日志文件。如果没有关联 上事务日志文件,那么就会使用与该事务操作关联的 ZXID 作为后缀创建一个事 务日志文件,同时构建事务日志文件头信息(含魔数 magic 、事务日志格式版 本 version 和 dbid), 并立即写入这个事务日志文件中去。同时,将该文件的 文件流放入一个集合: streamsToFlush。steamsToFlush 集合是 ZooKeeper用来记录当前需要强制进行数据落盘(将数据强制刷入磁盘上)的文件流,在后 续的步骤 6中会使用到。
-
确定事务日志文件是否需要扩容(预分配)。
在前面“文件存储”部分我们已经提到, ZooKeeper 的事务日志文件会采取“磁 盘空间预分配”的策略。当检测到当前事务日志文件剩余空间不足 4096 字节 (4KB) 时,就会开始进行文件空间扩容。文件空间扩容的过程其实非常简单,就是在现 有文件大小的基础上,将文件大小增加65536KB (64MB), 然后使用 “0”(\0) 填充这些被扩容的文件空间。因此在图 7-44 所示的事务日志文件中,我们会看到 文件后半部分都被%”填充了。
那么 ZooKeeper 为什么要进行事务日志文件的磁盘空间预分配呢?在前面的章节 中我们已经提到,对于客户端的每一次事务操作, ZooKeeper 都会将其写入事务 日志文件中。因此,事务日志的写入性能直接决定了 ZooKeeper 服务器对事务请 求的响应,也就是说,事务写入近似可以被看作是一个磁盘 I/O 的过程。严格地 讲,文件的不断追加写入操作会触发底层磁盘 I/O 为文件开辟新的磁盘块,即磁 盘 Seek 。因此,为了避免磁盘 Seek 的频率,提高磁盘 I/O 的效率, ZooKeeper 在 创建事务日志的时候就会进行文件空间“预分配”——在文件创建之初就向操作 系统预分配一个很大的磁盘块,默认是 64MB, 而一旦已分配的文件空间不足 4KB 时,那么将会再次“预分配”,以避免随着每次事务的写入过程中文件大小增长带 来的 Seek 开销,直至创建新的事务日志。事务日志“预分配”的大小可以通过系统属性 zookeeper. preAIlocSize 来进行设置。
-
事务序列化
事务序列化包括对事务头和事务体的序列化,分别是对 TxnHeader( 事务头)和 Record (事务体)的序列化。其中事务体又可分为会话创建事务 (CreateSessionTxn), 节点 创建事务(CreateTxn) 、节点删除事务 (DeleteTxn) 和节点数据更新事务 (SetDataTxn) 等。
序列化过程和之前提到的序列化原理是一致的,最终生成一个字节数组,这 里不再赘述。
-
生成 Checksum
为了保证事务日志文件的完整性和数据的准确性, ZooKeeper 在将事务日志写入 文件前,会根据步骤 3 中序列化产生的字节数组来计算 Checksum., ZooKeeper 默 认使用 Adler32 算法来计算 Checksum 值。
-
写入事务日志文件流。
将序列化后的事务头、事务体及 Checksum 值写入到文件流中去。此时由于 ZooKeeper 使用的是 BufferedOutputStream, 因此写入的数据并非真正被写入到磁盘文件上。
-
事务日志刷入磁盘。
在步骤 5 中,已经将事务操作写入文件流中,但是由于缓存的原因,无法实时地 写入磁盘文件中,因此我们需要将缓存数据强制刷入磁盘。在步骤 1 中我们已经 将每个事务日志文件对应的文件流放入了 streamsToFlush, 因此这里会从 streamsToFlush 中提取出文件流,并调用 FileChannel. force(boolean metaData) 接口来强制将数据刷入磁盘文件中去。 force接口对应的其实是底层 的 fsync 接口,是一个比较耗费磁盘 I/O 资源的接口,因此ZooKeeper 允许用户 控制是否需要主动调用该接口,可以通过系统属性 zookeeper.forceSync 来 设置。
日志截断
在 ZooKeeper 运行过程中,可能会出现这样的情况,非 Leader 机器上记录的事务 ID (我 们将其称为 peerLastZxid) 比 Leader 服务器大,无论这个情况是如何发生的,都是一个 非法的运行时状态。同时, ZooKeeper 遵循一个原则:只要集群中存在 Leader, 那么所 有机器都必须与该 Leader的数据保持同步。
因此,一旦某台机器碰到上述情况, Leader 会发送 TRUNC 命令给这个机器,要求其进 行日志截断。 Learner 服务器在接收到该命令后,就会删除所有包含或大于 peerLastZxid 的事务日志文件。
3 snapshot ----- 数据快照
数据快照是 ZooKeeper 数据存储中另一个非常核心的运行机制。顾名思义,数据快照用 来记录ZooKeeper 服务器上某一个时刻的全量内存数据内容,并将其写入到指定的磁盘 文件中。
文件存储
和事务日志类似, ZooKeeper 的快照数据也使用特定的磁盘目录进行存储,读者也可以 通过dataDir 属性进行配置。
假定我们确定 dataDir ^/home/admin/zkData/zk_data ,那么 ZooKeeper 在运行过程中 会在该目录下建立一个名为 version-2 的目录,该目录确定了当前 ZooKeeper 使用的快照数 据格式版本号。运行一段时间后,我们可以发现 ^./home/admin/zkData/zk_data/version-2 目录下会生成类似下面这样的文件:
