





#个性化联邦学习#,#数据异质性#,#参数分解#
 Wu, X., Liu, X., Niu, J., Wang, H., Tang, S., Zhu, G., & Su, H. (2024, October). Decoupling general and personalized knowledge in federated learning via additive and low-rank decomposition. In Proceedings of the 32nd ACM International Conference on Multimedia (pp. 7172-7181).
Wu, X., Liu, X., Niu, J., Wang, H., Tang, S., Zhu, G., & Su, H. (2024, October). Decoupling general and personalized knowledge in federated learning via additive and low-rank decomposition. In Proceedings of the 32nd ACM International Conference on Multimedia (pp. 7172-7181).
摘要
为了解决数据异质性,个性化联合学习(PFL)的关键策略是将常识(在客户之间共享)和特定于客户的知识中解脱出来,因为后者如果不删除,对协作会产生负面影响。 现有的PFL方法主要采用一种参数分区方法,其中模型的参数被指定为两种类型之一:与其他客户共享的参数之一,以提取本地保留的通用知识和参数以学习特定于客户端知识。 但是,由于在训练过程中,这两种类型的参数像拼图拼图一样将其放在单个模型中,因此每个参数可以同时吸收一般和客户特定的知识,因此努力地有效地分离了两种类型的知识。
在本文中,我们介绍了FedDecomp,这是一种简单但有效的PFL范式,它采用参数添加剂分解来解决此问题。 FedDecomp不是将模型的每个参数分配为共享或个性化的参数,而是将每个参数分解为两个参数的总和:共享一个和个性化的参数,从而实现了与参数相比,共享和个性化知识的更彻底的脱钩 分区方法。
