







1、爬取分析
目标网站:
打开网站后,通过开发者工具分析数据是如何返回的,可以看到数据通过https://b2b.10086.cn/api-b2b/api-sync-es/common 这个页面以json的形式返回,并在页面加载呈现;
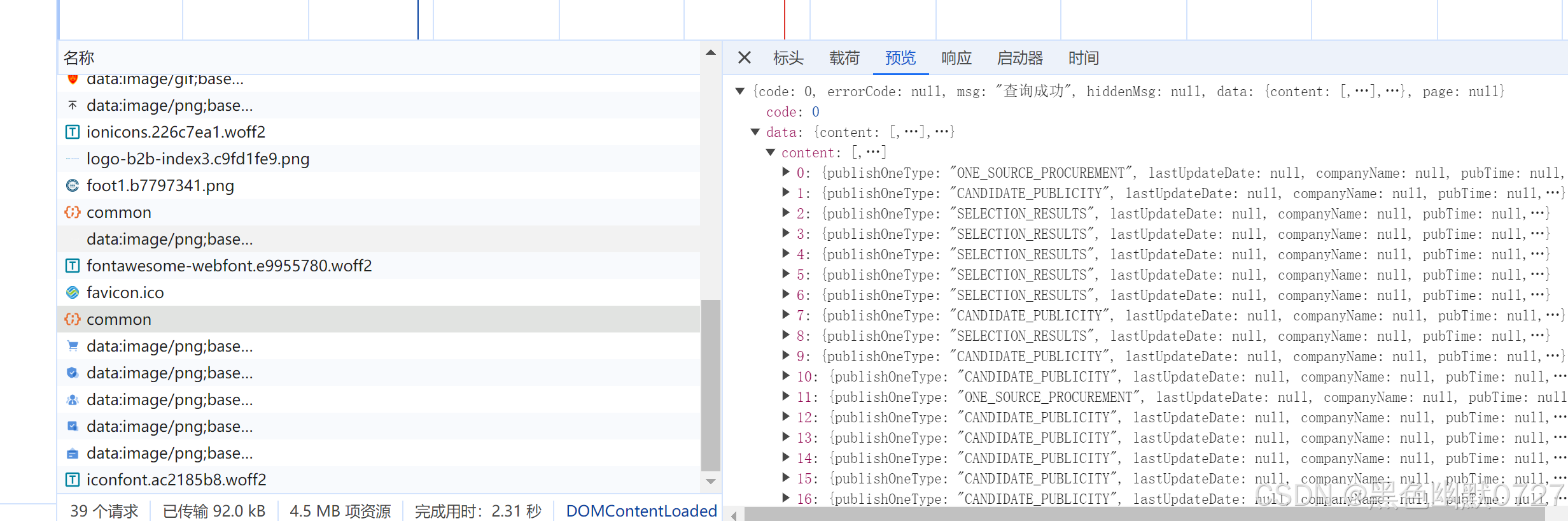
看下请求头的情况,发现未做cookie或其他加密混淆手段限制,遂分析能否通过request等爬虫方式获取内容;
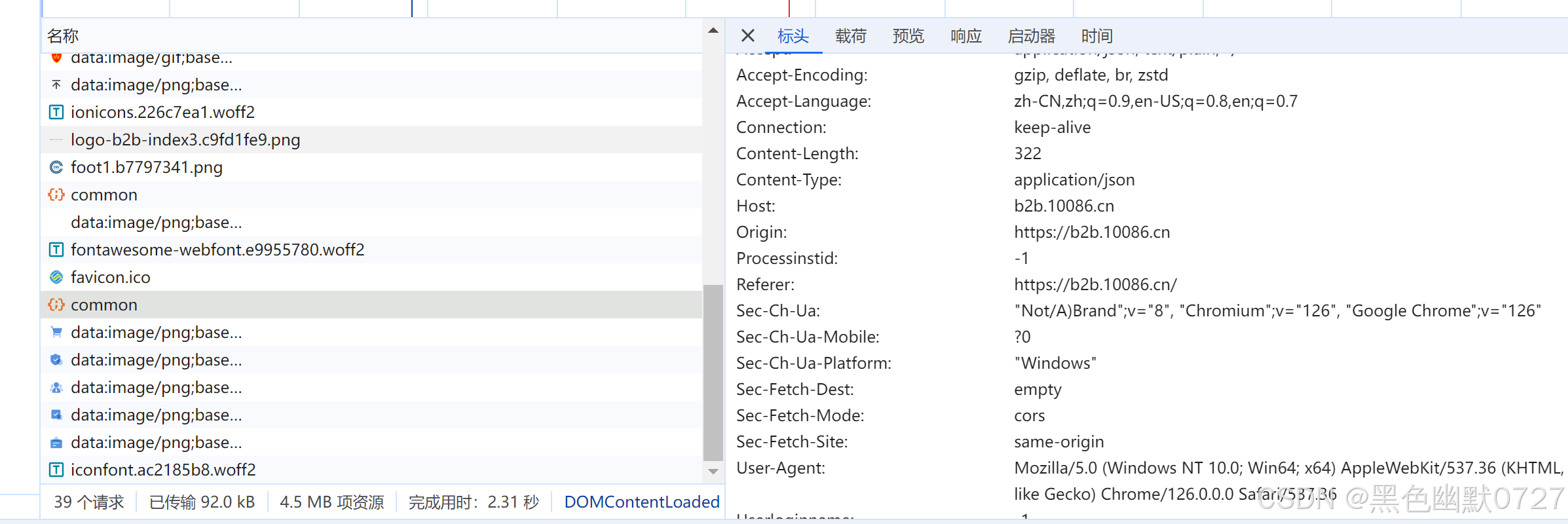
继续往下分析,看下请求的载荷情况,已经做了编码加密,无法得知明文结构,request方式不可行,所以考虑使用playwright有头方式请求,绕过该限制。
2、使用playwright尝试爬取获取标题和链接等信息
关于playwright的使用本文不做介绍,请自行搜索教程和说明
①尝试使用playwright看能否获取数据
from playwright.sync_api import sync_playwright
def cmUrls(playwright):
browser = playwright.chromium.launch(headless=False)
url = 'https://b2b.10086.cn/#/biddingProcurementBulletin'
context = browser.new_context()
page = context.new_page()
page.goto(url)
input('输入任意键继续:')
context.close()
browser.close()
with sync_playwright() as playwright:
cmUrls(playwright)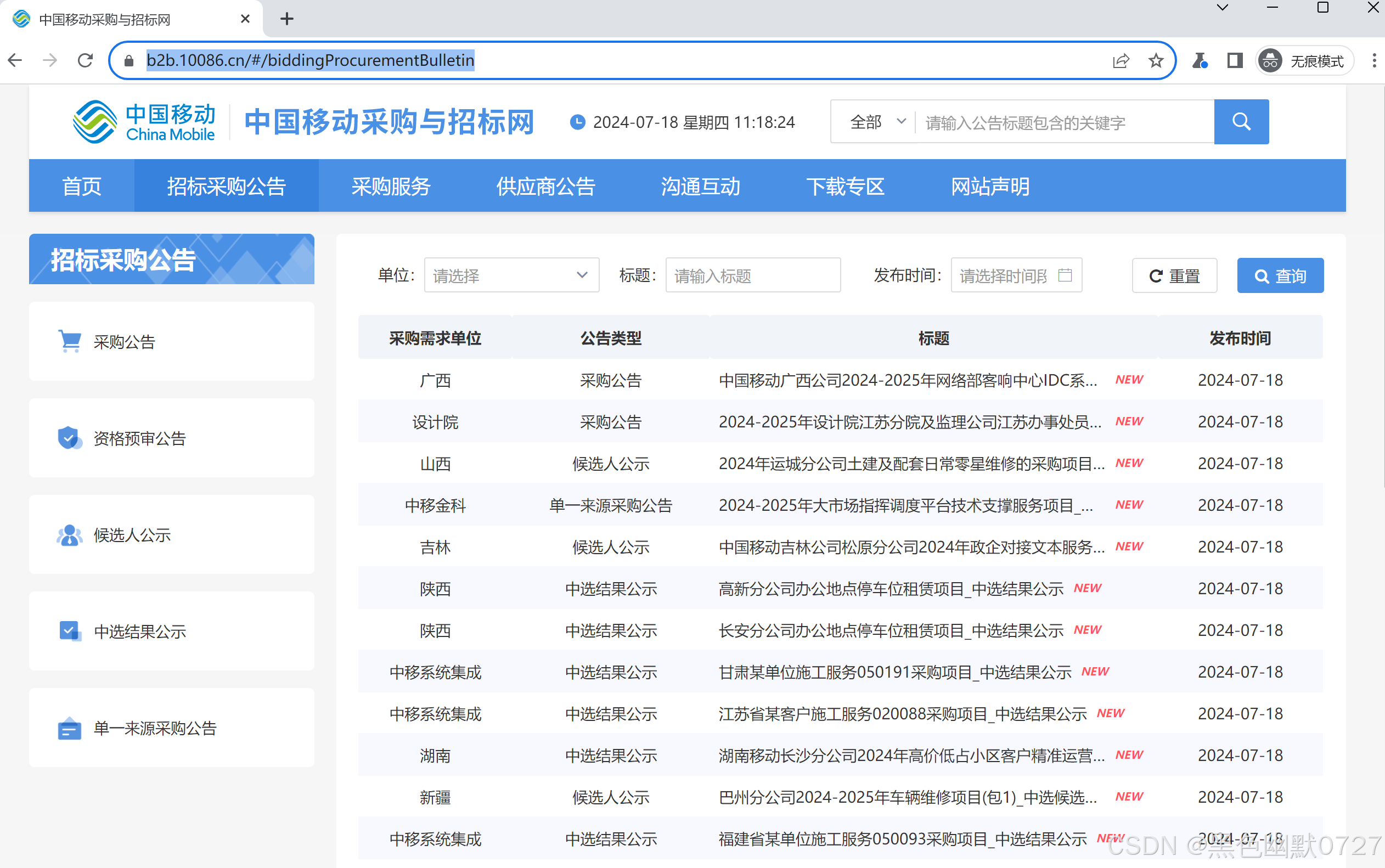
可以正常获取数据,那么下一步就是对数据处理,将数据取回即可。
②这里可以采用2种方式,一种是对页面数据直接处理,通过page.content()可以获取页面中的完整数据,再通过正则或其他方式将自己需要的数据提取出来,另一种是直接获取返回的json数据,减少数据抽取的难度。
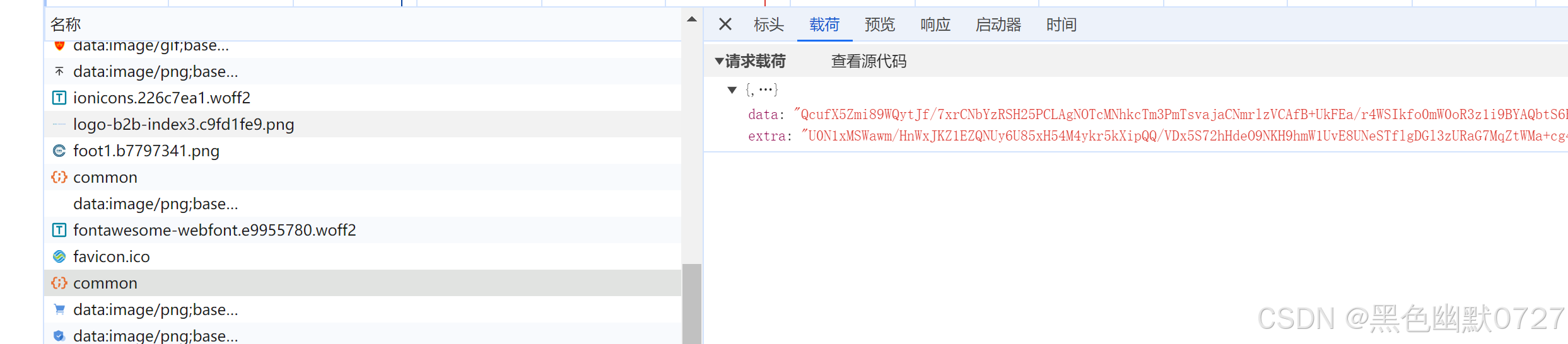
此处尝试使用expect_response方法获取https://b2b.10086.cn/api-b2b/api-sync-es/common返回的数据
