







现在做stacking的思想,对两个预测结果做一个融合
1.分别得出预测数据
作死的我刚开始只处理了训练数据,没有处理测试数据,现在对测试数据进行处理:
test_data['MSSubClass'] = test_data['MSSubClass'].astype(str)
dummy_test = pd.get_dummies(test_data)
然后我发现dummy_test在dummy之后只有285列,要说少一个‘SalePrice’也不至于少了这么多列吧,然后我检测了少了那系列,发现少了这些:
SalePrice
Utilities_NoSeWa
Condition2_RRAe
Condition2_RRAn
Condition2_RRNn
HouseStyle_2.5Fin
RoofMatl_ClyTile
RoofMatl_Membran
RoofMatl_Metal
RoofMatl_Roll
Exterior1st_ImStucc
Exterior1st_Stone
Exterior2nd_Other
Heating_Floor
Heating_OthW
Electrical_Mix
GarageQual_Ex
PoolQC_Fa
MiscFeature_TenC
除了SalePrice,还有这些列都是只特定存在于训练集中的,在测试集中可能没有出现这样的类别,所以dummy也没有分出这样的属性,所以还是安安分分一起处理,再分开测试集和训练集吧
import numpy as np
import pandas as pd
train_data = pd.read_csv('E:/机器学习/my_code_kaggle/lesson2/input/train.csv',index_col = 0)
test_data = pd.read_csv('E:/机器学习/my_code_kaggle/lesson2/input/test.csv',index_col = 0)
y_train = train_data['SalePrice']
X_train = train_data.drop(['SalePrice'],axis = 1)
#判断平滑性
#y_train.hist()
#发现平滑性不怎么样,最好分布图类似于一个正态分布就比较好
y_train_log = np.log1p(y_train)
#y_train_log.hist()
#把数据拼接在一起处理
data = pd.concat((X_train,test_data),axis = 0)
#MSSubClass属性的数值无意义,作为类别标签看待,转为字符串
#MSSubClass是Categorical类型,用One-Hot的方法来表示
#pandas自带get_dummies方法,一键做到One-Hot
data['MSSubClass'] = data['MSSubClass'].astype(str)
#print(data['MSSubClass'].value_counts())
#把MSSubClass换成字符串标签了之后,就和其他的英文分类差不多了,直接dummy
dummy_data = pd.get_dummies(data)#属性由79个变成了302个,1460*303
#查看各个属性缺失值的个数,用平均值填补缺失值
#print(dummy_train.isnull().sum().sort_values(ascending = False).head(10))
mean_cols = dummy_data.mean()
dummy_data = dummy_data.fillna(mean_cols)#用mean_cols来填满空缺值
#print(dummy_data.isnull().sum().sum())#确定没有空缺值了
#做regression的时候最好先标准化一下
#标准化numerical类型数据,不是One-Hot变成的numerical
numeric_cols = data.columns[data.dtypes != 'object']
#print(numeric_cols)#len(numeric_cols) = 36
numeric_col_means = dummy_data.loc[:,numeric_cols].mean()
numeric_col_std = dummy_data.loc[:,numeric_cols].std()
dummy_data.loc[:,numeric_cols] = (dummy_data.loc[:,numeric_cols]-numeric_col_means)/numeric_col_std
#合在一起处理完特征之后,分开测试集和训练集
dummy_train = dummy_data.loc[train_data.index,:]
dummy_test = dummy_data.loc[test_data.index,:]
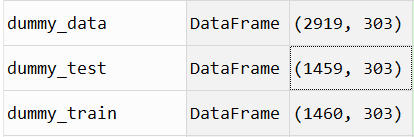
完美!
之前有得出ridge的参数设为alpha设为15,random forest参数设为max_feature = 0.3
#分别建立两个模型
from sklearn import linear_model
ridge = linear_model.Ridge(alpha = 15)
ridge.fit(dummy_train,y_train_log)
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators = 200,max_features = 0.3)
rf.fit(dummy_train,y_train_log)
#用两个模型进行预测
y_ridge_pre = ridge.predict(dummy_test)
y_rf_pre = ridge.predict(dummy_test)
2.Stacking模型融合
有了两种模型做出的判断,我们可以融合两种模型的判断,简单的处理方法,直接把两种模型的出的regression结果取平均值
#融合,简单的融合,直接取平均值
y_pre = (np.expm1(y_ridge_pre) + np.expm1(y_rf_pre))/2
print(y_pre)
#提交结果
submission_df = pd.DataFrame(data = {'Id':test_data.index,'SalePrice':y_pre})















 5110
5110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