此外,由于我们发现,保留特定客户的本地知识需要比所有客户的通用知识要低得多的模型容量,因此我们让包含个性化参数的矩阵在训练过程中是低等级的。 此外,提出了一种新的交替训练策略,以进一步提高性能。
多个数据集和不同程度的数据异质性的实验结果表明,FedDecomp优于最先进的方法高达4.9%。 该代码可在https://github.com/xinghaowu/feddecomp上找到。
Introduction
联邦学习(FL)[29]允许客户在不直接共享原始数据的情况下协作训练全局模型。它在多媒体人工智能系统的设计中获得了广泛的关注[4,21,41,46]。FL面临的一个主要挑战是数据异构性,即不同客户端之间的数据分布不是独立且相同的(非IID)。数据分布的这种差异阻碍了全局模型的训练,导致FL性能下降[11,23,36,44,51]。
为了应对这一挑战,个性化联合学习(Personalized Federated Learning,PFL)的概念应运而生。在PFL研究中,人们普遍认为,来访者学到的知识应分为两类:所有来访者的一般知识和该来访者的特定知识[6,37,43]。前者用于在客户端之间共享,以促进协作,而后者则保留在本地,以保持个性化,并减少数据异构对协作的影响。这一认识促使主流的PFL研究提出了一种基于划分的方法,在该方法中,在训练开始之前,客户个性化模型中的每个参数被指定为两种类型之一:与其他客户共享的参数,用于提取一般知识;以及在个性化中保留的参数,用于学习客户特定知识。已经出现了大量的研究。例如,FedPer [2]专注于分类器的个性化,而FedBN [25]的目标是批量规范化层的个性化。FedCAC [37]建议根据可测量的指标选择个性化参数。FedPFT [40]建议个性化可训练提示而不是模型参数。
虽然上述方法取得了一定的成功并引起了广泛的关注,但它们仍然没有有效地分离这两类知识。这是因为模型的个性化参数和共享参数作为一个整体一起从本地数据中学习,从而允许每个参数潜在地同时吸收通用和客户端特定的知识。这意味着个性化参数可以包含应当被共享的一些一般知识,并且共享参数可以包含应当被个性化的一些客户端特定知识。图1是直观地说明这一点的玩具示例。最左边的正方形表示包含九个参数的个性化模型参数矩阵。每个参数中的蓝色对角矩形和橙子对角矩形分别表示该参数中包含的一般知识和个性化知识,其面积大小表示知识量。