







1.搜索引擎的原理----TF-IDF
网页变成索引,存到搜索引擎的数据库里,等待被搜索
多模态搜索: 用文字搜索视频,用图片搜索视频,用图片搜索文字,等等
将图片,视频转化为数字,与其他转化为数字的视频,文字,视频进行匹配
BigData --> 批量召回 --> 粗排 --> 精排
层层筛选过滤,使用时间消耗较少的方法
将深度学习放在最后精排,使其时间消耗更短
TF-IDF: TF词频(Term Frequency) IDF逆文本频率指数(Inverse Document Frequency)
词频,就是词在文章中出现的频率,次数。 文章信息的局部信息
逆文本频率指数,指一个词在文本中的区分力大小,避免了常用词,如你我他词频太高带来的影响。 系统的全局信息
一般用TF * IDF来表示文章,表示文章的关键内容
使用IDF时,可以在专一的某一个领域下训练出一个特定的IDF值,比范领域下的IDF精确度要好。
把文章或者视频,语句转化为向量,用向量的相似性来匹配最相似的文章,cos距离计算。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
docs = [
"it is a good day,I like to stay here",
"I am happy to be here",
"I am bob",
"it is sunny today",
"I have a party today",
"it is a dog and that is a cat",
"there are dog and cat on the tree",
"I study hard this morning",
"today is a good day",
"tomorrow will be a good day",
"I like coffee,I like book and I like apple",
"I do not like it",
"I am kitty,I like bob",
"I do not care who like bob, but I like kitty",
"It is coffee time, bring your cups",
]
vectorizer = TfidfVectorizer()
# 直接调用TfidfVectorizer的fit_transformer方法就可以得到tf-idf值了
tf_idf = vectorizer.fit_transform(docs)
print("idf: ",[(n,idf) for idf,n in zip(vectorizer.idf_,vectorizer.get_feature_names())])
计算出来idf如下所示:
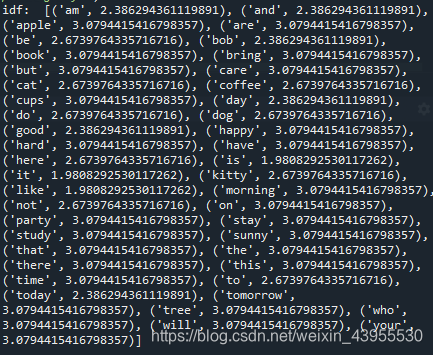
idf也可以单独提取出来,用去其他的操作和使用,如果有相同类型的文章集合也可以不用再去训练idf了
然后打印出每个单词对应的索引print("v2i:",vectorizer.vocabulary_)

那如果再来一个文本,就可以通过它的tf-idf向量与文本库里面的向量进行比对,找出最适合的向量
qtf_idf = vectorizer.transform([q])
res = cosine_similarity(tf_idf,qtf_idf)
把匹配结果按照分数高低进行排序
res = res.ravel().argsort()[-3:] # 只取最匹配的前三名
print("\ntop 3 docs for '{}':\n{}".format(q,[docs[i] for i in res[::-1]]))

tf-idf匹配流程:
1.实例化TfidfVectorizer()对象
2.输入若干条文本,transform成tf-idf向量
3.用cosin距离进行计算最匹配的文本
可以看到这里每个文本都变成了一个44维的向量


为什么都是44维呢,因为每个词有一个tf,有一个idf,那这总共的文本就一共有44维向量
BERT 注意力机制
集群版搜索引擎 ElasticSearch
搜索引擎流程:
Query --> 分词、敏感词过滤、纠错、拼音识别、查询改写、查询补全…–>ElasticSearch、热度召回、地理信息召回、…–>搜索结果
2.词向量训练方法----CBOW,skip-gram
深度学习的技术CBOW,非深度学习的技术TF-IDF,一个精度更高,一个更快。
中性词:区分力不大的词,“在”,“是”… 这些
One-hot represention 将词汇用二进制向量表示,这个向量表示的词汇,仅仅在词汇表中的索引位置处为1,其他地方都为0。

这样的缺点其实是很多的,所以有一种embedding的方法:

Word Embedding得到的向量维度远小于词汇表的个数,通过词向量之间的距离可以度量他们之间的关系。
训练词向量
非监督学习,取一小段文本,计算词向量,用整个向量预测最中间的那个词,依次类推,计算机就能搞清楚前后文关系,距离越近的词,关系越亲密。
如
输入[‘我’][‘中国’]
输出[‘爱’]
同样也可以用中间词预测前后文
CBOW(Continuous Bag of Words)
tf-idf算法是通过一种统计学的方式来用文章中的词的重要程度,转化成向量来表示一篇文章的。速度较快,但是准确率不如深度学习的方法
CBOW就是挑一个要预测的词,来学习这个词前后文中词语和预测词的关系,那每个词都可以在一个空间中表示出来,可以通过空间位置知道词语之间的对应关系,理论上,语义越相近的词语将会距离更近
corpus = [
# numbers
"5 2 4 8 6 2 3 6 4",
"4 8 5 6 9 5 5 6",
"1 1 5 2 3 3 8",
"3 6 9 6 8 7 4 6 3",
"8 9 9 6 1 4 3 4",
"1 0 2 0 2 1 3 3 3 3 3",
"9 3 3 0 1 4 7 8",
"9 9 8 5 6 7 1 2 3 0 1 0",
