






序列化
序列化就是将原本的数据类型转化成字符串的过程

1、json
json模块主要用于处理json格式的数据,可以将json格式的数据转化为python的字典,便于python处理,同时也可以将python的字典或列表等对象转化为json格式的数据,便于跨平台或跨语言进行数据交互.
Json模块提供了四个功能:dumps、dump、loads、load
dumps 和 loads 用于python对象和字符串间的序列化和反序列化
dumps:将python 基本数据类型转化为json格式数据类型
loads:将json格式数据类型转化为python数据类型
dump 和load 用于对文件进行序列化和反序列化
dump:主要用于json文件的读写,json.dump(x,f),x是对象,f是一个文件对象,这个方法可以将json字符串写入到文本文件中
load:加载json文件
dumps,loads
import json
#序列化
dic = {'k1':'v1','k2':'v2'}
str_dic = json.dumps(dic)
print('dic的数据类型是',type(dic),'内容是',dic)
print('json_dic的数据类型是',type(str_dic),'内容是',str_dic)
#反序列化
str_dic1 = '{"k1":"v1","k2":"v2"}' #字符串只能是这个格式的,才能被json转换 通过loads进行反序列化时,必须使用双引号
dic1 = json.loads(str_dic)
print('str_dic1的数据类型是',type(str_dic1),'内容是',str_dic1)
print('dic1的数据类型是',type(dic1),'内容是',dic1)
结果
dic的数据类型是 <class 'dict'> 内容是 {'k1': 'v1', 'k2': 'v2'}
json_dic的数据类型是 <class 'str'> 内容是 {"k1": "v1", "k2": "v2"}
str_dic1的数据类型是 <class 'str'> 内容是 {"k1":"v1","k2":"v2"}
dic1的数据类型是 <class 'dict'> 内容是 {'k1': 'v1', 'k2': 'v2'}
注意元组的序列化
import json
tup = (1,2,3,4,5)
str_tup = json.dumps(tup) # 序列化tup
tup = json.loads(str_tup) # 将结果反序列化
print(tup) #原来的tup元组变成了一个列表
结果
[1, 2, 3, 4, 5]
dump load
import json
dic = {'k1':'v1','k2':'v1'}
with open('exercise','w') as f:
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
with open('exercise') as f:
ret = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
print(ret)
多行写入以及读取
import json
lst = [{'k1':'v1'},{'k2':'v2'},{'k3':'v3'}]
with open('exercise','w')as f:
for i in lst:
str = json.dumps(i)
f.write(str+'\n')
with open('exercise')as f:
for line in f:
print(json.loads(line.strip()))
结果
{'k1': 'v1'}
{'k2': 'v2'}
{'k3': 'v3'}
关于dumps以及dump的参数
Serialize obj to a JSON formatted str.(字符串表示的json对象)
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse).