可以看出,每个参数都包含通用知识和个性化知识。基于分区的方法将一些参数划分为共享参数(如蓝色正方形所示),并且将其余参数划分为个性化参数(如橙子正方形所示)。显然,这种“非黑即白色”的划分方式无法实现参数内的知识解耦,导致共享参数中的一些客户端专有知识被共享,从而降低了模型个性化程度;而个性化参数中的一些共享知识被个性化,从而降低了客户端协同程度。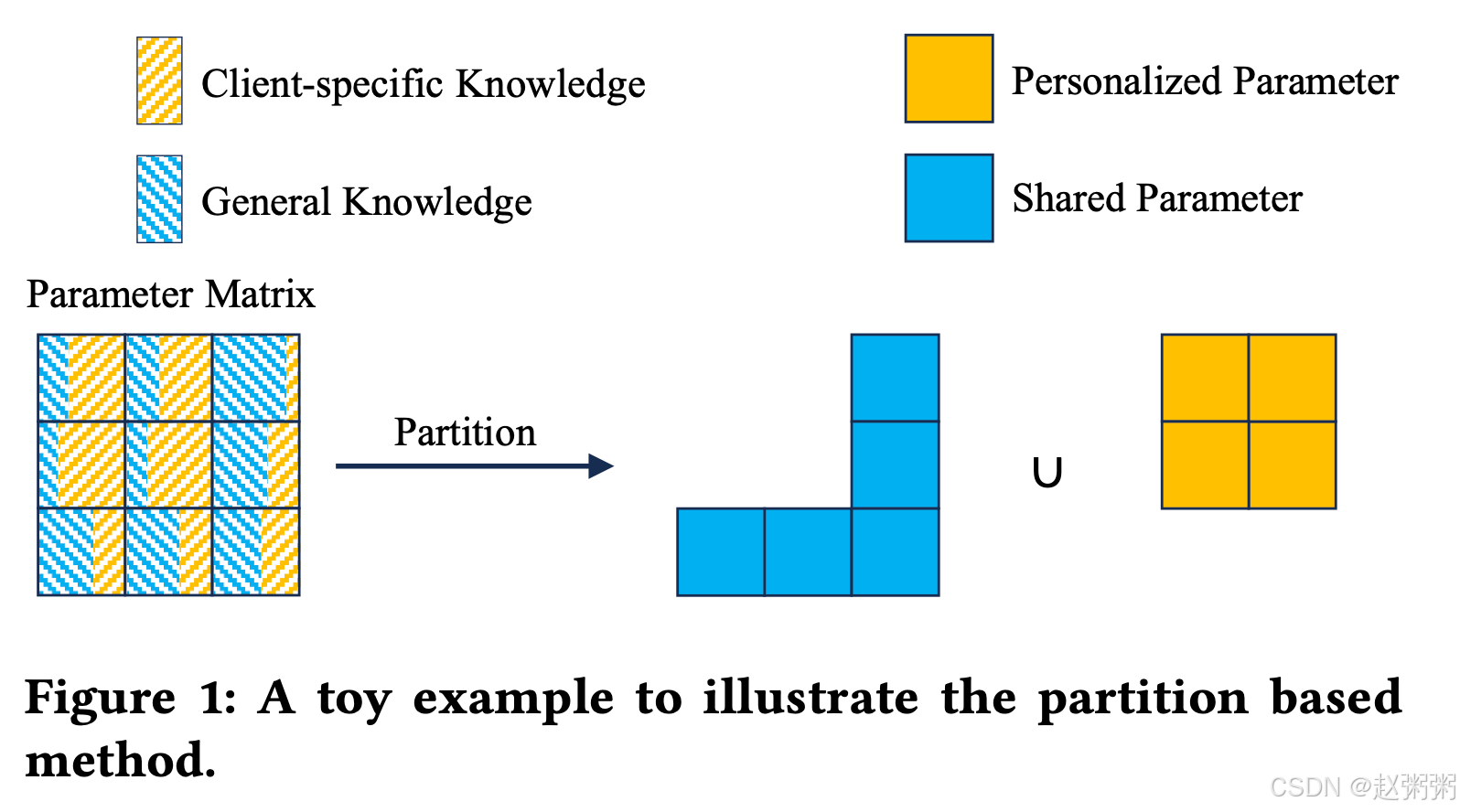
本文提出了一种基于参数加性分解的PFL范式,称为FedDecomp,以解决上述问题。与基于分区的方法不同,FedDecomp在训练开始之前将每个参数分解为两个参数的和:一个是共享的,以便于客户端之间的知识交换,另一个是本地保留的,以维护个性化。此外,我们发现,在PFL中,一般知识应该保留在具有高模型容量的共享参数中,以覆盖所有客户,而客户的特定知识可以通过具有较低模型容量的个性化参数来学习,作为一般知识的补充。因此,FedDecomp将包含个性化参数的矩阵约束为低秩。这允许个性化部分将其学习集中在局部知识的最关键方面,并减少对局部知识的过度拟合。因此,它有助于保留从其他客户端获得的大部分一般知识,从而增强概括性。图2说明了我们提出的方法。可以看出,在我们的方法中,每个参数中的通用知识和客户端特定知识都可以解耦,并相应地被共享和个性化参数捕获,从而实现更高效的客户端协作和个性化。
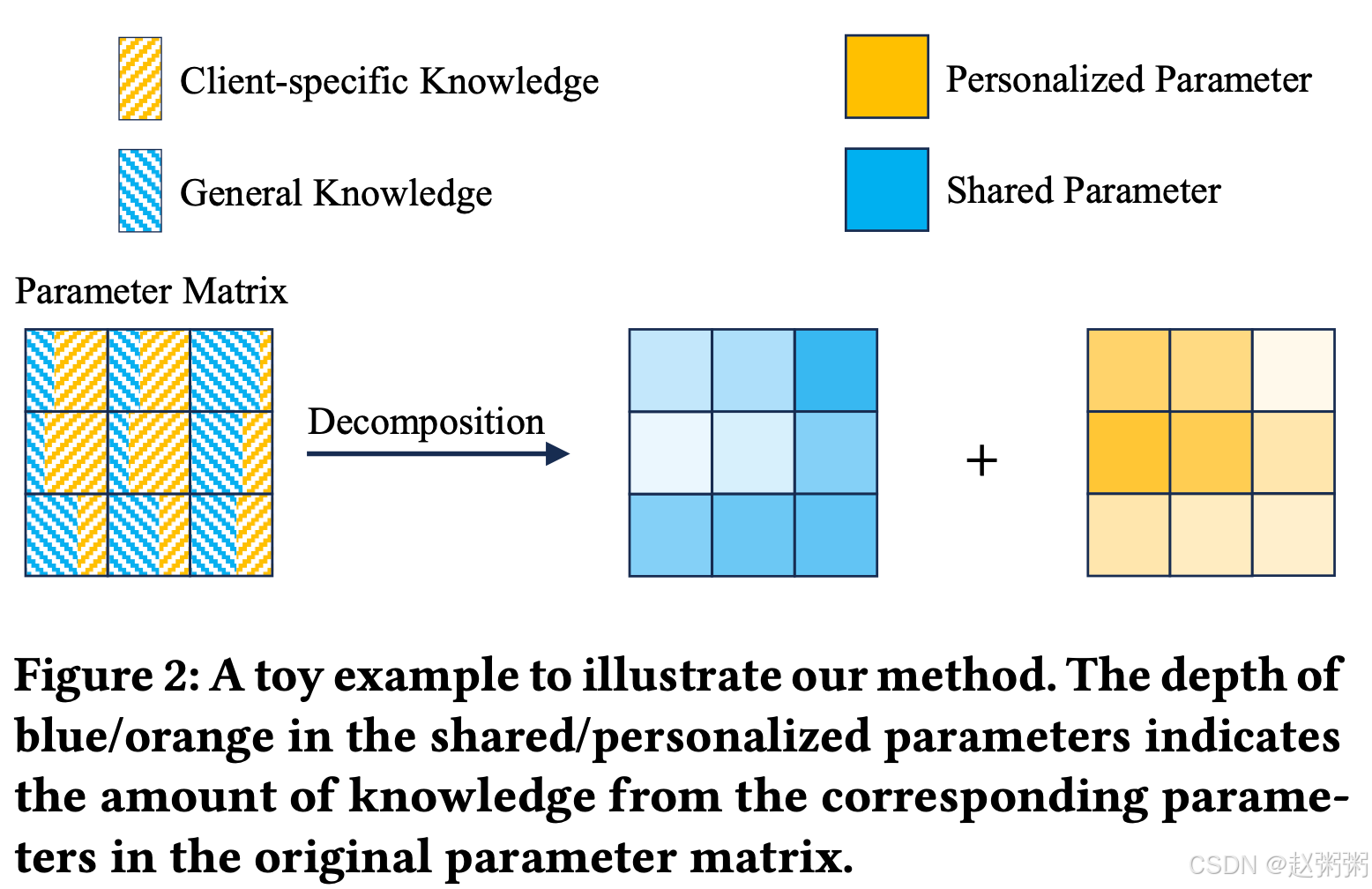
此外,与目前简单地同时训练个性化参数和共享参数的方法不同,本文研究了局部更新过程中共享参数矩阵和个性化参数矩阵的训练顺序.具体来说,我们建议首先训练个性化的低秩部分,以减轻非IID数据的影响,然后训练共享的满秩部分。我们的研究结果表明,采用交替的方法,不像并行训练方法,产生更大的好处。
我们在本文中的主要贡献可以概括如下:
·我们介绍了一种新的方法来分解共享和个性化的参数PFL,即FedDecomp。具体来说,我们将个性化模型的每一层分解为共享的满秩部分和个性化的低秩部分的总和,以保留一般知识和客户特定的知识。
我们引入了一种创新的训练策略,旨在优化FedDecomp,有效地减轻非IID数据的影响,并显着提高性能。