# alphabets, expecting that 9 is close to letters
"a t g q e h 9 u f",
"e q y u o i p s",
"q o 9 p l k j o k k o p",
"h g y i u t t a e q",
"i k d q r e 9 e a d",
"o p d g 9 s a f g a",
"i u y g h k l a s w",
"o l u y a o g f s",
"o p i u y g d a s j d l",
"u k i l o 9 l j s",
"y g i s h k j l f r f",
"i o h n 9 9 d 9 f a 9",
]
例如这里又字母也有数字,假设他们都是单词,那根据前后文关系,其实应该是学到字母们在向量空间上的位置更相近,而数字的位置更相近,对于数字9这个与字母也前后文关系密切,与数字也前后文关系密切的,应该空间上离两者都很近
构造模型的训练集,这里是将一句话中滑动移动5个单词的窗口,以前后两个,共四个单词作为训练数据的特征,中间那个词作为训练数据的标签
# 3.定义产生训练数据的方法
class Dataset:
def __init__(self, x, y, v2i, i2v):
self.x, self.y = x, y
self.v2i, self.i2v = v2i, i2v
self.vocab = v2i.keys()
def sample(self, n):
b_idx = np.random.randint(0, len(self.x), n) # 产生随机数
bx, by = self.x[b_idx], self.y[b_idx] # 使顺序打散训练,这样每一次调用,都会产生shuffle的数据
return bx, by
@property
def num_word(self):
return len(self.v2i)
def process_w2v_data(corpus, skip_window=2, method="skip_gram"):
all_words = [sentence.split(" ") for sentence in corpus]
all_words = np.array(list(itertools.chain(*all_words))) # 连成一条
# vocab sort by decreasing frequency for the negative sampling below (nce_loss).
vocab, v_count = np.unique(all_words, return_counts=True) # 统计有多少种不同的词,以及个数
vocab = vocab[np.argsort(v_count)[::-1]] # 按照个数从多到少排序
print("all vocabularies sorted from more frequent to less frequent:\n", vocab)
v2i = {v: i for i, v in enumerate(vocab)} # 单词即对应的索引,从大到小拍多少号
i2v = {i: v for v, i in v2i.items()} # 从索引找到单词
# pair data
pairs = []
js = [i for i in range(-skip_window, skip_window + 1) if i != 0]
# -2到2一共五个单词,去掉最中间的,窗口大小为5
for c in corpus:
words = c.split(" ")
w_idx = [v2i[w] for w in words] # 把每一行文本的单词都换成索引放在列表里
if method == "skip_gram":
for i in range(len(w_idx)):
for j in js:
if i + j < 0 or i + j >= len(w_idx):
continue
pairs.append((w_idx[i], w_idx[i + j])) # (center, context) or (feature, target)
elif method.lower() == "cbow":
for i in range(skip_window, len(w_idx) - skip_window): # 在这一行列表上开始滑动窗口,每一次华东都包含5个单词
context = [] # 装每个窗口的五个单词的索引,context里面装的是前后共四个
for j in js:
context.append(w_idx[i + j])
pairs.append(context + [w_idx[i]]) # (contexts, center) or (feature, target)
else:
raise ValueError
pairs = np.array(pairs)
print("5 example pairs:\n", pairs[:5])
if method.lower() == "skip_gram":
x, y = pairs[:, 0], pairs[:, 1]
elif method.lower() == "cbow":
x, y = pairs[:, :-1], pairs[:, -1]
else:
raise ValueError
return Dataset(x, y, v2i, i2v)
首先是把所有的单词进行一个词频的统计以及排序,为他们安排一个索引

所有的单词排序从出现词频最多的到最低的,同时每个词具有了一个索引,把上述的整段文本,用索引来转化
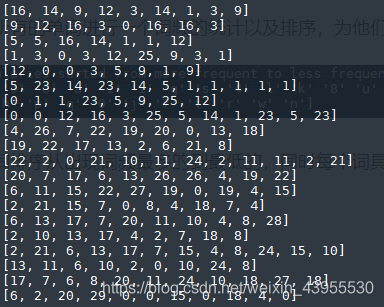
然后对每一句话开始以窗口为5划窗,中间的摘出来作为标签,那么特征就是:
[16, 14, 12, 3]
[14, 9, 3, 14]
[9, 12, 14, 1]
[12, 3, 1, 3]
[3, 14, 3, 9]
