







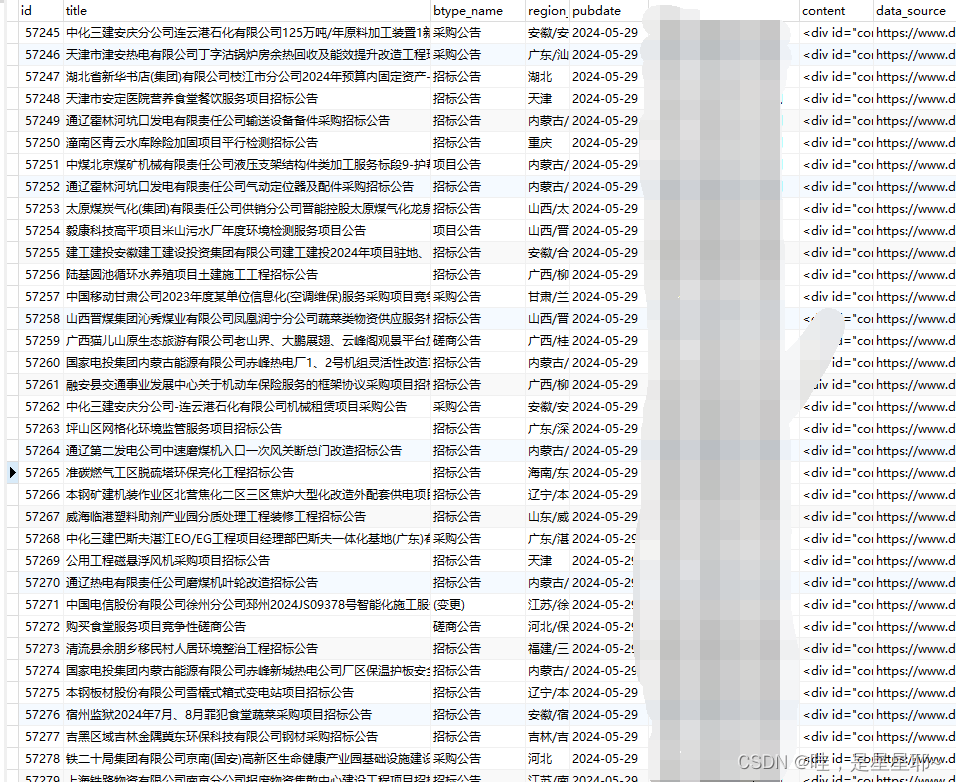
爬取中国国际招标网(https://zggj.zbytb.com/搜索-中国招标与采购网https://zggj.zbytb.com/),并将爬取的数据存储到数据库中,效果图如下:
1、建立数据库和表
数据表——zhaobiao

这里的字段看自己所需。
2、分析中国国际招标网网页
我们大概需要的数据是标题、公告类型、发布时间、省份、公告内容等,所以这里当我们进入网页的第一页时,需要获取分页链接以及公告内容的链接。
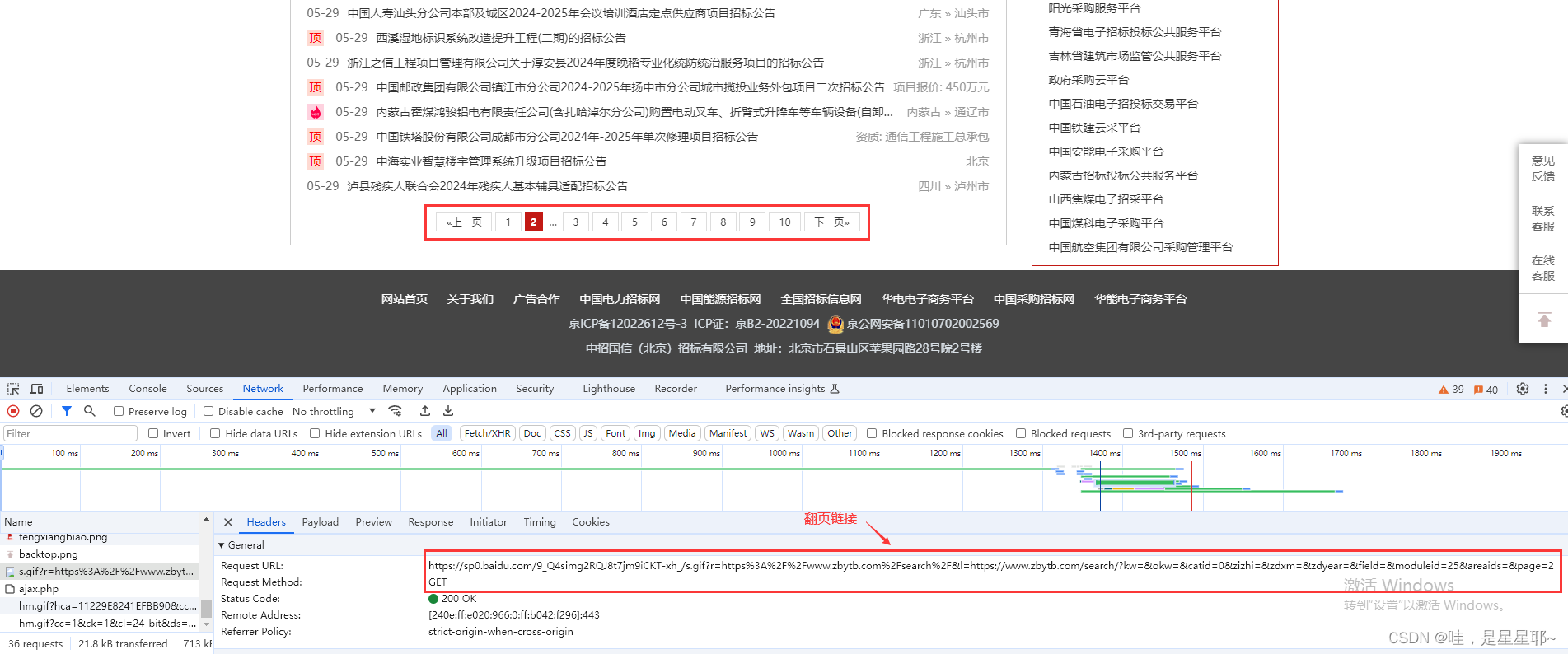
① 翻页:
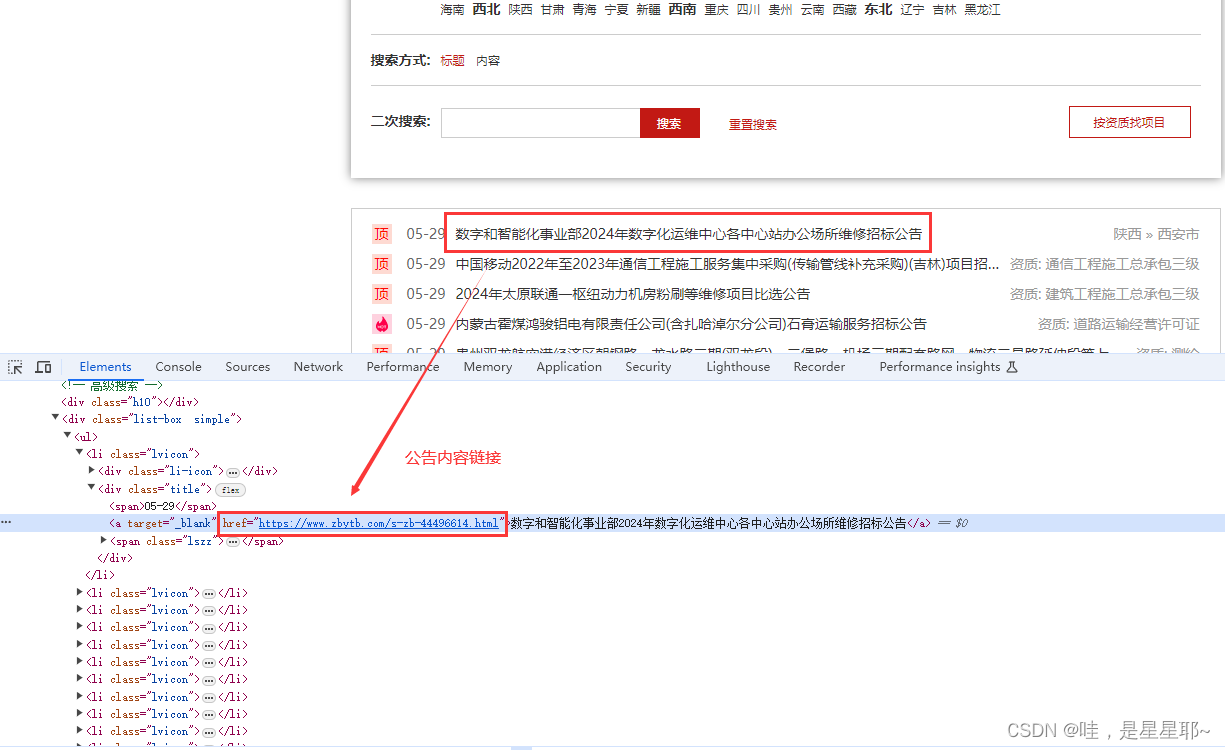
② 公告内容:
3、代码编写
① 连接数据库
下面用户密码等填自己的。
import pymysql
db = pymysql.connect(host='', # 连接名称
user='', # 用户名称
password='', # 密码
database='') # 数据库名称
print('数据库连接成功')
cursor = db.cursor()② 分析搜索-中国招标与采购网页面
获取总页数,注意是post还是get请求,这里是post请求
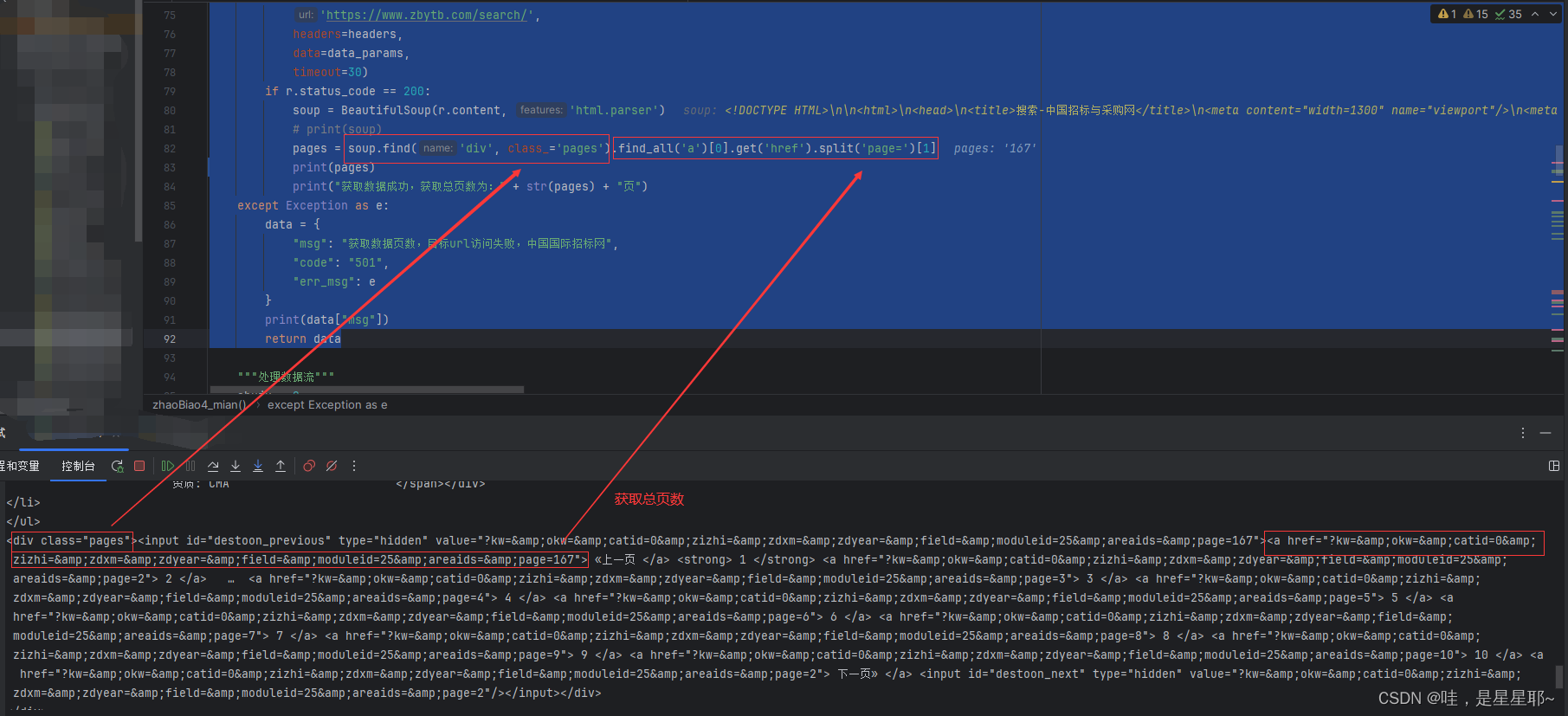
try:
print("中国国际招标网,正在获取数据列表")
r = requests.post(
'https://www.zbytb.com/search/',
headers=headers,
data=data_params,
timeout=30)
if r.status_code == 200:
soup = BeautifulSoup(r.content, 'html.parser')