我们在多个数据集和各种非IID条件下评估FedDecomp。我们的研究结果强调了我们提出的FedDecomp方法的有效性。
Related Work
当前的PFL方法主要可分为基于元学习的方法[1,8]、基于微调的方法[5,18]、基于聚类的方法[3,9,32,47]、基于模型正则化的方法[24,34]、基于个性化聚合的方法[15,38,45]和基于参数分区的方法。在这些方法中,基于参数划分的方法因其简单有效而受到广泛关注。
基于参数分区方法这种方法的核心思想是共享原模型的一部分参数,同时对另一部分参数进行个性化。代表性的工作包括为个性化选择特定的层,例如FedPer [2]、FedRep [7]、FedPick [50]和GFPL [43]提出个性化分类器。FedBN [25]和MTFL [30]建议对批量归一化(BN)层进行个性化设置。LG-FedAvg [26]、AlignFed [49]和FedGH [42]提出了个性化特征提取器。其他工作采用深度强化学习(DRL)或超网络技术来自动选择用于个性化的特定层[28,33]。尽管如此,一些其他研究不再基于层而是基于每个单独的参数来选择个性化参数,从而做出更细粒度的选择来个性化对非IID数据敏感的参数[37]。近年来,一些研究提出了另一种个性化参数划分方法。与以前的方法不同,该方法的核心思想是在原模型中增加额外的个性化参数。例如,ChannelFed [48]引入了个性化的注意层,以个性化的方式重新分配不同频道的权重。[31]提出了在每个前馈层之后添加用于个性化的瓶颈模块。FedPFT [40]引入了一个带有个性化可训练提示的特征转换模块。
基于参数分解的方法一些PFL作品也利用参数分解技术。例如,Fedpara [16]将个性化模型参数矩阵分解为两个低秩矩阵的Hadamard乘积。证明了Hadamard乘积后的参数矩阵仍具有高秩,从而不牺牲模型容量。这样,它只需要在训练期间上传具有较少参数的低秩矩阵,从而减少通信开销。分解FL [17]将模型参数矩阵分解为列向量和行向量的乘积。在训练期间,它在共享列向量的同时个性化行向量。这本质上是一种低秩分解技术,旨在通过仅上传列向量来减少通信开销。另一方面,FedSLR [14]在服务器分发模型时执行参数矩阵的低秩分解,从而减少下行链路的通信开销。
