







TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution) 法,又称为优劣解距离法。根据有限个评价对象与理想化目标的接近程度进行排序,是在现有的对象中进行相对优劣的评价。TOPSIS法是一种逼近于理想解的排序法,该方法只要求解具有单调递增(或递减)性。
·
针对解决层次分析法中的2个问题:
(1)评价的决策层不能太多;(2)决策层中指标的数据是已知的。
一、原理
1.理论
通过检测评价对象与最优解、最劣解的距离来进行排序。若评价对象最靠近最优解同时又最远离最劣解,则为最好;否则不为最优。
其中最优解的各指标值都达到各评价指标的最优值。最劣解的各指标值都达到各评价指标的最差值。
2.适用范围
(1) 比较的对象一般要远大于两个。(例如比较一个班级的成绩)
(2) 比较的指标也往往不只是一个方面的,例如成绩、工时数、课外竞赛得分等。
(3) 有很多指标不存在理论上的最大值和最小值,例如衡量经济增长水平的指标: GDP增速。
二、步骤
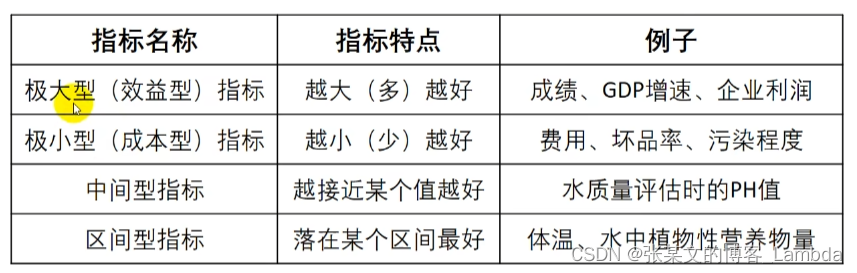
1.确定数据类型
- 极大型指标(效益类指标):指标数值越大越好。
- 极小型指标(成本类指标):指标数值越小越好。
- 中间型指标:指标数值越接近某个值越好。
- 区间型指标:指标数值在某个区间范围内最好,区间中的数值大小无优劣之分。
2.统一指标类型
- 极小型指标转化为极大型指标:
将所有的指标转化为极大型称为指标正向化(最常用)。

- 中间型指标转化为极大型指标:

- 区间型指标转化为极大型指标:

3.标准化处理
为了消去不同指标量纲的影响,需要对已经正向化的矩阵进行标准化处理。

4.计算得分
(1)当只有一个指标的时候:

(2)当有m个指标的时候:

三、解题举例
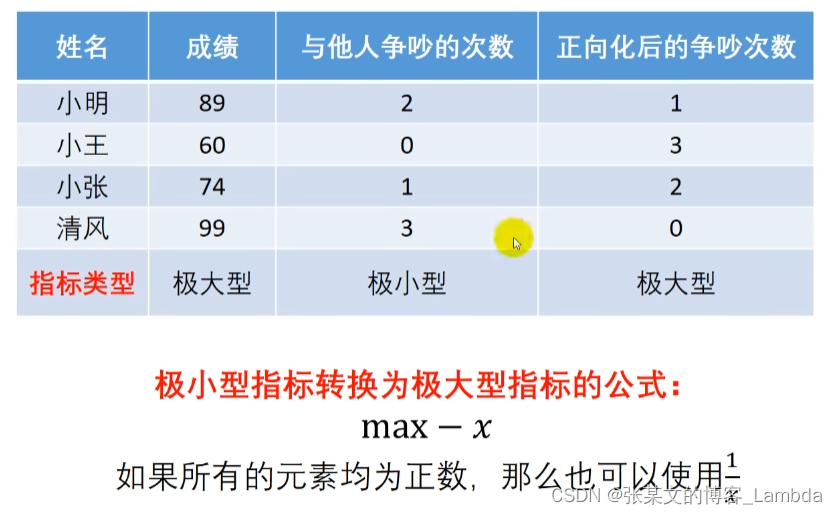
1.将原始矩阵正向化
所谓的将原式矩阵正向化,就是要将所有的指标类型统一转化为极大型指标。(转换的函数形式可以不唯一)
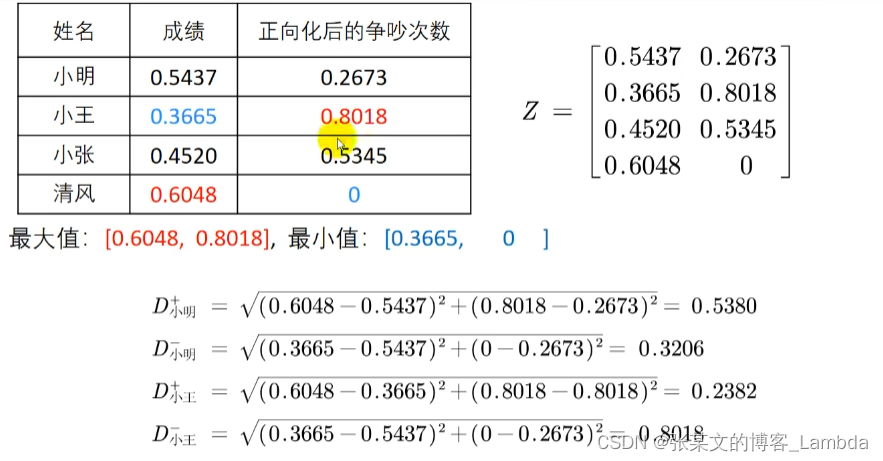
2.计算得分
(1)等权重情况
通过寻找各个指标的最大值和最小值,比如在成绩中,最小的值是0.3665最大是0.6048。联合这些不同的指标,我们就能构建一个多维的最大值的指标{0.6048, 0.8018} 和多维的最小值的点{0.0.3665, 0.00},这两个集合分别被称为最优方案、最劣方案。
到最优解的距离记为D+,到最劣解的距离记为D-,形成最终的评价指标C计算公式为:
C = (D-) / (D+)+(D-)
其中C越接近于1,就说明这个更优。
最后根据C从大到小的顺序,评价各个参选人的优劣。最终排名结果:

