







Flink安装部署和案例使用
Flink支持多种安装模式
- Local—本地单机模式,学习测试时使用
- Standalone—独立集群模式,Flink自带集群,开发测试环境使用
- StandaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用
- On Yarn—计算资源统一由Hadoop YARN管理,生产环境使用
1. Local本地模式
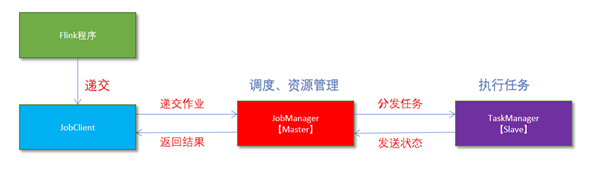
- Flink程序由JobClient进行提交。
- JobClient将作业提交给JobManager。
- JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的TaskManager。
- TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改,如开始执行,正在进行或已完成。
- 作业执行完成后,结果将发送回客户端(JobClient)。
操作
1.下载安装包
下载地址
2.上传flink-1.12.2-bin-scala_2.12.tgz到mnode1的指定目录Downloads
3.解压
sudo tar -zxvf ~/Downloads/flink-1.12.2-bin-scala_2.12.tgz -C /usr/local/
4.如果出现权限问题,需要修改权限
sudo chown -R hadoop:hadoop /usr/local/flink-1.12.2
5.改名或创建软链接
sudo mv flink-1.12.0 flink
sudo ln -s /usr/local/flink-1.12.0 /usr/local/flink
测试
1.准备文件 /home/hadoop/words.txt
vim /home/hadoop/words.txt
hello me you her
hello me you
hello me
hello
2.启动Flink本地“集群”
/usr/local/flink/bin/start-cluster.sh
3.使用jps可以查看到下面两个进程
- TaskManagerRunner
- StandaloneSessionClusterEntrypoint
4.访问Flink的Web UI
http://mnode1:8081/#/overview

slot在Flink里面可以认为是资源组,Flink是通过将任务分成子任务并且将这些子任务分配到slot来并行执行程序。
5.执行官方示例
/usr/local/flink/bin/flink run /usr/local/flink/examples/batch/WordCount.jar --input /home/hadoop/words.txt --output /home/hadoop/out
6.停止Flink
/usr/local/flink/bin/stop-cluster.sh
启动shell交互式窗口(目前所有Scala 2.12版本的安装包暂时都不支持 Scala Shell)
/usr/local/flink/bin/start-scala-shell.sh local
执行如下命令
benv.readTextFile("/home/hadoop/words.txt").flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1).print()
退出shell
:quit
2. Standalone独立集群模式
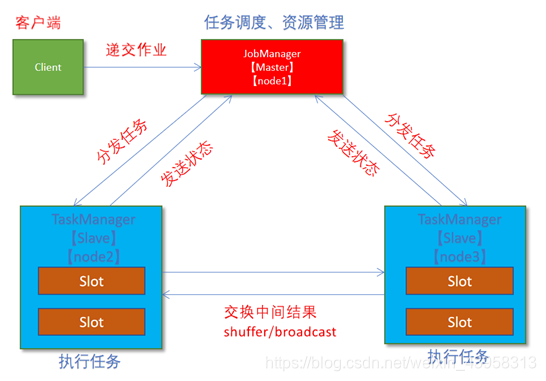
- client客户端提交任务给JobManager
- JobManager负责申请任务运行所需要的资源并管理任务和资源,
- JobManager分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
1.集群规划:
- 服务器: mnode1(Master + Slave): JobManager + TaskManager
- 服务器: wnode2(Slave): TaskManager
2.修改flink-conf.yaml
vim /usr/local/flink/conf/flink-conf.yaml
jobmanager.rpc.address: mnode1
taskmanager.numberOfTaskSlots: 2
web.submit.enable: true
历史服务器
jobmanager.archive.fs.dir: hdfs://mnode1:9000/flink/completed-jobs/
historyserver.web.address: mnode1
