






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
文章地址:https://dl.acm.org/doi/10.1145/3502181.3531467
背景
这是由Qiang Fu, Yuede Ji, and H. Howie Huang. 团队发表于HPDC2022的论文,主要讲了在GPU内部高校划分GNN节点给warp的策略。
图神经网络的训练过程就是顶点特征不断更新的过程,不同的模型采取不同的更新策略。
本文将激活函数前的所有操作统称为图卷积。显然,图卷积占据了图神经网络计算的大部分时间,因此本文着重对这一过程的计算模式进行优化。
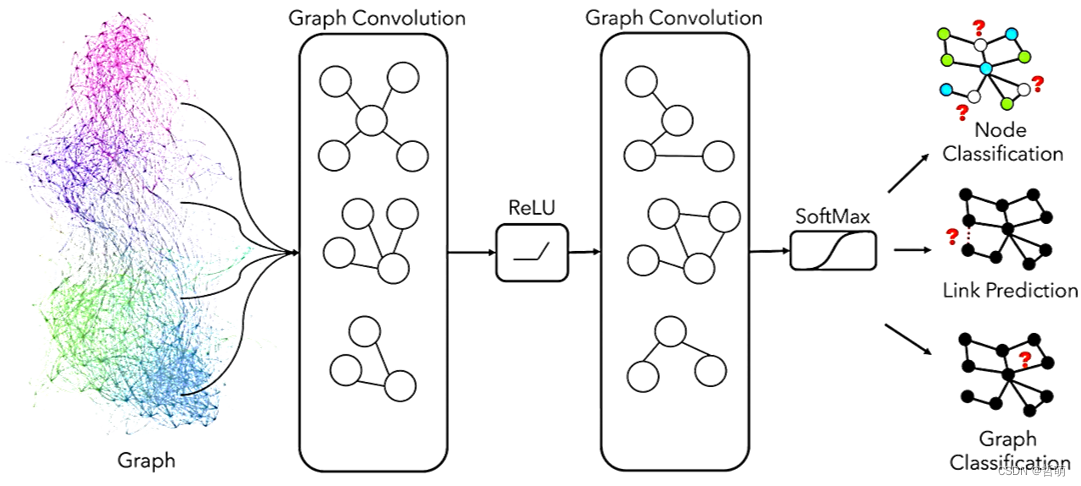
一、图卷积神经网络简单介绍
主要操作包含(1)邻域聚合(Aggregation); (2)神经网络操作(NN Operation); (3)带权求和(Reduction)
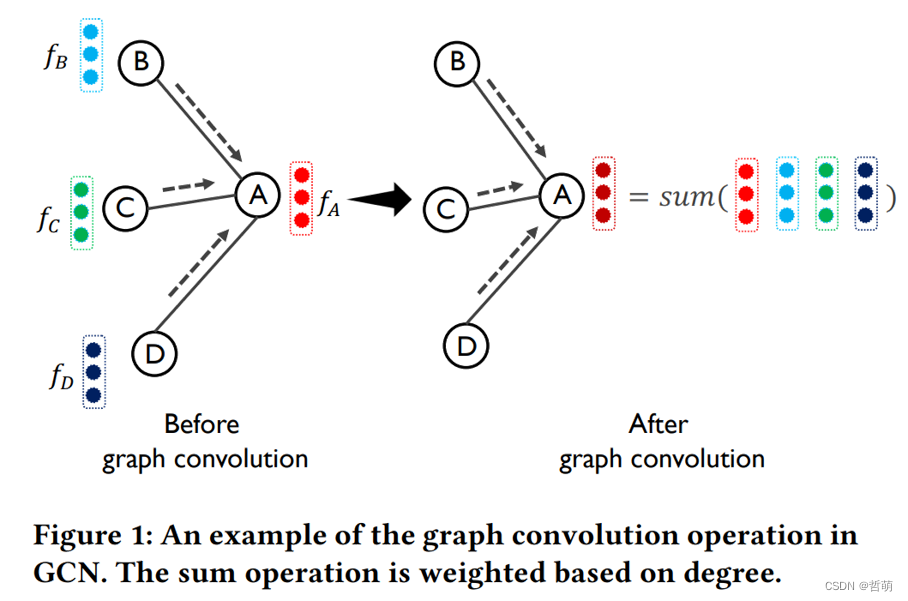
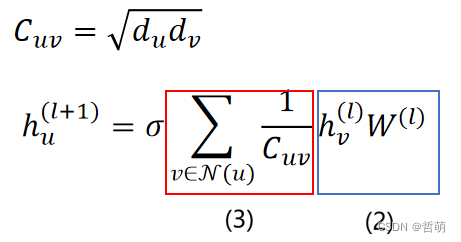

二、动机
1.简述
图神经网络的计算和传统图处理(graph processing) 有许多不同之处,例如顶点特征维度的大小等。因此,不能直接将传统图处理的计算模式应用到图卷积的计算中。
虽然有很多相关工作,例如:DGL, Pytorch PyG等大型开源图神经网络框架,考虑到了上述点,设计了多种计算模式的优化策略,但是他们的优化策略没有全面的考虑对硬件(例如GPU) 的影响,会产生资源利用率低下等问题。
