







目录
一.集合和数组的区别

数组创建的三种方式
public class Array {
/*数组是具有相同数据类型的一组数据的集合;
数组(Array)的标志是[];
数组的每个元素都有下标/索引(index),默认从0开始;*/
//数组的创建
int a[] = new int[3];
int a1[] = new int[]{1, 2, 3};
int a3[] = {1, 2, 3};
public static void main(String[] args) {
int x[] = {1, 2, 3};
for (int y = 0; y < x.length; y++) {
System.out.println(x[y]);
}
System.out.println(Arrays.toString(x));
int a3[] = {1, 2, 3};
int[] arr;
arr = new int[3];
System.out.println("arr是:"+arr);//[I@1540e19d
int [] arr1 = new int [6];
int intValue = arr1 [5];
//这里可以直接输出,因为数组会默认初始化。
System.out.println(intValue);
/*String str=" aaa",与 String str=new String("aaa")一样吗?*/
String str = "aa";
String str1 = new String("aa");
Boolean A = str.equals(str1);
System.out.println(A);//true
System.out.println(str == str1);//false
}
}
二.Collection集合的方法:
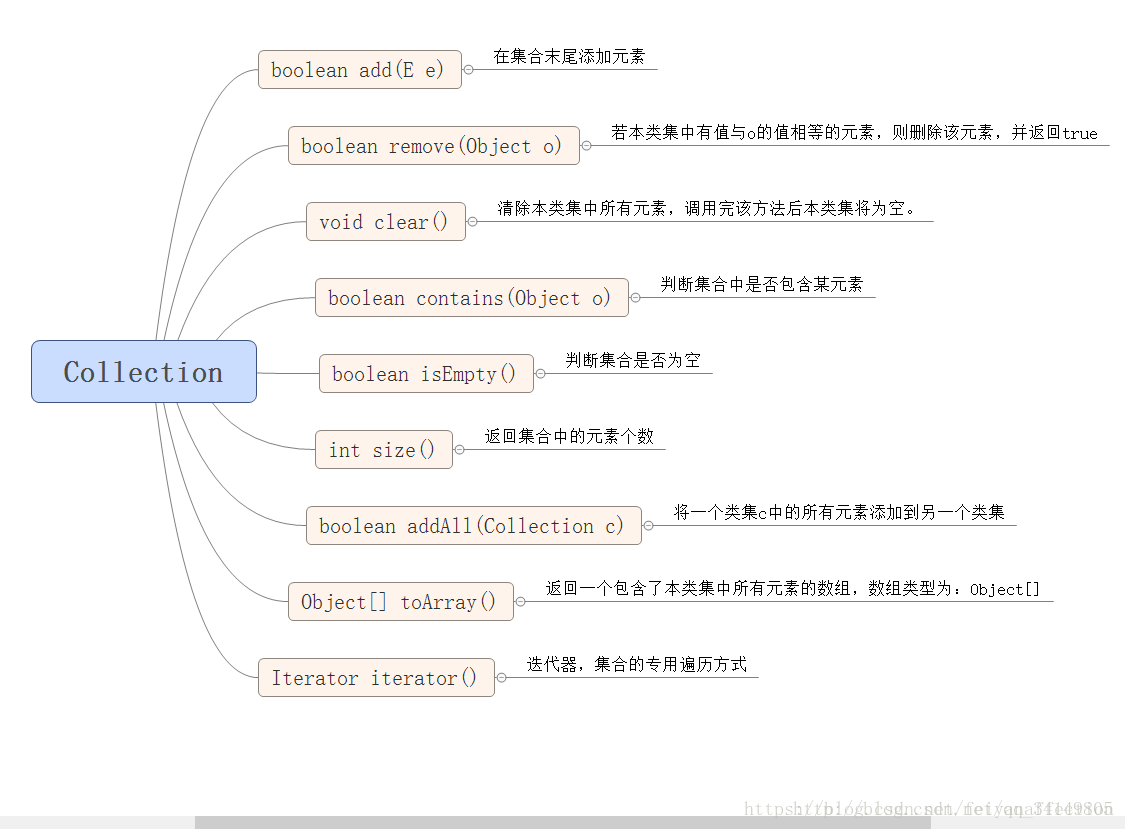
三.常用集合的分类:
Collection
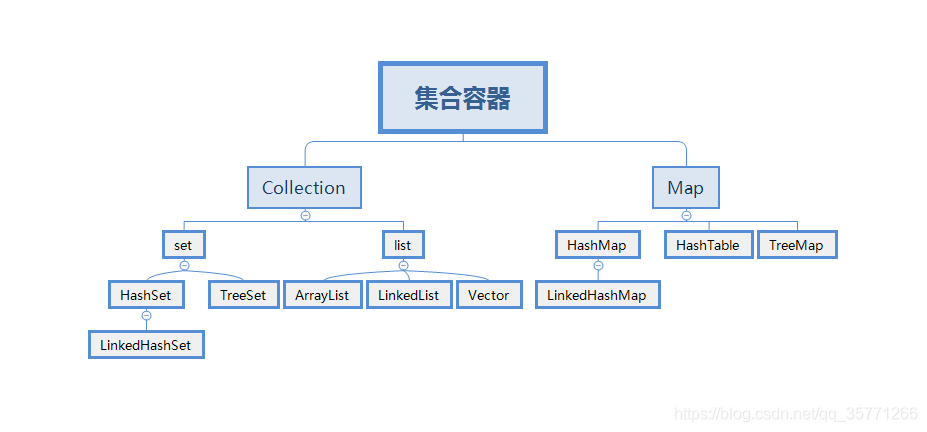
List下各种实现类对比。(这几个类都是有序的,允许重复的)
1.List:
(1)ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
(2)LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
(3)Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
Set下各种实现类对比
