







文章目录
profile源码位置:
- https://github.com/iovisor/bcc/blob/master/tools/profile.py
因为个人的研究需要,所以对bcc提供的tools之一cpu profile工具进行了源码的学习,本文章已假设你已经看懂了上面的python前端链接逻辑,下面会深入的具体的源码实现解析流程。总体上会已注释的形式直接在源码边上注解,并会在重要的部分配上了草图。个人理解,如有错误请指正,共同进步…
零、基础
1. perf-event的基本原理
PMC
性能监控计数器PMC,别名:PIC、CPC、PMU event
Linux性能计数器是一个新的基于内核的子系统,它提供一个性能分析框架,比如硬件(CPU、PMU(Performance Monitoring Unit))功能和软件(软件计数器、tracepoint)功能
作用:处理器上的硬件可编程计数器
两种模式:
- 计数:
PMC跟踪事件发生的频率,内核随时可以读取,开销基本可以忽略不计 - 溢出采样:
PMC所监控的事件发生到一定次数时通知内核(中断),让内核获取额外的状态
perf
基本概念:Perf 是内置于 Linux 内核源码树中的性能剖析(profiling)工具。它基于事件采样的原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析。可用于性能瓶颈的查找与热点代码的定位,其基本架构如图所示:
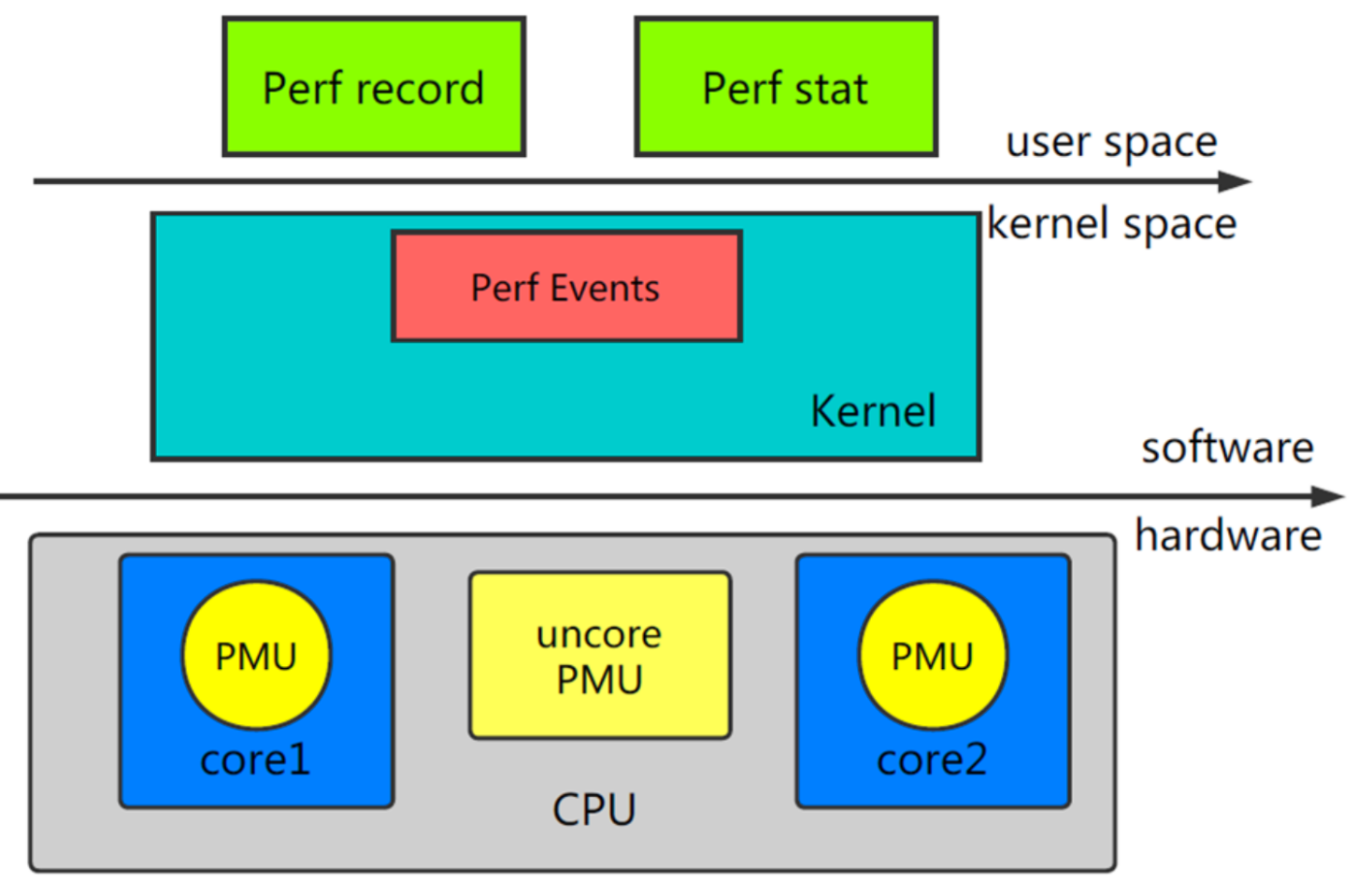
所支持的事件包括:
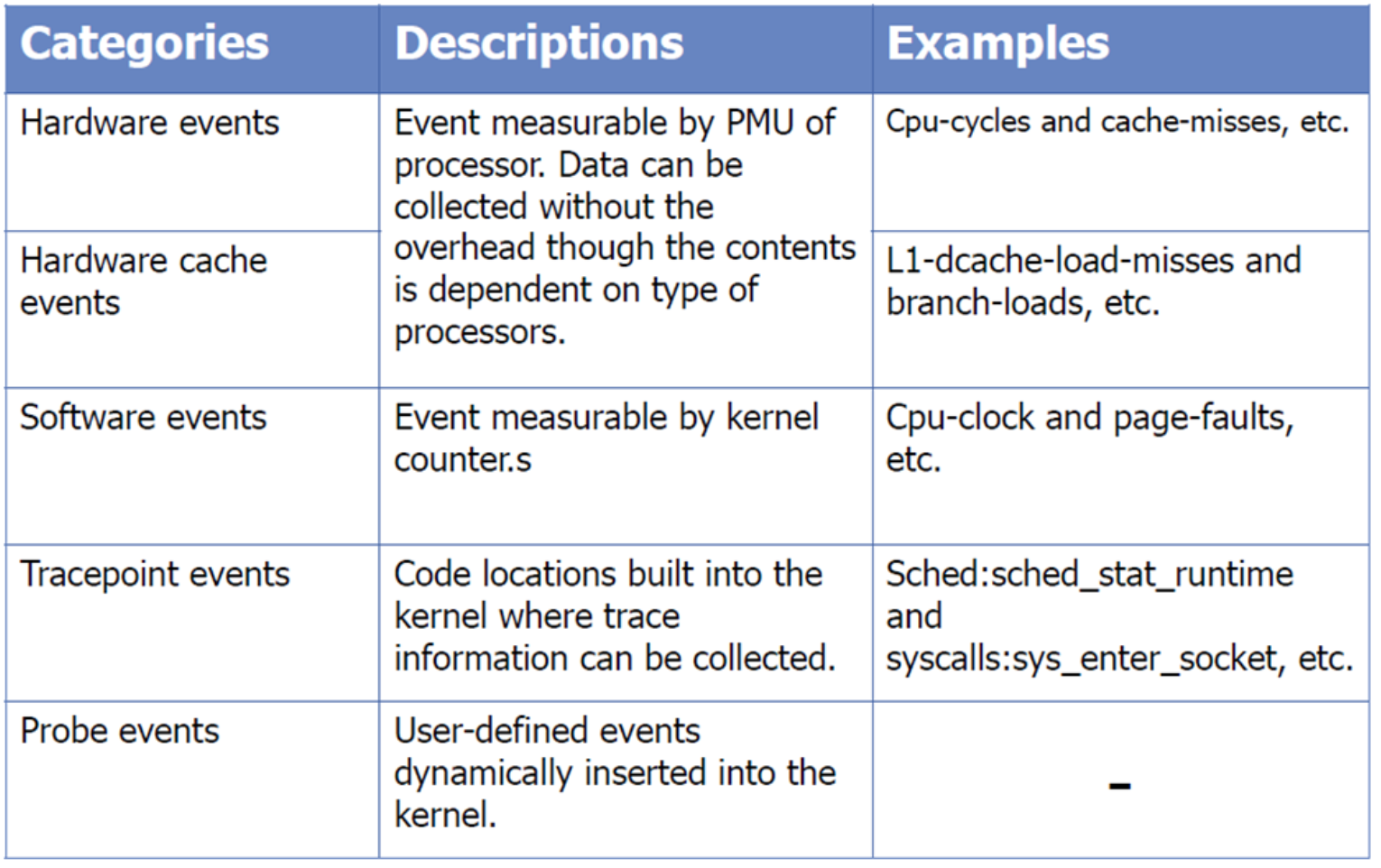
- 硬件性能事件(
Hardware event): 由PMU硬件产生的事件, 在特定的条件下探测性能事件是否发生以及发生的次数, 比如cache命中 - 软件性能事件(
Software event): 内核产生的事件,分布在各个功能模块中,统计和操作系统相关性能事件. 比如进程切换,tick数等 tracepoint event: 内核中的静态tracepoint所触发的事件,这些tracepoint用来判断程序运行期间内核的行为细节,比如SLAB分配器的分配次数等
或者是这张图:
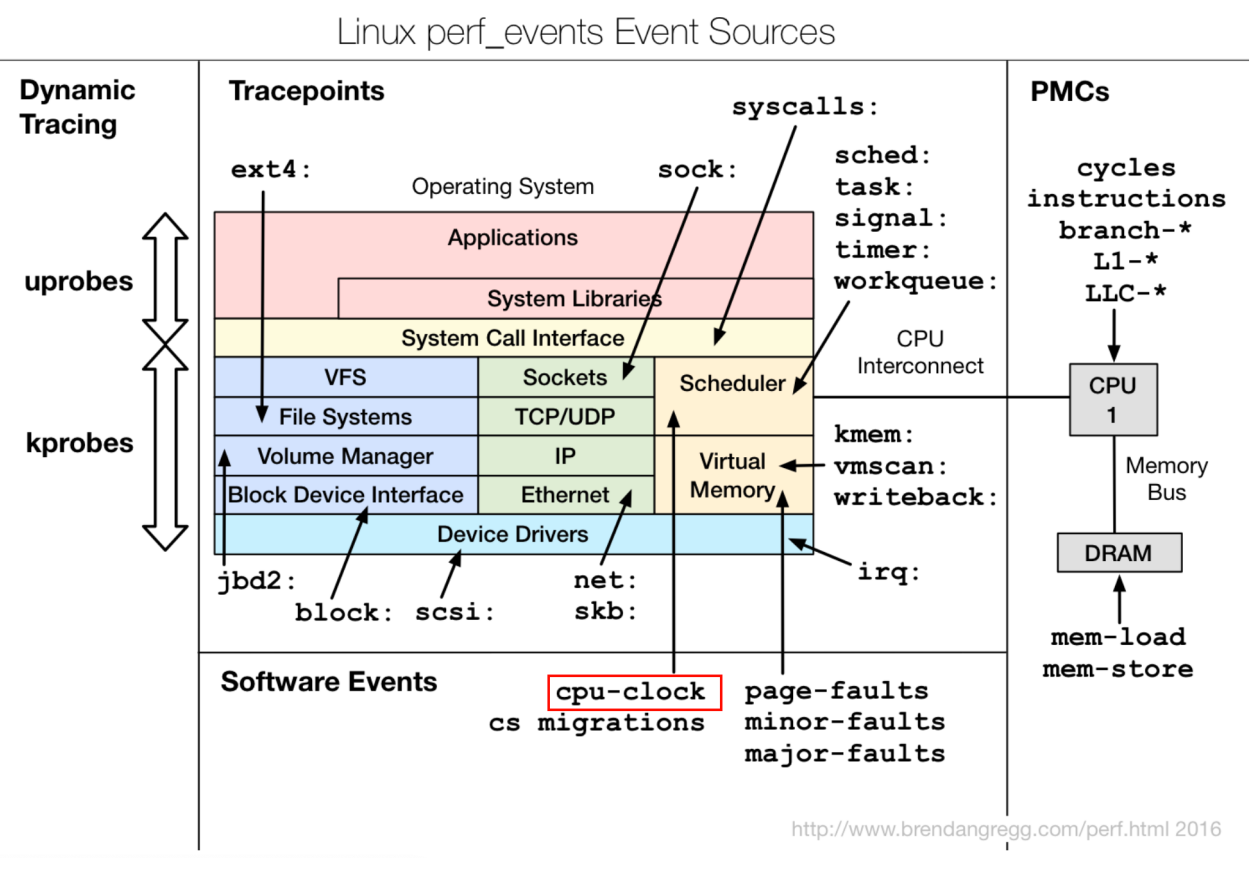
关于
perf,比较完整的资料见:https://github.com/freelancer-leon/notes/blob/master/kernel/profiling/perf.md
基本流程(一个例子):
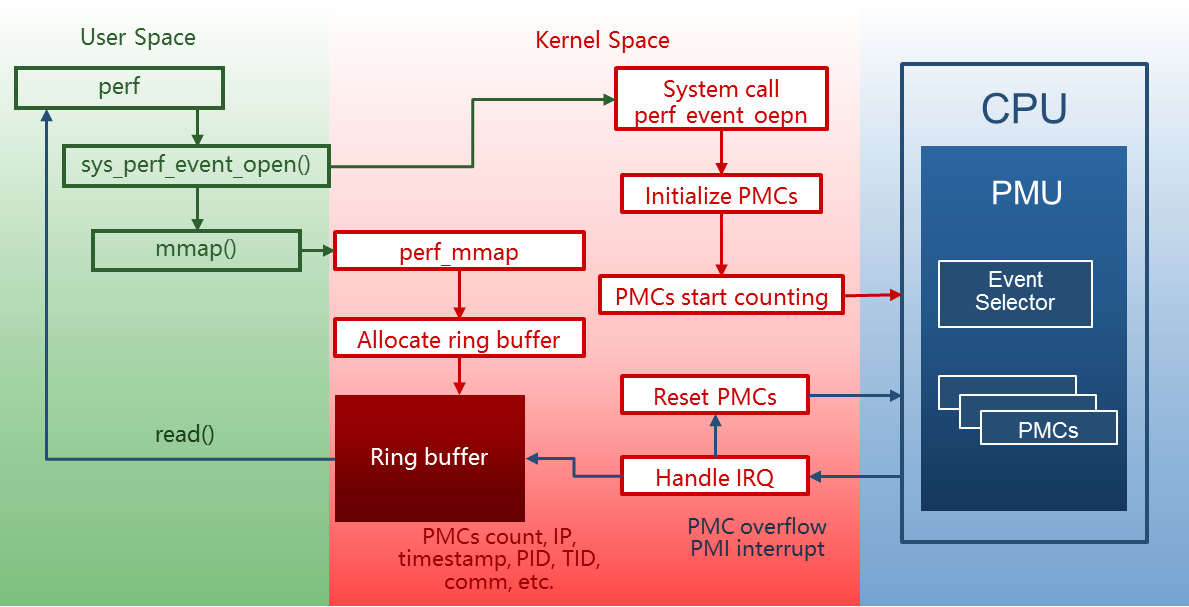
- perf 会通过系统调用
sys_perf_event_open在内核中注册一个监测cycles事件的性能计数器 - 内核根据 perf 提供的信息在 PMU 上初始化一个 硬件性能计数器(
