








今天分享的是RVC声音克隆项目,该项目不是新发布的项目,可能有的小伙伴已经了解和体验过这个项目了。
Retrieval-based-Voice-Conversion简称RVC,一个基于VITS的简单易用的变声框架。
很早之前用过该项目和so-vits-svc,当时还没开始写公众号,一直没来的及记录下,正好前段时间群友要MAC版本的,抽空做一个,哈哈。
(当然也有Windows版本的)
该项目支持训练、推理、音频处理等功能。比如之前网上听到的AI孙燕姿、AI周杰伦等AI翻唱都可以借助这个项目实现。
该项目特点
- 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
- 即便在相对较差的显卡上也能快速训练
- 使用少量数据进行训练也能得到较好结果(推荐至少收集10分钟低底噪语音数据)
- 可以通过模型融合来改变音色(借助ckpt处理选项卡中的ckpt-merge)
- 可调用UVR5模型来快速分离人声和伴奏
- 使用先进的人声音高提取算法InterSpeech2023-RMVPE根绝哑音问题。效果最好(显著地)但比crepe_full更快、资源占用更小
准备工作
训练用的音频素材,这里我准备了三段(准备好人声的素材,最好没有嘈杂的背景音,如果有背景音后面会说如何去除)
这是其中一段的效果。
(音频素材演示)
推理用的音频素材(最后需要翻唱的音频)
(推理素材演示)
使用方法
打开整合包进入主界面
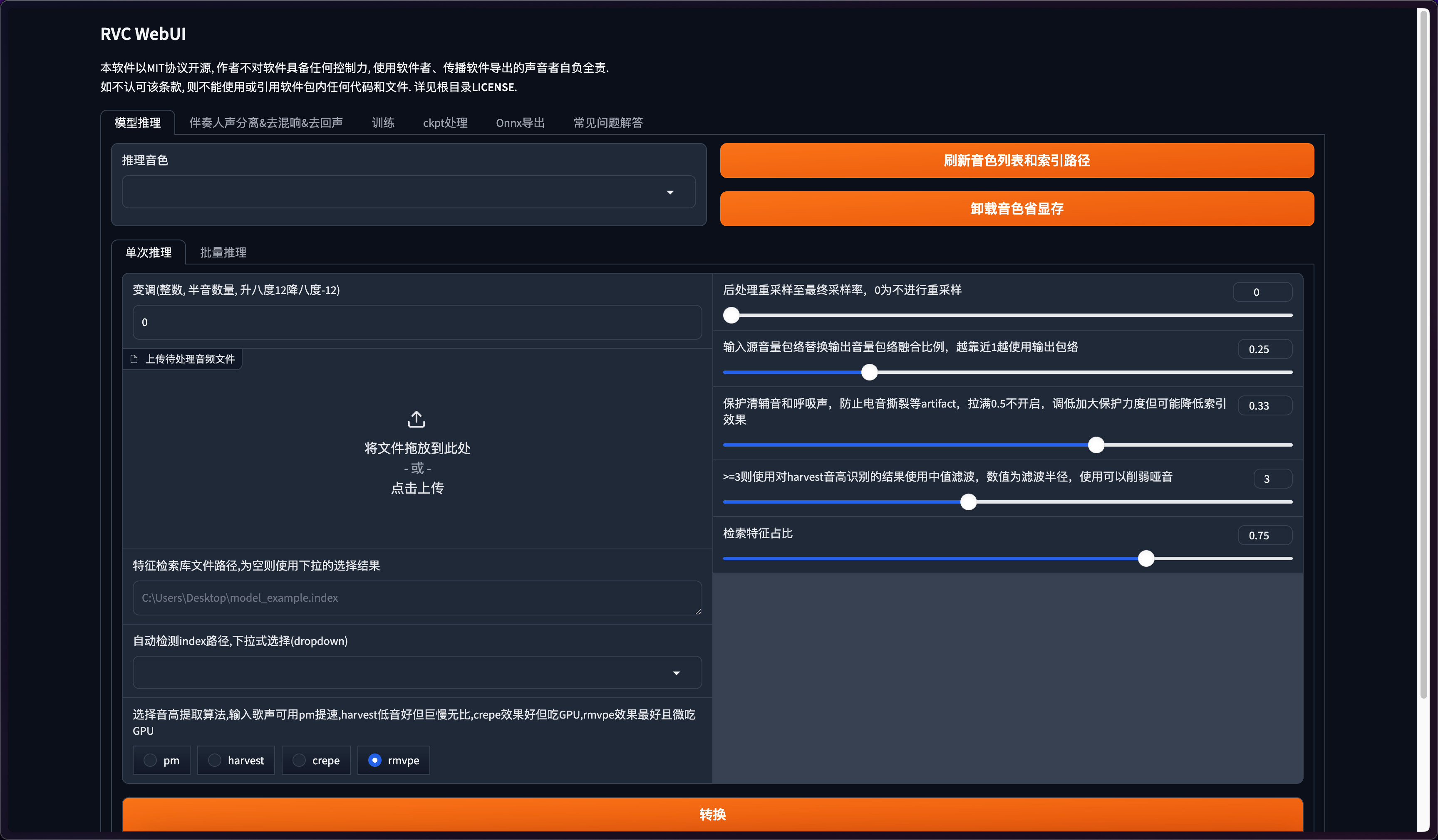
RVC一共分模型推理、伴奏处理(人声分离)、模型训练、ckpt处理、Onnx导出、常见问题解答六个部分。
伴奏处理
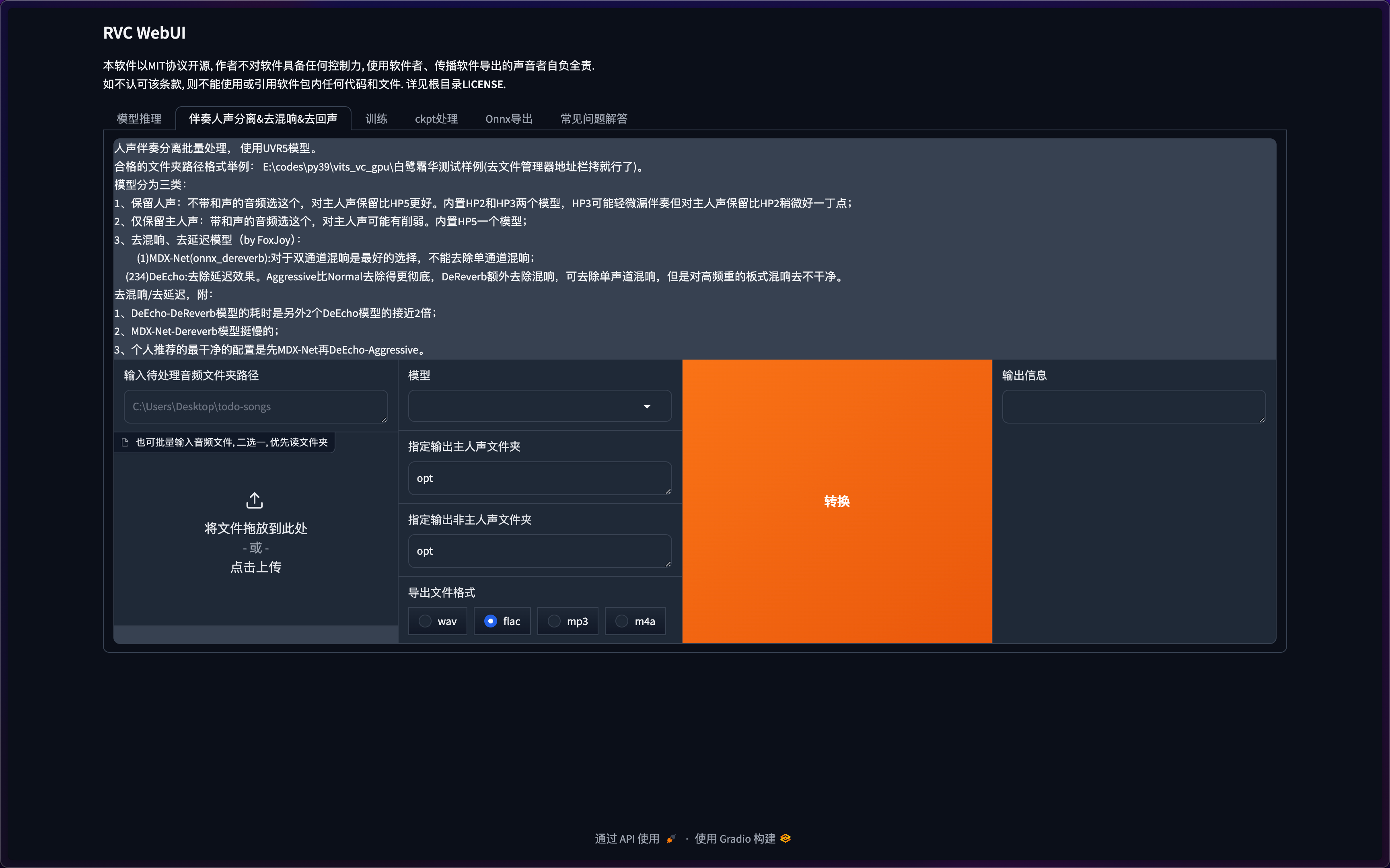
此步骤可选,如果你的音频足够干净,可以跳过这一步。
将你需要处理的音频路径粘贴到输入待处理音频文件夹路径这一栏
