






输入一个序列,求最长上升子序列(LIS)。
小数据
输入
第1行:1个整数n(1<=n<=5000),表示序列中元素的个数.
第2行-n+1行:每行1个整数x(-1000<=x<=1000),第i+1行表示序列中的第i个元素。
输出
第1行:1个整数k,表示最长上升子序列的长度。
思路:
深搜是行不通的,广搜也是行不通的,两者的时间复杂度都很高,前者是n的阶乘,后者要爆。
所以只能以逆向的思维,用记忆化搜索——动态规划(DP)来做,时间复杂度为O( n * ( n + 1 ) / 2 )。
DP主要就是利用数组里的部分最优解来求出另一个解,每个元素都要互相调用,调用的元素都是之前计算过的,当然也可以用递归优化。这就是它的本质——记忆化递归。
这里用一个数组 f [ ],f [ i ] 记录从1号元素到 i 号元素之间,以 i 元素结尾的最长上升子序列的长度,相当于它每一个元素就是一个可以独立输出的解了!
跟递推式一样,DP也有一个求解的式子(叫状态转移方程),可以代入求每一个 f [ i ]。这道题的式子是这样的:
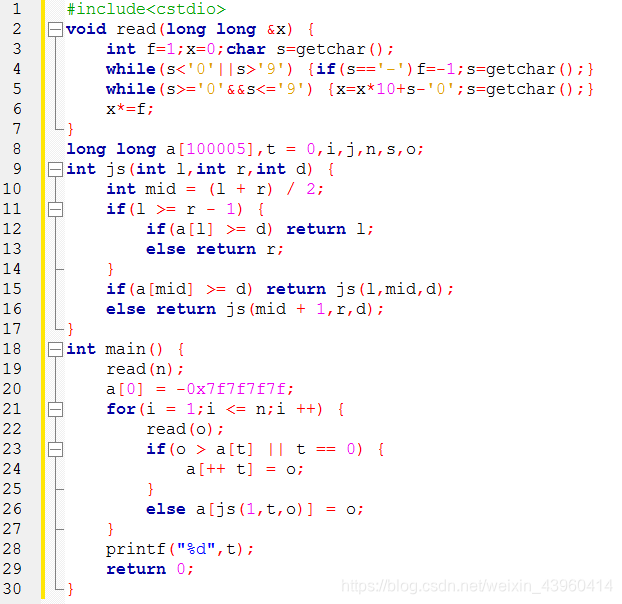
代码也很简单:(为了防复制我就发截图)
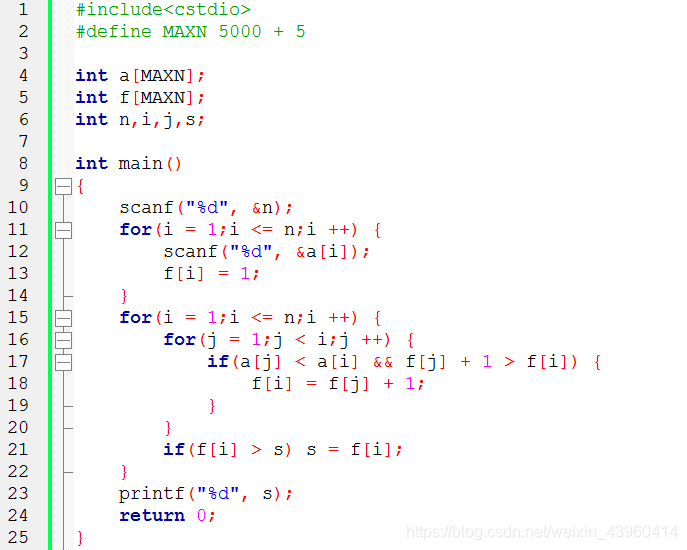
还没懂的可以看大神的解说:[ 点这里 ]
大数据
【题目背景】
进步,就是爬坡。——某不愿透露姓名高调路过的吃瓜群众。
高度迥异的坡很多,而你想进步。
输入
第一行一个正整数 n (1<=n<=100000),表示有n个坡。
第二行n个正整数ai(ai<=1e9),表示每个坡的高度。
输出
一行,一个正整数,表示最长的上升子序列(LIS)。
思路:
前面已经提到过,
用记忆化搜索——动态规划(DP)来做,时间复杂度为O( n * ( n + 1 ) / 2 )
这次的数据很大了,用前面的方法不再可靠了。为了减小时间复杂度,要么把他降成O( n ),要么降成O( n logn )。
所以就要用一种可以配合二分的数据结构——单调栈。具体做法如下:
开一个栈(数组模拟),将a[0]入栈,每次取栈顶元素top和读到的元素a[i](0<i<n)做比较,如果a[i]> top 则将a[i]入栈;如果a[i]<= top则二分查找栈中的比a[i]大的第1个数,并用a[i]替换它。 最长序列长度即为栈的大小top。这是很好理解的,对于x和y,如果x < y且stack[y] < stack[x],用stack[x]替换stack[y],此时的最长序列长度没有改变,但序列继续变长的''潜力''增大了。
举例:原序列为1,5,8,3,6,7开始1,5,8相继入栈,此时读到3,用3替换5,得到1,3,8; 再读6,用6替换8,得到1,3,6;再读7,得到最终栈为1,3,6,7。最长递增子序列为长度4。
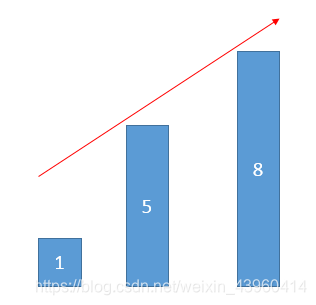
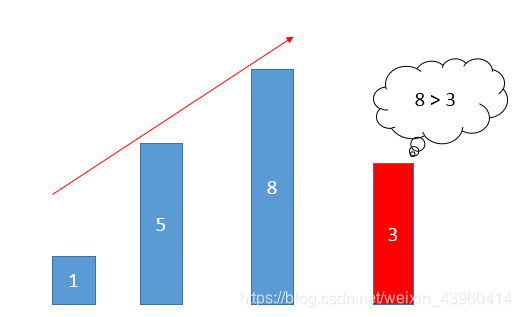
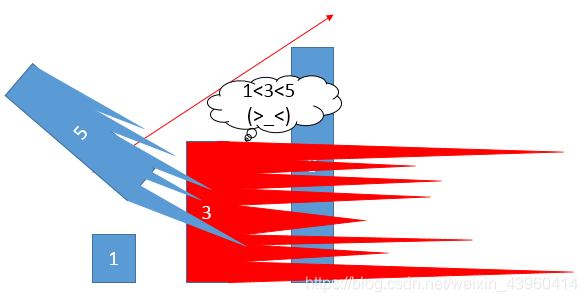
…………
代码:

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