因此,本文首先选取指标,对现有的计算模式进行分析,挖掘影响图卷积算子性能的主要因素,得出在设计图卷积算子时应该遵循的几点原则。再基于这些发现,设计新的图卷积算子。
2.Profiling of Cuda C
Atomic Operation(原子操作): 在CUDA程序中,原子操作用于避免多个线程同时写入同一个内存地址时导致的竞争情况,使用原子操作可以保证同一时刻只有一个线程在写入(类似于锁机制)。

int atomicAdd(int* address, int val);
这一行代码代表这kernel函数在执行操作时需要锁定GPU的显存块执行加法,该内存段无法被共享。
CUDA C编程的图神经网络中,有四种对顶点操作的方法:
- Push: 每个顶点都并行地将特征写入其所有相邻顶点
- Edge-centric: 每条边都并行地将起点特征写入终点
- GNNAdvisor:使用原子操作,对批量节点进行处理
- Pull: 每个顶点读取所有相邻节点的特征,再进行并行处理
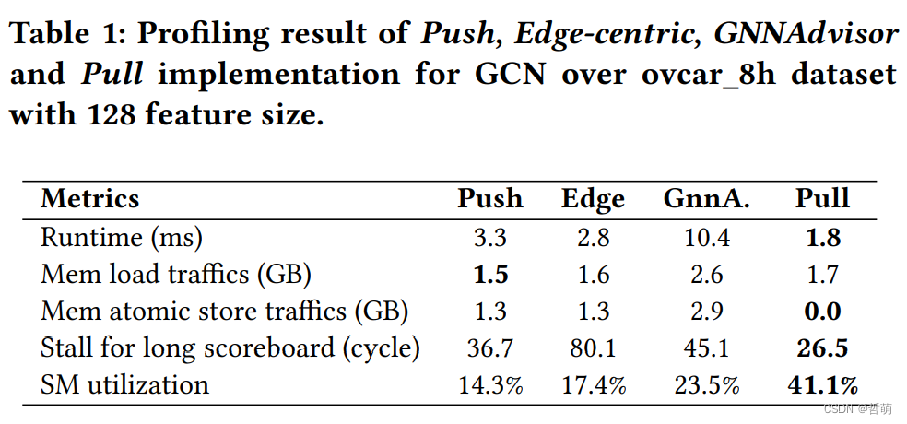
下表代表各种操作开销对比:
3.Profiling of Coalesced Memory Access
Coalesced Memory Access(合并访存): 在CUDA程序中,合并访存是指同一Warp(32 threads)内的线程访问连续内存地址,在GPU中:
读写全局内存的最小粒度= 32 Bytes = 1 sector