[9, 12, 3, 0]
[12, 16, 0, 16]
[16, 3, 16, 16]
[3, 0, 16, 3]
[5, 5, 14, 1]
[5, 16, 1, 1]
[16, 14, 1, 12]
[1, 3, 3, 12]
[3, 0, 12, 25]
[0, 3, 25, 9]
[3, 12, 9, 3]
[12, 25, 3, 1]
[12, 0, 3, 5]
[0, 0, 5, 9]
[0, 3, 9, 1]
[3, 5, 1, 9]
[5, 23, 23, 14]
[23, 14, 14, 5]
[14, 23, 5, 1]
[23, 14, 1, 1]
[14, 5, 1, 1]
[5, 1, 1, 1]
[1, 1, 1, 1]
[0, 1, 23, 5]
[1, 1, 5, 9]
[1, 23, 9, 25]
[23, 5, 25, 12]
[0, 0, 16, 3]
[0, 12, 3, 25]
[12, 16, 25, 5]
[16, 3, 5, 14]
[3, 25, 14, 1]
[25, 5, 1, 23]
[5, 14, 23, 5]
[14, 1, 5, 23]
[4, 26, 22, 19]
[26, 7, 19, 20]
[7, 22, 20, 0]
[22, 19, 0, 13]
[19, 20, 13, 18]
[19, 22, 13, 2]
[22, 17, 2, 6]
[17, 13, 6, 21]
[13, 2, 21, 8]
[22, 2, 21, 10]
[2, 0, 10, 11]
[0, 21, 11, 24]
[21, 10, 24, 2]
[10, 11, 2, 11]
[11, 24, 11, 11]
[24, 2, 11, 2]
[2, 11, 2, 21]
[20, 7, 6, 13]
[7, 17, 13, 26]
[17, 6, 26, 26]
[6, 13, 26, 4]
[13, 26, 4, 19]
[26, 26, 19, 22]
[6, 11, 22, 27]
[11, 15, 27, 19]
[15, 22, 19, 0]
[22, 27, 0, 19]
[27, 19, 19, 4]
[19, 0, 4, 15]
[2, 21, 7, 0]
[21, 15, 0, 8]
[15, 7, 8, 4]
[7, 0, 4, 18]
[0, 8, 18, 7]
[8, 4, 7, 4]
[6, 13, 7, 20]
[13, 17, 20, 11]
[17, 7, 11, 10]
[7, 20, 10, 4]
[20, 11, 4, 8]
[11, 10, 8, 28]
[2, 10, 17, 4]
[10, 13, 4, 2]
[13, 17, 2, 7]
[17, 4, 7, 18]
[4, 2, 18, 8]
[2, 21, 13, 17]
[21, 6, 17, 7]
[6, 13, 7, 15]
[13, 17, 15, 4]
[17, 7, 4, 8]
[7, 15, 8, 24]
[15, 4, 24, 15]
[4, 8, 15, 10]
[13, 11, 10, 2]
[11, 6, 2, 0]
[6, 10, 0, 10]
[10, 2, 10, 24]
[2, 0, 24, 8]
[17, 7, 8, 20]
[7, 6, 20, 11]
[6, 8, 11, 24]
[8, 20, 24, 10]
[20, 11, 10, 18]
[11, 24, 18, 27]
[24, 10, 27, 18]
[6, 2, 29, 0]
[2, 20, 0, 0]
[20, 29, 0, 15]
[29, 0, 15, 0]
[0, 0, 0, 18]
[0, 15, 18, 4]
[15, 0, 4, 0]
在每个list后面加上标签构成pairs,pairs里面就是若干5维的列表:
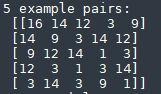
然后开始将数据进行训练:
# 1.定义一个CBOW模型,可以用来训练词向量
class CBOW(keras.Model):
def __init__(self,v_dim,emb_dim):
super().__init__()
self.v_dim = v_dim
self.embeddings = keras.layers.Embedding(
input_dim=v_dim,output_dim=emb_dim,
embeddings_initializer=keras.initializers.RandomNormal(0.,0.1)
) # 词向量就存在于embedding
# noise-contrastive estimation
self.nce_w = self.add_weight(
name="nce_w", shape=[v_dim, emb_dim],
initializer=keras.initializers.TruncatedNormal(0., 0.1)) # [n_vocab, emb_dim]
self.nce_b = self.add_weight(
name="nce_b", shape=(v_dim,),
initializer=keras.initializers.Constant(0.1)) # [n_vocab, ]
self.opt = keras.optimizers.Adam(0.01)
# 前向预测部分call和loss
def call(self, x, training=None, mask=None):
# x.shape = [n, skip_window*2]
o = self.embeddings(x) # [n, skip_window*2, emb_dim]
o = tf.reduce_mean(o, axis=1) # [n, emb_dim]
return o