with page.expect_response('https://b2b.10086.cn/api-b2b/api-sync-es/common') as jsonData:
page.goto(url)
print(jsonData.value.text())如图所示,数据已经正常获取

③下一步对返回的数据进行格式化处理。
import json
biddingList = []
def getUrlData(text):
data = json.loads(text)
content = data['data']['content']
for i in content:
publishOneType = i['publishOneType']
uuid = i['uuid']
id = i['id']
publishType = i['publishType']
url = 'https://b2b.10086.cn/#/noticeDetail?publishId={}&publishUuid={}&publishType={}&publishOneType={}'.format(id,uuid,publishType,publishOneType)
publishDate = i['publishDate'].split(' ')[0]
companyTypeName = i['companyTypeName']
name = i['name']
publishOneType_dictText = i['publishOneType_dictText']
biddingDict={
'companyTypeName':companyTypeName,
'publishOneType_dictText':publishOneType_dictText,
'name':name,
'publishDate':publishDate,
'url':url
}
biddingList.append(biddingDict)
return biddingList
使用了json库对返回的数据进行处理,获取了相关数据,并以字典+列表的方式存入数据。长期存储可采用数据库的方式,如mongodb,mysql等,此处不再展开,有兴趣可自行研究。
④目前只获取了当前页面数据,通过playwright的locator定位到翻页健,采用上述相同的方式,以expect_response获取翻页后的数据
for _ in list(range(1, 5)):#设置翻页数量
