






今天玩了一下tvm的安装
我要安装v0.14.0的版本
所以按照官网的方法
https://tvm.apache.org/docs/install/from_source.html#python-package-installation
git clone --recursive https://github.com/apache/tvm tvm
git checkout v0.14.0
recursive是很重要的
这一步可以替换成gitee的网址
然后我修改了.gitsubmodule文件成gitee的网址,但是被我遗失了。。。
这些第三方库下载完毕之后
开始build
首先要cp cmake的config.cmake到build文件夹下
修改里面的配置
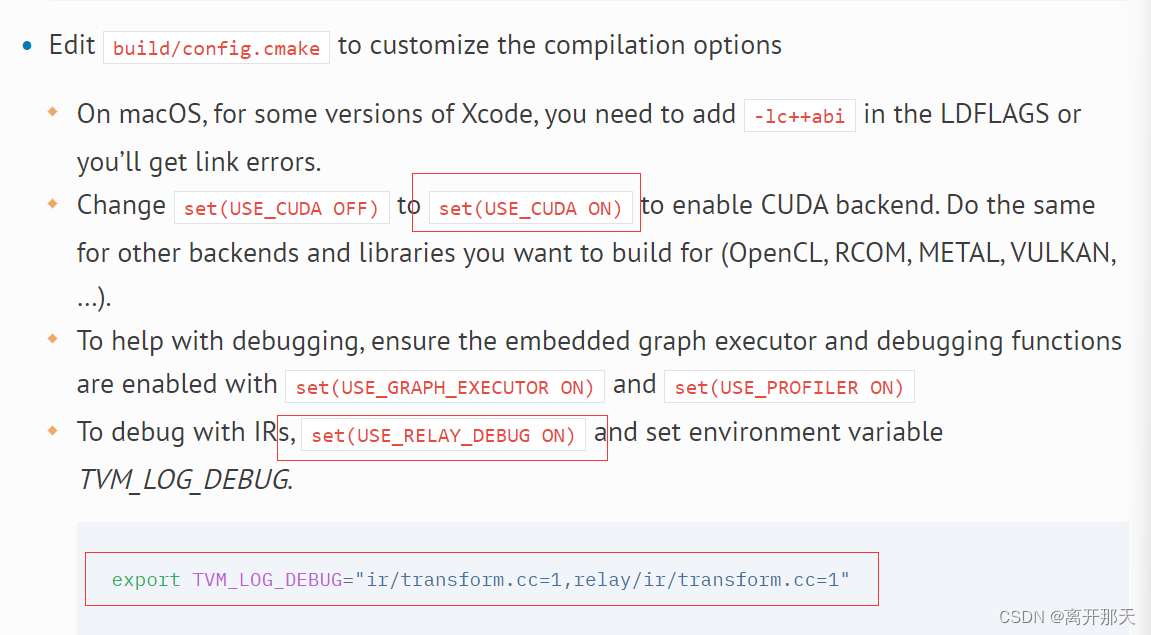
我反正是都上齐活了
然后.bashrc上面加上这一句
之后直接cmake…
make -j4开始构建
构建成功
参考下面的method1
export TVM_HOME=/path/to/tvm
export PYTHONPATH=$TVM_HOME/python:${PYTHONPATH}
把这两段放bashrc
调出python
import tvm就好啦
这时候你会发现有一些日志
如果你不喜欢这些日志
echo 'export TVM_LOG_DEBUG=0' >> ~/.bashrc
echo 'export TVM_LOG_INFO=0' >> ~/.bashrc
echo 'export TVM_LOG_WARNING=0' >> ~/.bashrc
source ~/.bashrc
尝试使用一下tvm
首先下载resnet50-v2-7.onnx
然后编译它
import onnx
import tvm
from tvm import relay
# Load the ONNX model
onnx_model = onnx.load("resnet50-v2-7.onnx")
# Convert ONNX model to Relay IR
shape_dict = {"data": (1, 3, 224, 224)}
mod, params = relay.frontend.from_onnx(onnx_model, shape_dict)
# Target configuration
target = tvm.target.cuda()
# Compile the model
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(mod, target, params=params)
# Export the compiled model as a shared library
lib.export_library("resnet50.so")
这样获得了resnet50.so
尝试读取
import tvm
tvm.runtime.Module = tvm.runtime.load_module("resnet50.so")
成功
fmlab
~/tvm1/test/resnet50Trans.py
这个网站能够下载部分github文件
https://blog.luckly-mjw.cn/tool-show/github-directory-downloader/index.html
阅读书籍p28
遇到问题ModuleNotFoundError: No module named ‘cffi’
解决办法:去除usr/bin的PATH,使用conda环境的python
以下是书上的示例代码
我有所修改
书的作者,虽然说在博客上开源了代码
但是格式很不好
也不知道他是怎么想的
反正我是没找到正儿八经的开源代码
总之我是运行成功了
代码算是没问题,然后文件下载是需要自己费点功夫的
当然书上写的挺详细的
# 代码来源https://zhuanlan.zhihu.com/p/435800815
# https://gitee.com/sophia_0823/web-data.git
# https://pjreddie.com/media/files/yolov3.weights
# 1、导入 numpy and matplotlib
import numpy as np
import matplotlib.pyplot as plt
import sys
# 2、导入 tvm, relay
import tvm