HashSet基于哈希表实现,有以下特点:
1.不允许重复
2.允许值为null,但是只能有一个
3.无序的。
4.没有索引,所以不包含索引操作的方法
LinkedHashSet跟HashSet一样都是基于哈希表实现。只不过linkedHashSet在hashSet的基础上多了一个链表,这个链表就是用来维护容器中每个元素的顺序的。有以下特点:
1.不允许重复
2.允许值为null,但是只能有一个
3.有序的。
4.没有索引,所以不包含索引操作的方法
TreeSet是SortedSet接口的唯一实现类,是基于二叉树实现的。TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。有以下特点:
1.不允许重复
2.不允许null值
3.没有索引,所以不包含索引操作的方法
hashset【基于哈希表来实现】 不允许重复 允许有null,只允许有一个 无序的 没有索引-所以不包含索引操作的方法
linkedset 【基于哈希表实现 然后多了一个链表】 有序
treeset 【二叉树 确保集合元素处于排序状态 自然排序和定制排序】不允许重复 允许有null,只允许有一个 没有索引
Map是双列集合的超类。也就是键值对形式。
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
| HashMap | HashTable | |
| 同步(synchronization) | 非synchronized的 | synchronized |
| 是否为null | HashMap可以接受为null的键值(key)和值(value) | 不行 |
| 正确同步后是否可以共享 | 不行 | 多个线程可以共享一个Hashtable |
| 迭代器 | HashMap的迭代器(Iterator)是fail-fast迭代器 | Hashtable的enumerator迭代器不是fail-fast的 |
| HashMap不能保证随着时间的推移Map中的元素次序是不变的 |
LinkedHashMap和hashMap的区别在于多维护了一个链表,用来存储每一个元素的顺序,就跟HashSet和LinkedHashSet差不多。
HashMap通常比TreeMap快一点(树和哈希表的数据结构使然),建议多使用HashMap,在需要排序的Map时候才用TreeMap。















 28万+
28万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