对齐且连续的32Bytes大小的读写可以被合并成一次内存事务,发送到GPU LD/ST Unit
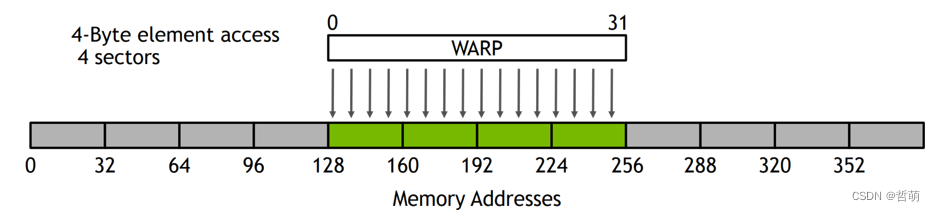 Coalesced Access
Coalesced Access
4 sectors
4 32-byte memory transactions
100% efficiency
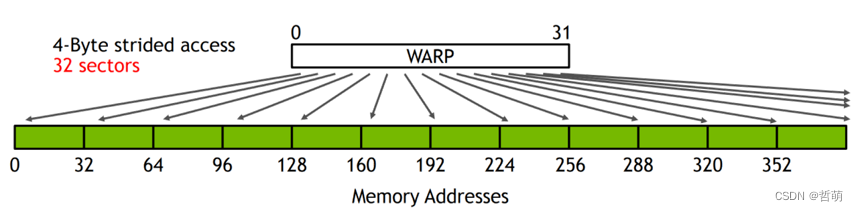 Strided Access
Strided Access
32 sectors
32 32-byte memory transactions
12.5% efficiency
在传统的图处理中,每个顶点的特征是标量值(即一个int或float类型),并且图结构不规则,访存随机性很大,很难实现合并访问。
GNN中顶点特征维度较大,每个顶点的特征是一个Tensor数组,在内存上保证连续,提供了实现更加合并的访存模式的机会。

从上表中可以发现使用同一个warp的好处(runtime非常小)。因此合并内存访问提高性能->确保在任何可能的情况下合并全局内存访问。
4.Profiling of Kernel Launch
Kernel Launch(核函数启动): 更多的核函数意味着更高的核函数启动开销和更多的内存使用.
在cuda c编程中每定义一个函数,即被称为核函数kernel。现有的大型开源框架(如DGL) 由于基于Pytorch以及使用CuSparse等第三方库的原因,存在大量的核函数。启动核函数具有以下特点:
- Kernel launch time ≈ Runtime – GPU time 核函数越多,启动时间越长