with page.expect_response('https://b2b.10086.cn/api-b2b/api-sync-es/common') as npJsonData:
page.locator(".cmcc-page-next").click()
biddingList=getUrlData(npJsonData.value.text())3、公告内容爬取
如果想要进一步获取标题页中的详细公告内容,可以对公告页面进行公告内容爬取
①上节已经通过爬虫获取每个标题页的链接,我们可以通过playwright访问标题页获取详细的公告内容,同样采用expect_response获取数据
from playwright.sync_api import sync_playwright
def cmPage(playwright):
browser = playwright.chromium.launch(headless=False)
url = 'https://b2b.10086.cn/#/noticeDetail?publishId=1813764404530753538&publishUuid=2bb8386608384562aef0b349f2ce9ddc&publishType=PROCUREMENT&publishOneType=SELECTION_RESULTS'
context = browser.new_context()
page = context.new_page()
with page.expect_response('https://b2b.10086.cn/api-b2b/api-sync-es/common') as pageJsonData:
page.goto(url)
print(pageJsonData.value.text())
context.close()
browser.close()
with sync_playwright() as playwright:
cmPage(playwright)
顺利获取公告内的详细内容。
②通过观察发现,公告页面内容有2种形式,一种是pdf,一种是html,如下图
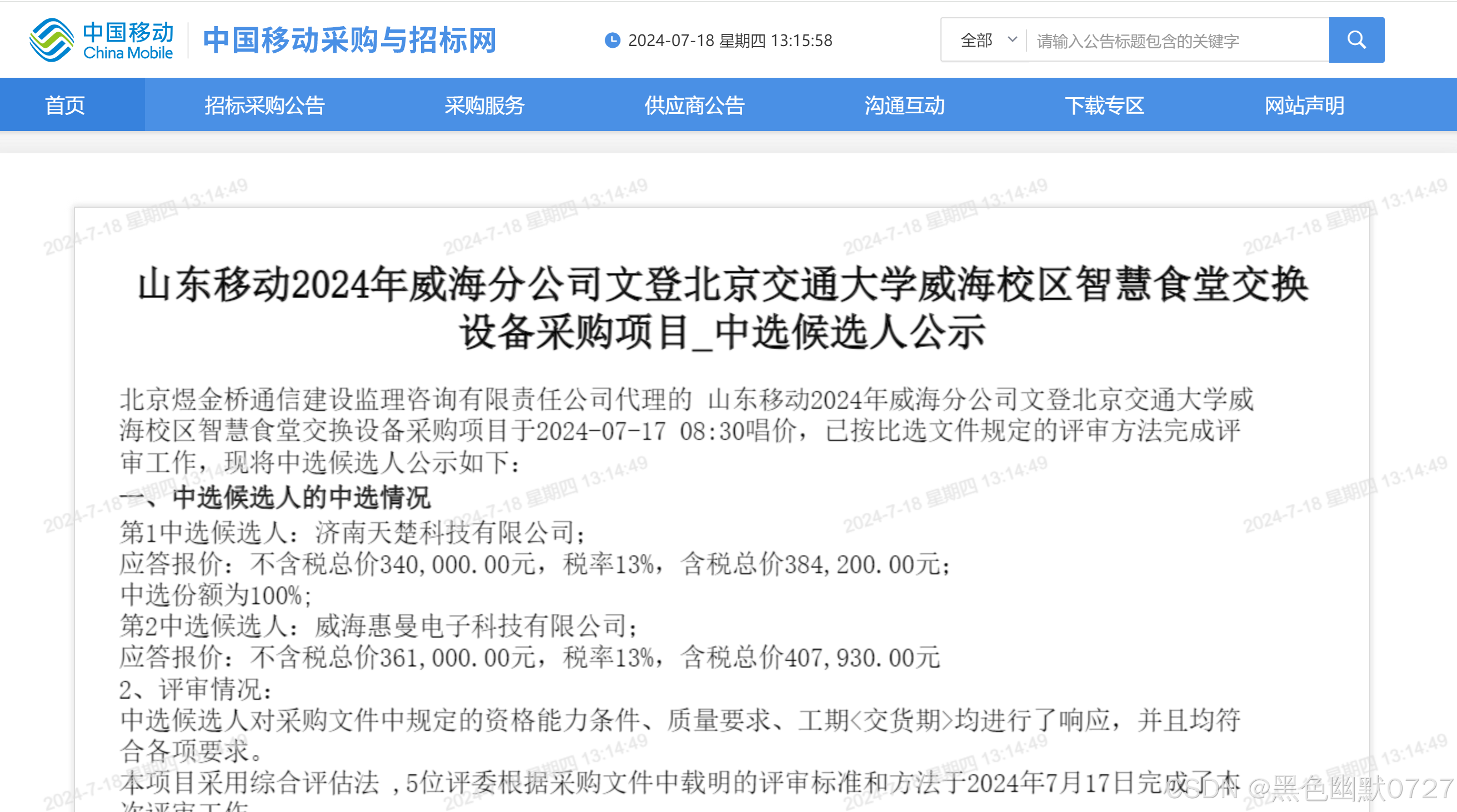
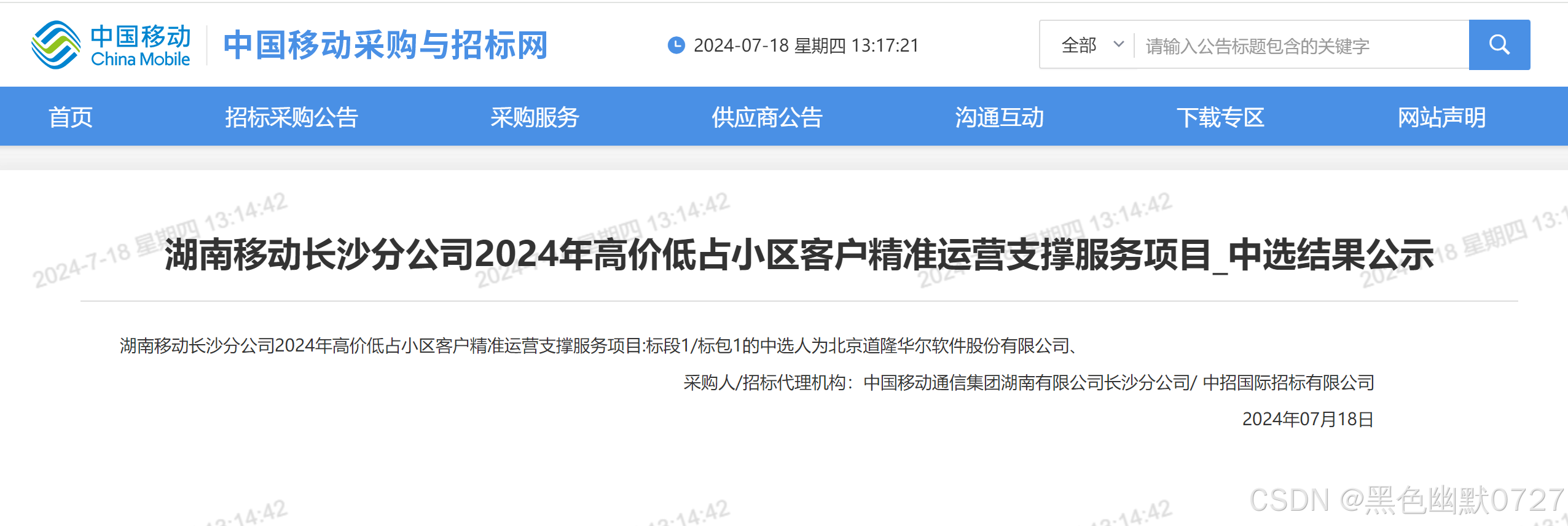
③所以对返回数据处理时,需要对2种不同的数据分别处理,html的数据采用BeautifulSoup方式处理,简单快捷,pdf的数据采用pdfminer.six处理。