# print(soup)
pages = soup.find('div', class_='pages').find_all('a')[0].get('href').split('page=')[1]
print(pages)
print("获取数据成功,获取总页数为:" + str(pages) + "页")
except Exception as e:
data = {
"msg": "获取数据页数,目标url访问失败,中国国际招标网",
"code": "501",
"err_msg": e
}
print(data["msg"])
return data获取每一条招标信息,这里就是get请求
r = requests.get(
f'https://www.zbytb.com/search/?kw=&okw=&catid=0&zizhi=&zdxm=&zdyear=&field=&moduleid=25&areaids=&page={page}',
headers=headers,
timeout=60)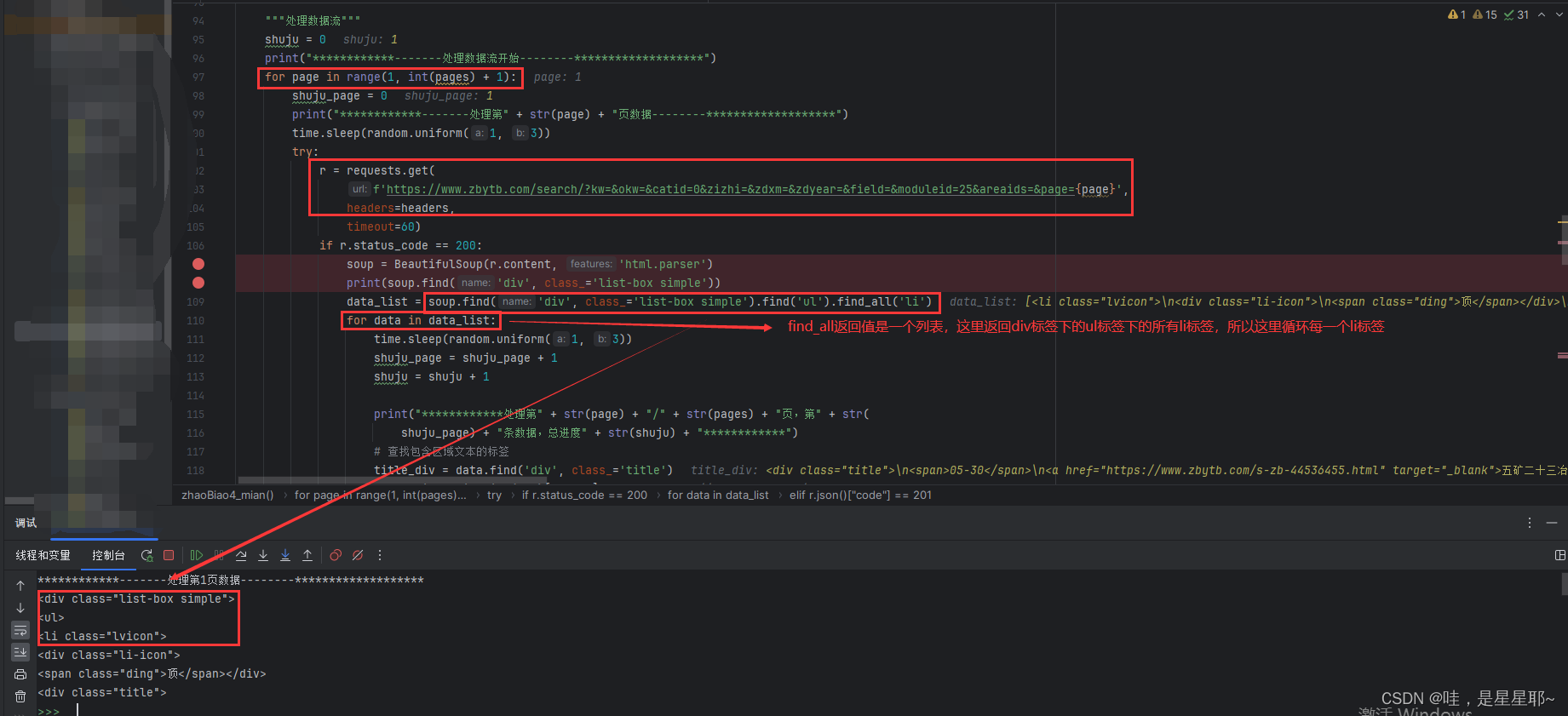
提取招标标题,时间,公告类型,每一条招标信息的详细页面的url以及省份
提取每一条招标信息的详细页面
content_r = requests.get(url, headers=headers, timeout=500, verify=False)③ 插入数据库中
"""上传至数据库中"""
sql = ('insert into zhaobiao(title,btype_name,pubdate,content,data_source,region_name) '
'VALUES(%s, %s, %s, %s, %s, %s)')
try:
cursor.execute("SELECT * FROM zhaobiao WHERE data_source = %s", (url,))
existing_user = cursor.fetchone()