很明显,我们的方法显着不同于目前的分解为基础的方法,从目标到方法。目前的方法主要针对PFL中的通信问题,通过对参数进行低秩分解来减少客户端和服务器端之间的通信量。本文主要研究PFL中知识的分离和提取。通过加性分解,将一般知识和客户特定知识的学习进行了并行化。通过将个性化矩阵约束为低秩,协调了一般知识和客户特定知识之间的关系。
Method
3.1 FedDecomp概述
我们首先介绍一下FedDecomp。如图3所示,客户端的个性化模型的每一层被分解为满秩矩阵和低秩矩阵的和。每个通信回合中的训练过程可以总结如下:
1)每个客户端重新冻结其满秩矩阵,并重新更新低秩矩阵𝝉𝑖。
2)然后,每个客户端轮流更新和冻结𝝉𝑖。在本地更新之后,所有客户端将满秩部分上传到服务器,同时保持低秩部分私有。
3)服务器接收客户端的满秩矩阵并将其聚合以生成全局模型矩阵。完成此操作后,服务器会向所有客户端发回数据包。
4)每个客户端接收全局模型并使用它来初始化满秩矩阵。
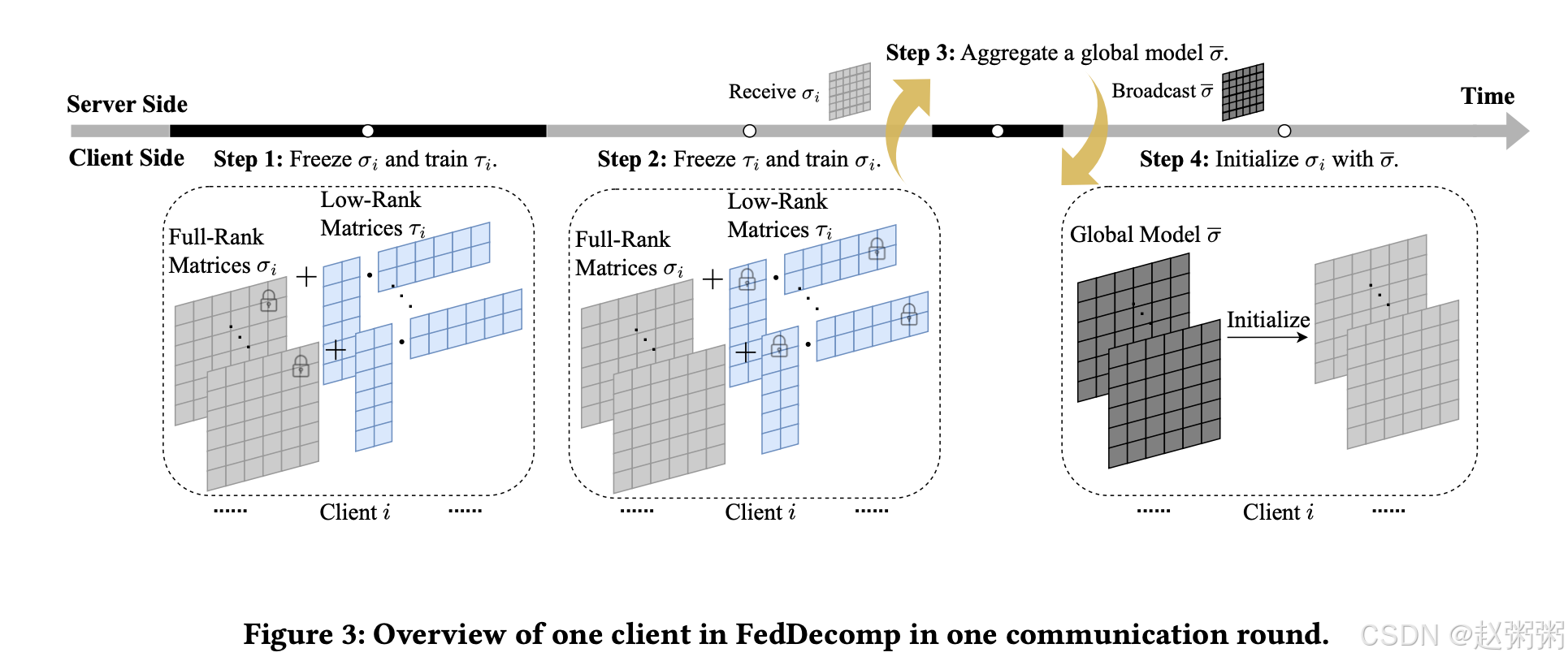
3.2 PFL的问题定义
PFL 与为所有客户训练通用模型的传统 FL 算法不同,它致力于为每个客户 𝑖 开发个性化模型,表示为 𝑤𝑖 ,专门捕捉其本地数据分布 𝐷𝑖 的独特特征。在最近的 PFL 研究中,人们一致认为,个人客户获得的知识包括一般知识和客户特定知识。在非 IID 场景中,由于不同的客户具有不同的数据分布(即,𝐷𝑖 ≠ 𝐷𝑗,𝑖 ≠ 𝑗),很难提取一般知识,从而给客户协作带来挑战。为了解决这个问题,PFL 将𝑤𝑖 解耦为共享部分𝜎 和个性化部分𝜏𝑖,分别学习一般知识和客户特定知识。正式地,训练目标可以表述为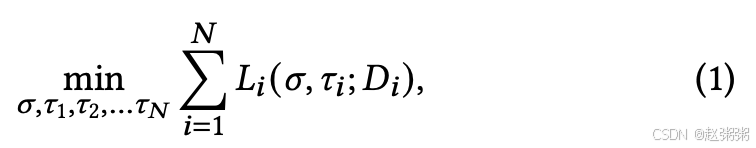
中 𝐿𝑖 (𝜎; 𝜏𝑖 ; 𝐷𝑖 ) 表示客户端 𝑖 的损失函数,𝑁 表示客户端总数。为了优化公式 (1) 中的目标函数,最近的研究提出了各种 PFL 方法来划分 𝜏𝑖 和 𝜎。虽然这些努力已经显示出希望,但如何进一步细化这两个参数分量的分解仍然是一个尚未解决的挑战。
3.3 低秩参数分解
我们观察到,共享参数负责提取一般知识受益于高模型容量。相比之下,个性化参数的任务是学习补充对特定本地任务的一般理解的知识(即,客户特定的知识),因此,使用低秩矩阵来表示这些个性化参数就足够了。基于这一观察,我们提出了FedDecomp,一种加性低秩分解技术。有关此方法的详细信息如下。