import json
from bs4 import BeautifulSoup
from io import BytesIO
import base64
from pdfminer.high_level import extract_text
def getPageData(text):
data = json.loads(text)
contentType = data['data']['contentType']
noticeContent = data['data']['noticeContent']
if contentType == 'pdf':
pdf_file = BytesIO(base64.b64decode(noticeContent))
content = extract_text(pdf_file)
else:
soup = BeautifulSoup(noticeContent, 'html.parser')
content = soup.get_text(strip=True)
return content

两种类型数据都顺利提取了公告详细内容。
4、完整代码
对上述爬取公告标题、链接和公告页详细内容的代码做个结合,下述代码仅供参考学习。本文未使用并发或其他更加高效的方式,可自行研究修改。
有问题可留言。
本文可转载,请注明出处,谢谢。
#coding:utf-8
import time
from playwright.sync_api import sync_playwright
import json
from bs4 import BeautifulSoup
from io import BytesIO
import base64
from pdfminer.high_level import extract_text
biddingList = []
# 获取公告标题链接等信息
def getUrlData(text):
data = json.loads(text)
content = data['data']['content']
for i in content:
publishOneType = i['publishOneType']
uuid = i['uuid']
id = i['id']
publishType = i['publishType']
url = 'https://b2b.10086.cn/#/noticeDetail?publishId={}&publishUuid={}&publishType={}&publishOneType={}'.format(id,uuid,publishType,publishOneType)
