









运行tesorflow代码出现显卡不足出现如下错误
2019-06-13 09:37:18.789283: I T:\src\github\tensorflow\tensorflow\core\common_runtime\bfc_allocator.cc:665] Chunk at 000000030614C200 of size 256
2019-06-13 09:37:18.789416: I T:\src\github\tensorflow\tensorflow\core\common_runtime\bfc_allocator.cc:665] Chunk at 000000030614C300 of size 256
2019-06-13 09:37:18.789547: I T:\src\github\tensorflow\tensorflow\core\common_runtime\bfc_allocator.cc:665] Chunk at 000000030614C400 of size 256
2019-06-13 09:37:18.789679: I T:\src\github\tensorflow\tensorflow\core\common_runtime\bfc_allocator.cc:665] Chunk at 000000030614C500 of size 6912
2019-06-13 09:37:18.789813: I T:\src\github\tensorflow\tensorflow\core\common_runtime\bfc_allocator.cc:665] Chunk at 000000030614E000 of size 6912
2019-06-13 09:37:18.789951: I T:\src\github\tensorflow\tensorflow\core\common_runtime\bfc_allocator.cc:665] Chunk at 000000030614FB00 of size 6912
2019-06-13 09:37:18.790090: I T:\src\github\tensorflow\tensorflow\core\common_runtime\bfc_allocator.cc:665] Chunk at 0000000306151600 of size 6912
2019-06-13 09:37:18.790229: I T:\src\github\tensorflow\tensorflow\core\common_runtime\bfc_allocator.cc:665] Chunk at
查看了网上错误的原因如下:
报错原因:显卡内存不够;
解决办法:
报错原因:显卡内存不够;
解决办法:
- 首先查看显卡占用情况,有可能是显卡内存被别的程序占用没有退出,可以后台查看;
- 排除第一种情况之后,考虑:bath_size可能设置过大,可以适当调小。
1.然后我试了一下将batch_size逐渐降低,从128降到32,但是发现代码运行一段时间还是不行并且出现上面的错误。
2.将sess = tf.Session(config=sess_config) 更改为
sess_config = tf.ConfigProto() sess_config.gpu_options.per_process_gpu_memory_fraction = 0.4
sess = tf.Session(config=sess_config)
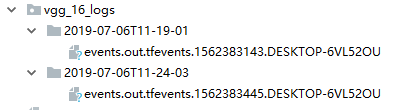
最后发现还是出错,最后检查发现是保存的节点信息所占的内存过多,我是反复训练了多个episode,因为迭代训练多次所以保存了好多图节点如下图所示,所以最后将保存logs的代码删除就可以了。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