if not existing_user: # 如果不存在重复记录才执行插入操作
cursor.execute(sql, (
Title, BTypeName, PubDate, detail, url, RegionName))
db.commit()
else:
print(f"{url} 已存在,不进行插入操作")
except Exception as e:
db.rollback()
print(e)4、代码
import random
import time
import requests
from bs4 import BeautifulSoup
import urllib3
def zhaoBiao4_mian():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Referer": "https://www.google.com",
"Connection": "keep-alive",
"Cookie": cookies # cookie需要自行加
}
data_params = {
"moduleid": 25,
"areaids": "",
"exareaid": "",
"field": "",
"okw": "",
"obiao": 0,
"zizhi": "",
"search": 1,
"kw": "",
}
try:
r = requests.post(
'https://www.zbytb.com/search/',
headers=headers,
data=data_params,
timeout=30)
if r.status_code == 200:
soup = BeautifulSoup(r.content, 'html.parser')
pages = soup.find('div', class_='pages').find_all('a')[0].get('href').split('page=')[1]
except Exception as e:
data = {
"msg": "获取数据页数,目标url访问失败",
"code": "501",
"err_msg": e
}
print(data["msg"])
return data
"""处理数据流"""
shuju = 0
for page in range(1, int(pages) + 1):
shuju_page = 0
time.sleep(random.uniform(1, 3))
try:
r = requests.get(
f'https://www.zbytb.com/search/?kw=&okw=&catid=0&zizhi=&zdxm=&zdyear=&field=&moduleid=25&areaids=&page={page}',
headers=headers,
timeout=60)
if r.status_code == 200:
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.find('div', class_='list-box simple'))
data_list = soup.find('div', class_='list-box simple').find('ul').find_all('li')
for data in data_list:
time.sleep(random.uniform(1, 3))
shuju_page = shuju_page + 1
shuju = shuju + 1
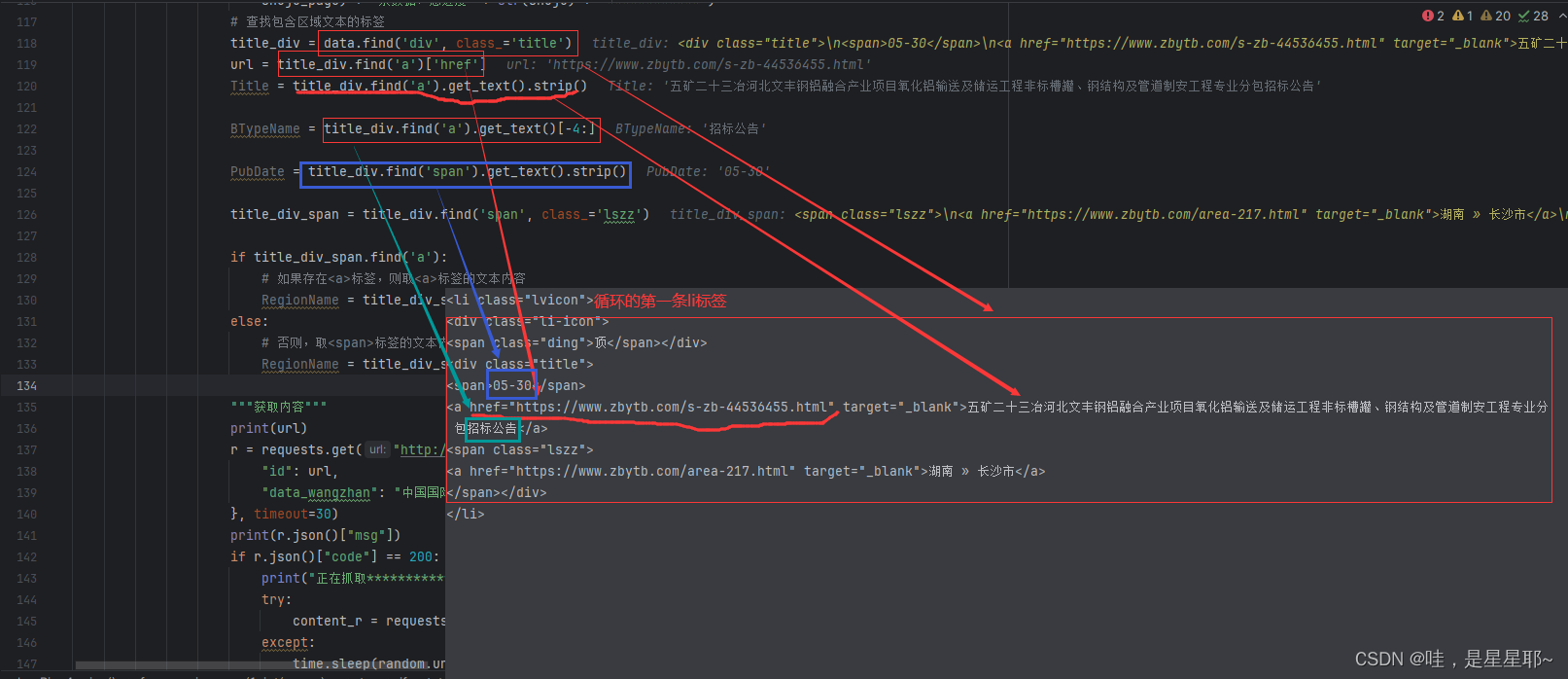
title_div = data.find('div', class_='title')
url = title_div.find('a')['href']