# negative sampling: take one positive label and num_sampled negative labels to compute the loss
# in order to reduce the computation of full softmax
# 使用nce_loss能够大大加速softmax求loss的方式,在词数很多的时候效果显著,不需要的话用cross_entropy
def loss(self, x, y, training=None):
embedded = self.call(x, training)
return tf.reduce_mean(
tf.nn.nce_loss(
weights=self.nce_w, biases=self.nce_b, labels=tf.expand_dims(y, axis=1),
inputs=embedded, num_sampled=5, num_classes=self.v_dim))
def step(self, x, y):
with tf.GradientTape() as tape:
loss = self.loss(x, y, True)
grads = tape.gradient(loss, self.trainable_variables)
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss.numpy()
完整代码:
# -*- coding: utf-8 -*-
import tensorflow as tf
tf.enable_eager_execution() # 为了解决loss.numpy()报错
import numpy as np
import itertools
from tensorflow import keras
corpus = [
# numbers
"5 2 4 8 6 2 3 6 4",
"4 8 5 6 9 5 5 6",
"1 1 5 2 3 3 8",
"3 6 9 6 8 7 4 6 3",
"8 9 9 6 1 4 3 4",
"1 0 2 0 2 1 3 3 3 3 3",
"9 3 3 0 1 4 7 8",
"9 9 8 5 6 7 1 2 3 0 1 0",
# alphabets, expecting that 9 is close to letters
"a t g q e h 9 u f",
"e q y u o i p s",
"q o 9 p l k j o k k o p",
"h g y i u t t a e q",
"i k d q r e 9 e a d",
"o p d g 9 s a f g a",
"i u y g h k l a s w",
"o l u y a o g f s",
"o p i u y g d a s j d l",
"u k i l o 9 l j s",
"y g i s h k j l f r f",
"i o h n 9 9 d 9 f a 9",
]
# 1.定义一个CBOW模型,可以用来训练词向量
class CBOW(keras.Model):
def __init__(self,v_dim,emb_dim):
super().__init__()
self.v_dim = v_dim
self.embeddings = keras.layers.Embedding(
input_dim=v_dim,output_dim=emb_dim,
embeddings_initializer=keras.initializers.RandomNormal(0.,0.1)
) # 词向量就存在于embedding
# noise-contrastive estimation
self.nce_w = self.add_weight(
name="nce_w", shape=[v_dim, emb_dim],
initializer=keras.initializers.TruncatedNormal(0., 0.1)) # [n_vocab, emb_dim]
self.nce_b = self.add_weight(
name="nce_b", shape=(v_dim,),
initializer=keras.initializers.Constant(0.1)) # [n_vocab, ]
self.opt = keras.optimizers.Adam(0.01)
# 前向预测部分call和loss
def call(self, x, training=None, mask=None):
# x.shape = [n, skip_window*2]
o = self.embeddings(x) # [n, skip_window*2, emb_dim]
o = tf.reduce_mean(o, axis=1) # [n, emb_dim]
return o
# negative sampling: take one positive label and num_sampled negative labels to compute the loss
# in order to reduce the computation of full softmax
# 使用nce_loss能够大大加速softmax求loss的方式,在词数很多的时候效果显著
def loss(self, x, y, training=None):
embedded = self.call(x, training)
return tf.reduce_mean(
tf.nn.nce_loss(
weights=self.nce_w, biases=self.nce_b, labels=tf.expand_dims(y, axis=1),
inputs=embedded, num_sampled=5, num_classes=self.v_dim))
def step(self, x, y):
with tf.GradientTape() as tape:
loss = self.loss(x, y, True)