Hardware performance counter) - 硬件性能计数器随着 CPU 周期的增加而自动累加
- 在硬件性能计数器溢出时,PMU 触发一个 PMI(
Performance Monitoring Interrupt)中断 - 内核在
PMI中断的处理函数中保存以下信息,这些信息统称为一个采样(sample)- 硬件性能计数器的计数值
- 触发中断时的指令地址(
Register IP:Instruction Pointer) - 当前时间戳
- 当前进程的
PID,TID,comm等信息
- 内核会将收集到的 sample 放入用于跟用户空间通信的
ring buffer - 用户空间里的 perf 分析程序采用
mmap机制从ring buffer中读入采样,并对其解析 - perf 根据
pid,comm等信息可以找到对应的进程 - perf 根据
IP与ELF文件中的符号表可以查到触发PMI中断的指令所在的函数- 为了能够使 perf 读到函数名,我们的目标程序必须具备 符号表·
perf的分析结果中只看到一串地址,而没有对应的函数名时,通常是由于用strip删除了 ELF 文件中的符号表
2. 帧指针调用栈回溯原理
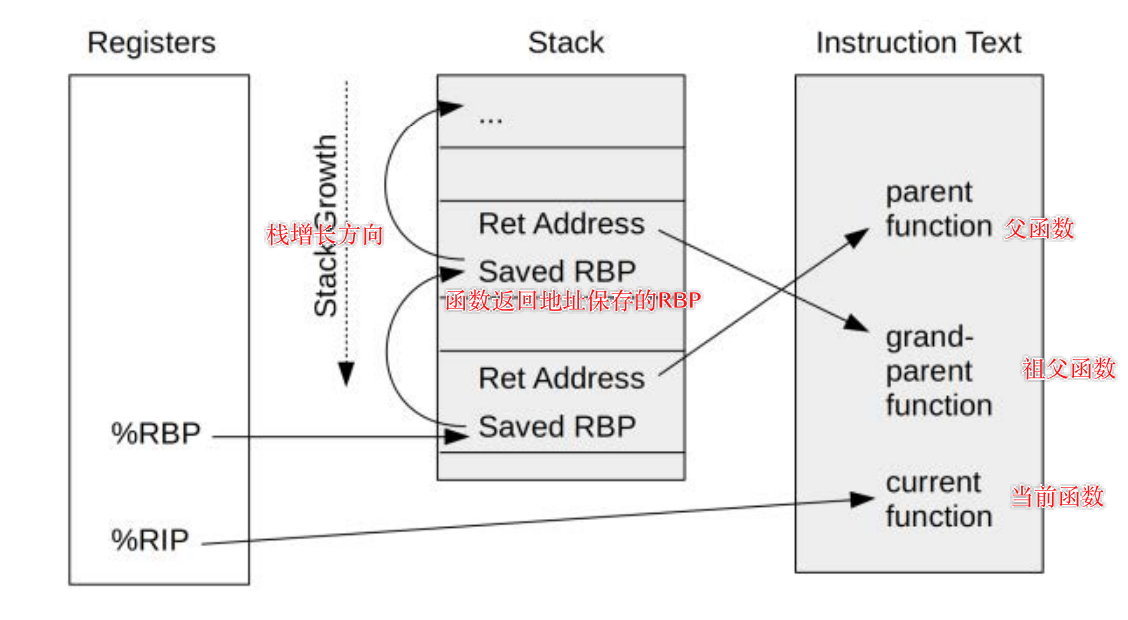
基本工作原理:
- 调用栈帧链表头部地址始终保存在RBP寄存器(X86_64)中(X86中是使用ebp寄存器保存栈帧地址,esp保存栈顶指针)
- 函数的返回地址位置始终在RBP的值指向位置+8的偏移量
- 任何调试器或跟踪器在中断程序之后就可以通过读取RBP的地址值作为链表头部进行不断的回溯
缺点:
- 占用了一个通用寄存器
- 此方式逐渐被淘汰
一、执行逻辑
整体的执行逻辑如下:
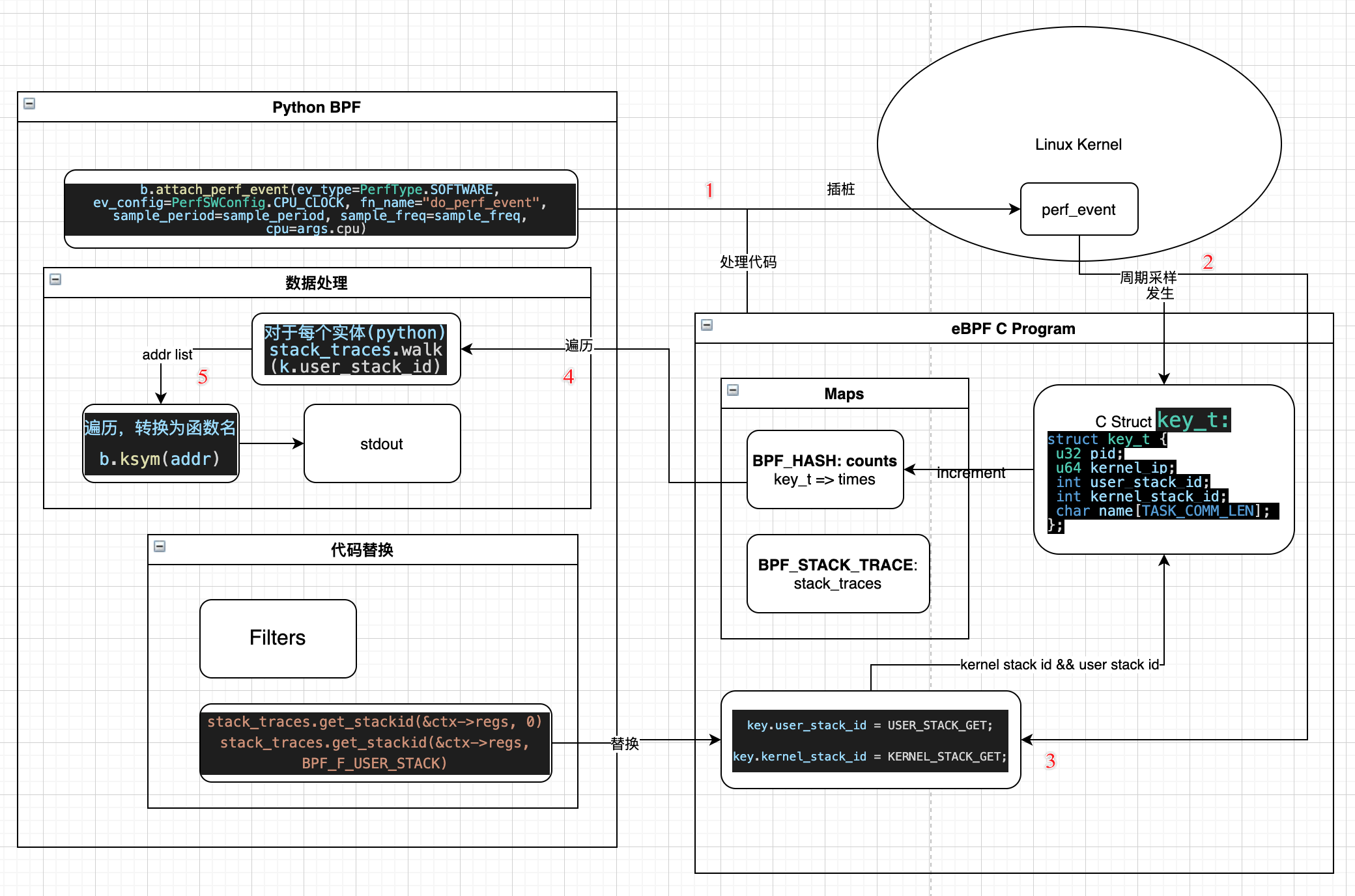
- 对内核
perf_event事件设置CPU的时钟周期性采样插桩,并设置eBPF的C处理逻辑代码 - 当周期性事件发生后,执行处理逻辑,填充结构体
key_t(包括进程pid和命令名name) - 此外通过
int map.get_stackid(void *ctx, u64 flags)分别获取内核栈、用户栈的id,此函数将返回唯一的调用栈id, 填充到key_t, 同时BPF_HASH用于保存每个对象的计数/出现次数 - 在
ctrl+C之后,遍历获取所有的实体对象(此时是python对象,bpf库已经帮我们从C对象自动转换);对于每个实体调用stack_teaces.walk()根据其栈id不断向上索引整个调用栈函数地址,最终将所有地址保存为一个list - 遍历
addr list对于每个地址调用ksym(addr)函数将地址映射获取为对应的函数名 - 最终输出到标准输出
二. 重点细节
一些重点函数的细节逻辑:
1. key_t数据对象的赋值过程
struct key_t {
u32 pid; // 用户空间下的PID
u64 kernel_ip;
int user_stack_id; // 用户栈ID
int kernel_stack_id; // 内核栈ID
char name[TASK_COMM_LEN]; // 内核命令名
u64 timestamp; // 时间戳
};
#include <uapi/linux/ptrace.h>
#include <uapi/linux/bpf_perf_event.h>
#include <linux/sched.h>
struct key_t {
u32 pid; // 用户空间下的PID
u64 kernel_ip; // 内核指令指针
int user_stack_id; // 用户调用栈ID
int kernel_stack_id; // 内核调用栈ID
char name[TASK_COMM_LEN]; // 内核命令名
u64 timestamp; // 时间戳
};
BPF_HASH(counts, struct key_t);
BPF_STACK_TRACE(stack_traces, STACK_STORAGE_SIZE); // 栈存储,使用栈ID索引
// This code gets a bit complex. Probably not suitable for casual hacking.