- 存在后一个核函数需要使用前一个核函数计算结果的情况。
- 核函数越多,需要存储的中间结果越多,显存的使用越多
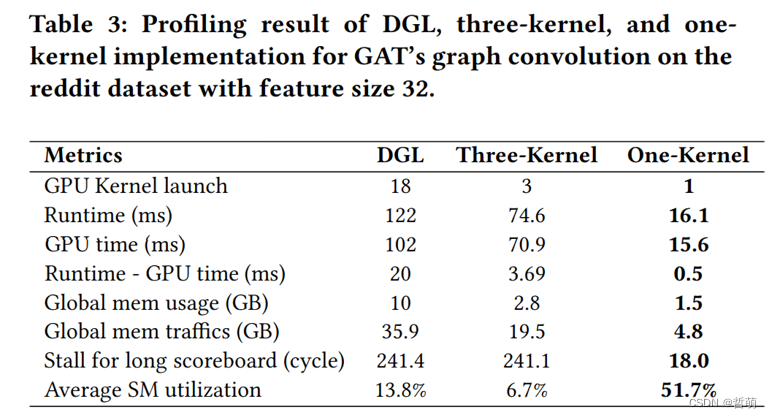 因此想要加速GCN,gnn的图卷积应该用尽可能少的核来实现。
因此想要加速GCN,gnn的图卷积应该用尽可能少的核来实现。
三、设计
1.顶点分配给一整个warp
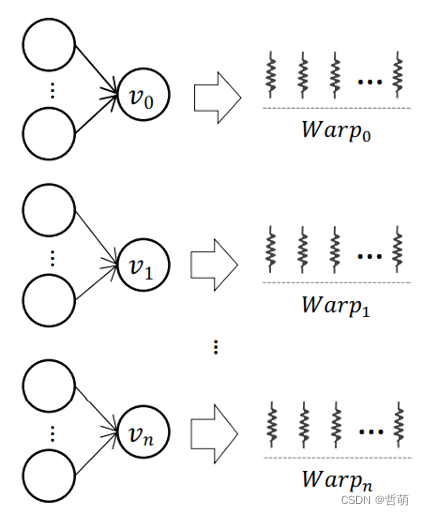
- 一个线程处理一条边: 虽然能避免工作负载不均衡,但会引入原子操作,带来巨大开销
- 一个线程处理一个顶点: 引入if-else 分支, 产生Warp divergence; 非合并访存(Strided
Access)导致访存效率低下 - 多个warp处理一个顶点: 引入多个warp之间同步操作的额外开销,会导致计算效率降低
设计要点:Mapping each vertex to a warp. 一个Warp并行处理一个顶点的图卷积过程。避免同步操作的开销,消除Warp divergence,容易实现合并访存。
2.Warp Divergence
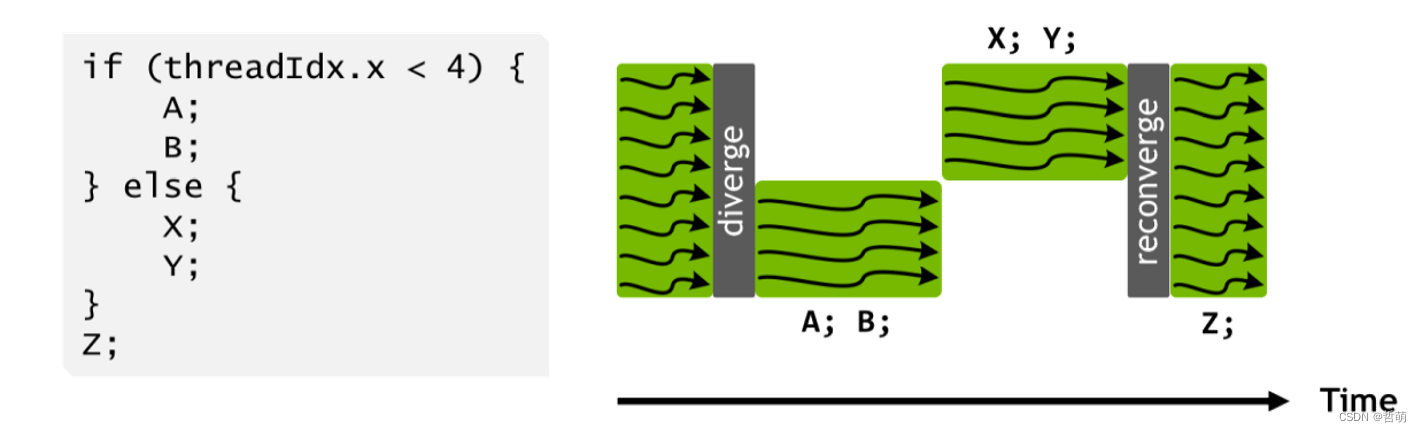 从上图可以看到,不处在分支内的线程实际上是不工作的,导致资源利用率降低。因此在设计时,可针对条件分支语句做一些优化: Feature Parallelism. (特征并行,Warp中线程的并行模式) 。