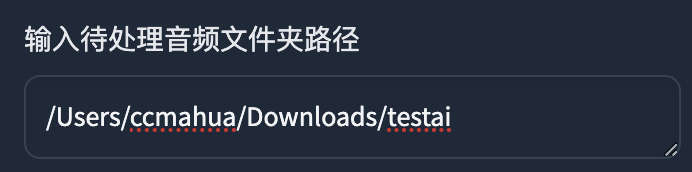
示例:
MAC
/Users/ccmahua/Downloads/testaiWIN
C:\User\Destop\todo也可以将需要处理的音频直接拖拽进去
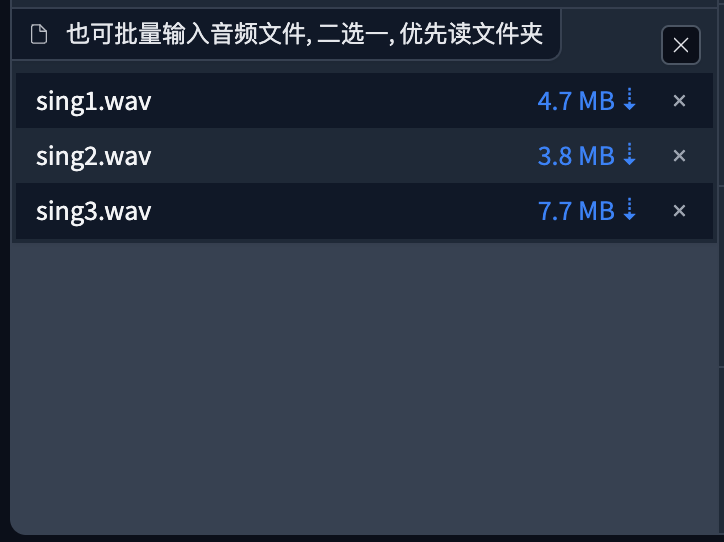
然后选择HP3_all_vocals模型,导出文件格式选择WAV
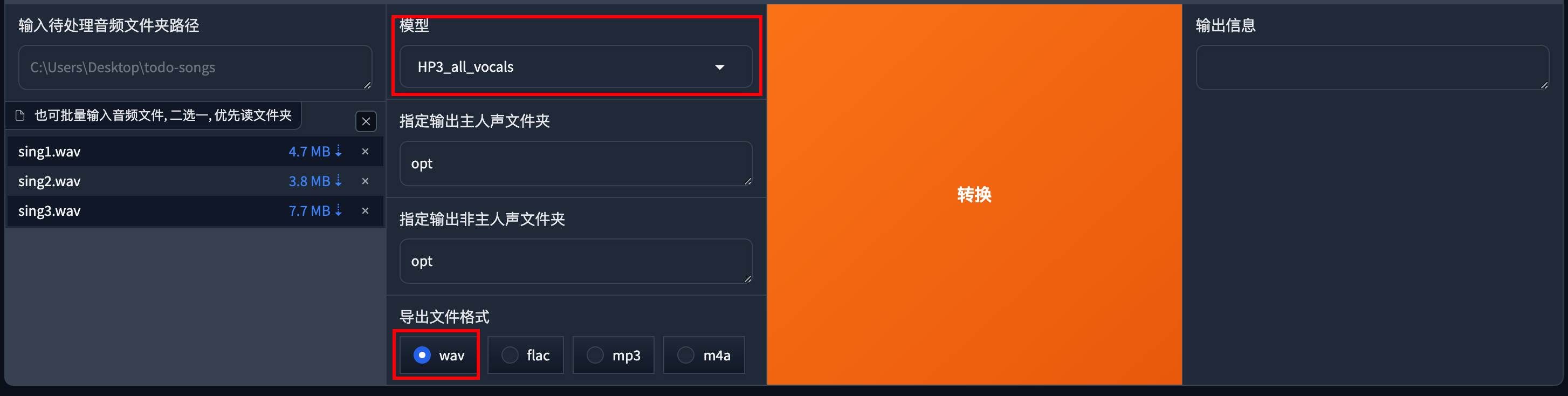
处理成功后可以看到项目根目录下的opt文件夹生成的音频。

instrument和vocal分别代表伴奏和人声的音频片段。
(最后的结果演示)
再根据上面的步骤将最后推理的音频也进行处理,可以听到我准备的音频有伴奏,我们需要把伴奏去掉。
(最后的结果演示)
训练
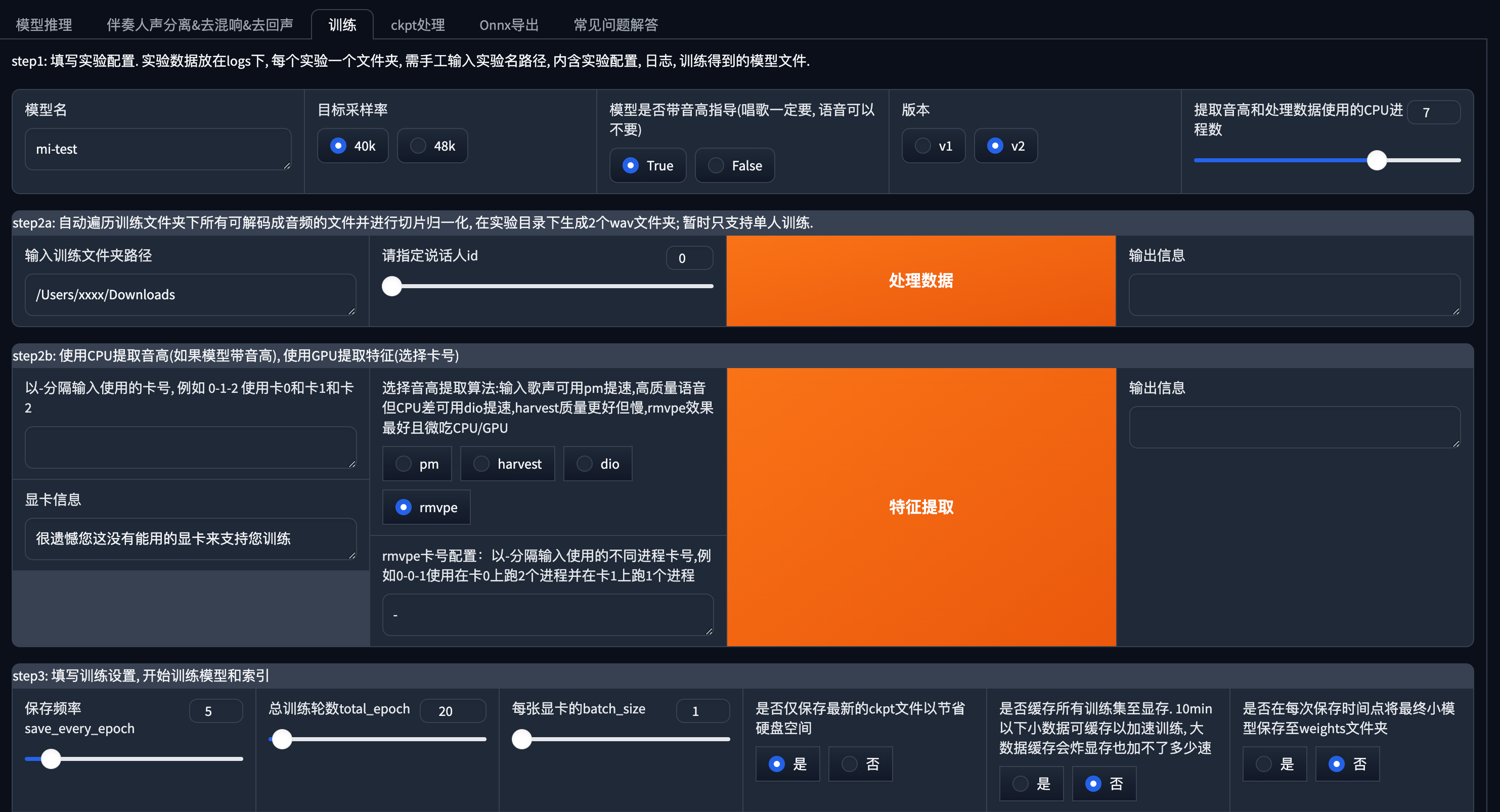
进入训练标签页。
填写配置

