







论文解读:《Deep Learning Face Representation by Joint Identification-Verification》,NIPS 2014
0. 论文基本信息

被引次数:2001 (2021/4/15)
开源代码链接:github,找不到官方实现,但是有其他人的实现
论文链接:paper
1. 论文解决的问题
- 人脸识别
- 输入含有未确定身份的人脸图像,与人脸数据库中的若干已知身份的人脸匹配得到相似度得分,表明待识别的人脸的身份
- 即判断图像里的人是谁
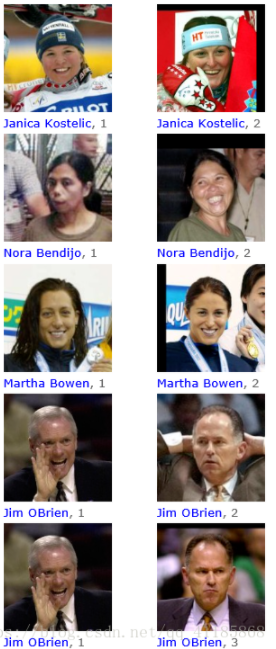
- 人脸验证
- 给定两张含有人脸的图像,判断这两个人是否是同一个人


- 论文关注点
- 以往的做法中,通常分为以下几步
- 人脸检测 => 人脸对齐 => 人脸表征 => 人脸分类


- 人脸检测 => 人脸对齐 => 人脸表征 => 人脸分类
2. 论文贡献
- 本论文关注的是人脸表征和分类/验证部分
- 每个人脸的特征向量必须满足两个目标:
- 最大化不同人的特征的方差:每个人的固有特征是不同的
- 最小化同一个人的特征的方差:因为光照、姿态、表情等因素,同一个人的不同照片的特征不同

- 每个人脸的特征向量必须满足两个目标:
- 本文提出构建一个网络提取人脸特征后,使用多任务训练法,同时进行人脸识别和验证两个任务的训练。这样得到的人脸特征能很好地满足以上两个目标:
- 人脸识别任务可以最大化不同人的固有特征的区别
- 人脸验证任务可以最小化同一个人的不同照片的特征的区别
- 这样提取的特征可以结合softmax进行有效的人脸识别,也可以结合联合贝叶斯算法(JointBayesian)进行人脸验证,达到了当时人脸验证的state of the art,人脸识别的结果没有说明
3. 方法框架
- 注意,论文关注的是两个步骤:人脸特征提取、人脸分类验证
- 因此训练也分为了两个步骤,先训练特征提取网络,再训练分类器
1. 特征网络训练
- 流程图

- 主干网络

- 输入是人脸图像
- 输出的是160维的特征向量,作者称为DeepID2
- 损失函数
- 损失包含两个部分:
-
人脸检测和人脸验证
-
总损失是两个损失的加权和,用一个超参数 λ 来加权
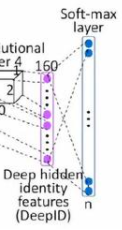
- 人脸识别分支
- 是一个全连接的softmax分类层,如下左图
- 将160维的特征先进行一个全连接到人脸类别数n,再softmax得到预测概率分布
- 损失如下右图,其中 f 表示cnn提取的特征(DeepID2),θ表示的是全连接层的参数,t是target class
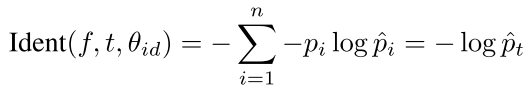
- 人脸验证分支
- 对于两张图提取的两个特征向量,计算L2损失
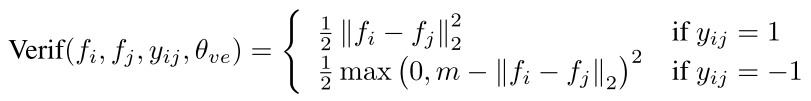
- 其中 fi 和 fj 表示第i张图和第j张图的DeepID2特征,yij = 1表示是同一个人,θ表示人脸验证分支的参数,其实就是只有一个 m,这个m是一个margin阈值,表示只有当两个特征的差距超过这个阈值时才认定为不是同一个人
- 需要注意的是,m是不可学习的,因为对m的梯度必定为非负数,因此作者在每次训练中都采用了使最近一些样本预测错误最小化的m值作为当前的m
-
- 人脸验证训练
- 注意,人脸分类验证的主要流程:人脸检测 => 人脸对齐 => 人脸表征 => 人脸分类
- 本论文使用SDM算法进行人脸对齐,主要是 检测人脸关键点 => 人脸整体对齐
- 数据增强方案:
- 前面提取的整张人脸特征只有160维,过于单一
- 因此作者将对齐后的人脸根据人脸关键点进行裁剪得到不同的人脸区域块(patch),这些区域块经过包括翻转、平移、黑白化等各种转换,如下图
- 对每个区块分别训练一个特征网络提取160维的特征,论文内选择了200个patch,然后最后采用前后向贪婪算法(the forward-backward greedy algorithm)选择了25个patch提取的特征向量拼接为25 * 160 = 4000维的特征向量,因为4000太大了,所以还做了一次PCA降维,作为一个人脸的特征