从上图可以看到,不处在分支内的线程实际上是不工作的,导致资源利用率降低。因此在设计时,可针对条件分支语句做一些优化: Feature Parallelism. (特征并行,Warp中线程的并行模式) 。
Loop scheme: 有两种可能的方式。循环特征维度,每个循环内并行的处理不同邻居节点的同一特征维度;循环邻居节点,每个循环内并行的处理一个邻居节点的不同特征维度。
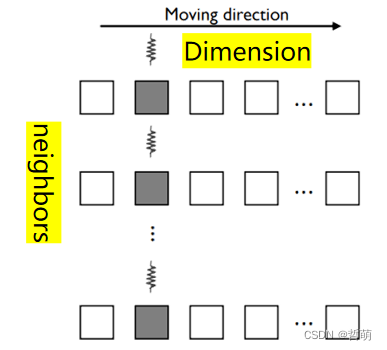 不采用循环特征维度:
不采用循环特征维度:
- 一个Warp中的线程同一时刻总是处理同一特征维度,这意味着它们总是更新特征的同一维度,即访问相同地址,会引入原子操作
- 引入原子操作,例如:AtomicAdd
- Warp中的线程访问分布在global memory分散地址(scattered addresses)中的数据
- 导致非合并的访存模式
Loop scheme: 循环邻居节点,每个循环内并行的处理一个邻居节点的不同特征维度。
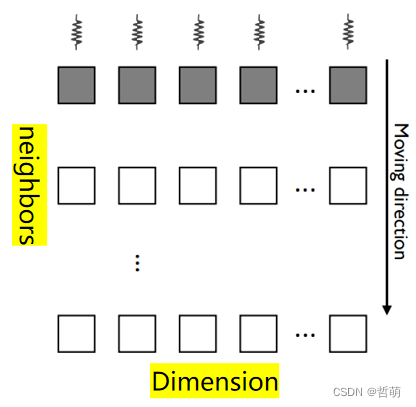 采用循环邻居节点:
采用循环邻居节点:
- 一个Warp中的线程在任何时候都处理不同的特征维度,这意味着它们总是更新特征的不同维度
- 避免引入原子操作而降低计算效率
- 一个Warp内的所有线程处理单个邻居特征的连续维度
- 实现合并访存模式
3.Hybrid Workload Balancing
节点并行可能导致工作负载分布不均衡
Hardware-based assignment: 每个warp负责一个节点,使用与输入图节点数相同的Warp总数。