这栏填入你要训练的模型名字。(避免中文等特殊符号)其他选项保持默认。
数据处理

这里填入你要训练的音频素材文件夹的路径。
指定说话人id目前只支持单人,保持默认值0。
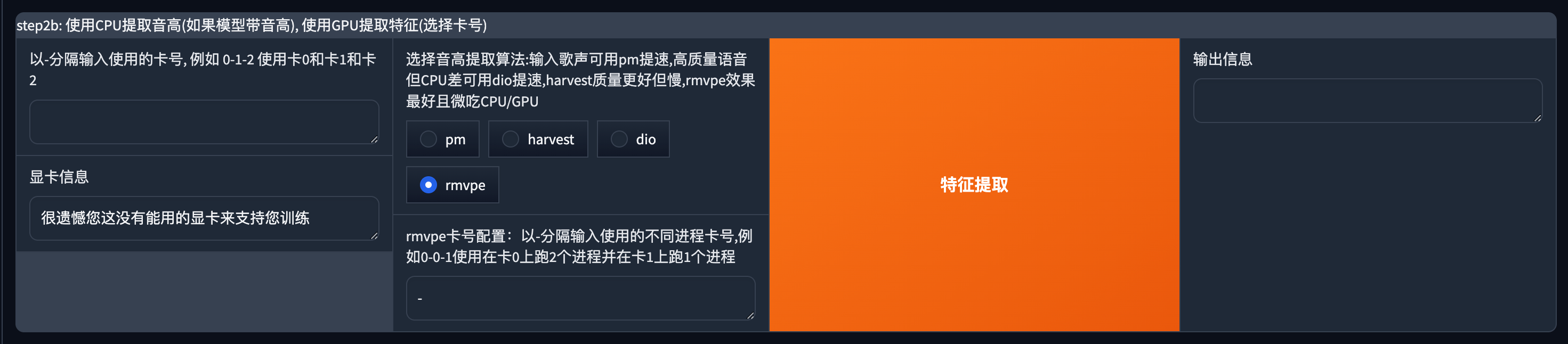
提取音高
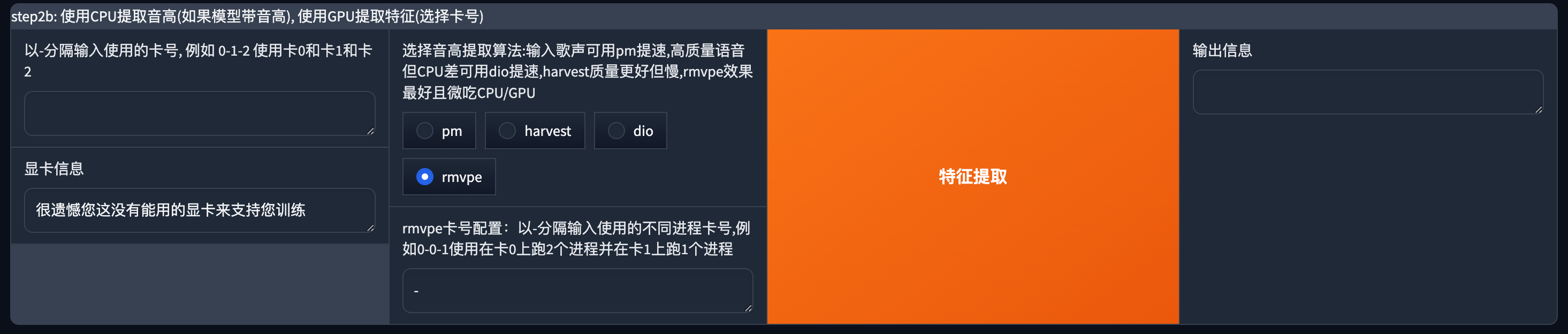
这一步MAC和Windows在界面上有点不一样,mac上不支持cuda,所以默认是rmvpe模型。
提示的显卡信息这里显示没有可用的显卡也不要担心,这在mac上是正常的。
MAC设置截图
Windows设置截图
训练设置
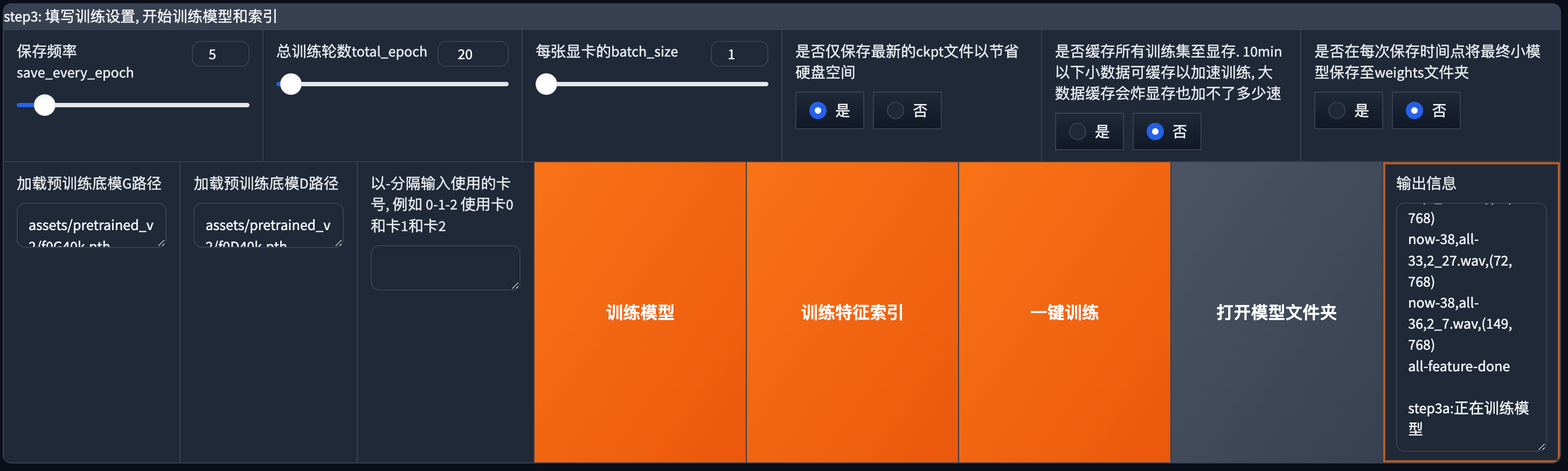
如果你是第一次使用RVC,这部分选项基本上保持默认即可,等你熟练了再来根据需求调节这里的选项,我会对这些参数做个简单的介绍。
保存频率:
模型在第几轮的时候进行保存,比如你总轮数是20,保存频率是5。那么一共会保存4次。
