







 本文探讨了云原生时代企业面临的多告警源问题,详细阐述了企业在上云、多云和自研监控系统下遇到的告警不统一痛点,并介绍了ARMS告警管理如何通过半结构化数据、自定义告警接入和事件处理流等方式实现告警的统一管理和自动化恢复,旨在帮助企业和运维人员有效应对复杂IT环境中的告警挑战。
本文探讨了云原生时代企业面临的多告警源问题,详细阐述了企业在上云、多云和自研监控系统下遇到的告警不统一痛点,并介绍了ARMS告警管理如何通过半结构化数据、自定义告警接入和事件处理流等方式实现告警的统一管理和自动化恢复,旨在帮助企业和运维人员有效应对复杂IT环境中的告警挑战。
本文介绍告警统一管理的最佳实践,以帮助企业更好地处理异构监控系统所带来的挑战和问题。
背景信息
在云原生时代,企业IT基础设施的规模越来越大,越来越多的系统和服务被部署在云环境中。为了监控这些复杂的IT环境,企业通常会选择使用异构监控系统,例如Prometheus、Grafana、Zabbix等,以获取更全面的监控数据,以便更好地了解其IT基础设施的运行状况和性能表现。
然而,这种异构监控系统也带来了一些问题,其中最显着的是告警信息的分散。由于不同的监控系统可能会产生不同的告警信息,这些信息可能会分散在各个系统中,导致企业很难全面了解其IT系统的告警状况。这使得响应告警变得更加困难,同时也增加了人工管理的复杂性和工作量。
为了解决这些问题,企业需要一种更加统一和集中的告警管理方案,以确保告警信息能够及时到达正确的人员,以便他们能够快速采取必要的措施来应对潜在的问题。
告警管理的痛点
场景一:企业迁移上云后,云上产品的告警不统一
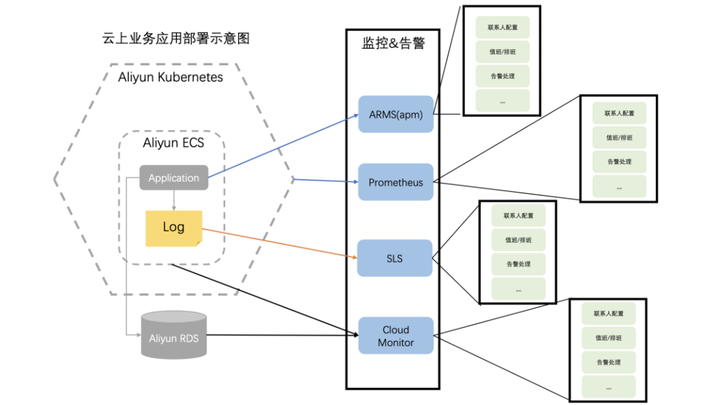