grads = tape.gradient(loss, self.trainable_variables)
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss.numpy()
# 2.定义训练的函数
def train(model, data):
for t in range(2500):
bx, by = data.sample(8)
loss = model.step(bx, by)
if t % 200 == 0:
print("step: {} | loss: {}".format(t, loss))
class Dataset:
def __init__(self, x, y, v2i, i2v):
self.x, self.y = x, y
self.v2i, self.i2v = v2i, i2v
self.vocab = v2i.keys()
def sample(self, n):
b_idx = np.random.randint(0, len(self.x), n) # 产生随机数
bx, by = self.x[b_idx], self.y[b_idx] # 使顺序打散训练,这样每一次调用,都会产生shuffle的数据
return bx, by
@property
def num_word(self):
return len(self.v2i)
# 3.定义产生训练数据的方法
def process_w2v_data(corpus, skip_window=2, method="skip_gram"):
all_words = [sentence.split(" ") for sentence in corpus]
all_words = np.array(list(itertools.chain(*all_words))) # 连成一条
# vocab sort by decreasing frequency for the negative sampling below (nce_loss).
vocab, v_count = np.unique(all_words, return_counts=True) # 统计有多少种不同的词,以及个数
vocab = vocab[np.argsort(v_count)[::-1]] # 按照个数从多到少排序
print("all vocabularies sorted from more frequent to less frequent:\n", vocab)
v2i = {v: i for i, v in enumerate(vocab)} # 单词即对应的索引,从大到小拍多少号
i2v = {i: v for v, i in v2i.items()} # 从索引找到单词
# pair data
pairs = []
js = [i for i in range(-skip_window, skip_window + 1) if i != 0]
# -2到2一共五个单词,去掉最中间的,窗口大小为5
for c in corpus:
words = c.split(" ")
w_idx = [v2i[w] for w in words] # 把每一行文本的单词都换成索引放在列表里
if method == "skip_gram":
for i in range(len(w_idx)):
for j in js:
if i + j < 0 or i + j >= len(w_idx):
continue
pairs.append((w_idx[i], w_idx[i + j])) # (center, context) or (feature, target)
elif method.lower() == "cbow":
for i in range(skip_window, len(w_idx) - skip_window): # 在这一行列表上开始滑动窗口,每一次滑动都包含5个单词
context = [] # 装每个窗口的五个单词的索引,context里面装的是前后共四个
for j in js:
context.append(w_idx[i + j])
pairs.append(context + [w_idx[i]]) # (contexts, center) or (feature, target)
else:
raise ValueError
pairs = np.array(pairs)
print("5 example pairs:\n", pairs[:5])
if method.lower() == "skip_gram":
x, y = pairs[:, 0], pairs[:, 1]
elif method.lower() == "cbow":
x, y = pairs[:, :-1], pairs[:, -1]
else:
raise ValueError
return Dataset(x, y, v2i, i2v)
if __name__ == "__main__":
d = process_w2v_data(corpus, skip_window=2, method="cbow")
m = CBOW(d.num_word, 2)
train(m, d)
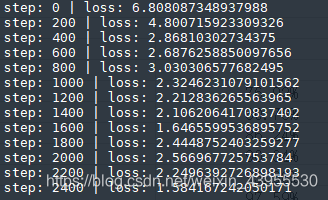
前后文的window不一定要是2,也可以使3,4,使前后文的向量更多
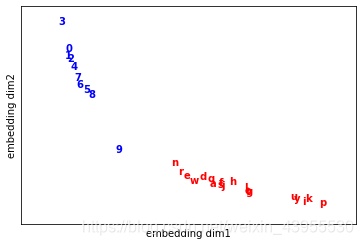
画图显示由词向量表示的词语在空间中的位置:
def show_w2v_word_embedding(model, data: Dataset, path):
"""
传入训练好的产生词向量的模型,传入的数据形式是Dataset类型的
"""
word_emb = model.embeddings.get_weights()[0] # 得到模型参数
for i in range(data.num_word):