总训练轮数:
一共训练的总轮数。轮数越多,花费时间越长。
每张显卡的batch_size:
一次训练时的样本数量。batch_size越大,占用显存越多。较大的batch_size通常训练更快。根据硬件配置来。
是否仅保存最新的ckpt文件以节省硬盘空间:
开启后仅保存最新生成的模型,适合硬盘不是很大的小伙伴。
是否缓存所有训练集至显存:
开启后可以适当的提高速度,但是配置低的慎重开。
是否在每次保存时间点将最终小模型保存至weights文件夹:
开启后也会在对应的
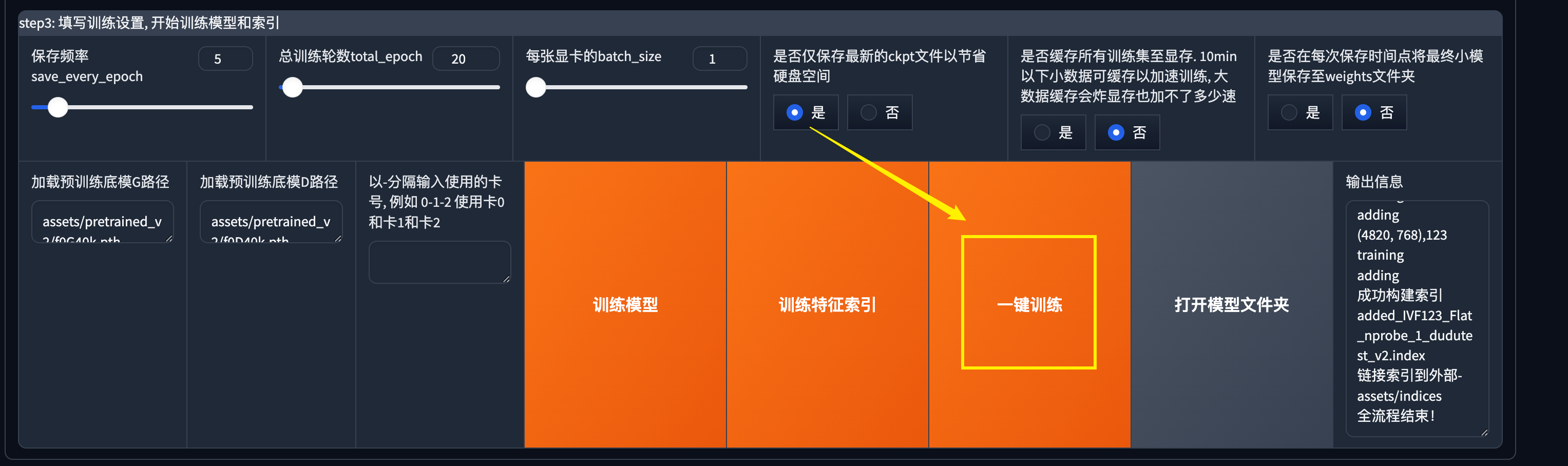
最后点击一键训练。
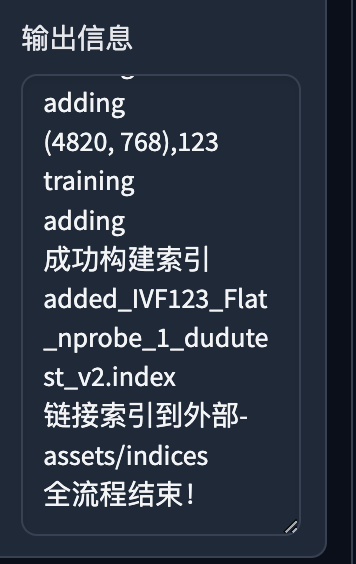
训练结束并成功,如果中间有报错,会在这个位置或启动器上显示错误信息。
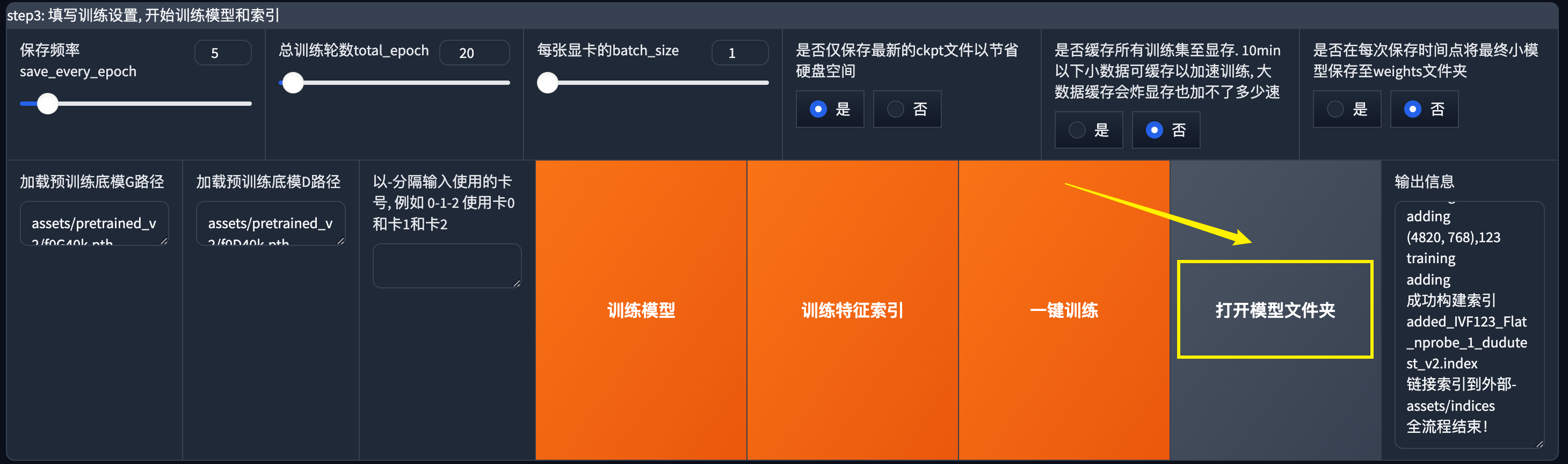
点击打开模型文件夹