在一个典型的云原生业务应用部署架构中,通常会使用到如下产品 ACK、ECS、RDS,应用通过Kubernetes部署在阿里云的ECS上并访问云上的RDS。在这个架构中通常会用到如下监控产品来对系统进行监控。
- 通过CloudMonitor对阿里云基础设施ECS和RDS进行监控,当资源出现异常时进行告警。
- 通过Prometheus对Kubernetes以及部署在kubernetes上的Pod进行监控,当Kubernetes出现异常时进行告警。
- 通过ARMS对部署在Kubernetes上的应用进行监控,包括应用直接的调用链。当应用异常时进行告警。
- 通过SLS对应用产生的日志进行监控,当日志出现异常时进行告警。
在这样一个场景下由于用到了多个云产品对整个系统进行监控会导致使用者需要在多个产品上重复配置联系人、通知方式、值班等运维配置。且不同系统之间的告警无法产生有机结合,当一个问题出现时不能快速关联不同告警系统中的相关告警。
场景二:多云、混合云架构下,异构监控系统告警不统一
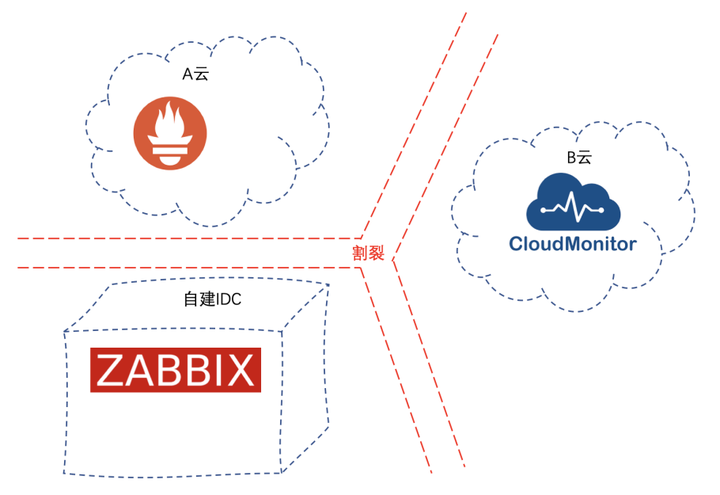
当企业的应用部署在多云环境或混合云环境下时,监控系统产生的告警可能会更加分散和复杂,给企业的运维工作带来很大的挑战。由于不同的云平台和私有云架构之间的差异,监控数据的采集和处理方式也可能不同,因此,不同监控系统产生的告警信息也可能表现出差异化,这会带来一系列的问题。
首先,不同监控系统产生的告警信息分散在不同的地方,运维人员需要耗费更多的时间和精力去处理这些信息。其次,不同系统产生的告警信息难以统一进行管理和分析,使得问题的诊断和解决更加困难。此外,因为不同系统的告警信息可能存在重复或冲突,管理和处理这些信息也会变得更加复杂。