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://mnode1:9000/flink/completed-jobs/
2.修改masters
vim /usr/local/flink/conf/masters
mnode1:8081
3.修改slaves
vim /usr/local/flink/conf/workers
mnode1
mnode2
4.添加HADOOP_CONF_DIR环境变量
vim ~/.bashrc
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
5.分发
scp -r /usr/local/flink mnode2:/usr/local/flink
scp ~/.bashrc mnode2: ~/.bashrc
6.source
source ~/.bashrc
测试
1.启动集群,在mnode1上执行如下命令
/usr/local/flink/bin/start-cluster.sh
2.启动历史服务器
/usr/local/flink/bin/historyserver.sh start
注意:第一次启动时会报错,因为缺少连接Hadoop的jar包,需要将flink-shaded-hadoop-3-uber-3.1.1.7.1.1.0-565-9.0.jar包上传到flink/lib目录。
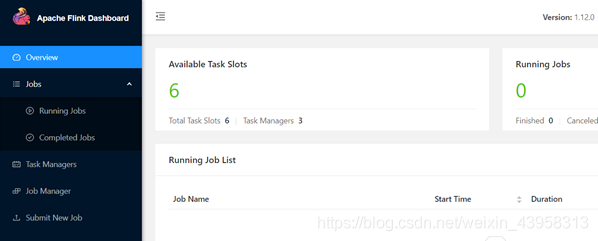
3.访问Flink UI界面或使用jps查看
http://mnode1:8081/#/overview
http://mnode1:8082/#/overview
TaskManager界面:可以查看到当前Flink集群中有多少个TaskManager,每个TaskManager的slots、内存、CPU Core是多少
4.执行官方测试案例
上传words.txt到hdfs目录,命令如下:
hdfs dfs -mkdir -p /flink/example/wordcount/input
hdfs dfs -put /home/hadoop/words.txt /flink/example/wordcount/input
/usr/local/flink/bin/flink run /usr/local/flink/examples/batch/WordCount.jar --input hdfs://mnode1:9000/flink/example/wordcount/input/words.txt --output hdfs://mnode1:9000/flink/example/wordcount/output/result.txt --parallelism 2
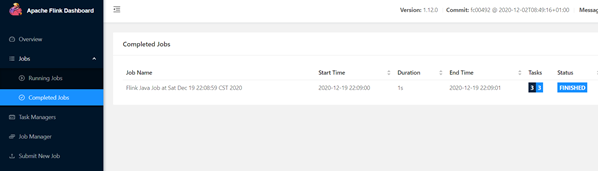
5.查看历史日志
http://mnode1:50070/explorer.html#/flink/completed-jobs
http://mnode1:8082/#/overview
6.停止Flink集群
/usr/local/flink/bin/stop-cluster.sh
3. Standalone-HA高可用集群模式

从之前的架构中我们可以很明显的发现 JobManager 有明显的单点问题(SPOF,single point of failure)。JobManager 肩负着任务调度以及资源分配,一旦 JobManager 出现意外,其后果可想而知。
在 Zookeeper 的帮助下,一个 Standalone的Flink集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选一个新的 JobManager 来接管 Flink 集群。
操作
1.集群规划
- 服务器: mnode1(Master + Slave): JobManager + TaskManager
- 服务器: mnode2(Master + Slave): JobManager + TaskManager
2.启动ZooKeeper
zkServer.sh status
zkServer.sh stop
zkServer.sh start
3.启动HDFS
/usr/local/hadoop/sbin/start-dfs.sh
4.停止Flink集群
/usr/local/flink/bin/stop-cluster.sh
5.修改flink-conf.yaml
vim /usr/local/flink/conf/flink-conf.yaml
增加如下内容:
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://mnode1:9000/flink/flink-checkpoints
high-availability: zookeeper
high-availability.storageDir: hdfs://mnode1:9000/flink/ha/