c = "blue"
try:
int(data.i2v[i])
except ValueError:
c = "red"
plt.text(word_emb[i, 0], word_emb[i, 1], s=data.i2v[i], color=c, weight="bold")
plt.xlim(word_emb[:, 0].min() - .5, word_emb[:, 0].max() + .5)
plt.ylim(word_emb[:, 1].min() - .5, word_emb[:, 1].max() + .5)
plt.xticks(())
plt.yticks(())
plt.xlabel("embedding dim1")
plt.ylabel("embedding dim2")
# embedding的词向量是很多为的,但是这里取前两维表示一下相应的空间位置
# plt.savefig(path, dpi=300, format="png")
plt.show()
if __name__ == "__main__":
d = process_w2v_data(corpus, skip_window=2, method="cbow")
m = CBOW(d.num_word, 2)
train(m, d)
# plotting
show_w2v_word_embedding(m, d, "./visual/results/cbow.png")
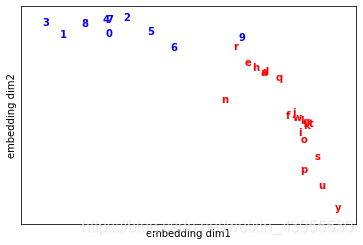
可以看出9这个单词的空间位置离字母和数字都很近,这是因为它在文本中确实离字母和数字都有上下文关系。
句子是由词语组成的, 所以CBOW得到的词向量,可以进一步扔进一个RNN网络得到句子的整个含义。
Skip-Gram
skip-Gram的训练方法与CBOW非常相似,不同的是,它是以中间的词去预测上下文
输入[‘爱’]
输出[‘我’][‘中国’]
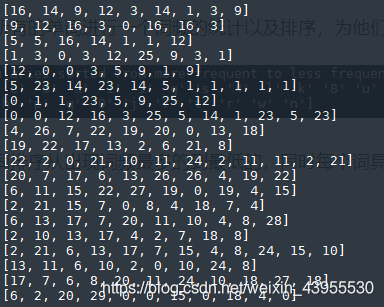
那这里的产生数据就变成了,中间哪一个词维特征,前后两个距离内的词都是标签,如下
# 3.定义产生训练数据的方法
def process_w2v_data(corpus, skip_window=2, method="skip_gram"):
all_words = [sentence.split(" ") for sentence in corpus]
all_words = np.array(list(itertools.chain(*all_words))) # 连成一条
# vocab sort by decreasing frequency for the negative sampling below (nce_loss).
vocab, v_count = np.unique(all_words, return_counts=True) # 统计有多少种不同的词,以及个数
vocab = vocab[np.argsort(v_count)[::-1]] # 按照个数从多到少排序
print("all vocabularies sorted from more frequent to less frequent:\n", vocab)
v2i = {v: i for i, v in enumerate(vocab)} # 单词即对应的索引,从大到小拍多少号
i2v = {i: v for v, i in v2i.items()} # 从索引找到单词
# pair data
pairs = []
js = [i for i in range(-skip_window, skip_window + 1) if i != 0]
# -2到2一共五个单词,去掉最中间的,窗口大小为5
for c in corpus:
words = c.split(" ")
w_idx = [v2i[w] for w in words] # 把每一行文本的单词都换成索引放在列表里
if method == "skip_gram":
for i in range(len(w_idx)):
for j in js:
if i + j < 0 or i + j >= len(w_idx):
continue
pairs.append((w_idx[i], w_idx[i + j])) # (center, context) or (feature, target)
elif method.lower() == "cbow":
for i in range(skip_window, len(w_idx) - skip_window): # 在这一行列表上开始滑动窗口,每一次华东都包含5个单词
context = [] # 装每个窗口的五个单词的索引,context里面装的是前后共四个
for j in js:
context.append(w_idx[i + j])
pairs.append(context + [w_idx[i]]) # (contexts, center) or (feature, target)
else:
raise ValueError
pairs = np.array(pairs)
# print(pairs)
print("5 example pairs:\n", pairs[:20])
if method.lower() == "skip_gram":
x, y = pairs[:, 0], pairs[:, 1]
elif method.lower() == "cbow":
x, y = pairs[:, :-1], pairs[:, -1]
else:
raise ValueError
return Dataset(x, y, v2i, i2v)
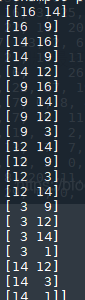
输入时16,输出有两种可能14,9;输入是14时,输出有三种16,9,12;输入时9时,输出有四种16,14,12,3.