from tvm import relay
from ctypes import *
#from tvm.contrib.download import download_testdata
from tvm.relay.testing.darknet import __darknetffi__
import tvm.relay.testing.yolo_detection
import tvm.relay.testing.darknet
import datetime
import os
# 3、设置 Model name
MODEL_NAME = 'yolov3'
######################################################################
# 4、下载所需文件
# -----------------------
# 这部分程序下载cfg及weights文件。
CFG_NAME = MODEL_NAME + '.cfg'
WEIGHTS_NAME = MODEL_NAME + '.weights'
#REPO_URL = 'https://github.com/dmlc/web-data/blob/master/darknet/'
#CFG_URL = REPO_URL + 'cfg/' + CFG_NAME + '?raw=true'
#WEIGHTS_URL = 'https://pjreddie.com/media/files/' + WEIGHTS_NAME
#cfg_path = download_testdata(CFG_URL, CFG_NAME, module="darknet")
# 5、以下为直接填写路径值示例,后同。
cfg_path = "darknet/cfg/yolov3.cfg"
#weights_path = download_testdata(WEIGHTS_URL, WEIGHTS_NAME, module="darknet")
weights_path = "yolov3.weights"
# 下载并加载DarkNet Library
if sys.platform in ['linux', 'linux2']:
DARKNET_LIB = 'libdarknet2.0.so'
# DARKNET_URL = REPO_URL + 'lib/' + DARKNET_LIB + '?raw=true'
elif sys.platform == 'darwin':
DARKNET_LIB = 'libdarknet_mac2.0.so'
# DARKNET_URL = REPO_URL + 'lib_osx/' + DARKNET_LIB + '?raw=true'
else:
err = "Darknet lib is not supported on {} platform".format(sys.platform)
raise NotImplementedError(err)
#lib_path = download_testdata(DARKNET_URL, DARKNET_LIB, module="darknet")
lib_path = "darknet/lib/libdarknet2.0.so"
# ******timepoint1-start*******
start1 = datetime.datetime.now()
# ******timepoint1-start*******
DARKNET_LIB = __darknetffi__.dlopen(lib_path)
net = DARKNET_LIB.load_network(cfg_path.encode('utf-8'), weights_path.encode('utf-8'), 0)
#net = DARKNET_LIB.load_network(cfg_path.encode('utf-8'), weights_path.encode('utf-8'), 0)
dtype = 'float32'
batch_size = 1
data = np.empty([batch_size, net.c, net.h, net.w], dtype)
shape_dict = {'data': data.shape}
print("Converting darknet to relay functions...")