个性化模型的加法分解:假设每个个性化模型都有一组权重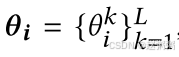 ,其中𝜃𝑘𝑖
,其中𝜃𝑘𝑖
是第𝑘层的权重,𝐿是总层数。每个权重矩阵𝜃𝑘𝑖最初都是满秩的。在 FedDecomp 中,我们将𝜃𝑘𝑖
分解为
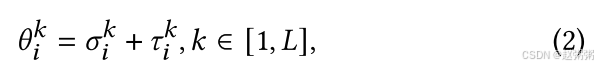
其中 𝜎𝑘 𝑖 , 𝑘 ∈ [1, 𝐿] 是所有客户端共享的满秩参数矩阵,𝜏𝑘 𝑖 , 𝑘 ∈ [1, 𝐿] 是个性化的低秩参数矩阵。在下文中,我们使用符号 𝜽𝑖 、 𝝈𝑖 和 𝝉𝑖 分别表示完整的模型参数集、满秩参数集和特定于客户端 𝑖 的低秩参数集。此外,我们使用 𝜃𝑘 𝑖 、 𝜎𝑘 𝑖 和 𝜏𝑘 𝑖 来表示客户端 𝑖 内第 𝑘 层的参数矩阵。
接下来,我们提出的方法施加低秩的约束上的随机数𝝉𝑖。
全连接层的低秩分解:对于全连接层,𝜏𝑘 𝑖 的维度为 𝐼 × 𝑂,其中 𝐼 和 𝑂 表示输入和输出维度。我们通过低秩分解约束 𝜏𝑘 𝑖,如下所示:
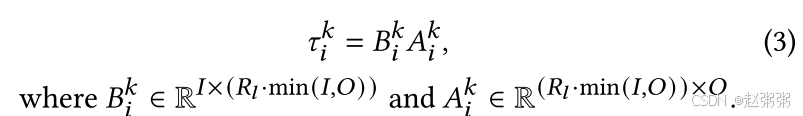
𝑅𝑙 是一个超参数,用于调节全连接层中 𝜏𝑘 𝑖 的秩。其值在 0 < 𝑅𝑙 ≤ 1 的范围内。
卷积层的低秩分解:与全连接层相比,卷积层涉及多个核,导致 𝜏𝑘 𝑖 ∈ 𝐼×𝑂×𝐾×𝐾 维度。但是,我们仍然可以应用低秩分解来约束 𝜏𝑘 𝑖,如下所示: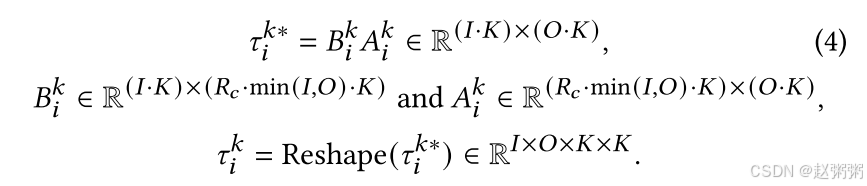
𝑅𝑐 是用于控制卷积层中 𝜏𝑘 𝑖 的秩的超参数。其值在 0 < 𝑅𝑐 ≤ 1 的范围内。
在训练过程中,𝐵 和 𝐴 都用作可训练参数矩阵。我们用随机高斯值初始化 𝐴,用零初始化 𝐵,这意味着 𝜏𝑘 𝑖 在训练开始时从零开始。
超参数𝑅𝑙 和 𝑅𝑐 分别在控制全连接层和卷积层中参数的秩方面起着至关重要的作用。随着秩的增加,模型中个性化参数的学习能力逐渐提高。但是,如果秩设置得太低,𝝉𝑖 可能难以有效捕获客户特定知识,从而使𝝈𝑖 极易受到非IID 数据分布的影响。这反过来会对客户之间的协作产生负面影响。相反,如果秩太大,𝝉𝑖 可能会开始吸收𝝈𝑖 应该学习的一些一般知识,从而降低客户之间的协作水平。为简单起见,在 FedDecomp 方法中,我们对所有卷积层应用相同的𝑅𝑐,对所有全连接层应用相同的𝑅𝑙。这种简化简化了模型架构和超参数调整过程。
