







SDU项目实训记录2.1——数据预处理
一、分析数据集
样本数有15万条,特征变量有12个
数据字典如下:

翻译成中文:
| Variable Name | Description | Type |
|---|---|---|
| SeriousDlqin2yrs | 好客户坏客户 | Y/N |
| RevolvingUtilizationOfUnsecuredLines | 无担保放款的循环利用 | percentage |
| age | 借款人借款时年龄 | integer |
| NumberOfTime30-59DaysPastDueNotWorse | 30-59天逾期但不糟糕次数 | integer |
| DebtRatio | 负债率 | percentage |
| MonthlyIncome | 月收入 | real |
| NumberOfOpenCreditLinesAndLoans | 开放式信贷和贷款数量 | integer |
| NumberOfTimes90DaysLate | 90天逾期次数 | integer |
| NumberRealEstateLoansOrLines | 不动产贷款或额度数量 | integer |
| NumberOfTime60-89DaysPastDueNotWorse | 60-89天逾期但不糟糕次数 | integer |
| NumberOfDependents | 家属数量 | integer |
二、数据预处理
1、装载数据集
import pandas as pd
import numpy as np
df = pd.read_csv('data/ScorecardsData.csv')
df.info()

2、拆分数据集
将数据集按7:3比例拆分成训练集和测试集:
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(df.iloc[:, 1:], df.iloc[:, 0], test_size=0.3, random_state=random_state)
print("训练集特征维度:", X_train.shape, ",标签维度:", y_train.shape)
print("测试集特征维度:", X_test.shape, ",标签维度:", y_test.shape)
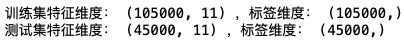
3、判断重复值
# 获取重复值的标识矩阵
isDuplicated = df.duplicated()
print("完全重复的样本行:")
print(df[isDuplicated])

可得:无重复样本
4、处理缺失值
# 统计每个字段的缺失值数量
print("各字段缺失样本数量统计:\n", dataset.isnull().sum())

#求两个变量的缺失比
print("月收入缺失比:{:.2%}".format(df['MonthlyIncome'].isnull().sum()/df.shape[0]))
print("家属数量缺失比:{:.2%}".format(df['NumberOfDependents'].isnull().sum()/df.shape[0]))

(1)直接删除缺失值所在行(不可取)
new_df = df.dropna(axis=0)
new_df.info()
new_df.to_csv("data/删除缺失值.csv",index=False,sep=',')

一共删了20829条数据,可见存在家属数量缺失的都是存在月收入缺失的数据,将删除之后的写入"删除缺失值.csv"作为中间结果保存。
(2)用众数填充NumberOfDependents缺失值,随机森林推算MonthlyIncome
'''
使用众数填充NumberOfDependents缺失值
'''
NoD_mode = df['NumberOfDependents'].mode()[0] # 众数可能有多个并列值,此处取第一个
print("NumberOfDependents字段的众数值:", NoD_mode)
df.loc[df.NumberOfDependents.isnull(), 'NumberOfDependents'] = NoD_mode
print(df.info())

用众数0去填充NumberOfDependents缺失值
NumberOfDependents:10500 non-null,填充完成
'''
使用随机森林推算MonthlyIncome
'''
from sklearn.ensemble import RandomForestRegressor
#用除了明显存在异常值的负债率、家属数量其余的五个特征去推算月收入
monthlyIncome = df[['MonthlyIncome','RevolvingUtilizationOfUnsecuredLines','age',
'NumberOfTime30-59DaysPastDueNotWorse','NumberOfOpenCreditLinesAndLoans',
'NumberOfTime60-89DaysPastDueNotWorse']]
known_monthlyIncome = monthlyIncome[monthlyIncome.MonthlyIncome.notnull()].values # MonthlyIncome未缺失的样本
unknown_monthlyIncome = monthlyIncome[monthlyIncome.MonthlyIncome.isnull()].values # MonthlyIncome缺失的样本
X = known_monthlyIncome[:,1:] # 后5个字段为特征矩阵X
y = known_monthlyIncome[:,0] # 第1个字段为标签结果
# 训练模型
rf = RandomForestRegressor(random_state=random_state, n_estimators=200)
rf.fit(X, y)
# 计算MonthlyIncome缺失的样本中的预测值
predicts = rf.predict(unknown_monthlyIncome[:, 1:])
# 将MonthlyIncome值更新到df中
df.loc[(df.MonthlyIncome.isnull()), 'MonthlyIncome' ] = predicts
print("插补的MonthlyIncome值:", predicts)
print("=" * 100)
print(df.info())

MonthlyIncome:10500 non-null,缺失值填充完成
5、异常值处理
具体见前一篇博客。
导师解答:下一步会默认对过高或过低的异常值进行处理,所以不需要处理异常值,直接进行分箱即可。
6、分箱,计算woe、iv
目前用导师讲的三种示例方法(等宽等频、Kmeans聚类)都遇到了问题,如无法进行分箱或箱体过少、分箱后出现零坏客户数导致woe、iv为负无穷(inf) 的情况,故学习并尝试了其他分箱方法,具体见下篇博客。
















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