#func, params = relay.frontend.from_darknet(net, dtype=dtype, shape=data.shape)
func, params = relay.frontend.from_darknet(net, dtype=dtype, shape=data.shape)
import ast
#s1 = ast.literal_eval(func)
#s2 = ast.literal_eval(params)
s1 = func
s2 = params
######################################################################
# 6、将图导入Relay
# -------------------------
# 编译模型
#target = 'llvm'
#target_host = 'llvm'
#ctx = tvm.cpu(0)
target = tvm.target.Target("llvm", host="llvm")
dev = tvm.cpu(0)
#wujianming20210713start
# optimization
print("optimize relay graph...")
with tvm.relay.build_config(opt_level=2):
func = tvm.relay.optimize(func, target, params)
# quantize
print("apply quantization...")
from tvm.relay import quantize
with quantize.qconfig():
func = quantize.quantize(s1, s2)
#wujianming20210713finsih
print("Compiling the model...")
#print(func.astext(show_meta_data=False))
#with relay.build_config(opt_level=3):
# graph, lib, params = tvm.relay.build(func, target=target, params=params)
# Save the model
#tmp = util.tempdir()
#tmp =tempdir()
#lib_fname = tmp.relpath('model.tar')
#lib_fname =os.path.relpath('model.tar')
#lib.export_library(lib_fname)
#[neth, netw] = shape['data'][2:] # Current image shape is 608x608
######################################################################
# Import the graph to Relay
# -------------------------
# compile the model
#target = tvm.target.Target("llvm", host="llvm")
#dev = tvm.cpu(0)
data = np.empty([batch_size, net.c, net.h, net.w], dtype)
shape = {"data": data.shape}
print("Compiling the model...")
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(func, target=target, params=params)
[neth, netw] = shape["data"][2:] # Current image shape is 608x608
######################################################################
# ******timepoint1-end*******
end1 = datetime.datetime.now()
# ******timepoint1-end*******
######################################################################
# 7、加载测试图片
# -----------------
test_image = 'dog.jpg'
print("Loading the test image...")
#img_url = REPO_URL + 'data/' + test_image + '?raw=true'
# img_path = download_testdata(img_url, test_image, "data")
img_path = "darknet/data/dog.jpg"