- 人脸验证
- 联合贝叶斯算法
- 这个算法数学原理比较复杂,本论文没有详细展开讲述这个算法,我这里给一个直观的简单描述
- 先贴上我学习时用的博客和原论文链接
- Bayesian face revisited : a joint formulation 笔记_csyhhb的专栏-CSDN博客
- 基于联合贝叶斯的人脸验证_wawjb的博客-CSDN博客
- 原论文:Bayesian Face Revisited: A Joint Formulation
- 大概意思是说,每个人的脸都有独自的固有特征 μ (下图左),然后加上光照、姿态、表情等不可控特征 ε (下图右),才能得到在一个特定图片中人脸的特征 x = μ + ε

- 假设这两个特征是相互独立的高斯分布,此时就可以用联合贝叶斯算法来估算从样本空间随便抽一张图的特征概率分布
- 假设 µ,ε 服从高斯分布N(0,Su), N(0,Se),其中Su,Se为需要学习的协方差矩阵
- 这时将人脸验证变成一个假设检验任务,即两个假设:
- H-inter:两个人脸不是同一个人
- H-intra:两个人脸是同一个人
- 最后用概率的对数似然值来判断是否是同一个人

- 其中P(f1,f2|H-inter)指两个人脸不是同一个人的情况下,抽样得到f1和f2这两个特征的概率
- P(f1,f2|H-intra)同理
4. 实验
- 损失函数的加权超参数λ
- 实验设计
- 不断调整训练时对人脸分类分支和验证分支的损失加权 λ 值,查看影响
- 其中在进行最后的验证任务时,有两条曲线,联合贝叶斯就是之前说的算法,L2 norm的线是在训练特征抽取网络时计算损失那个分支的直接输出
- 评价指标
- 人脸验证的准确率accuracy
- 结果分析
- 可以发现,在λ接近0.01-0.1的数量级时效果比较好,作者最后选择了λ=0.05
- 特征的可视化图中可以发现,λ=0时特征很难分辨出类别,λ=0.05时有比较明显的类别内聚现象,且可以看出一些类间区别,λ=∞时虽然有些类内聚程度高,但是也很容易揉成一团,类内高内聚,但是类间很难区分


- 训练集用到的人脸类别数量影响
- 实验设计
- 由于目标中有一个人脸类别间特征方差最大化,因此作者想查看训练时使用的类别数的影响
- 评价指标
- 人脸验证的准确率accuracy
- 结果分析
- 可以发现用的人脸类别越多效果越好,一方面可能是因为数据集大了,另一方面也可能验证了损失设计的合理性

- 可以发现用的人脸类别越多效果越好,一方面可能是因为数据集大了,另一方面也可能验证了损失设计的合理性
- 两个损失分支的影响
- 实验设计
- 设置不同的λ值和不同的DeepID的特征维数,查看类间和类内的特征方差大小变化曲线
- 评价指标
- 无
- 结果分析
- 不使用人脸验证分支时(λ=0),类内方差很大(红线);因此人脸验证分支是能有效降低类内方差的,且不降低类间方差
- 不使用人脸分类分支时(λ=∞),类内方差和类间方差都很小(蓝线),模型效果很差;因此人脸分类分支是必要的

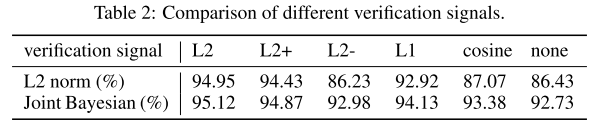
- 人脸验证是采用L2还是联合贝叶斯
- 实验设计
- 前面说了,有L2(训练时的验证方式)和联合贝叶斯(测试时的验证方式)两种,作者想对比在测试时实际哪个更好
- L2+和L2-分别表示在训练时验证分支采用的样本类型,+表示只采用同类样本,-表示只采用不同类样本,同样也对比了L1和余弦相似度的损失
- 评价指标
- 人脸验证的准确率accuracy
- 结果分析
- 显然联合贝叶斯的效果更好,L2+的指标也很高,说明在验证分支中,同类样本是提高类内聚的关键
- 显然联合贝叶斯的效果更好,L2+的指标也很高,说明在验证分支中,同类样本是提高类内聚的关键
- 区块patch数的影响
- 实验设计
- 在进入联合贝叶斯之前,是将多个patch提取的特征合并的,作者通过这个实验选择最佳的patch数量
- 评价指标
- 人脸验证的准确率accuracy
- 结果分析
- 越多显然越好,但是速度也慢了,最后选25

- 越多显然越好,但是速度也慢了,最后选25
- 最终效果
- 实验设计
- 作者采用了集成学习的方式,训练了7个不同的分类器,将7个分数学习一个svm作为最终的分类器
- 评价指标
- 人脸验证的准确率accuracy
- 结果分析
- 达到了state of the art


- 达到了state of the art
5. 讨论
- 在实验5中,作者单个分类器的准确率只有98.97,和实验6中写明的高斯脸的结果差不多,感觉最后的指标可能是因为实验6中作者使用了集成学习的trick?
6. 数据集
- 论文是2014年的,那个时候的老数据集已经变了
- 202599张人脸图像
- 10177个人
- 训练和验证集
- CelebFaces+A
- 抽取8192个人的图像
- 用于训练DeepID2的特征抽取网络
- CelebFaces+B
- 抽取剩下的1985个人的图像
- 用于选择超参数、选择高效patch、训练联合贝叶斯模型
- 论文是2014年的,那个时候的老数据集已经变了
- 13233张人脸图像
- 5749个人
- 测试集















 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