问题:产生大量Warp和Block,过于依赖Block scheduler(闭源硬件) 的调度,不透明;处理不了大图(最大线程数量受到硬件限制)
Software-based assignment: 类似于任务池,每个warp每次处理固定数量的节点,处理完后如果池子不空,则继续。Warp总数可以小于节点数量,且不会闲置
Heuristic hybrid assignment:
Software: vertices > 1M or average degree > 50
Hardware: otherwise
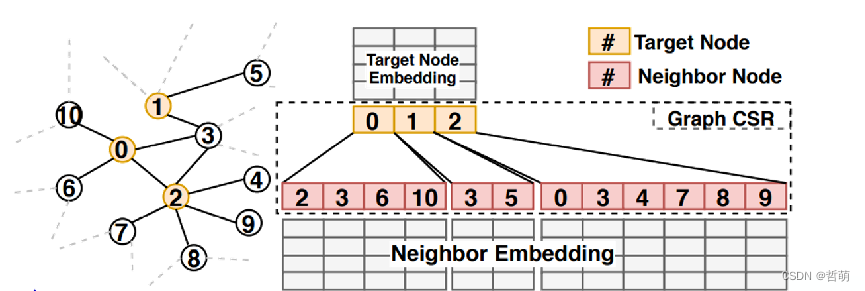 ## 4.Kernel fusion and register caching
## 4.Kernel fusion and register caching
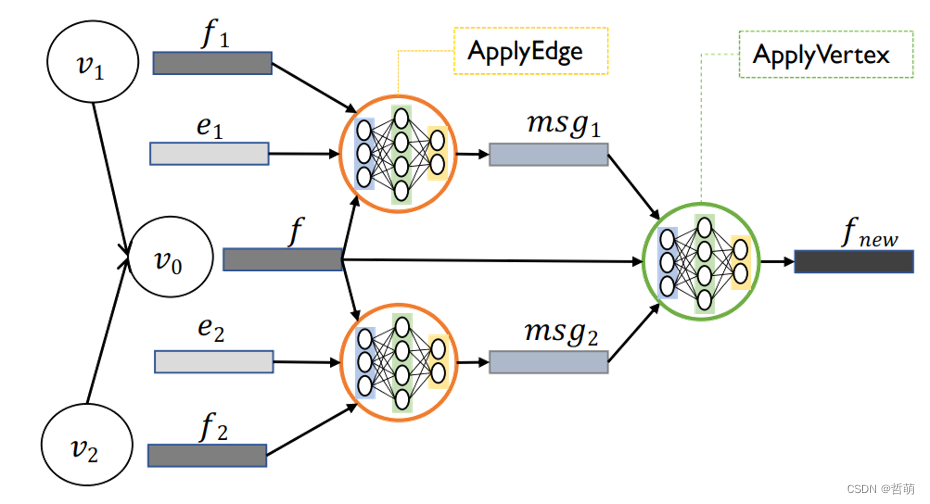 如图所示,编码只用两个核函数
如图所示,编码只用两个核函数
 避免缓存错误共享
避免缓存错误共享
四、实验结果
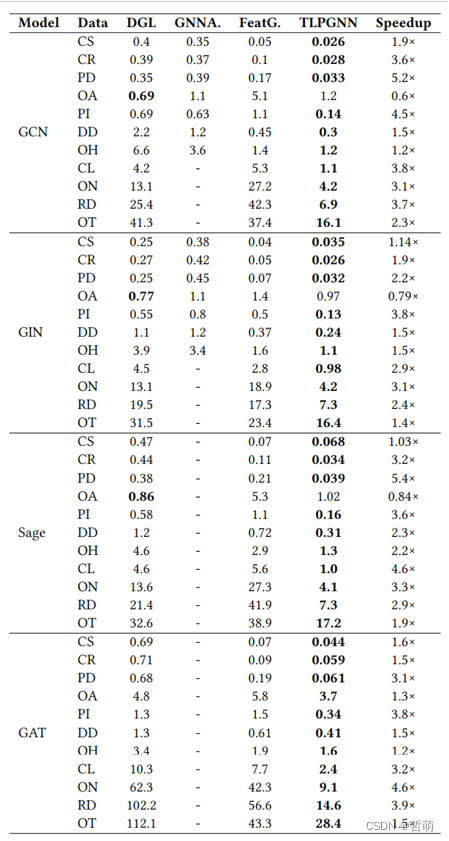
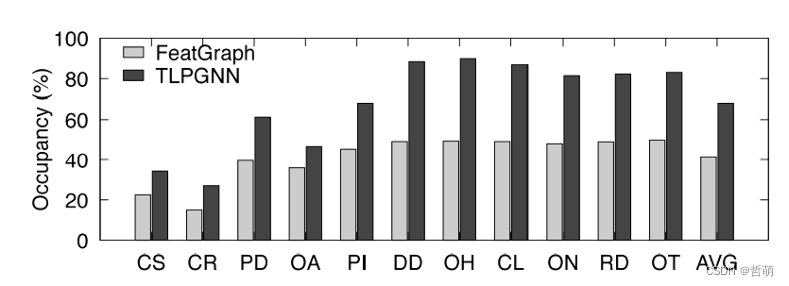
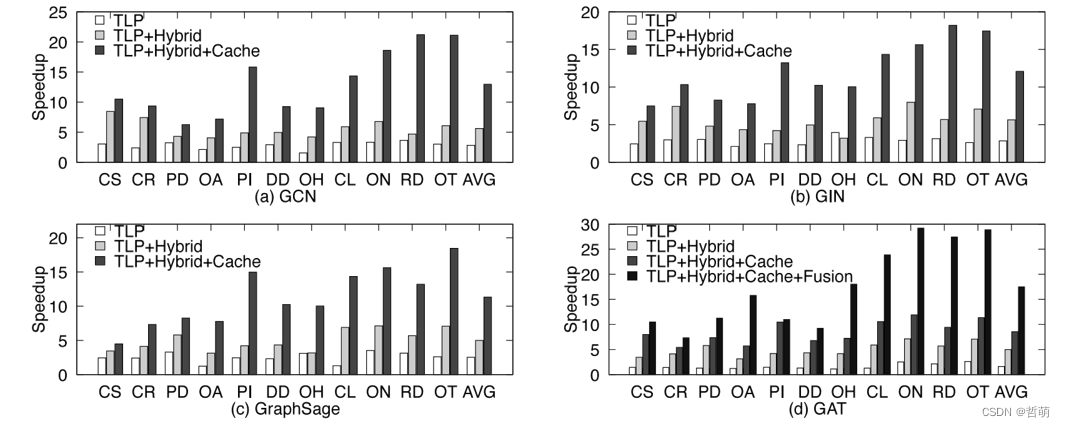
对比之下,自然有了很好的性能加速效果。















 8887
8887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









