







Partition 数据文件
Kafka 中的 Message 是以 Topic 为基本单位进行归类的,不同的 Topic 之间是相互独立的。Topic 是一个逻辑上的概念,为了提升整个集群的吞吐量,Topic 在物理上还可以细分为多个 Partition(每个 Topic 划分几个 partition 是在创建 Topic 时指定的)。
每个 Partition 都负责保存和处理 Topic 的一部分 Message 数据,Partition 的个数对应了消费者和生产者的并发度,比如 Partition 的个数为 3 个,则集群中最多同时有 3 个线程的消费者并发处理数据。
可以把 Partition 看作一个可追加的日志文件,Message 在被追加到分区日志文件的时候,都会分配一个特定的偏移量 offset,用作唯一标识,从而 Kafka 通过它来保证 Message 在 Partition 内的顺序性,不过 offset 并不跨分区,也就是说 Kafka 只能保证分区有序而非主题有序。

一个 Patition 只属于一个 Topic,每个 partition 在磁盘上对应一个文件夹,该文件夹下存放了这个 Patition 的所有消息文件和索引文件。
Patition 中的每条 Message 都包含 offset、messageSize 以及 Data 。其中,offset 用来标识 Message 在这个 Patition 中的偏移量,它是一个逻辑值而并非实际物理偏移量,可以唯一确定 Patition 中的一条 Message;messageSize 表示消息内容的大小;Data 为消息的具体内容。
Message 的详细结构如下图所示,中间部分为一条完整的 Message,其中,“Record” 部分为消息格式,接下来我们具体描述一下 Record 格式中的各个字段。

- crc32:是对 magic 到 value 范围的校验值,占4B;
- magic:消息格式版本号,0.9.X 的版本对应的值为0,占1B;
- attributes:消息属性,低 3 位表示压缩类型,其余位保留,占1B;
- key length:表示消息的 key 的长度,若为 -1,则表示没有设置 key;
- key:可选,没有 key 则无此字段;
- value length:表示实际消息体的长度,若为 -1,则表示消息为空;
- value:消息体,可以为空。
与 Message 对应的则是 Message Set(消息集)的概念(上图左侧),消息集中包含一条或者多条 Message,按 offset 由小到大排列在一起的。Message Set 不仅是存储在磁盘以及在网络上传输的基本形式,也是 Kafka 进行数据压缩的基本单元。
LEO & HW
每个 Patition 都有两个重要的属性:
- LEO(Log End Offset):日志末端偏移,标识当前日志文件中下一条消息的偏移量 offset(也就是下一条消息的写入位置);
- HW(High Watermark):标识了一个特定的消息偏移量 offset,消费者只能拉取到这个 offset 之前的消息,因其类似于木桶效应中短板决定水位高度,故取名为高水位。
所有高水位以下消息都是已经备份过的,消费者仅可消费这些已备份了的,对于任何一个副本分区而言,其 HW 的值都不会大于其 LEO 的值。
举个栗子,有一个日志文件如下图所示,其中有 10 条消息,第一条消息的 offset (LogStartOffset)为 0,最后一条消息的 offset 为 9,offset 为 10 的消息用虚线框表示,代表下一条待写入的消息。
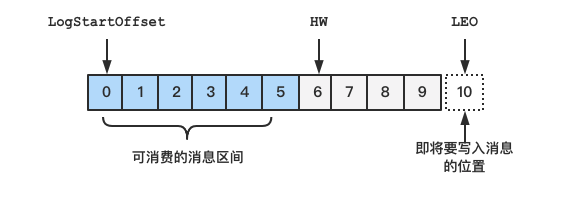
该日志文件的 HW 为 6 ,表示消费者只能拉取到小于这个 offset 的消息,而 offset 为 6 的消息对消费者是不可见的;该日志文件的 LEO 为 10,相当于当前日志分区中最后一条消息的 offset 的值加 1。
ISR 与 LEO、HW 的关系
分区 ISR 集合中的每个副本都会维护自身的 LEO,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
为了更好地理解 ISR 与 LEO、HW ,接下来通过一个栗子来说明三者之间的关系。如下图所示,为三个副本分区组成的 ISR,包含一个 Leader 和两个 Follower,此时 ISR 的 HW 和 LEO 都为 3。

右侧为生产者 Producer ,会发出消息写入到 Leader 分区中,然后 Follower 会向 Leader 发送拉取请求来进行消息同步。

同步过程中,不同的 Follower 的同步效率也不尽相同,如下图所示,Follower1 完全跟上了 Leader 而 Follower2 只同步了消息3。那么此时,Leader 副本的 LEO 为 5,Follower1 副本的 LEO 也为 5,而 Follower2 副本的 LEO 为 4,那么当前 ISR 的 HW 取最小的 LEO 值,此时消费者可以消费到 offset 为 0 至 3 之间的消息。

当所有 Follower 副本都成功的同步到 Leader 写入的消息之后,那么整个分区的 HW 和 LEO 也都变为了 5,此时消费者可以消费到 offset 为 0 至 4 之间的消息。
Kafka 为什么要设计 LEO 和 HW?
在上述分析中,我们知道 Kafka 的复制机制并不是完全的同步复制,也不是单纯的异步复制。同步复制是要求所有的 Follower 副本都复制完,这条消息才会被确认为已经成功提交,这种方式将会极大地影响同步性能。而在异步复制中,只要消息被写入到 Leader 副本中就会被确认为已经成功提交,那么这种情况下,如果所有 Follower 副本都没有完全复制完而落后于 Leader 副本,突然 Leader 出现故障或者宕机,那么将造成数据丢失。
而 Kafka 通过设计 ISR、LEO、HW 的方式,可以有效地权衡数据同步的性能与可靠性的关系。
最后
获取本文PDF版的方式,关注:Data跳动,回复:Kafka123。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