high-availability.zookeeper.quorum: mnode1:2181,mnode2:2181
配置解释
#开启HA,使用文件系统作为快照存储
state.backend: filesystem
#启用检查点,可以将快照保存到HDFS
state.backend.fs.checkpointdir: hdfs://mnode1:9000/flink/flink-checkpoints
#使用zookeeper搭建高可用
high-availability: zookeeper
#存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://mnode1:9000/flink/ha/
#配置ZK集群地址
high-availability.zookeeper.quorum: mnode1:2181,mnode2:2181
6.修改masters
vim /usr/local/flink/conf/masters
mnode1:8081
mnode2:8081
7.同步
scp -r /usr/local/flink/conf/flink-conf.yaml mnode2:/usr/local/flink/conf/
scp -r /usr/local/flink/conf/flink-conf.yaml mnode3:/usr/local/flink/conf/
scp -r /usr/local/flink/conf/masters mnode2:/usr/local/flink/conf/
scp -r /usr/local/flink/conf/masters mnode3:/usr/local/flink/conf/
8.修改node2上的flink-conf.yaml
vim /usr/local/flink/conf/flink-conf.yaml
jobmanager.rpc.address: mnode2
9.重新启动Flink集群,node1上执行
/usr/local/flink/bin/stop-cluster.sh
/usr/local/flink/bin/start-cluster.sh

10.使用jps命令查看
发现没有Flink相关进程被启动
11.查看日志
cat /usr/local/flink/log/flink-root-standalonesession-0-node1.log
发现如下错误

因为在Flink1.8版本后,Flink官方提供的安装包里没有整合HDFS的jar
12.下载jar包并在Flink的lib目录下放入该jar包并分发使Flink能够支持对Hadoop的操作
下载地址
放入lib目录
cd /usr/local/flink/lib
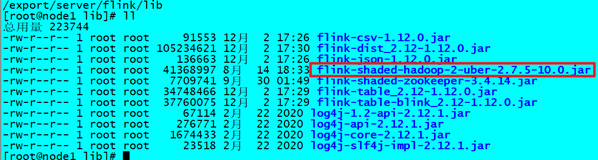
分发
for i in {2..3}; do scp -r flink-shaded-hadoop-2-uber-2.7.5-10.0.jar mnode$i:$PWD; done
13.重新启动Flink集群,mnode1上执行
/usr/local/flink/bin/start-cluster.sh
14.使用jps命令查看,发现三台机器已经ok
测试
1.访问WebUI
http://mnode1:8081/#/job-manager/config
http://mnode2:8081/#/job-manager/config
2.执行wc
/usr/local/flink/bin/flink run /usr/local/flink/examples/batch/WordCount.jar
3.kill掉其中一个master
4.重新执行wc,还是可以正常执行
/usr/local/flink/bin/flink run /usr/local/flink/examples/batch/WordCount.jar
3.停止集群
/usr/local/flink/bin/stop-cluster.sh
4. Flink On Yarn模式
原理
为什么使用Flink On Yarn?
在实际开发中,使用Flink时,更多的使用方式是Flink On Yarn模式,原因如下:
1.Yarn的资源可以按需使用,提高集群的资源利用率
2.Yarn的任务有优先级,根据优先级运行作业
3.基于Yarn调度系统,能够自动化地处理各个角色的 Failover(容错)
○ JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控
○ 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器
○ 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager
Flink如何和Yarn进行交互?