# ******timepoint2-start*******
start2 = datetime.datetime.now()
# ******timepoint2-start*******
data = tvm.relay.testing.darknet.load_image(img_path, netw, neth)
######################################################################
# 在TVM上执行
# ----------------------
# 过程与其他示例没有差别
#from tvm.contrib import graph_runtime
from tvm.contrib import graph_executor
#m = graph_runtime.create(graph, lib, ctx)
m = graph_executor.GraphModule(lib["default"](dev))
# 8、设置输入
m.set_input('data', tvm.nd.array(data.astype(dtype)))
m.set_input(**params)
# 执行
print("Running the test image...")
m.run()
# 9、获得输出
tvm_out = []
if MODEL_NAME == 'yolov2':
layer_out = {}
layer_out['type'] = 'Region'
# Get the region layer attributes (n, out_c, out_h, out_w, classes, coords, background)
layer_attr = m.get_output(2).asnumpy()
layer_out['biases'] = m.get_output(1).asnumpy()
out_shape = (layer_attr[0], layer_attr[1]//layer_attr[0],
layer_attr[2], layer_attr[3])
layer_out['output'] = m.get_output(0).asnumpy().reshape(out_shape)
layer_out['classes'] = layer_attr[4]
layer_out['coords'] = layer_attr[5]
layer_out['background'] = layer_attr[6]
tvm_out.append(layer_out)
elif MODEL_NAME == 'yolov3':
for i in range(3):
layer_out = {}
layer_out['type'] = 'Yolo'
# 获取YOLO层属性 (n, out_c, out_h, out_w, classes, total)
layer_attr = m.get_output(i*4+3).asnumpy()
layer_out['biases'] = m.get_output(i*4+2).asnumpy()
layer_out['mask'] = m.get_output(i*4+1).asnumpy()
out_shape = (layer_attr[0], layer_attr[1]//layer_attr[0],
layer_attr[2], layer_attr[3])
layer_out['output'] = m.get_output(i*4).asnumpy().reshape(out_shape)
layer_out['classes'] = layer_attr[4]
tvm_out.append(layer_out)
# 10、检测,并进行框选标记。
thresh = 0.5
nms_thresh = 0.45
img = tvm.relay.testing.darknet.load_image_color(img_path)
_, im_h, im_w = img.shape
dets = tvm.relay.testing.yolo_detection.fill_network_boxes((netw, neth), (im_w, im_h), thresh, 1, tvm_out)
last_layer = net.layers[net.n - 1]
tvm.relay.testing.yolo_detection.do_nms_sort(dets, last_layer.classes, nms_thresh)
# ******timepoint2-end*******
end2 = datetime.datetime.now()
# ******timepoint2-end*******
#coco_name = 'coco.names'
#coco_url = REPO_URL + 'data/' + coco_name + '?raw=true'
#font_name = 'arial.ttf'
