







拿到餐饮日销额数据的excel表
1.首先进行异常值分析:
import pandas as pd
catering_sale = 'catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
#print(data)
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure() #建立图像
p = data.boxplot(return_type='dict') #画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序,该方法直接改变原对象
#plt.show()
#print(x) #得出异常值的列数
#print(y) #得出异常值的行数
#用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱线图
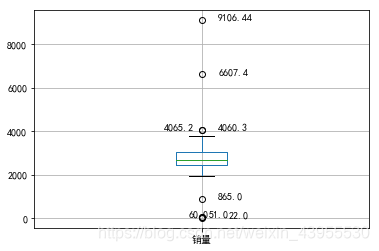
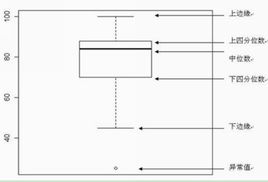
- 箱型图识别异常值标准: 异常值被定义为大于QU+1.5IQRQU+1.5IQR或小于QL−1.5IQRQL−1.5IQR的值。QUQU是上四分位数,表示全部观察值中有1/4的数据比他大,QLQL是下四分位数,表示全部数据中有1/4的数据比他小。IQR是四分位间距,是QUQU和QLQL的差,其间包含了观察值的一半。
2.对异常值处理后的数据集做统计量分析:
- *describe()*函数能算出数据集的八个统计量
from __future__ import print_function #必须放在所有代码的最开头位置
import pandas as pd
catering_sale = 'catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
data = data[(data[u'销量'] > 400)&(data[u'销量'] < 5000)] #过滤异常数据
statistics = data.describe() #保存基本统计量
statistics.loc['range'] = statistics.loc['max']-statistics.loc['min'] #极差
statistics.loc['var'] = statistics.loc['std']/statistics.loc['mean'] #变异系数
statistics.loc['dis'] = statistics.loc['75%']-statistics.loc['25%'] #四分位数间距
print(statistics)
这里from _ future _ import print_function这条语句是说在python2.7下也必须要使用python3的print格式,无关紧要,要用的话记得置首

describe()已经能得到八个统计量,后面三个是之后加算的
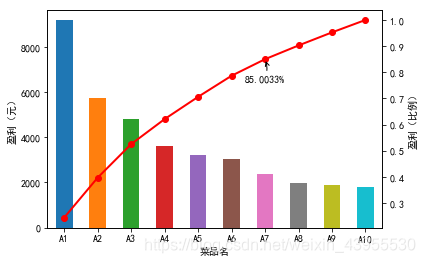
3.对菜品盈利数据进行贡献度分析
帕累托图代码:
from __future__ import print_function
import pandas as pd
#初始化参数
dish_profit = 'catering_dish_profit.xls' #餐饮菜品盈利数据
data = pd.read_excel(dish_profit, index_col = u'菜品名')
print(data)
data = data['盈利'].copy()
print(data)
a = data.sort_values(ascending = False)#False表示按照从大到小的顺序排列
print(data)
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure()
data.plot(kind='bar')
plt.ylabel(u'盈利(元)') #对第一个y轴直接标注
p = 1.0*data.cumsum()/data.sum()
p.plot(color = 'r', secondary_y = True, style = '-o',linewidth = 2)
#secondary_y参数表示是否对第二个y轴的标注
plt.annotate(format(p[6], '.4%'), xy = (6, p[6]), xytext=(6*0.9, p[6]*0.9), arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))
#添加注释,即85%处的标记。这里包括了指定箭头样式。
plt.ylabel(u'盈利(比例)')
plt.show()
p = 1.0*data.cumsum()/data.sum()
data.cumsum()表示累加
x=np.arange(101)
y=x.cumsum()
print y
print len(y)
得到:
[ 0 1 3 6 10 15 21 28 36 45 55 66 78 91 105
120 136 153 171 190 210 231 253 276 300 325 351 378 406 435
465 496 528 561 595 630 666 703 741 780 820 861 903 946 990
1035 1081 1128 1176 1225 1275 1326 1378 1431 1485 1540 1596 1653 1711 1770
1830 1891 1953 2016 2080 2145 2211 2278 2346 2415 2485 2556 2628 2701 2775
2850 2926 3003 3081 3160 3240 3321 3403 3486 3570 3655 3741 3828 3916 4005
4095 4186 4278 4371 4465 4560 4656 4753 4851 4950 5050]
4.根据菜品日销售数据分析菜品之间的相关性
即求任意两菜品的相关系数
from __future__ import print_function
import pandas as pd
catering_sale = 'catering_sale_all.xls' #餐饮数据,含有其他属性
data = pd.read_excel(catering_sale, index_col = '日期') #读取数据,指定“日期”列为索引列
#print(data)
a = data.corr() #相关系数矩阵,即给出了任意两款菜式之间的相关系数
b = data.corr()[u'百合酱蒸凤爪'] #只显示“百合酱蒸凤爪”与其他菜式的相关系数
c = data[u'百合酱蒸凤爪'].corr(data[u'翡翠蒸香茜饺']) #计算“百合酱蒸凤爪”与“翡翠蒸香茜饺”的相关系数
print(a)
print(c)
print(b)
相关系数越高,说明两者一起购买的可能性越大

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