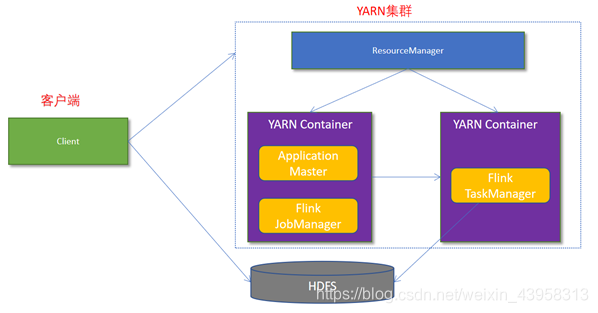

1.Client上传jar包和配置文件到HDFS集群上
2.Client向Yarn ResourceManager提交任务并申请资源
3.ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager。
JobManager和ApplicationMaster运行在同一个container上。
一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。
它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。
这个配置文件也被上传到HDFS上。
此外,AppMaster容器也提供了Flink的web服务接口。
YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink
4.ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
5.TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
两种方式
Session模式

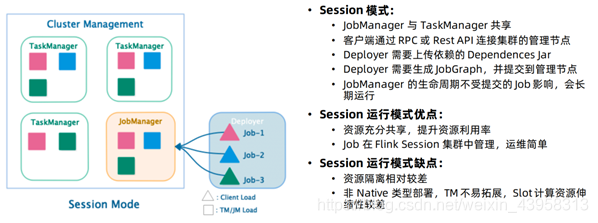
特点:需要事先申请资源,启动JobManager和TaskManger
优点:不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源
应用场景:适合作业递交比较频繁的场景,小作业比较多的场景
Per-Job模式
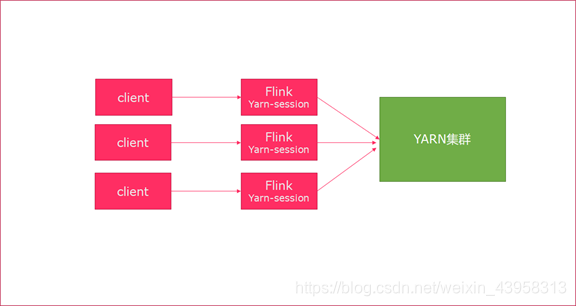
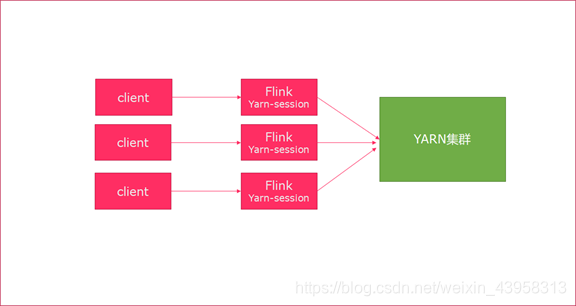
特点:每次递交作业都需要申请一次资源
优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源
缺点:每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间
应用场景:适合作业比较少的场景、大作业的场景
操作
1.关闭yarn的内存检查
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
添加:
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
说明:
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
在这里面我们需要关闭,因为对于flink使用yarn模式下,很容易内存超标,这个时候yarn会自动杀掉job
2.同步
scp -r /usr/local/hadoop/etc/hadoop/yarn-site.xml mnode2:/usr/local/hadoop/etc/hadoop/yarn-site.xml
scp -r /usr/local/hadoop/etc/hadoop/yarn-site.xml mnode3:/usr/local/hadoop/etc/hadoop/yarn-site.xml
3.重启yarn
/usr/local/hadoop/sbin/stop-yarn.sh
/usr/local/hadoop/sbin/start-yarn.sh
测试
Session模式
yarn-session.sh(开辟资源) + flink run(提交任务)
1.在yarn上启动一个Flink会话,mnode1上执行以下命令
/usr/local/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
说明:
申请2个CPU、1600M内存
#-n 表示申请2个容器,这里指的就是多少个taskmanager
#-tm 表示每个TaskManager的内存大小
-s 表示每个TaskManager的slots数量
-d 表示以后台程序方式运行
注意:
该警告不用管
WARN org.apache.hadoop.hdfs.DFSClient - Caught exception
java.lang.InterruptedException
2.查看UI界面
http://mnode1:8088/cluster
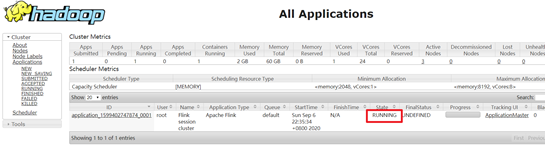
3.使用flink run提交任务:
/usr/local/flink/bin/flink run /usr/local/flink/examples/batch/WordCount.jar
运行完之后可以继续运行其他的小任务
/usr/local/flink/bin/flink run /usr/local/flink/examples/batch/WordCount.jar
4.通过上方的ApplicationMaster可以进入Flink的管理界面
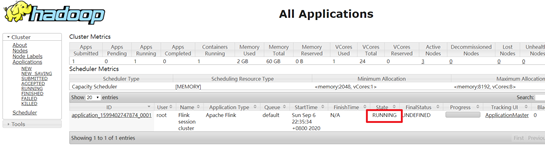
5.关闭yarn-session:
yarn application -kill application_1599402747874_0001
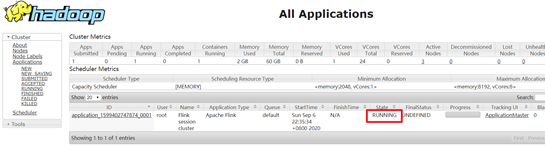
rm -rf /tmp/.yarn-properties-hadoop
Per-Job分离模式
1.直接提交job
/usr/local/flink/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 /usr/local/flink/examples/batch/WordCount.jar
-m jobmanager的地址
-yjm 1024 指定jobmanager的内存信息
-ytm 1024 指定taskmanager的内存信息
2.查看UI界面
http://node1:8088/cluster
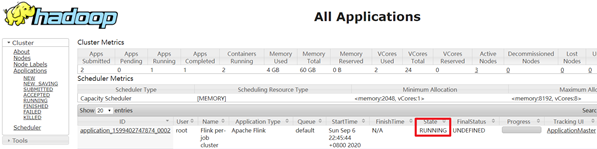
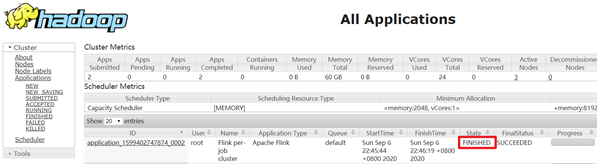
3.注意:
在之前版本中如果使用的是flink on yarn方式,想切换回standalone模式的话,如果报错需要删除:【/tmp/.yarn-properties-root】
rm -rf /tmp/.yarn-properties-root
rm -rf /tmp/.yarn-properties-hadoop
因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
5.Flink入门案例
前置说明
Flink提供了多个层次的API供开发者使用,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大
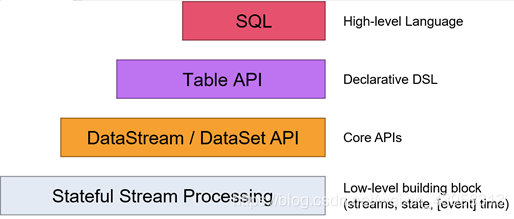
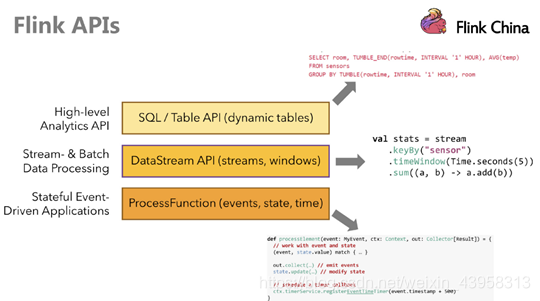
注意:在Flink1.12时支持流批一体,DataSetAPI已经不推荐使用了。
编程模型
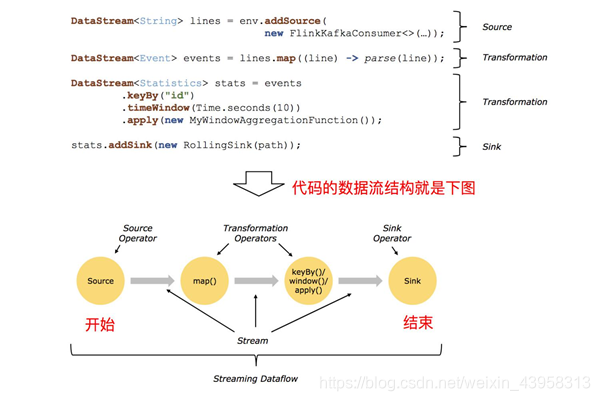
Flink 应用程序结构主要包含三部分,Source/Transformation/Sink,如下图所示:

准备工程
<?xml version="1.0" encoding="UTF-8"?>
4.0.0
<groupId>com.nhbd.flink</groupId>