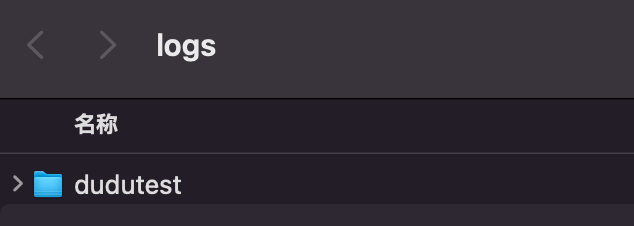
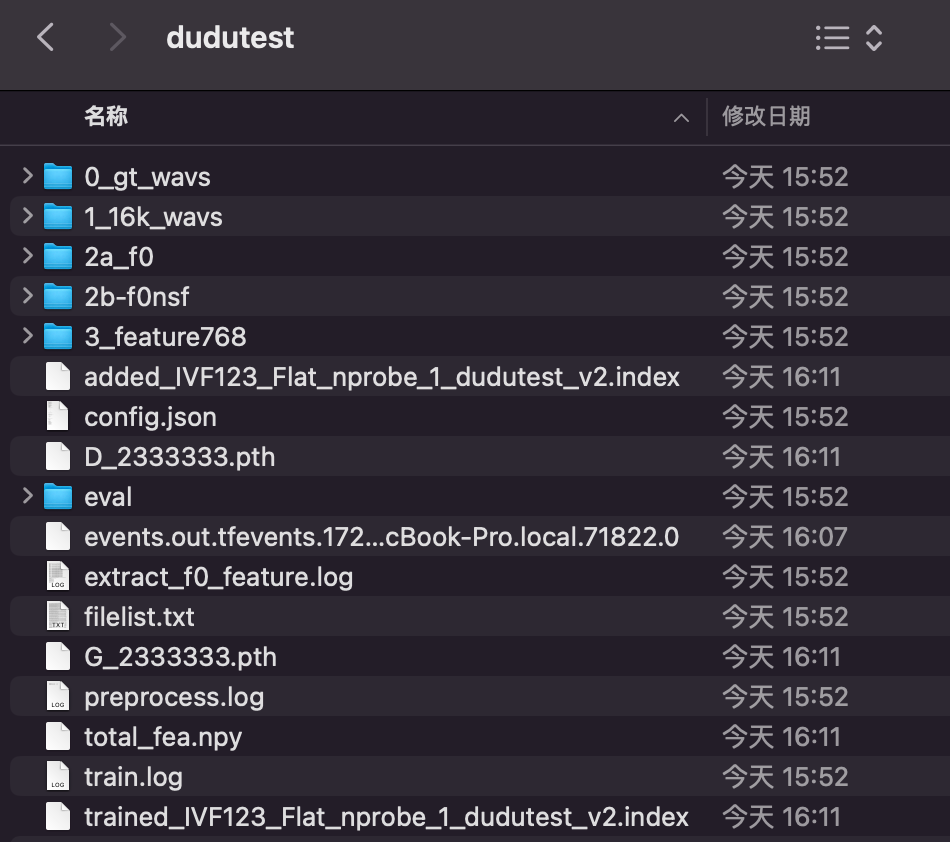
可以看到我们训练好的模型以及数据集。
推理

接下来进入推理界面

选择刚才训练好的模型,如果没有,可以点击刷新音色列表和索引路径选项
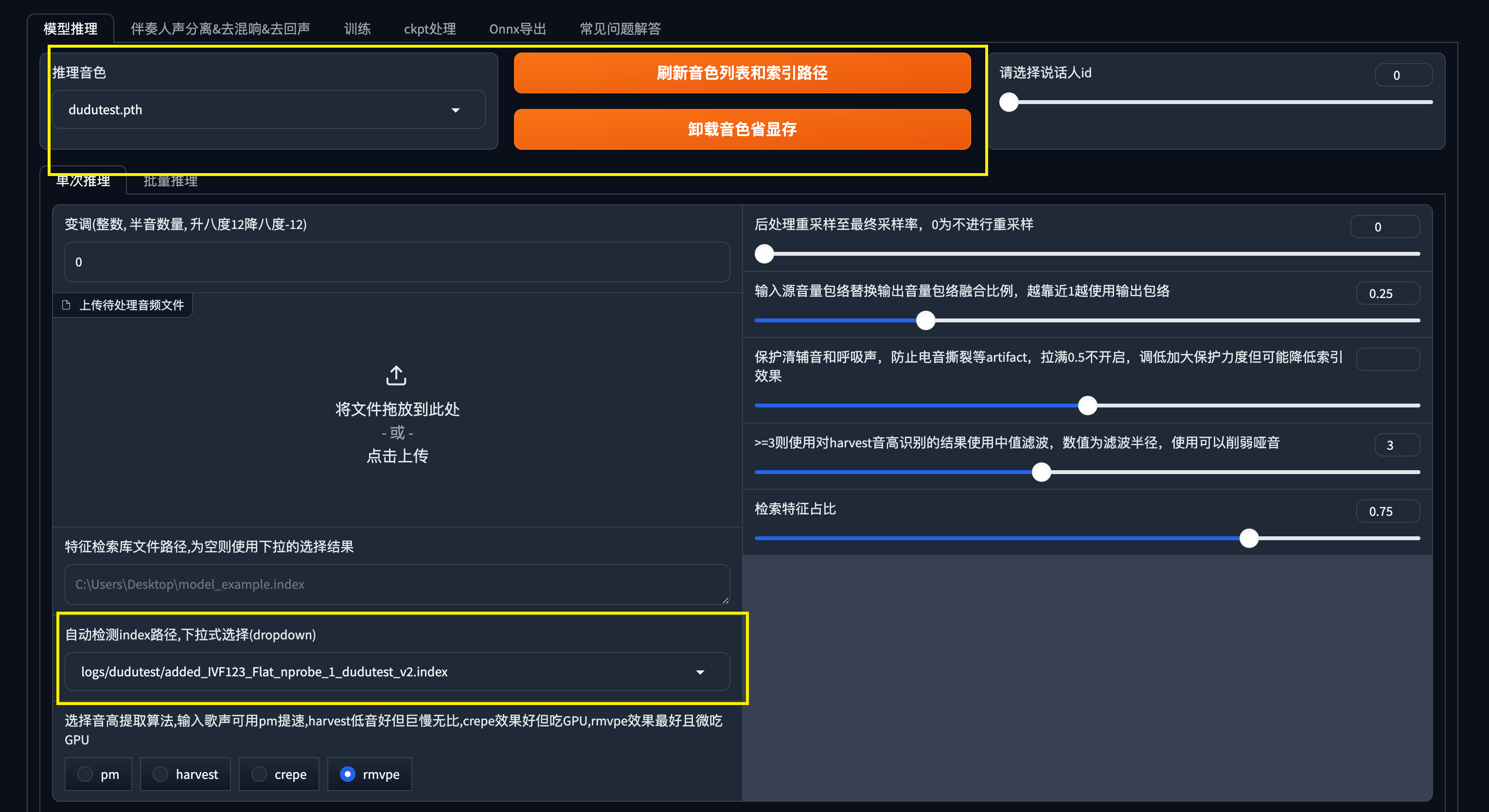
当出现卸载音色选项、并且下方index路径自动填充完成,意味着模型加载成功。
如果没有index路径,有可能模型训练时出现报错以及不完整的问题。
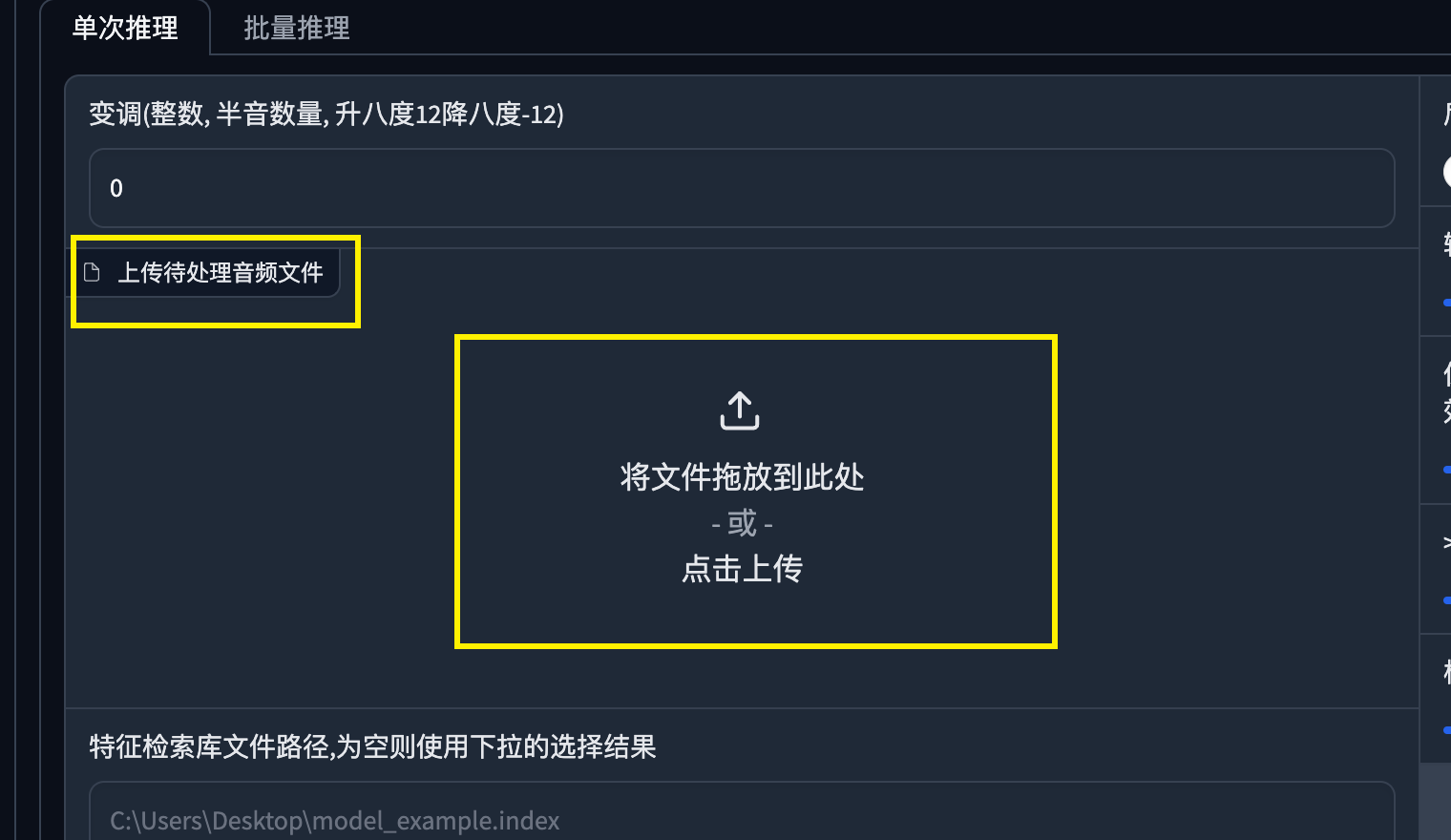
将最终要唱歌的音频拖拽进待处理音频文件中。

其他选项保持默认,点击转换
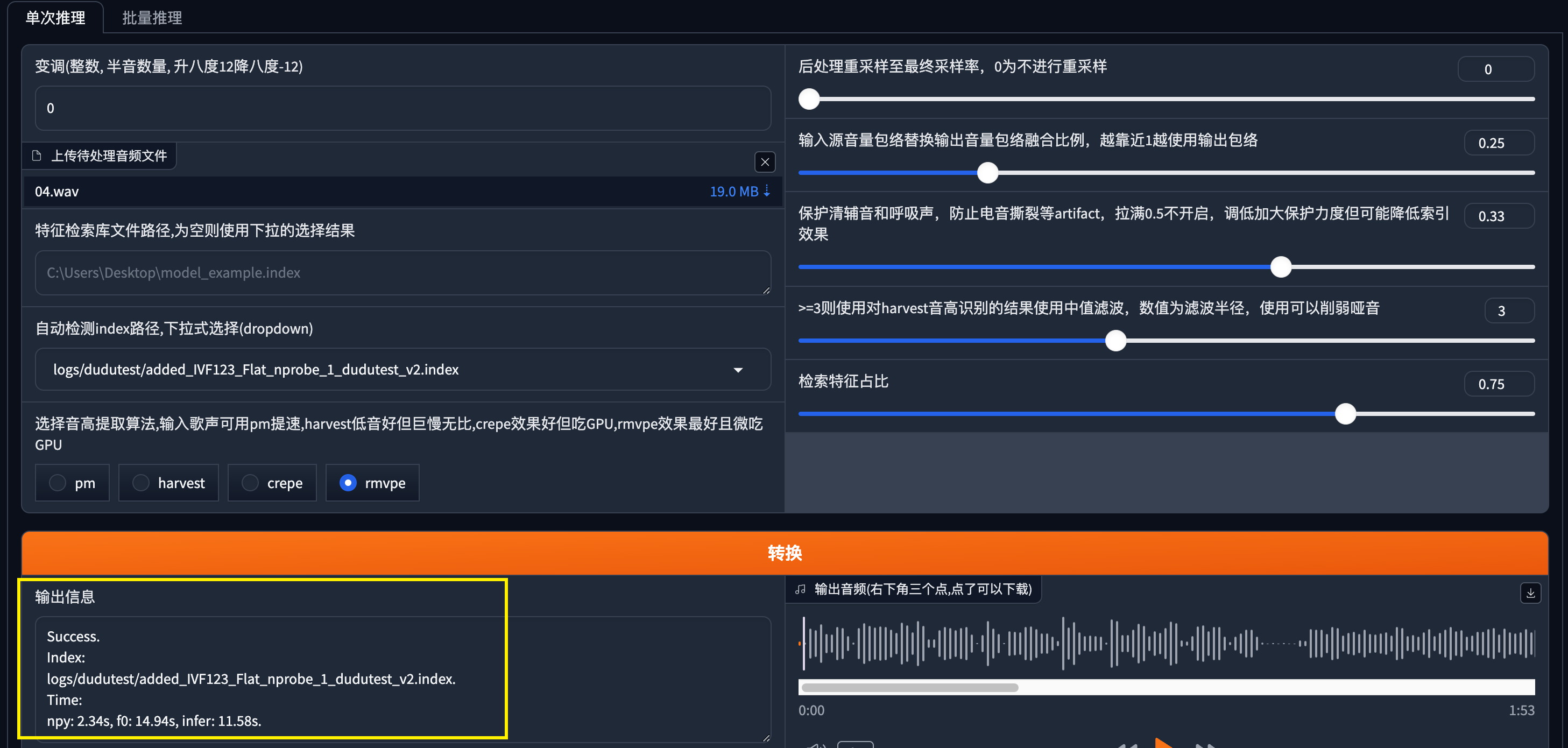
输出成功
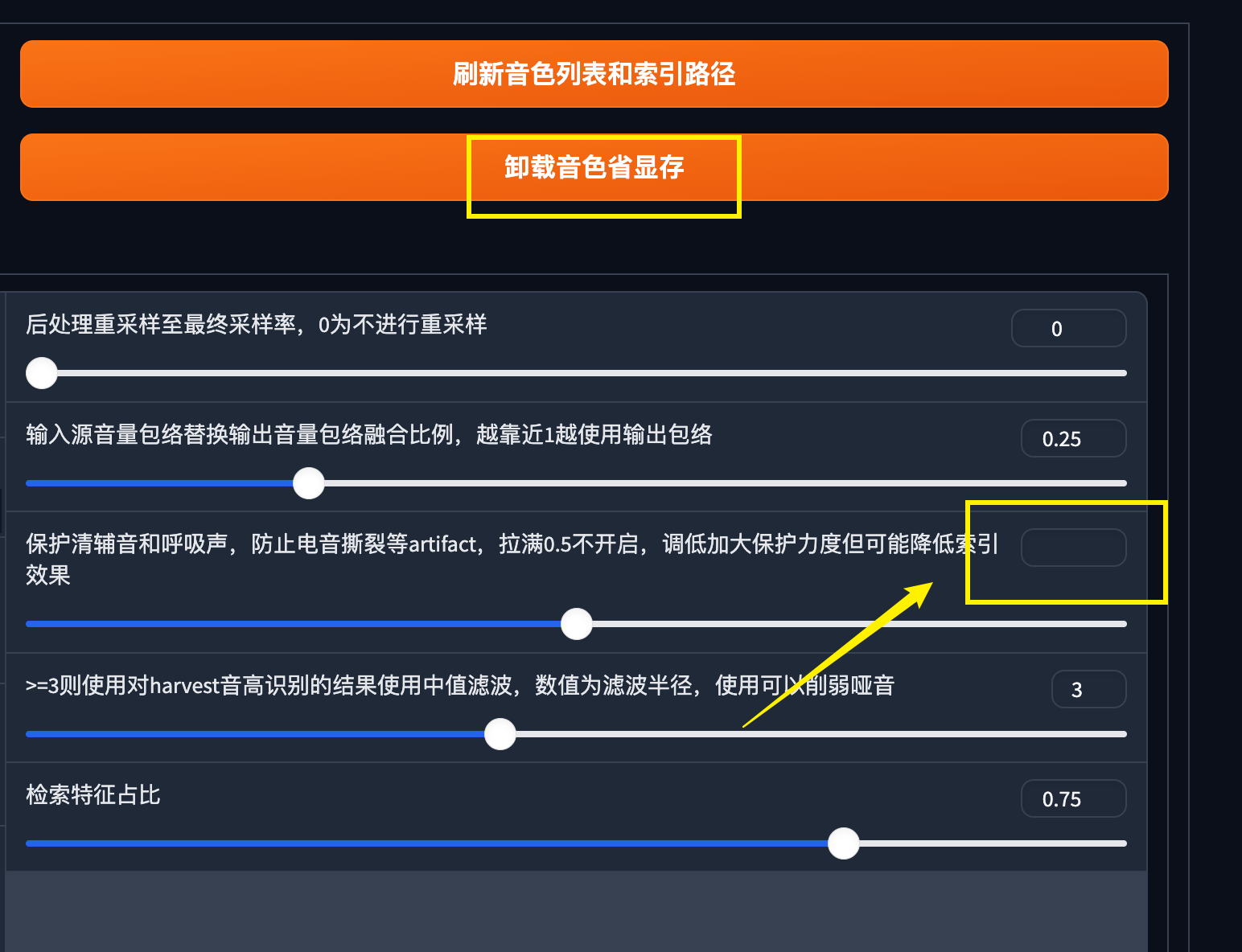