int do_perf_event(struct bpf_perf_event_data *ctx) {
// 分别获取pid和tgid
u64 id = bpf_get_current_pid_tgid();
u32 tgid = id >> 32; // 高32位是线程组ID(在用户空间为PID)
u32 pid = id; // 低32位是进程pid(在用户空间为线程id)
// 用于替换判断某些功能是否开启
if (IDLE_FILTER)
return 0;
if (!(THREAD_FILTER))
return 0;
if (container_should_be_filtered()) {
return 0;
}
// create map key
struct key_t key = {.pid = tgid};
// 获取当前命令
bpf_get_current_comm(&key.name, sizeof(key.name));
// 获取时间戳
key.timestamp = bpf_ktime_get_ns(); // 内核事件戳,纳秒为单位
// get stacks
key.user_stack_id = USER_STACK_GET;
key.kernel_stack_id = KERNEL_STACK_GET;
// 获取kernel_ip
if (key.kernel_stack_id >= 0) {
// populate extras to fix the kernel stack
u64 ip = PT_REGS_IP(&ctx->regs);
u64 page_offset;
// if ip isn't sane, leave key ips as zero for later checking 如果获得的ip不够完整就设置为0值,用于最后的检测
// 区分不同的硬件架构
#if defined(CONFIG_X86_64) && defined(__PAGE_OFFSET_BASE)
// x64, 4.16, ..., 4.11, etc., but some earlier kernel didn't have it
page_offset = __PAGE_OFFSET_BASE;
#elif defined(CONFIG_X86_64) && defined(__PAGE_OFFSET_BASE_L4)
// x64, 4.17, and later
#if defined(CONFIG_DYNAMIC_MEMORY_LAYOUT) && defined(CONFIG_X86_5LEVEL)
page_offset = __PAGE_OFFSET_BASE_L5;
#else
page_offset = __PAGE_OFFSET_BASE_L4;
#endif
#else
// earlier x86_64 kernels, e.g., 4.6, comes here
// arm64, s390, powerpc, x86_32
page_offset = PAGE_OFFSET;
#endif
// 通过比较与页偏移量的大小来校对通过PT_REGS_IP获取的IP是否是完整的
if (ip > page_offset) {
key.kernel_ip = ip;
}
}
// 加入到map映射中,累计++
counts.increment(key);
return 0;
}
-
pid:通过bpf_get_current_pid_tgid();辅助函数得到一个64位的ID, 高32位就是tgid线程组ID,也就是用户态的PID,低32位是pid,在用户态是线程ID;所以就将高32位的ID值赋值给Pid// 分别获取pid和tgid u64 id = bpf_get_current_pid_tgid(); u32 tgid = id >> 32; // 高32位是线程组ID(在用户空间为PID) u32 pid = id; // 低32位是进程pid(在用户空间为线程id) ... struct key_t key = {.pid = tgid}; -
kernel_ip:内核指令指针instruction_pointer,作为额外的记录用于修复内核栈;使用PT_REGS_IP调用来获取当前寄存器上下文的指令位置,然后通过获取不同硬件架构的当前页偏移量,将通过PT_REGS_IP与页偏移量进行对比,如果超出就是非法地址保持IP为0, 如果在其中那么就赋值 -
user_stack_id: 用户调用栈的ID,通过此ID可以索引到此进程的所有用户栈地址key.user_stack_id = USER_STACK_GET;在python前端做了替换:
user_stack_get = "stack_traces.get_stackid(&ctx->regs, BPF_F_USER_STACK)" bpf_text = bpf_text.replace('USER_STACK_GET', user_stack_get)stack_traces就是BPF_STACK_TRACE(stack_traces, STACK_STORAGE_SIZE),BPF给这类数据结构提供了获取stack_id的方法:Syntax: int map.get_stackid(void *ctx, u64 flags) This walks the stack found via the struct pt_regs in ctx, saves it in the stack trace map, and returns a unique ID for the stack trace.会使用上下文的寄存器信息溯源的
walk并保存调用栈(也就是帧指针的方式),最终返回一个唯一的映射ID调用该函数使用了一个
BPF_F_USER_STACK的flag,就表示获取用户态的调用栈关于帧指针调用栈回溯的原理见<零基础>
-
kernel_stack_id:同理:key.kernel_stack_id = KERNEL_STACK_GET;kernel_stack_get = "stack_traces.get_stackid(&ctx->regs, 0)" bpf_text = bpf_text.replace('KERNEL_STACK_GET', kernel_stack_get)
2. 调用栈溯源逻辑
在python前端中,这一块的核心逻辑在于:
stack_traces = b.get_table("stack_traces")
...