<artifactId>flink_study</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 指定仓库位置,依次为aliyun、apache和cloudera仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>apache</id>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.12.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink执行计划,这是1.9版本之前的-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- blink执行计划,1.11+默认的-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_2.12</artifactId>
<version>${flink.version}</version>
</dependency>-->
<!-- flink连接器-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.12</artifactId>
<version>${flink.version}</version>
</dependency>-->
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.12</artifactId>
<version>${flink.version}</version>
</dependency>-->
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.12</artifactId>
<version>${flink.version}</version>
</dependency>-->
<!--<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.10.0</version>
</dependency>-->
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
<exclusions>
<exclusion>
<artifactId>flink-streaming-java_2.11</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-runtime_2.11</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-core</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
<exclusion>
<artifactId>flink-java</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
<!--<version>8.0.20</version>-->
</dependency>
<!-- 高性能异步组件:Vertx-->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>3.9.0</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-jdbc-client</artifactId>
<version>3.9.0</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-redis-client</artifactId>
<version>3.9.0</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.44</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<scope>provided</scope>
</dependency>
<!-- 参考:https://blog.csdn.net/f641385712/article/details/84109098-->
<!--<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>-->
<!--<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libfb303</artifactId>
<version>0.9.3</version>
<type>pom</type>
<scope>provided</scope>
</dependency>-->
<!--<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>-->
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<!--<encoding>${project.build.sourceEncoding}</encoding>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<!-- 打包插件(会包含所有依赖) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<!--
zip -d learn_spark.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF -->
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- 设置jar包的入口类(可选) -->
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
log4j.properties
log4j.rootLogger=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
编码步骤
1.准备环境-env
2.准备数据-source
3.处理数据-transformation
4.输出结果-sink
5.触发执行-execute

基于DataSet
package com.nhbd.flink.ch1.example;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* Desc
* 需求:使用Flink完成WordCount-DataSet
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute//如果有print,DataSet不需要调用execute,DataStream需要调用execute
*/
public class WordCount4DataSet {
public static void main(String[] args) throws Exception {
//老版本的批处理API如下,但已经不推荐使用了
//1.准备环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2.准备数据-source
DataSet<String> lineDS = env.fromElements("nhbd hadoop spark","nhbd hadoop spark","nhbd hadoop","nhbd");
//3.处理数据-transformation
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
/*