Title = title_div.find('a').get_text().strip()
BTypeName = title_div.find('a').get_text()[-4:]
PubDate = title_div.find('span').get_text().strip()
title_div_span = title_div.find('span', class_='lszz')
if title_div_span.find('a'):
# 如果存在<a>标签,则取<a>标签的文本内容
RegionName = title_div_span.find('a').get_text().replace(' » ', '')
else:
# 否则,取<span>标签的文本内容
RegionName = title_div_span.get_text()
"""获取内容"""
print(url)
print("正在抓取****************")
try:
content_r = requests.get(url, headers=headers, timeout=500, verify=False)
except:
time.sleep(random.uniform(1, 3))
content_r = requests.get(url, headers=headers, timeout=500, verify=False)
if content_r.status_code == 200:
soup1 = BeautifulSoup(content_r.content, "html.parser", from_encoding="gb18030")
detail = soup1.find("div", id="content")
data_updata["Content_text"] = str(detail)
"""上传至数据库中"""
sql = ('insert into zhaobiao(title,btype_name,pubdate,content,data_source,region_name) '
'VALUES(%s, %s, %s, %s, %s, %s)')
try:
cursor.execute("SELECT * FROM zhaobiao WHERE data_source = %s", (url,))
existing_user = cursor.fetchone()
if not existing_user: # 如果不存在重复记录才执行插入操作
cursor.execute(sql, (
Title, BTypeName, PubDate, detail, url, RegionName))
db.commit()
else:
print(f"{url} 已存在,不进行插入操作")
except Exception as e:
db.rollback()
print(e)
else:
data = {
"msg": "获取详细数据,目标url访问失败,中国国际招标网",
"code": "503",
"err_msg": r.json()
}
return data
except Exception as e:
data = {
"code": 502,
"msg": "中国国际招标网,单个数据抓取失败?????????????????????????????",
"err_msg": e
}
print(data["msg"])
return data
if __name__ == '__main__':
data_msg = zhaoBiao4_mian() # 中国国际招标网本教程仅供教学使用,严禁用于商业用途!

















 2764
2764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









