







实验目的
1、理解3种基本分类算法决策树、贝叶斯、KNN的思想;
2、掌握如何基于上述3种分类算法构建分类模型;
3、学会如何对训练好的分类模型进行简单对比分析;
实验环境
基于python的Pycharm环境
实验内容
一.分别采用C4.5决策树、朴素贝叶斯、KNN分类器在训练数据上训练出模型
1.采用C4.5决策树在训练数据上训练出分类模型
(1)查看数据集的属性
①属性集合=[天气,是否周末,是否促销]
②类别标签有两个,类别集合=[高,低]
(2)读取数据–数据的预处理
①因为要引入包C4.5,TreePlootter,所以转换data中的数据,把中文转换为英文

②把data转换为list存入datalist中

可以看到经过处理后的数据行变成这样,以这个格式进行 参数的输入。
(3)划分训练集和验证集
随机选取数据集中的80%样本作为训练集,剩余的20%作为验证集.

x,y是原始的数据集。X_train,y_train 是原始数据集 划分出来作为训练模型的,fit模型的时候用。
X_test,y_test 这部分的数据不参与模型的训练,而是用 于评价训练出来的模型好坏,score评分的时候用。
(4)特征值
①样本特征标签

②样本特征类型

③类别向量

(5)构建决策树

(6)减枝后的决策树:

(7)准确率和匹配度


可以看到此训练集的准确率为83%
(8)运行时间1.83s
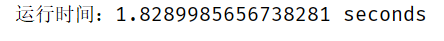
(9)混淆矩阵

实验代码
import C45
import treePlotter
import pandas as pd
from sklearn.model_selection import train_test_split
import time
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
start=time.time()
# 读取数据文件
fr ='../data/quan.xlsx'
# # 生成数据集
data=pd.read_excel(fr)
# print(data)
#把data中的中文转换成英文
data 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5411
5411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