#font_url = REPO_URL + 'data/' + font_name + '?raw=true'
#coco_path = download_testdata(coco_url, coco_name, module='data')
#font_path = download_testdata(font_url, font_name, module='data')
coco_path = "darknet/data/coco.names"
font_path = "darknet/data/arial.ttf"
# ******timepoint3-start*******
start3 = datetime.datetime.now()
# ******timepoint3-start*******
with open(coco_path) as f:
content = f.readlines()
names = [x.strip() for x in content]
tvm.relay.testing.yolo_detection.draw_detections(font_path, img, dets, thresh, names, last_layer.classes)
# ******timepoint3-end*******
end3 = datetime.datetime.now()
# ******timepoint3-end*******
print(end1-start1)
print(end2-start2)
print(end3-start3)
plt.imshow(img.transpose(1, 2, 0))
plt.savefig('image.png')
plt.show()
最后保存图片
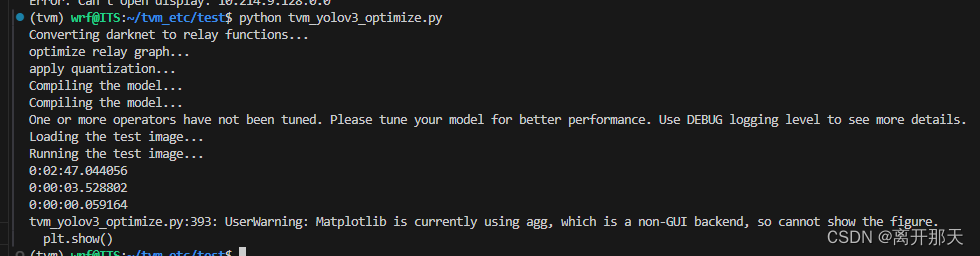

这后面几个时间看不太懂,以后看懂了再解析一下子
下面就是对PackedFunc类里面的东西进行解析
就是PackedFunc包含了TVMArgs,TVMRetValue。
然后把参数输入,返回值返回
接着介绍函数注册
在看源码的时候有个很奇怪的问题
#include <bits/stdc++.h>
using namespace std;
#define TVM_STR_CONCAT_(__x, __y) __x##__y
#define TVM_STR_CONCAT(__x, __y) TVM_STR_CONCAT_(__x, __y)
#define ali(name) TVM_STR_CONCAT(name, __COUNTER__)
int ali(a) = 1;
int main(){
cout << a0;
return 0;
}
这样是ok的
但是
#include <bits/stdc++.h>
using namespace std;
//#define TVM_STR_CONCAT_(__x, __y) __x##__y
#define TVM_STR_CONCAT(__x, __y) __x##__y
#define ali(name) TVM_STR_CONCAT(name, __COUNTER__)
int ali(a) = 1;
int main(){
cout << a0;
return 0;
}
这样是不行的
注册的话可以看源码

set_body_typed是在注册编译期不能确定函数参数和返回类型的情况,或者在运行时动态确定函数类型的情况。保证类型安全
set_body就是编译期可以确定的情况下使用
set_body_method是注册类内函数
这里必须得传PackedFunc 类型,刚好可以用[](args, ret)来构造
Registry& set_body(PackedFunc f)
这里传进来是啥就是啥
template <typename FLambda>
Registry& set_body_typed(FLambda f)
Register类中的设计
首先是三个set_body
然后是静态方法Register和Get
分别负责new出Registry对象放到manager里面
和获取名字对应的Register
然后在使用的时候就是TVM_REGISTER_GLOBAL(“xxx”).set_body()
上层python调用C++函数
是通过TVM动态库
然后python里面对sys.modules这个字典进行修改
从而达到调用C++的效果
我只能说吴建明老师对这本书不太用心,不过我还是找到了有用的东西,书上的代码完全不能看,我回溯了他的博客
https://www.cnblogs.com/wujianming-110117/p/15542763.html
这是他的博客
然后顺藤摸瓜
发现最初的代码是跑在v0.7的
https://zhuanlan.zhihu.com/p/258432371
我修改了一下代码
import tvm
from tvm import te
import numpy as np
from tvm import relay