3.4协调训练𝜎与𝝉
为了更好地提取一般知识,与同时训练个性化和共享参数的常见做法不同,我们发现更有效的策略是首先训练低秩参数。这种交替方法有助于减轻非 IID 数据的影响,然后再继续训练全秩参数。正式地说,在每个通信轮次 𝑡 ∈ [1, 𝑇] 中,我们首先通过以下方式优化 𝐸lora 轮次的低秩参数: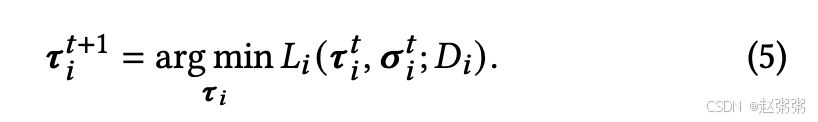
然后通过以下方式优化𝐸全局时期的全秩参数𝝈𝑖
我们设置 𝐸lora + 𝐸global = 𝐸,其中 𝐸 是一轮中局部更新周期的总数。这些超参数在平衡两个关键组件 𝝈𝑖 和 𝝉𝑖 之间的学习动态方面发挥着重要作用。
当 𝐸lora 设置得较高时,𝝈𝑖 学习的知识较少。因此,客户端之间的知识共享程度会降低。
相反,如果 𝐸lora 设置得太低,𝝈𝑖 最终会获得大量客户端特定的知识。
这种情况增加了客户端共享更容易受到非 IID 数据影响的知识的风险。
在特殊情况下,当 𝐸lora = 0 时,FedDecomp 框架会退化为 FedAvg。类似地,当𝐸global = 0时,FedDecomp 转变为具有低秩参数的本地训练,无需客户端之间的任何协作。
本地更新后,每个客户端𝑖 将𝝈𝑡+1 𝑖 上传到服务器,同时保持𝝉𝑡+1 𝑖 的私密性。服务器通过以下方式汇总所有客户端的𝝈𝑡+1 𝑖 来计算全局模型
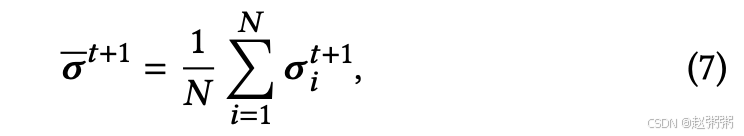
并将其发送回客户端。
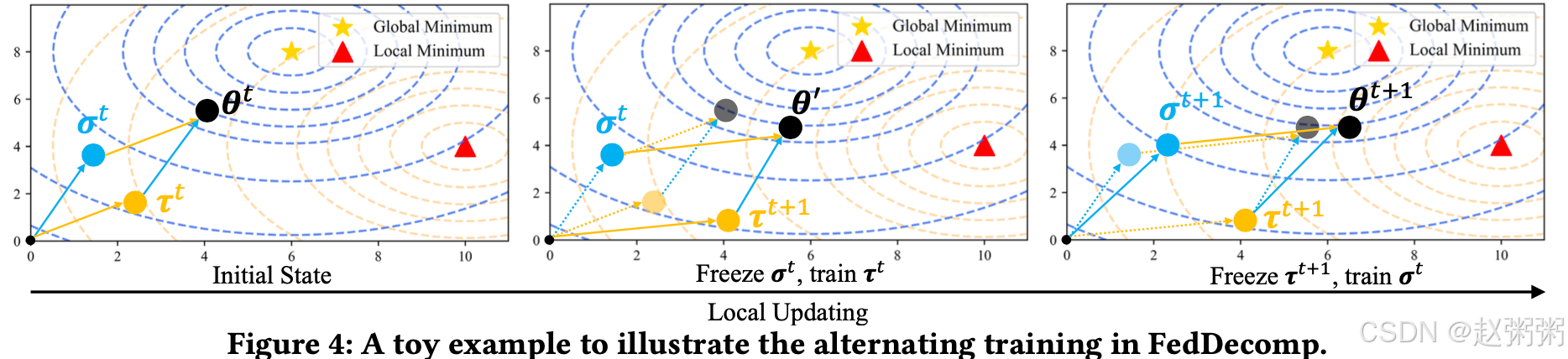
为了解释我们提出交替训练的直觉,我们使用一个玩具示例来说明每个客户的个性化模型在参数空间内的局部更新阶段。如图4所示,黄色*和红色△分别表示全局模型在所有客户数据上的最佳点(全局损失最小点)和个性化模型在客户数据上的最佳点(局部损失最小点)。在非IID的影响下,客户的全局知识和局部知识之间存在很大差异。这使得局部最小点远离全局最小点。
客户的个性化模型分解为共享部分
和个性化部分
的总和。由于我们首先训练个性化部分,客户特定知识主要由
学习,而
向局部最小点的转移主要由