(2)非等权重情况
我们发现,按照如上方法计算距离的时,是假定各个因素没有重要性之分,然而实际上并不可能,因此需要我们加入权重。
① AHP
具体适用AHP方法计算权重的代码及思想如上节所讲:超链接。
② 熵权法
具体方法计算权重的代码及思想如下节所讲:超链接
第一步:矩阵是经过了正向化和归一化之后的矩阵,如果之后矩阵中还存在负数,则需要再次归一化。比如说用值减去指标的最小值,再除以指标最大值和最小值的差。以保证所有的权重都是正数。
第二步:计算熵值。n是个数,这里为5。

其中p值的计算:
用相应值除以一列中数值的和。比如第一列第一个数据概率的计算方法为(第一列第一个数)/(这一列的和)。
第三步:构建权重。用1-e得到信息的效用值,再对权重进行归一化即可得到权重w。
获得权重后,将权重矩阵与数据矩阵相乘获得加权后的数据矩阵,并求D+及D-的数值。代入到上述所讲的公式S即可求出具体得分。
四、代码
借用了一位博主的数据,兼顾了4种情况:

写了代码:
import numpy as np
'''1.输入数据'''
'''
5000 0.01 7.35 89
4500 0.2 7 63
4000 0.1 7.42 201
4400 0.0 7.10 60
5100 0.03 7.52 180
'''
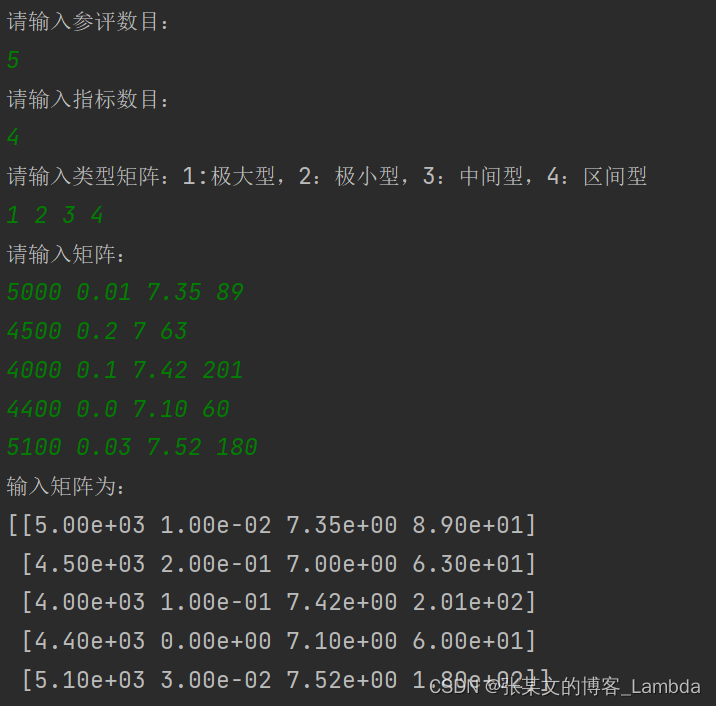
print("请输入参评数目:")
n = eval(input())
print("请输入指标数目:")
m = eval(input())
print("请输入类型矩阵:1:极大型,2:极小型,3:中间型,4:区间型")
kind = input().split(" ")
print("请输入矩阵:")
A = np.zeros(shape=(n, m))
for i in range(n):
A[i] = input().split(" ")
A[i] = list(map(float, A[i]))
print("输入矩阵为:\n{}".format(A))
'''2.统一指标类型'''
# 极小型指标转化为极大型指标:
def minTomax(maxx, x):
x = list(x)
ans = [[(maxx-e)] for e in x]
# ans = [list(1/e) for e in x]
return np.array(ans)
# 中间型指标转化为极大型指标:
def midTomax(bestx, x):
x = list(x)
h = [abs(e-bestx) for e in x]
M = max(h)
if M == 0:
M = 1
ans = [[(1-e/M)] for e in h]
return np.array(ans)
# 区间型指标转化为极大型指标:
def regTomax(lowx, highx, x):
x = list(x)
M = max(lowx-min(x), max(x)-highx)
if M == 0:
M = 1
ans = []
for i in range(len(x)):
if x[i]<lowx:
ans.append([(1-(lowx-x[i])/M)])
elif x[i]>highx:
ans.append([(1-(x[i]-highx)/M)])
else:
ans.append([1])
return np.array(ans)
X = np.zeros(shape=(n, 1))
for i in range(m):