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
DataSet<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是一行行的数据
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//将切割处理的一个个的单词收集起来并返回
}
}
});
//3.2对集合中的每个单词记为1
/*
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
DataSet<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是进来一个个的单词
return Tuple2.of(value, 1);
}
});
//3.3对数据按照单词(key)进行分组
//0表示按照tuple中的索引为0的字段,也就是key(单词)进行分组
UnsortedGrouping<Tuple2<String, Integer>> groupedDS = wordAndOnesDS.groupBy(0);
//3.4对各个组内的数据按照数量(value)进行聚合就是求sum
//1表示按照tuple中的索引为1的字段也就是按照数量进行聚合累加!
DataSet<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
//3.5排序
DataSet<Tuple2<String, Integer>> result = aggResult.sortPartition(1, Order.DESCENDING).setParallelism(1);
//4.输出结果-sink
result.print();
//5.触发执行-execute//如果有print,DataSet不需要调用execute,DataStream需要调用execute
//env.execute();//'execute()', 'count()', 'collect()', or 'print()'.
}
}
基于DataStream
package com.nhbd.flink.ch1.example;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Desc
* 需求:使用Flink完成WordCount-DataStream
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute
*/
public class WordCount4DataStream {
public static void main(String[] args) throws Exception {
//新版本的流批统一API,既支持流处理也支持批处理
//1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//2.准备数据-source
DataStream<String> linesDS = env.fromElements("nhbd hadoop spark","nhbd hadoop spark","nhbd hadoop","nhbd");
//3.处理数据-transformation
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
/*
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是一行行的数据
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//将切割处理的一个个的单词收集起来并返回
}
}
});
//3.2对集合中的每个单词记为1
/*
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是进来一个个的单词
return Tuple2.of(value, 1);
}
});
//3.3对数据按照单词(key)进行分组
//0表示按照tuple中的索引为0的字段,也就是key(单词)进行分组
//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
Lambda版
package com.nhbd.flink.ch1.example;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* Desc
* 需求:使用Flink完成WordCount-DataStream--使用lambda表达式
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute
*/
public class WordCount4Lambda {
public static void main(String[] args) throws Exception {
//1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//2.准备数据-source
DataStream<String> linesDS = env.fromElements("nhbd hadoop spark", "nhbd hadoop spark", "nhbd hadoop", "nhbd");
//3.处理数据-transformation
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
/*
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
//lambda表达式的语法:
// (参数)->{方法体/函数体}
//lambda表达式就是一个函数,函数的本质就是对象
DataStream<String> wordsDS = linesDS.flatMap(
(String value, Collector<String> out) -> Arrays.stream(value.split(" ")).forEach(out::collect)
).returns(Types.STRING);
//3.2对集合中的每个单词记为1
/*
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
/*DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING, Types.INT));*/
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(
(String value) -> Tuple2.of(value, 1)
, TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {})
);
//3.3对数据按照单词(key)进行分组
//0表示按照tuple中的索引为0的字段,也就是key(单词)进行分组
//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);
//KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy((KeySelector<Tuple2<String, Integer>, String>) t -> t.f0);
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
//3.4对各个组内的数据按照数量(value)进行聚合就是求sum
//1表示按照tuple中的索引为1的字段也就是按照数量进行聚合累加!
DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);
//4.输出结果-sink
result.print();
//5.触发执行-execute
env.execute();
}
}
在Yarn上运行
package com.nhbd.flink.ch1.example;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* Desc
* 需求:使用Flink完成WordCount-DataStream--使用lambda表达式--修改代码使适合在Yarn上运行
* 编码步骤
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute//批处理不需要调用!流处理需要
*/
public class WordCount4Yarn {
public static void main(String[] args) throws Exception {
//获取参数
ParameterTool params = ParameterTool.fromArgs(args);
String output = null;
if (params.has("output")) {
output = params.get("output");
} else {
output = "hdfs://mnode1:9000/flink/example/wordcount/output_" + System.currentTimeMillis();
}
//1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//2.准备数据-source
DataStream<String> linesDS = env.fromElements("nhbd hadoop spark", "nhbd hadoop spark", "nhbd hadoop", "nhbd");
//3.处理数据-transformation
DataStream<Tuple2<String, Integer>> result = linesDS
.flatMap(
(String value, Collector<String> out) -> Arrays.stream(value.split(" ")).forEach(out::collect)
).returns(Types.STRING)
.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING, Types.INT))
//.keyBy(0);
.keyBy((KeySelector<Tuple2<String, Integer>, String>) t -> t.f0)
.sum(1);
//4.输出结果-sink
result.print();
//如果执行报hdfs权限相关错误,可以执行 hadoop fs -chmod -R 777 /
System.setProperty("HADOOP_USER_NAME", "hadoop");//设置用户名
//result.writeAsText("hdfs://mnode1:9000/flink/example/wordcount/output_"+System.currentTimeMillis()).setParallelism(1);
result.writeAsText(output).setParallelism(1);
//5.触发执行-execute
env.execute();
}
}
打包运行:
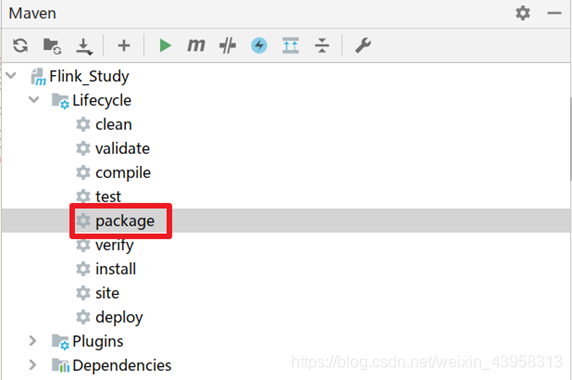
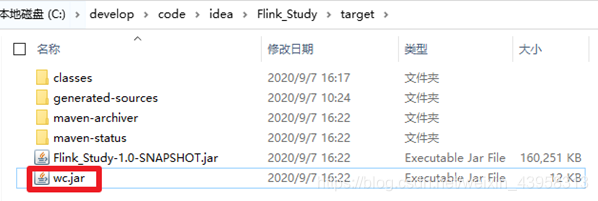

提交执行!!!














 9027
9027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