If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity).
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError.
sort_keys:将数据根据keys的值进行排序。
To use a custom JSONEncoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
数据类型转换
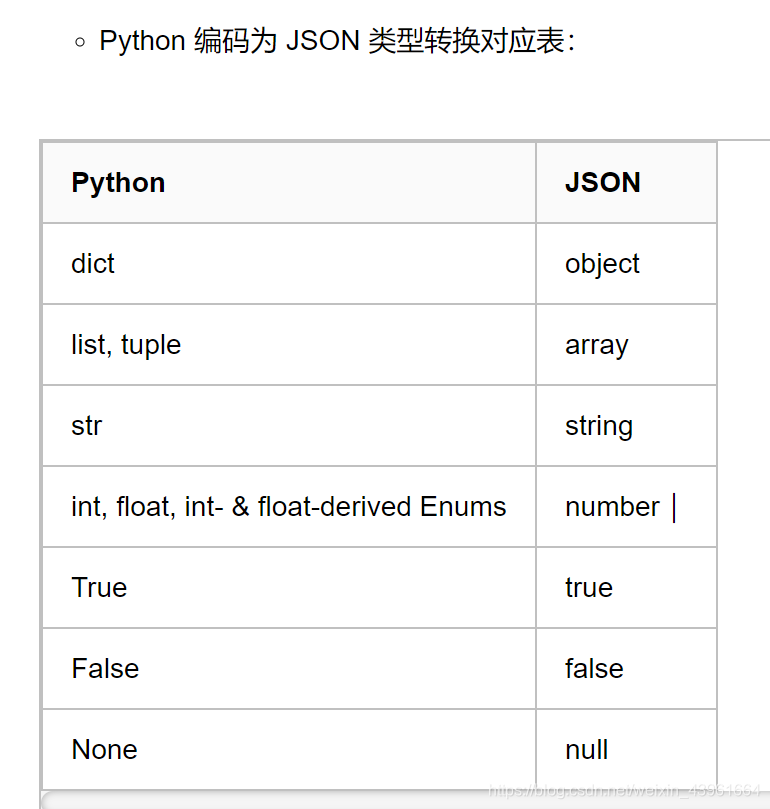
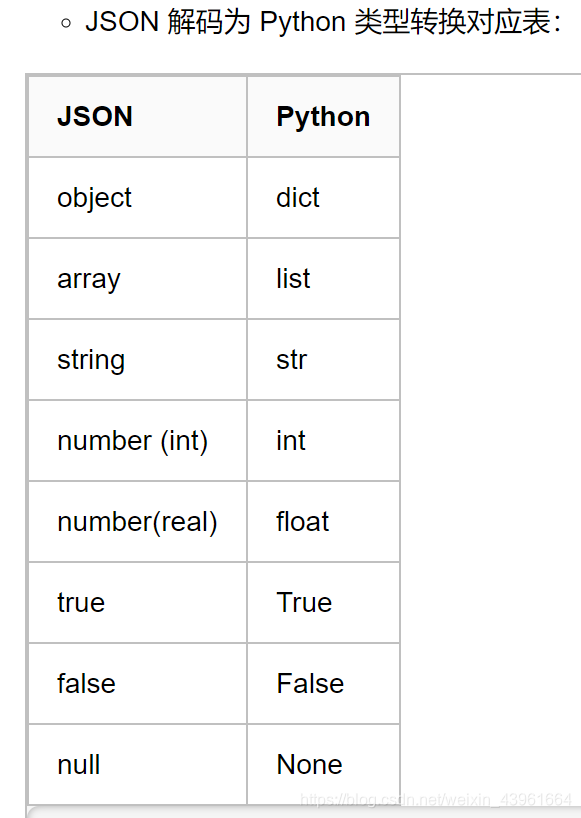
2、pickle
pickle模块实现了基本的数据序列和反序列化,和json的功能类似。
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储,也可以简单的将字符进行序列化
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象,也可以将字符进行反序列化。和json不同的是:json 更适合跨语言 可以处理字符串,基本数据类型;pickle python专有,更适合处理复杂类型的序列化
dumps,loads dump,load
dumps 和loads 用于python对象和字符串间的序列化和反序列化
dump 和load 用于对文件进行序列化和反序列化.
pickle.dump(obj, file, [,protocol])
注解:将对象obj保存到文件file中去。
protocol为序列化使用的协议版本,0:ASCII协议,所序列化的对象使用可打印的ASCII码表示;1:老式的二进制协议;2:2.3版本引入的新二进制协议,较以前的更高效。其中协议0和1兼容老版本的python。protocol默认值为0。
file:对象保存到的类文件对象。file必须有write()接口, file可以是一个以’w’方式打开的文件或者一个StringIO对象或者其他任何实现write()接口的对象。如果protocol>=1,文件对象需要是二进制模式打开的。
pickle.load(file)
注解:从file中读取一个字符串,并将它重构为原来的python对象。
file:类文件对象,有read()和readline()接口
import pickle
s = '我爱中国'
pickled_s = pickle.dumps(s) #和json不同,pickle序列化后会得到一个bytes类型
print('pickled_s的类型是',type(pickled_s),'值是',pickled_s)
s1 = pickle.loads(pickled_s)
print('s1的类型是',type(s1),'值是',s1)
结果
pickled_s的类型是 <class 'bytes'> 值是 b'\x80\x03X\x0c\x00\x00\x00\xe6\x88\x91\xe7\x88\xb1\xe4\xb8\xad\xe5\x9b\xbdq\x00.'
s1的类型是 <class 'str'> 值是 我爱中国
dump和load
import pickle
s = '我爱中国'
with open('exercise1','wb') as f:
pickle.dump(s,f)
with open('exercise1','rb')as f:
print(pickle.load(f))
结果
我爱中国
多次写入以及多次读取
import pickle
s = '我爱中国'
s1 = '我爱北京天安门'
with open('exercise1','wb') as f:
pickle.dump(s,f)
pickle.dump(s1,f)
with open('exercise1','rb')as f:
print(pickle.load(f))
print(pickle.load(f))
结果
我爱中国
我爱北京天安门















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