user_stack = [] if k.user_stack_id < 0 else stack_traces.walk(k.user_stack_id) # stack_traces.walk(k.user_stack_id) 根据栈id追溯整个栈地址的过程; 这里没有传入解析函数,所以默认返回地址
kernel_tmp = [] if k.kernel_stack_id < 0 else stack_traces.walk(k.kernel_stack_id)
其返回溯源的一系列调用栈地址(用list保存),用于后面的解析
stack_traces.walk(k.kernel_stack_id) :
class StackTrace(TableBase):
MAX_DEPTH = 127
BPF_F_STACK_BUILD_ID = (1<<5)
BPF_STACK_BUILD_ID_EMPTY = 0 #can't get stacktrace
BPF_STACK_BUILD_ID_VALID = 1 #valid build-id,ip
BPF_STACK_BUILD_ID_IP = 2 #fallback to ip
def __init__(self, *args, **kwargs):
super(StackTrace, self).__init__(*args, **kwargs) # 调用父类初始化
class StackWalker(object):
def __init__(self, stack, flags, resolve=None):
self.stack = stack
self.n = -1 # 索引下标,也是调用栈的深度
self.resolve = resolve
self.flags = flags
# 定义了__iter__和__next__让StackWalker成为一个可迭代对象
def __iter__(self):
return self
def __next__(self):
return self.next()
def next(self):
self.n += 1
if self.n == StackTrace.MAX_DEPTH: # 到达最大高度就不再往下迭代了
raise StopIteration()
# 如果设置了build id的方式(flag判断)就使用此方式获取addr
if self.flags & StackTrace.BPF_F_STACK_BUILD_ID:
addr = self.stack.trace[self.n] # 获取对应下标的地址值
# 如果已经回滚到IP或者为空时,结束
if addr.status == StackTrace.BPF_STACK_BUILD_ID_IP or \
addr.status == StackTrace.BPF_STACK_BUILD_ID_EMPTY:
raise StopIteration()
else:
# 如果没设置那么就采用原本的方式
addr = self.stack.ip[self.n]
if addr == 0 :
raise StopIteration()
return self.resolve(addr) if self.resolve else addr
def walk(self, stack_id, resolve=None):
return StackTrace.StackWalker(self[self.Key(stack_id)], self.flags, resolve)
def __len__(self):
i = 0
for k in self: i += 1
return i
def clear(self):
pass
next函数获取地址addr的build_id方式和普通方式
什么是
Build ID?编译时指定的一个唯一构建id,可以用file xxx命令查看到这里的
Build ID的方式应该对应的是使用ELF文件的Build ID唯一标识的debuginfo
build_id方式对应需要使用BPF_STACK_TRACE_BUILDID这个映射数据结构:
bcc/src/cc/export/helpers.h:
struct bpf_stacktrace { // 传统方式
u64 ip[BPF_MAX_STACK_DEPTH]; // 对应上面的addr = self.stack.ip[self.n]
};
struct bpf_stacktrace_buildid {
struct bpf_stack_build_id trace[BPF_MAX_STACK_DEPTH]; // 对应上面的self.stack.trace[self.n]
};
#define BPF_STACK_TRACE(_name, _max_entries) \