定义一个可以训练的Skip-Gram模型
# 1.构造模型
class SkipGram(keras.Model):
def __init__(self, v_dim, emb_dim):
super().__init__()
self.v_dim = v_dim
self.embeddings = keras.layers.Embedding(
input_dim=v_dim, output_dim=emb_dim, # [n_vocab, emb_dim]
embeddings_initializer=keras.initializers.RandomNormal(0., 0.1),
) #
# noise-contrastive estimation
self.nce_w = self.add_weight(
name="nce_w", shape=[v_dim, emb_dim],
initializer=keras.initializers.TruncatedNormal(0., 0.1)) # [n_vocab, emb_dim]
self.nce_b = self.add_weight(
name="nce_b", shape=(v_dim,),
initializer=keras.initializers.Constant(0.1)) # [n_vocab, ]
self.opt = keras.optimizers.Adam(0.01)
def call(self, x, training=None, mask=None):
# x.shape = [n, ]
o = self.embeddings(x) # [n, emb_dim] Skip-Gram 的前向,比CBOW的前向更简单了,只有一个取embedding的过程
return o
# negative sampling: take one positive label and num_sampled negative labels to compute the loss
# in order to reduce the computation of full softmax
def loss(self, x, y, training=None):
embedded = self.call(x, training)
return tf.reduce_mean(
tf.nn.nce_loss(
weights=self.nce_w, biases=self.nce_b, labels=tf.expand_dims(y, axis=1),
inputs=embedded, num_sampled=5, num_classes=self.v_dim))
def step(self, x, y):
with tf.GradientTape() as tape:
loss = self.loss(x, y, True)
grads = tape.gradient(loss, self.trainable_variables)
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss.numpy()
完整代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Apr 28 11:28:18 2021
@author: zhongxi
"""
# -*- coding: utf-8 -*-
import tensorflow as tf
tf.enable_eager_execution() # 为了解决loss.numpy()报错
import numpy as np
import itertools
from tensorflow import keras
import matplotlib.pyplot as plt
corpus = [
# numbers
"5 2 4 8 6 2 3 6 4",
"4 8 5 6 9 5 5 6",
"1 1 5 2 3 3 8",
"3 6 9 6 8 7 4 6 3",
"8 9 9 6 1 4 3 4",
"1 0 2 0 2 1 3 3 3 3 3",
"9 3 3 0 1 4 7 8",
"9 9 8 5 6 7 1 2 3 0 1 0",
# alphabets, expecting that 9 is close to letters
"a t g q e h 9 u f",
"e q y u o i p s",
"q o 9 p l k j o k k o p",
"h g y i u t t a e q",
"i k d q r e 9 e a d",
"o p d g 9 s a f g a",
"i u y g h k l a s w",
"o l u y a o g f s",
"o p i u y g d a s j d l",
"u k i l o 9 l j s",
"y g i s h k j l f r f",
"i o h n 9 9 d 9 f a 9",
]
# 1.构造模型
class SkipGram(keras.Model):
def __init__(self, v_dim, emb_dim):
super().__init__()
self.v_dim = v_dim
self.embeddings = keras.layers.Embedding(
input_dim=v_dim, output_dim=emb_dim, # [n_vocab, emb_dim]
embeddings_initializer=keras.initializers.RandomNormal(0., 0.1),
) #
# noise-contrastive estimation
self.nce_w = self.add_weight(
name="nce_w", shape=[v_dim, emb_dim],
initializer=keras.initializers.TruncatedNormal(0., 0.1)) # [n_vocab, emb_dim]
self.nce_b = self.add_weight(
name="nce_b", shape=(v_dim,),
initializer=keras.initializers.Constant(0.1)) # [n_vocab, ]
self.opt = keras.optimizers.Adam(0.01)
def call(self, x, training=None, mask=None):
# x.shape = [n, ]
o = self.embeddings(x) # [n, emb_dim] Skip-Gram 的前向,比CBOW的前向更简单了,只有一个取embedding的过程
return o
# negative sampling: take one positive label and num_sampled negative labels to compute the loss
# in order to reduce the computation of full softmax
def loss(self, x, y, training=None):
embedded = self.call(x, training)
return tf.reduce_mean(
tf.nn.nce_loss(
weights=self.nce_w, biases=self.nce_b, labels=tf.expand_dims(y, axis=1),