这里有个BUG需要注意,如果你中间点击卸载音色后,防电音的选项的数值会清空。这里一定要有数值,不然推理的时候必然会报错!!
(最终音频展示)
使用配置
Windows N卡8G及以上显存
支持Windows AMD/Intel GPU显卡版本
MAC Apple Silicon M1/M2/M3/M4 芯片
整合包获取
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻
关注公众号,发送【RVC】关键字获取整合包。
如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!
写到最后
为什么没视频教程?说实话,最近心情有点复杂。
前段时间不是没更新嘛,忙着开发项目去了,中间发现自己的视频被盗用了,(B站上盗B站的,YouTube上也盗用),要不是刘悦大佬提醒,我可能到现在都还不知道。真的特别感谢他!
其实做视频教程对我来说,只是单纯地想和大家分享如何更好的去用这些AI项目,希望能帮更多人少走弯路。每一个视频都倾注了很多心血,从选题、整理思路到熬夜录制...就是想着:"这样讲,大家应该更容易理解吧?"
看到视频被盗,说不难过是假的。但转念一想,这可能也说明内容还不错?

说心里话,最开心的时候就是看到留言区有人说:"原来是这样!我终于懂了!" 或者 "太感谢了,帮我解决了大问题!"
希望我们能一起创造一个互相尊重、共同进步的学习环境。毕竟在AI这个领域,能帮助别人的同时,自己也在不断成长,这种感觉真的很棒!
如果大家发现视频被盗用,麻烦告诉我一声。江湖路远,感谢有你们一路相伴。
后面我和我们团队的小伙伴还会继续更新更多实用的AI教程,(视频也会更的)咱们一起学习,一起进步!
最后感谢翅膀同学、白日制夢车间提供的音频素材。


















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