# from tvm.topi.testing import conv2d_nchw_python
import tvm.topi.testing
# Tensor Expression
# args: (shape, label)
A = te.placeholder((10,), name='A')
B = te.placeholder((10,), name='B')
# args: (shape, function, label)
# function represented in lambda expression (element-wise)
# lambda axis1, axis2, ... : f(axis1, axis2, ...)
C = te.compute((10,), lambda i: A[i] + B[i], name="C")
# generate schedule
s = te.create_schedule(C.op)
# print low level codes
print(tvm.lower(s,[A,B,C],simple_mode=True))
# for (i: int32, 0, 10) {
# C_2[i] = ((float32*)A_2[i] + (float32*)B_2[i])
# }
# split(parent[, factor, nparts])
# Split the stage either by factor providing outer scope, or both. Return outer, inner vaiable of iteration.
bx, tx = s[C].split(C.op.axis[0],factor=2)
print(tvm.lower(s,[A,B,C],simple_mode=True))
tgt_host = "llvm"
# Change it to respective GPU if gpu is enabled Ex: cuda, opencl, rocm
tgt = "llvm" # cuda llvm
n = 10
fadd = tvm.build(s, [A, B, C], tgt, target_host=tgt_host, name="myadd")
ctx = tvm.device(tgt,0)
a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), ctx)
b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), ctx)
c = tvm.nd.array(np.zeros(n,dtype=C.dtype), ctx)
fadd(a,b,c) # run
# test
tvm.testing.assert_allclose(c.asnumpy(),a.asnumpy() + b.asnumpy())
print(fadd.get_source())
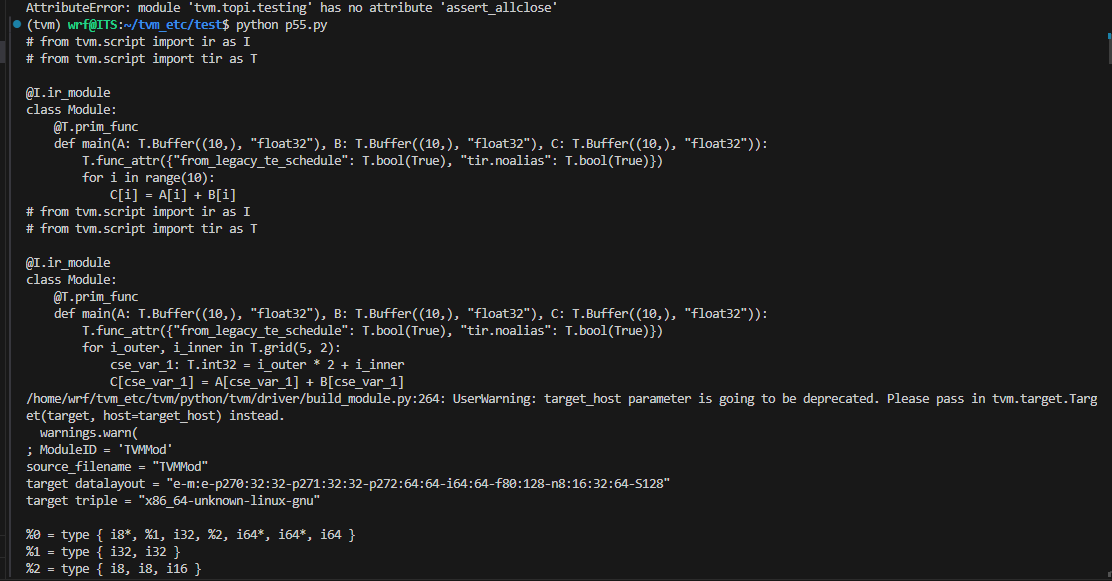
能跑出来
这段代码就是演示一下构建一个向量加法计算图,然后build执行
后面讲的都是build的原理
看不懂思密达
https://chhzh123.github.io/blogs/2020-03-26-tvm-flow/#relaybuild
为何书上要写gcn
这篇博客会给出答案
总之第二章看完了
看起来还可以
至少是能让我学到东西的
明天继续看
第三章
算子融合,也就是fusion,可以有效减少计算量和访存次数
常量折叠
常量折叠是一种编译器优化技术,它涉及在编译时期简化常数表达式的过程。具体来说,常量折叠意味着编译器会直接计算并替换掉表达式中的常量部分,用计算得到的结果来替换原来的表达式。这种优化技术可以减少运行时的计算开销,从而提高程序的执行效率和性能。此外,常量折叠还可以减小可执行文件的体积,并简化代码。12
过程:常量折叠发生在编译时期,编译器直接对表达式中的常量部分进行计算和替换。这个过程类似于宏替换,但与宏替换不同的是,常量折叠是编译器优化的一部分,旨在提高程序的运行效率。
应用:常量折叠被广泛应用于现代编译器中,作为一种重要的优化技术。它不仅可以增加程序的精确度,还可以更精确地传播常数及无缝地移除无用的代码。
注意事项:虽然常量折叠可以提高程序的性能,但使用它时需要注意可能的副作用,如编译时间的增加以及数值溢出等问题。此外,由于编译器在编译时期就进行了常量的计算和替换,因此任何在运行时依赖于未计算常量的行为都可能受到影响。
综上所述,常量折叠是一种在编译时期进行的优化技术,通过直接计算并替换表达式中的常量部分,来提高程序的执行效率和性能。
静态内存规划
静态内存规划(Static Memory Allocation)是指在程序编译时决定内存的分配,而不是在程序运行时动态地分配内存。在静态内存规划中,所有变量和数据结构的内存空间在编译时就已经确定,程序运行期间不会再发生内存分配和释放操作。这种方式有几个显著的特点和优缺点:
特点
固定大小:编译时内存分配大小是固定的,程序运行时无法改变。
效率高:由于内存分配是在编译时完成的,程序运行时无需额外的内存管理操作,运行效率较高。
确定性强:内存地址在编译时就确定,容易进行内存访问和管理,调试也较为方便。
优点
性能高:没有动态内存分配和释放的开销,适合对性能要求高的场景。
简单性:内存管理简单,不需要处理动态内存分配可能引起的碎片化问题。
安全性高:由于内存地址和大小在编译时确定,避免了运行时的内存分配错误(如内存泄漏和越界访问)。
缺点
灵活性差:内存大小在编译时确定,运行时不能根据需要调整,可能导致内存浪费或不足。
不适合大型或复杂程序:对于需要动态调整内存大小的应用场景,静态内存规划不合适。
编译期限制:需要在编译期就预估好所需内存,增加了编程的难度。
典型应用场景
静态内存规划常用于嵌入式系统、实时系统等对内存管理要求严格且需要高效运行的场合。这类系统通常资源有限,且程序逻辑较为固定,适合采用静态内存分配。
总的来说,静态内存规划适合一些对性能要求高、内存需求较为确定的应用场景,但在需要灵活内存管理的复杂应用中,其局限性也显而易见。
数据布局变换
数据布局变换(Data Layout Transformation)是指对程序中数据的存储布局进行调整和优化,以提高程序的性能。这种优化可以在编译阶段进行,也可以在运行时通过特定的优化技术来实现。数据布局变换的**主要目的是提高缓存命中率、减少内存访问延迟**、提升数据并行处理效率等。以下是一些常见的数据布局变换技术及其应用场景:
常见的数据布局变换技术
数组重排(Array Reordering):
重新排列数组的存储顺序,使得相关数据更靠近,从而提高缓存命中率。
典型应用:在多维数组的处理中,改变数据存储顺序以优化访问模式。
结构体字段排列(Struct Field Reordering):
调整结构体中字段的顺序,使得频繁访问的字段尽量靠近。
典型应用:减少由于结构体内存对齐而产生的填充空间,优化内存使用。
内存对齐(Memory Alignment):
调整数据的存储地址,使其符合特定的对齐要求,以提高访问效率。
典型应用:在向量化计算或需要高效内存访问的场景中使用。
数组分块(Blocking or Tiling):
将大数组分解为较小的块,逐块进行处理,从而提高缓存利用率。
典型应用:矩阵运算、图像处理等需要处理大规模数据的应用。
数据布局转换(Data Layout Transformation):
将一种数据布局转换为另一种数据布局,以适应不同的计算模式或硬件特性。
典型应用:在图形处理或大数据处理中的行列变换(Row-Major Order 和 Column-Major Order)。
存储模式转换(Storage Format Transformation):
在压缩和解压缩、稀疏矩阵存储格式转换等场景中,通过转换存储格式来提高处理效率。
典型应用:稀疏矩阵的CSR(Compressed Sparse Row)和CSC(Compressed Sparse Column)格式转换。
优化目标
提高缓存命中率:通过优化数据布局,使得程序访问的数据尽量在缓存中,从而减少内存访问延迟。
减少内存带宽占用:通过对数据进行紧凑存储和优化访问模式,减少内存带宽的占用。
提高并行处理效率:通过对数据进行分块和对齐,使得并行处理更加高效。
减少内存碎片:通过合理的数据布局,减少内存分配中的碎片问题,提高内存使用效率。
典型应用场景
高性能计算:在科学计算、工程模拟等需要大量数据处理和计算的领域,数据布局变换能够显著提高计算效率。
图形处理:在图像和视频处理、计算机图形学中,通过数据布局变换优化数据访问模式,提升处理性能。
数据库系统:在数据库系统中,通过优化数据存储布局,提升查询和数据处理的效率。
总之,数据布局变换是一种重要的优化技术,通过合理调整数据的存储布局,可以显著提升程序的性能。
自动buffer融合优化技术
内存墙问题
内存墙问题是指在计算机系统中,特别是在多核处理器和并行计算环境中,由于处理器速度与内存访问速度之间的差距导致的性能瓶颈。具体来说,处理器的速度远远快于内存的访问速度,这导致处理器在等待数据从内存加载或存储时处于空闲状态,从而降低了系统的整体效率。
内存墙问题通常出现在以下情况下:
数据依赖:当处理器需要等待某些数据加载完成后才能继续执行,而这些数据的加载速度受到内存访问速度的限制。
内存带宽:处理器需要大量数据传输时,内存的带宽限制可能导致数据传输速度无法满足处理器的需求。
并行处理:在多核处理器中,多个处理核心同时访问内存时可能会竞争内存带宽,进而限制整体性能的提升。
解决内存墙问题通常需要采取多种策略,例如优化数据访问模式、增加缓存的利用效率、改进内存系统的设计与管理等措施,以减少处理器等待内存数据的时间,从而提高系统的整体性能。
AStitch技术讲相互依赖的算子通过层次化存储媒介,进一步“缝合在一起”,不再依赖融合算子循环空间的深度合并















 3038
3038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