inputs=embedded, num_sampled=5, num_classes=self.v_dim))
def step(self, x, y):
with tf.GradientTape() as tape:
loss = self.loss(x, y, True)
grads = tape.gradient(loss, self.trainable_variables)
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss.numpy()
# 2.训练模型
def train(model, data):
for t in range(2500):
bx, by = data.sample(8)
loss = model.step(bx, by)
if t % 200 == 0:
print("step: {} | loss: {}".format(t, loss))
class Dataset:
def __init__(self, x, y, v2i, i2v):
self.x, self.y = x, y
self.v2i, self.i2v = v2i, i2v
self.vocab = v2i.keys()
def sample(self, n):
b_idx = np.random.randint(0, len(self.x), n) # 产生随机数
bx, by = self.x[b_idx], self.y[b_idx] # 使顺序打散训练,这样每一次调用,都会产生shuffle的数据
return bx, by
@property
def num_word(self):
return len(self.v2i)
# 3.定义产生训练数据的方法
def process_w2v_data(corpus, skip_window=2, method="skip_gram"):
all_words = [sentence.split(" ") for sentence in corpus]
all_words = np.array(list(itertools.chain(*all_words))) # 连成一条
# vocab sort by decreasing frequency for the negative sampling below (nce_loss).
vocab, v_count = np.unique(all_words, return_counts=True) # 统计有多少种不同的词,以及个数
vocab = vocab[np.argsort(v_count)[::-1]] # 按照个数从多到少排序
print("all vocabularies sorted from more frequent to less frequent:\n", vocab)
v2i = {v: i for i, v in enumerate(vocab)} # 单词即对应的索引,从大到小拍多少号
i2v = {i: v for v, i in v2i.items()} # 从索引找到单词
# pair data
pairs = []
js = [i for i in range(-skip_window, skip_window + 1) if i != 0]
# -2到2一共五个单词,去掉最中间的,窗口大小为5
for c in corpus:
words = c.split(" ")
w_idx = [v2i[w] for w in words] # 把每一行文本的单词都换成索引放在列表里
if method == "skip_gram":
for i in range(len(w_idx)):
for j in js:
if i + j < 0 or i + j >= len(w_idx):
continue
pairs.append((w_idx[i], w_idx[i + j])) # (center, context) or (feature, target)
elif method.lower() == "cbow":
for i in range(skip_window, len(w_idx) - skip_window): # 在这一行列表上开始滑动窗口,每一次华东都包含5个单词
context = [] # 装每个窗口的五个单词的索引,context里面装的是前后共四个
for j in js:
context.append(w_idx[i + j])
pairs.append(context + [w_idx[i]]) # (contexts, center) or (feature, target)
else:
raise ValueError
pairs = np.array(pairs)
# print(pairs)
print("5 example pairs:\n", pairs[:20])
if method.lower() == "skip_gram":
x, y = pairs[:, 0], pairs[:, 1]
elif method.lower() == "cbow":
x, y = pairs[:, :-1], pairs[:, -1]
else:
raise ValueError
return Dataset(x, y, v2i, i2v)
#4.显示数据
def show_w2v_word_embedding(model, data: Dataset, path):
"""
传入训练好的产生词向量的模型,传入的数据形式是Dataset类型的
"""
word_emb = model.embeddings.get_weights()[0] # 得到模型参数
for i in range(data.num_word):
c = "blue"
try:
int(data.i2v[i])
except ValueError:
c = "red"
plt.text(word_emb[i, 0], word_emb[i, 1], s=data.i2v[i], color=c, weight="bold")
plt.xlim(word_emb[:, 0].min() - .5, word_emb[:, 0].max() + .5)
plt.ylim(word_emb[:, 1].min() - .5, word_emb[:, 1].max() + .5)
plt.xticks(())
plt.yticks(())
plt.xlabel("embedding dim1")
plt.ylabel("embedding dim2")
# embedding的词向量是很多为的,但是这里取前两维表示一下相应的空间位置
# plt.savefig(path, dpi=300, format="png")
plt.show()
if __name__ == "__main__":
d = process_w2v_data(corpus, skip_window=2, method="skip_gram")
m = SkipGram(d.num_word, 2)
train(m, d)
# plotting
show_w2v_word_embedding(m, d, "./visual/results/skipgram.png")














 5858
5858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









