







1.说明
1.环境依赖
flink版本:flink-1.13.0
flink-cdc版本:2.1.0
hudi版本:2.11-0.10.0
hive版本:3.1.0
2.使用过程中FLINK中的包

3.过程记录
注意
1.我这里读取的是Oracle的实时数据,所以需要开通Oracle的附加日志
2.hudi目前需要自己去编译,也可以在社区中找你想要的包或者直接下载HUDI包下载
3.cdc我这边因为读取的是Oracle所以用的是2.1.0,cdc版本和flink版本对比 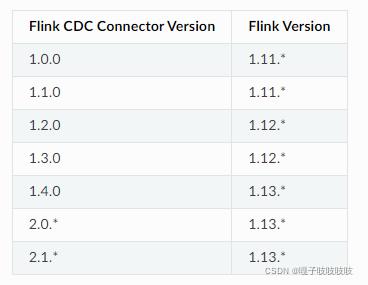
开搞
1.启动flinksql
./sql-client.sh embedded
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR or HADOOP_CLASSPATH was set.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
2022-01-27 16:43:43,765 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-hive.
2022-01-27 16:43:43,765 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-hive.
No default environment specified.
Searching for ‘/home/hive/flink-1.13.0/conf/sql-client-defaults.yaml’…found.
Reading default environment from: file:/home/hive/flink-1.13.0/conf/sql-client-defaults.yaml
Command history file path: /home/hive/.flink-sql-history
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
______ _ _ _ _____ ____ _ _____ _ _ _ BETA
| | () | | / |/ __ | | / | () | |
| | | | _ __ | | __ | ( | | | | | | | | | ___ _ __ | |
| | | | | ’ | |/ / _ | | | | | | | | | |/ _ \ ’ | |
| | | | | | | | < ____) | || | |____ | || | | _/ | | | |
|| |||| |||_\ |/ ___| ___|||_|| ||__|
Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit.
2.创建Oracle源表
create table IF NOT EXISTS ORACLE_FLINK(
ID STRING,
NAME STRING,
AGE STRING,
SEX STRING)
WITH (
'connector' = 'oracle-cdc',
'hostname' = '127.0.0.1',
'port' = '6045',
'username' = 'liuyun',
'password' = '123456',
'table-name' = 'FLINK',
'schema-name' = 'LIUYUN',
'database-name' = 'xe',
'debezium.log.mining.strategy'='online_catalog',
'debezium.log.mining.continuous.mine'='true'
);
[INFO] Execute statement succeed.
3.查询Oracle源表数据
SELECT * FROM ORACLE_FLINK;
ID NAME AGE SEX
7 7 7 7
1 1 1 1
2 2 2 2
3 3 3 3
4 4 4 4
5 5 5 5
4.创建HUDI表
create TABLE ORACLE_HUDI(
id string ,
name string,
age string,
sex VARCHAR(20),
primary key(id) not enforced
)
PARTITIONED BY (sex)
with(
'connector'='hudi',
'path'= 'hdfs://bigdata/tmp/hudi/ORACLE_HUDI'
, 'table.type'= 'MERGE_ON_READ'
, 'read.streaming.enabled'= 'true'
, 'read.streaming.check-interval'= '3'
);
[INFO] Execute statement succeed.
5.把ORACLE_FLINK数据插入ORACLE_HUDI
insert into ORACLE_HUDI select * from ORACLE_FLINK;
6.查看任务执行情况
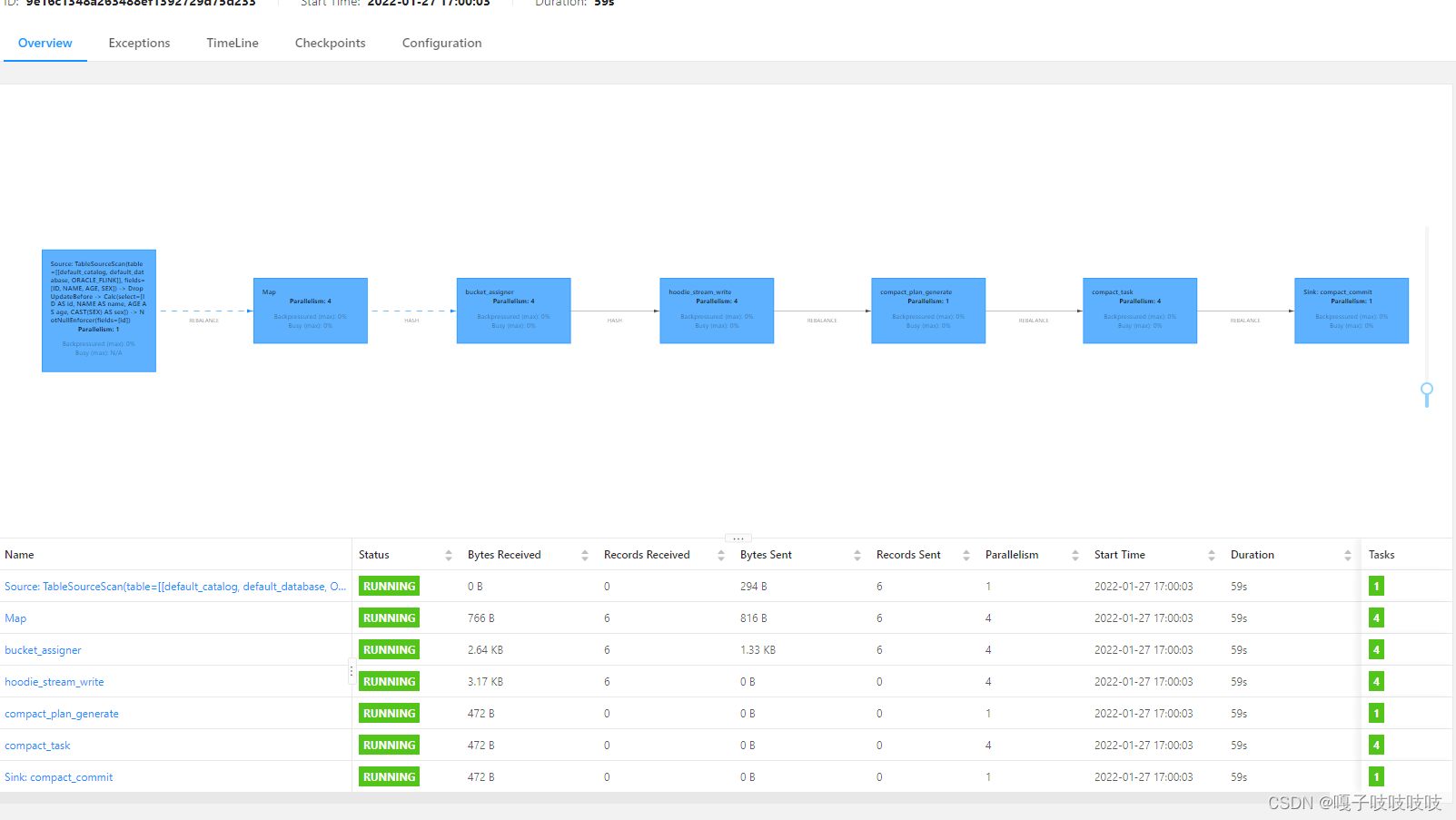
7.查看ORACLE_HUDI数据是否正常
select * from ORACLE_HUDI;
id name age sex
3 3 3 3
4 4 4 4
1 1 1 1
2 2 2 2
7 7 7 7
5 5 5 5















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