完成。因此,在训练
时,它向局部最小点的移动较少(即受非ID数据的影响较小)。所以它可以更好地提取一般知识。在第 4.4 节中,我们进行了一项实验来进一步验证这一直觉。
3.5 训练成本分析
在本节中,我们对比了 FedDecomp 在每个客户端 𝑖 中的内存使用情况、计算成本和通信成本,以及与基线方法 FedAvg 的比较。
内存使用情况:FedAvg 需要维护一组满秩参数集 𝜽𝒊。根据公式 (2)、公式 (3) 和公式 (4),FedDecomp 需要维护一个可训练参数数量相当于 𝜽𝒊 的满秩参数集 𝝈𝒊,以及一个可训练参数数量远少于 𝜽𝒊 的低秩参数集 𝝉𝒊。因此,FedDecomp 所需的内存略高于 FedAvg。
计算成本:在一轮中,FedAvg 会更新 𝐸 个局部时期的 𝜽𝒊。根据公式 (5) 和公式 (6), FedDecomp 在 𝐸lora 个时期内更新 𝝉𝑖,在 𝐸 − 𝐸lora 个时期内更新 𝝈𝑖。由于 𝝉𝑖 的可训练参数比 𝜽𝒊 少,因此 FedDecomp 的计算成本低于 FedAvg。
通信成本:在一轮通信中,FedAvg 需要上传 𝜽𝒊,而 FedDecomp 需要上传 𝝈𝑖 。由于 𝝈𝑖 的可训练参数数量与 𝜽𝒊 相同,因此 FedDecomp 的通信成本与 FedAvg 相同。
Experiments
4.1实验装置
数据集。我们的主要实验是在三个数据集上进行的:CIFAR-10 [20]、CIFAR-100 [19]和Tiny ImageNet [22]。
在补充材料中纳入了涉及文本模态的较大数据集的实验。为了评估我们的方法在各种场景中的有效性,我们采用了Dirichlet非IID设置,这是当前FL研究中常用的框架[13,27,39]。在这个设置中,每个客户端的数据都是从Dirichlet分布中生成的,表示s𝐷𝑖𝑟(𝛼).。𝐷𝑖𝑟随着𝛼值的增加,每个客户端数据集中的类不平衡程度逐渐降低。因此,Dirichlet非IID设置允许我们在各种不同的非IID场景中测试我们的方法的性能。为了更直观地理解这一概念,我们在补充材料中提供了数据分区的可视化。

















 1095
1095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









