







1 线程
import threading
def main():
print(threading.active_count()) #看一下目前有多少个激活了的线程
print(threading.enumerate()) #看一下这些线程是哪几个
print(threading.current_thread()) #看一下现在在用的是哪个线程
if __name__ == '__main__':
main()
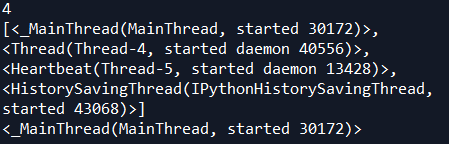
可以看到现在有四个线程,执行的是主线程
2 添加线程
import threading
def thread_job():
print("This is an add Thread,number is %s" % threading.current_thread())
def main():
added_thread = threading.Thread(target = thread_job)
# 添加一个线程,参数里传进一个可执行的方法
added_thread.start() #线程开始
# print(threading.active_count()) #看一下目前有多少个激活了的线程
# print(threading.enumerate()) #看一下这些线程是哪几个
# print(threading.current_thread()) #看一下现在在用的是哪个线程
if __name__ == '__main__':
main()
This is an add Thread,number is <Thread(Thread-6, started 5508)>
添加了一个Thread-6线程
import threading
import time
def thread_job():
print("T1 start\n" )
for i in range(10):
time.sleep(0.1)#每次暂停0.1,一共十次暂停1s
print('T1 finish\n')
def main():
added_thread = threading.Thread(target = thread_job,name = 'T1')
# 添加一个线程,参数里传进一个可执行的方法
added_thread.start() #线程开始
print('all Done\n')
if __name__ == '__main__':
main()
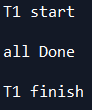
3 join()
可以看到all Done并不是等到T1 finish这行语句执行完的,说明这个added_thread.start()和print('all Done\n')两条语句是同时执行的
为了让这两个语句能够先后执行:
import threading
import time
def thread_job():
print("T1 start\n" )
for i in range(10):
time.sleep(0.1)#每次暂停0.1,一共十次暂停1s
print('T1 finish\n')
def main():
added_thread = threading.Thread(target = thread_job,name = 'T1')
# 添加一个线程,参数里传进一个可执行的方法
added_thread.start() #线程开始
added_thread.join() #表示等待added_thread任务执行完之后才开始后面的代码
print('all Done\n')
if __name__ == '__main__':
main()
加了一个join,等待程序执行完毕,开始后面的代码
import threading
import time
def T1_job():
print("T1 start\n" )
for i in range(10):
time.sleep(0.1)#每次暂停0.1,一共十次暂停1s
print('T1 finish\n')
def T2_job(): #T2做的任务耗时更少
print("T2 start\n" )
print('T2 finish\n')
def main():
added_threadT1 = threading.Thread(target = T1_job,name = 'T1')
# 添加一个线程,参数里传进一个可执行的方法
added_threadT2 = threading.Thread(target = T2_job,name = 'T2')
# 添加一个线程,参数里传进一个可执行的方法
added_threadT1.start() #线程开始
added_threadT2.start() #线程开始
print('all Done\n')
if __name__ == '__main__':
main()
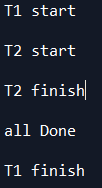
我们能看到,T1开始后,T2也开始,但是因为T2耗时更少,所以马上就结束了,T1等到all Done之后才结束added_threadT1.start()和added_threadT2.start()和print('all Done\n')开始有先后,但是处理是同时进行的,耗时久的后结束
import threading
import time
def T1_job():
print("T1 start\n" )
for i in range(10):
time.sleep(0.1)#每次暂停0.1,一共十次暂停1s
print('T1 finish\n')
def T2_job(): #T2做的任务耗时更少
print("T2 start\n" )
print('T2 finish\n')
def main():
added_threadT1 = threading.Thread(target = T1_job,name = 'T1')
# 添加一个线程,参数里传进一个可执行的方法
added_threadT2 = threading.Thread(target = T2_job,name = 'T2')
# 添加一个线程,参数里传进一个可执行的方法
added_threadT1.start() #线程开始
added_threadT2.start() #线程开始
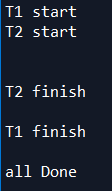
added_threadT1.join() #等待T1结束之后才进行后面的操作
print('all Done\n')
if __name__ == '__main__':
main()
4 Queue
多线程运算的结果放在队列中,对每一个线程的队列,放入主线程中,再取出
import threading
import queue
def job(name,lis,q):#传进来一个列表
#定义一个job,对列表中的每一个值进行平方的运算
for i in range(len(lis)):
lis[i] = lis[i]**2
q.put(lis) #把小列表的处理结构放到q里面
print(str(lis) + ' has been done\n')
#返回得出来的结果
#return L不能使用,因为线程中的返回值是得不到的,所以需要构建一个列表去得到
def multithreading(data):
q = queue.Queue() #存放所有线程返回的结果
threads = [] #存放所有的线程
for i in range(4):#定义4个线程
threadName = 'Thread' + str(i)
t = threading.Thread(target = job,args = (threadName,data[i],q))
#target后面只放方法索引job,具体参数放在后面的args里面
#每一个线程对应处理data里面一个小列表,如[1,2,3]
print(threadName + ' start\n')
t.start()
# print(data[i])
threads.append(t)#threads得到的是一个线程列表,里面存放的是各个线程
for thread in threads:
thread.join()
# 将所有线程join到主线程里面去,等待所有线程完了之后才进行后面的操作
results = []
for _ in range(4):#得到q里面的值
results.append(q.get()) #从q里面拿四次值,拿出来放到result里面去
return results
if __name__ == '__main__':
data = [[1,2,3],[3,4,5],[4,4,4],[5,5,5]] #四个线程同时处理四个小列表
results = multithreading(data)
print(results)