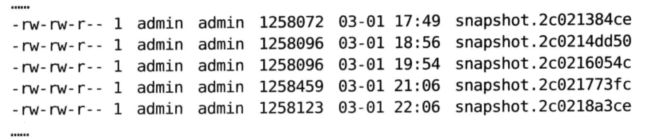
和事务日志文件的命名规则一致,快照数据文件也是使用 ZXID 的十六进制表示来作为 文件名后缀,该后缀标识了本次数据快照开始时刻的服务器最新 ZXID 。这个十六进制 的文件后缀非常重要,在数据恢复阶段, ZooKeeper 会根据该 ZXID 来确定数据恢复的 起始点。
和事务日志文件不同的是, ZooKeeper 的快照数据文件没有采用“预分配”机制,因此 不会像事务日志文件那样内容中可能包含大量的"0”。每个快照数据文件中的所有内容 都是有效的,因此该文件的大小在一定程度上能够反映当前 ZooKeeper 内存中全量数据 的大小。
存储格式
现在我们来看快照数据文件的内容。和 7.9.2 节的“日志格式”部分讲解的一样,也部 署一个全新的 ZooKeeper 服务器,并进行一系列简单的操作,这个时候就会生成相应的 快照数据文件,使用二进制编辑器将这个文件打开后

图就是一个典型的数据快照文件内容,可以看出, ZooKeeper 的数据快照文件同样 让人无法看明白究竟文件内容是什么。所幸 ZooKeeper 也提供了一套简易的快照数据格 式化工具 org .apache, zookeeper, server. Snapshot Formatter, 用于将这个默 认的快照数据文件转换成可视化的数据内容,使用方法如下:Java SnapshotFormatter 快照数据文件
例如,我们针对执行上述系列操作之后产生的快照数据文件,执行以下代码:java SnapshotFormatter snapshot.300000007
执行后的输出结果如图所示。
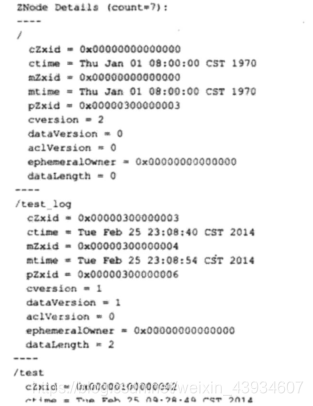
我们可以看到,之前的二进制形式的文件内容已经被格式化输出了: SnapshotFormatter 会将 ZooKeeper 上的数据节点逐个依次输出,但是需要注意的 一点是,这里输出的仅仅是每个数据节点的元信息,并没有输出每个节点的数据内容, 但这已经对运
维非常有帮助了。
数据快照
FileSnap 负责维护快照数据对外的接口,包括快照数据的写入和读取等。我们首先来看 数据的写入过程——将内存数据库写入快照数据文件中其实是一个序列化过程。
我们已经提到,针对客户端的每一次事务操作, ZooKeeper 都会将它们记 录到事务日志中,当然,ZooKeeper 同时也会将数据变更应用到内存数据库中。另外, ZooKeeper 会在进行若干次事务日志记录之后,将内存数据库的全量数据 Dump 到本地 文件中,这个过程就是数据快照。可以使用 snapCount 参数来配置每次数据快照之间的 事务操作次数,即 ZooKeeper 会在 snapCount 次事务日志记录后进行一个数据快照。
下面我们重点来看数据快照的过程。
-
确定是否需要进行数据快照。
每进行一次事务日志记录之后, ZooKeeper 都会检测当前是否需要进行数据快照。 理论上进行 snapCount 次事务操作后就会开始数据快照,但是考虑到数据快照对 于 ZooKeeper 所在机器的整体性能的影响,需要尽量避免 ZooKeeper 集群中的所 有机器在同一时刻进行数据快照。因此 ZooKeeper 在具体的实现中,并不是严格 地按照这个策略执行的,而是采取“过半随机”策略,即符合如下条件就进行数 据快照:
logCount> (snapCount / 2 + randRoll)其中 logCount 代表了当前已经记录的事务日志数量, randRoll 为 1 ~snapCount/2 之间的随机数,因此上面的条件就相当于:如果我们配置的 snapCount 值为默认 的 100000, 那么ZooKeeper 会在 50000- 100000 次事务日志记录后进行一次数据 快照。
-
切换事务日志文件。
满足上述条件之后, ZooKeeper 就要开始进行数据快照了。首先是进行事务日志 文件的切换。所谓的事务日志文件切换是指当前的事务日志已经“写满”(已经写 入了 snapCount 个事务日志),需要重新创建一个新的事务日志。
-
创建数据快照异步线程。
为了保证数据快照过程不影响 ZooKeeper 的主流程,这里需要创建一个单独的异步线程来进行数据快照。
-
获取全量数据和会话信息。
数据快照本质上就是将内存中的所有数据节点信息 (DataTree) 和会话信息保 存到本地磁盘中去。因此这里会先从 ZKDatabase 中获取到 DataTree 和会话 信息。
-
生成快照数据文件名。
在“文件存储”部分,我们已经提到快照数据文件名的命名规则。在这一步中,ZooKeeper 会根据当前已提交的最大 ZXID 来生成数据快照文件名。
-
数据序列化。
接下来就开始真正的数据序列化了。在序列化时,首先会序列化文件头信息,这 里的文件头和事务日志中的一致,同样也包含了魔数、版本号和 dbid 信息。然后 再对会话信息和DataTree 分别进行序列化,同时生成一个 Checksum, 一并写 入快照数据文件中去。

















 2735
2735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