if kind[i]=="1":
v = np.array(A[:, i])
elif kind[i]=="2":
maxA = max(A[:, i])
v = minTomax(maxA, A[:, i])
elif kind[i]=="3":
print("类型三:请输入最优值:")
bestA = eval(input())
v = midTomax(bestA, A[:, i])
elif kind[i]=="4":
print("类型四:请输入区间[a, b]值a:")
lowA = eval(input())
print("类型四:请输入区间[a, b]值b:")
highA = eval(input())
v = regTomax(lowA, highA, A[:, i])
if i==0:
X = v.reshape(-1, 1)
else:
X = np.hstack([X, v.reshape(-1, 1)])
print("统一指标后矩阵为:\n{}".format(X))
'''3.标准化处理'''
X = X.astype('float')
for j in range(m):
X[:, j] = X[:, j]/np.sqrt(sum(X[:, j]**2))
print("标准化矩阵为:\n{}".format(X))
'''4.获取权重指标'''
# 熵权法
# 这里默认了矩阵中不存在负数;若存在负数,需要再次归一化
p = X # 计算概率矩阵P
for j in range(m):
p[:, j] = X[:, j]/sum(X[:, j])
E = np.array(X[0, :]) # 计算熵值
for j in range(m):
E[j] = -1/np.log(n)*sum(p[:, j]*np.log(p[:, j]+ 1e-5))
w = (1-E)/sum(1-E) # 计算熵权
print("权重矩阵为:\n{}".format(w))
'''5.最大值最小值距离'''
# 得到加权后的数据
R = X*w
print("权重后的数据:\n{}".format(R))
# 得到最大值最小值距离
r_max = np.max(R, axis=0) # 每个指标的最大值
r_min = np.min(R, axis=0) # 每个指标的最小值
d_z = np.sqrt(np.sum(np.square((R - np.tile(r_max, (n, 1)))), axis=1)) # d+向量
d_f = np.sqrt(np.sum(np.square((R - np.tile(r_min, (n, 1)))), axis=1)) # d-向量
print('每个指标的最大值:', r_max)
print('每个指标的最小值:', r_min)
print('d+向量:', d_z)
print('d-向量:', d_f)
'''6.计算排名'''
s = d_f/(d_z+d_f)
Score = 100*s/max(s)
for i in range(len(Score)):
print(f"第{i+1}个百分制得分为:{Score[i]}")
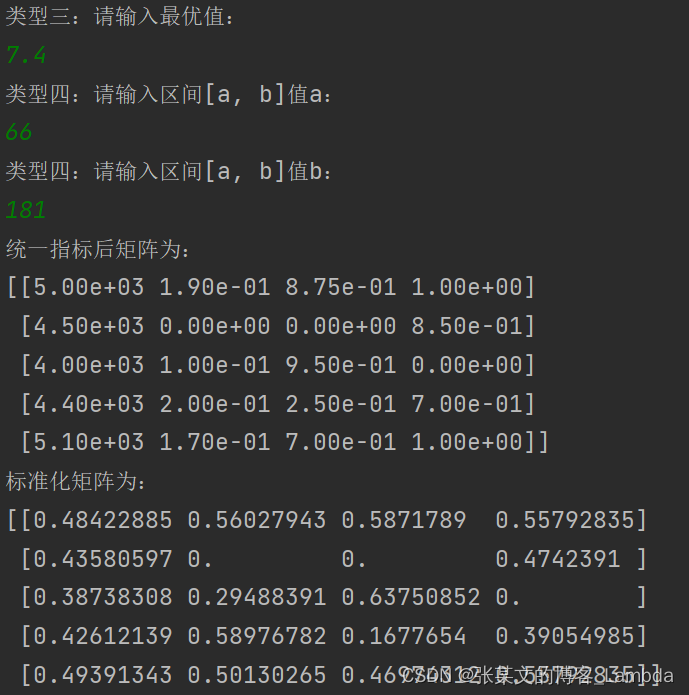
运算结果如图所示:

















 3943
3943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