publishDate = i['publishDate'].split(' ')[0]
companyTypeName = i['companyTypeName']
name = i['name']
publishOneType_dictText = i['publishOneType_dictText']
biddingDict={
'companyTypeName':companyTypeName,
'publishOneType_dictText':publishOneType_dictText,
'name':name,
'publishDate':publishDate,
'url':url
}
biddingList.append(biddingDict)
return biddingList
#获取公告页面的详细内容
def getPageData(text):
data = json.loads(text)
contentType = data['data']['contentType']
noticeContent = data['data']['noticeContent']
if contentType == 'pdf':
pdf_file = BytesIO(base64.b64decode(noticeContent))
content = extract_text(pdf_file)
else:
soup = BeautifulSoup(noticeContent, 'html.parser')
content = soup.get_text(strip=True)
return content
def cmUrls(playwright):
browser = playwright.chromium.launch(headless=False)
url = 'https://b2b.10086.cn/#/biddingProcurementBulletin'
context = browser.new_context()
page = context.new_page()
with page.expect_response('https://b2b.10086.cn/api-b2b/api-sync-es/common') as jsonData:
page.goto(url)
biddingList=getUrlData(jsonData.value.text())
time.sleep(1)
for _ in list(range(1, 5)):#设置翻页数量
with page.expect_response('https://b2b.10086.cn/api-b2b/api-sync-es/common') as npJsonData:
page.locator(".cmcc-page-next").click()
biddingList=getUrlData(npJsonData.value.text())
time.sleep(1)
for i in biddingList:
page1 = context.new_page()
with page1.expect_response('https://b2b.10086.cn/api-b2b/api-sync-es/common') as pagejsonData:
page1.goto(i['url'])
content = getPageData(pagejsonData.value.text())
i['content'] = content
page1.close()
print(i['companyTypeName'],i['publishOneType_dictText'],i['name'],i['publishDate'],i['content'])
time.sleep(1)
context.close()
browser.close()
with sync_playwright() as playwright:
cmUrls(playwright)5、补充
7月22日更新
今天发现返回json数据的地址发生了变化,上述代码无法执行,请根据开发者工具分析,自行更改expect_response监控数据返回的地址。
当前地址更新情况如下:
链接信息变更为
https://b2b.10086.cn/api-b2b/api-sync-es/white_list_api/b2b/publish/queryList
公告明细变更为
https://b2b.10086.cn/api-b2b/api-sync-es/white_list_api/b2b/publish/queryDetail

















 2212
2212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