场景三:自研监控系统、自定义事件告警接入
在应用开发运维过程中,随着系统规模的扩大和复杂度的提高,各个角落中的胶水代码逐渐增多。这些代码虽然是连接不同模块和系统的重要纽带,但一旦出现问题,由于分散在不同的地方,很难立即发现和处理。这就使得企业难以保证系统的高可用性和稳定性。如何灵活的低成本的接入这部分代码产生的告警也成为企业应用运维的痛点之一。
统一告警管理
在构建统一告警管理平台过程中,不同的监控系统对告警定义、处理流程都不一样,往往会存在下面问题:
- 不同系统产生的告警格式不同,接入成本高。
- 不同系统间的告警接入后由于格式不统一,难以统一处理逻辑。
- 不同告警系统对于告警等级的定义不同。
- 不同告警系统对于告警自动恢复的处理方式不同。有的告警系统支持自动恢复,有的不支持。
ARMS告警管理[1]设计的集成、事件处理流、通知策略等功能专门针对告警统一管理的场景,解决了统一管理过程中遇到的诸多问题。
ARMS告警管理如何接入不同格式的告警?
传统告警通常包括如下一些内容,这种结构化的告警通常只适用于单一告警源。当多个告警源的数据汇总到一起后通常会导致数据结构的冲突。因此ARMS使用了半结构化的数据来存储告警。
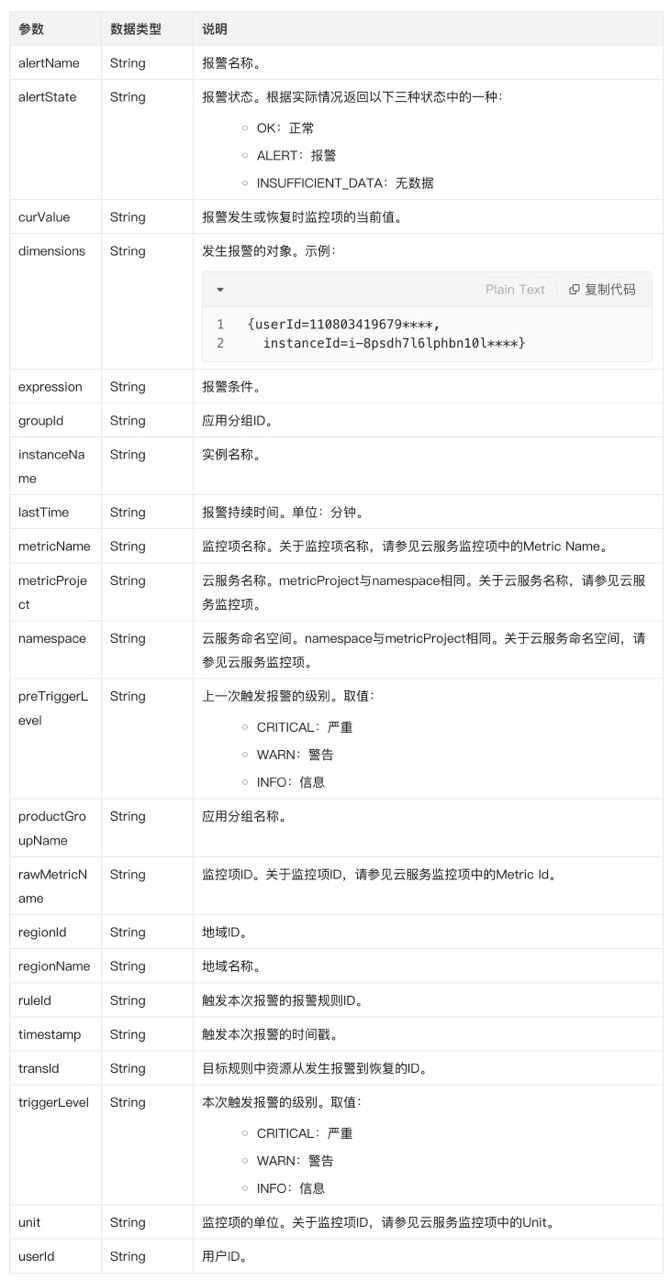
阿里云监控告警数据格式:
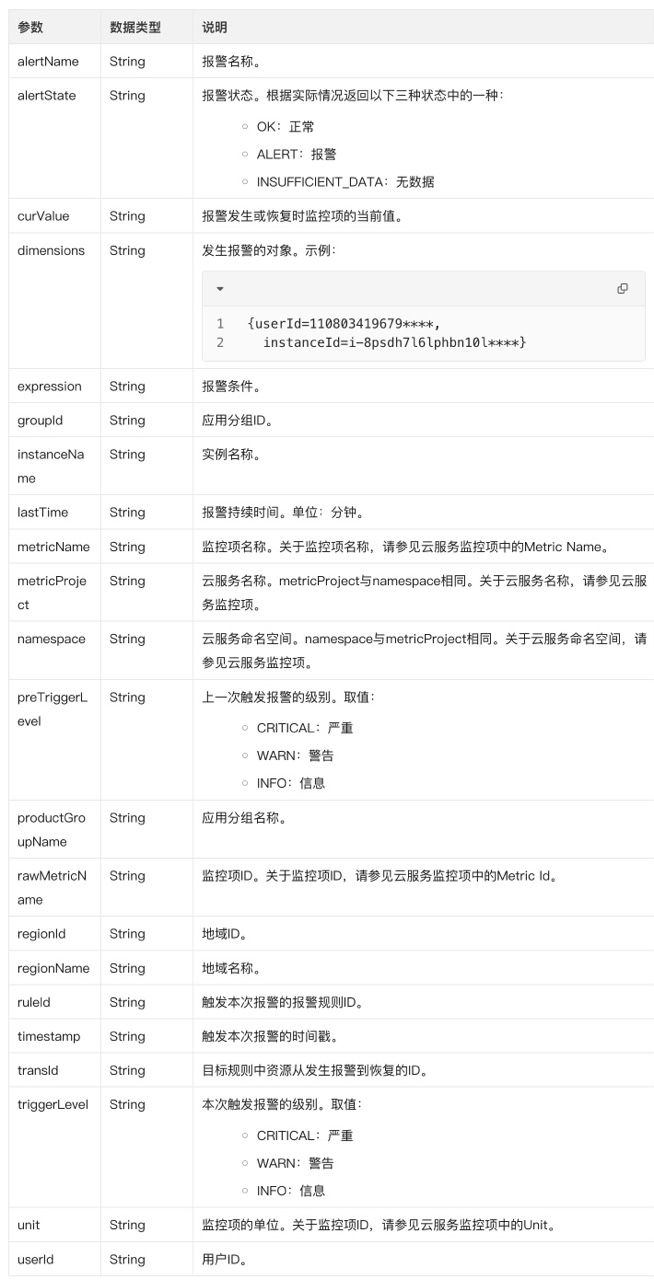
Zabbix告警数据格式:
Nagios告警数据格式:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