5 效率问题
python中多线程不一定有效率提高的效果
多线程有一个全局的控制,并不是把任务平均分给每个线程同时做
python只能让一个线程在同一个时间运算,只是不同的线程在相互切换

这里采用normal方法和multithreading的方法对比:
普通方法一个线程执行四遍,多线程方法,四个线程执行一遍,看看是否是多线程会提高效率
import threading
import queue
import time
import copy
def job(name,lis,q):#传进来一个列表
res = sum(lis)
q.put(res)
def multithreading(data):
q = queue.Queue() #存放所有线程返回的结果
threads = [] #存放所有的线程
for i in range(4):#定义4个线程
threadName = 'Thread' + str(i)
t = threading.Thread(target = job,args = (threadName,copy.copy(data),q))
#target后面只放方法索引job,具体参数放在后面的args里面
# print(threadName + ' start\n')
t.start()
# print(data[i])
threads.append(t)#threads得到的是一个线程列表,里面存放的是各个线程
# for thread in threads:
# thread.join()
# # 将所有线程join到主线程里面去,等待所有线程完了之后才进行后面的操作
[t.join() for t in threads]#与上面的for循环作用一样
total = 0
for _ in range(4):#得到q里面的值
total += q.get()
return total
def nomal(data):
total = sum(data)
return total
if __name__ == '__main__':
data = list(range(1000000))#得到一个列表
s_t = time.time()
nomal_total = nomal(data*4)#这个列表扩大四倍,用普通方法求和
#一个线程求和四倍数据所用的时间
print('nomal:',time.time()-s_t)
print(nomal_total)
s_t = time.time()
multithreading_total = multithreading(data)
#四个线程求和一倍数据所有的总时间
print('multithreading:',time.time()-s_t)
print(multithreading_total)
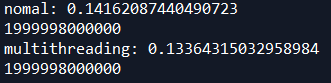
同时只有一个线程在工作,实际上减少的时间是读写所节省出来的时间
如果要使很多数据的处理同时进行,那么就需要multiprocess,多进程
6 Lock
import threading
#定义两个任务,都对A进行操作,看会怎么样
def job1():
global A
for i in range(10):
A += 1
print('job1:',A)
def job2():
global A
for i in range(10):
A += 10
print('job2:',A)
if __name__ == '__main__':
A = 0
#开两个线程,两个线程分别做不同的任务
t1 = threading.Thread(target = job1)
t2 = threading.Thread(target = job2)
t1.start()
t2.start()
t1.join()
t2.join()
我们可以看到job1,job2同时进行,而且打印的比较乱,每次运行的过程都是不确定的
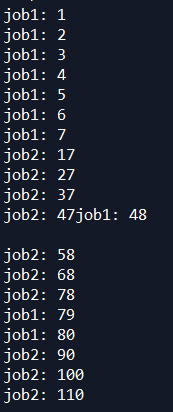
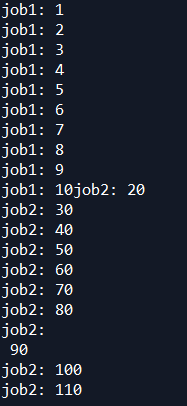

如果想要job1进行完了之后才进行job2,那么就要把job1给lock起来
import threading
#定义两个任务,都对A进行操作,看会怎么样
def job1():
global A,lock
lock.acquire()
for i in range(10):
A += 1
print('job1:',A)
lock.release()
def job2():
global A,lock
lock.acquire()
for i in range(10):
A += 10
print('job2:',A)
lock.release()
if __name__ == '__main__':
lock = threading.Lock() #实例化一个lock对象
A = 0
#开两个线程,两个线程分别做不同的任务
t1 = threading.Thread(target = job1)
t2 = threading.Thread(target = job2)
t1.start() #t1开始之后,进入锁锁住,知道运行结束,才开始t2的任务
t2.start()
t1.join()
t2.join()
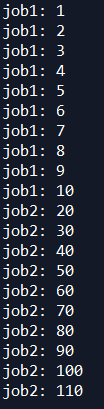














 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