BPF_TABLE("stacktrace", int, struct bpf_stacktrace, _name, roundup_pow_of_two(_max_entries))
#define BPF_STACK_TRACE_BUILDID(_name, _max_entries) \
BPF_F_TABLE("stacktrace", int, struct bpf_stacktrace_buildid, _name, roundup_pow_of_two(_max_entries), BPF_F_STACK_BUILD_ID)
而bpf_stack_build_id的具体结构可见bcc/libbpf-tools/x86/vmlinux.h:
enum bpf_stack_build_id_status {
BPF_STACK_BUILD_ID_EMPTY = 0,
BPF_STACK_BUILD_ID_VALID = 1,
BPF_STACK_BUILD_ID_IP = 2,
};
struct bpf_stack_build_id {
__s32 status;
unsigned char build_id[20];
union {
__u64 offset; // 偏移量
__u64 ip; // 指令地址
};
};
几个状态的意义:
BPF_F_STACK_BUILD_ID: 用于表示存储build_id+offset,也就是self.flag表示是一个build id的StackTraceBPF_STACK_BUILD_ID_EMPTY:状态表示调用栈的遍历结束BPF_STACK_BUILD_ID_VALID: 状态表示是一个有效的build_id+offset即bpf_stack_build_idBPF_STACK_BUILD_ID_IP: 此状态表示无法获得build_id,回退到IP这样的错误
Build_id详细可见commit:https://github.com/iovisor/bcc/commit/2ddbc07782c3ca4115a0840882e42dfb0c88686d
里面还有使用
BPF_STACK_TRACE_BUILDID这个Map映射数据结构的example
3. 符号表解析逻辑
在看细节之前先整理了一下总体的结构和源码基本的过程:
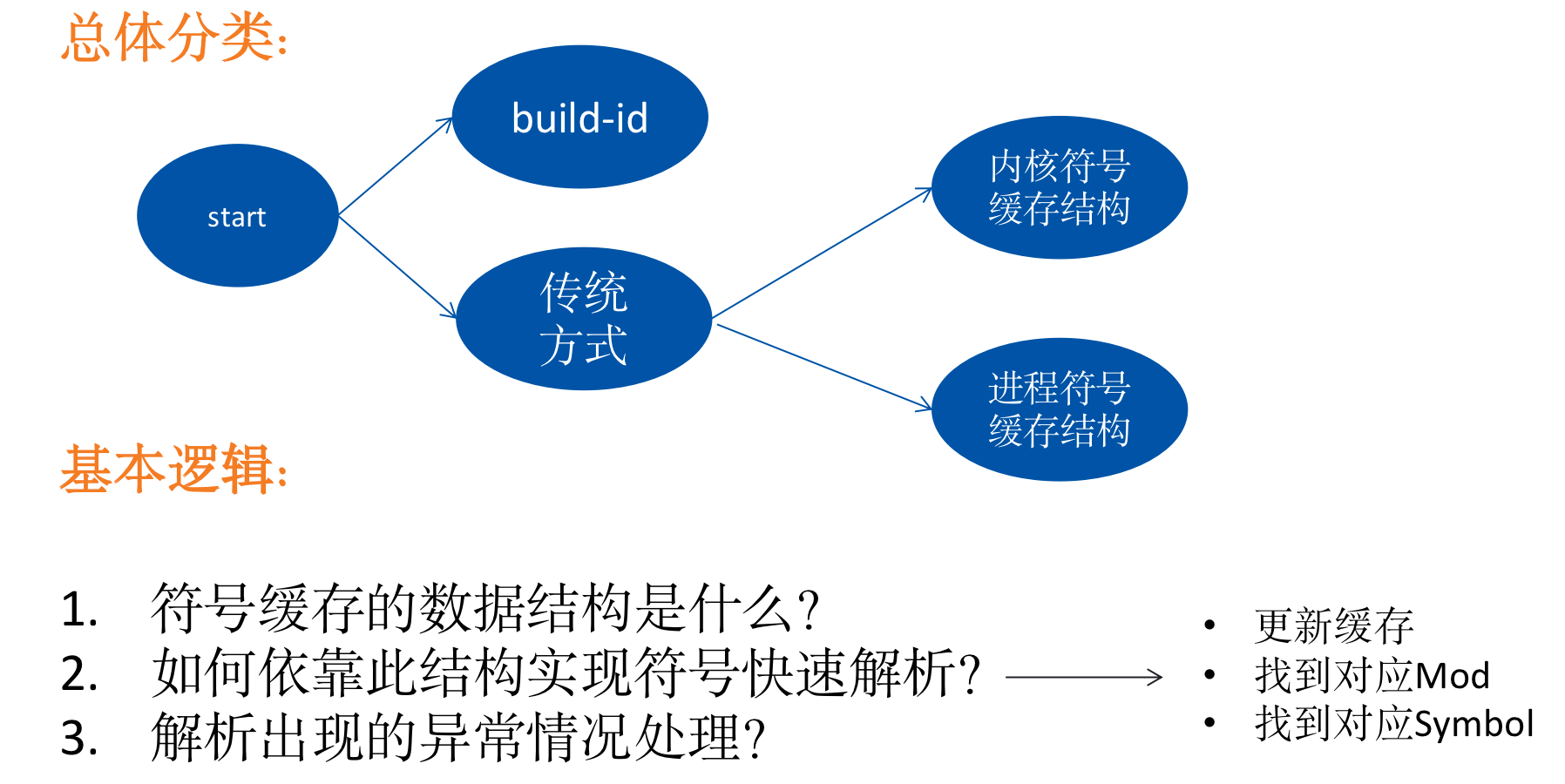
b.ksym(addr)
@staticmethod
def ksym(addr, show_module=False, show_offset=False):
"""ksym(addr)
Translate a kernel memory address into a kernel function name, which is
returned. When show_module is True, the module name ("kernel") is also
included. When show_offset is true, the instruction offset as a
hexadecimal number is also included in the string.
Example output when both show_module and show_offset are True:
"default_idle+0x0 [kernel]"
"""
return BPF.sym(addr, -1, show_module, show_offset, False)
@staticmethod
def sym(addr, pid, show_module=False, show_offset=False, demangle=True):
"""sym(addr, pid, show_module=False, show_offset=False)
Translate a memory address into a function name for a pid, which is
returned. When show_module is True, the module name is also included.
When show_offset is True, the instruction offset as a hexadecimal
number is also included in the string.
A pid of less than zero will access the kernel symbol cache.
Example output when both show_module and show_offset are True:
"start_thread+0x202 [libpthread-2.24.so]"
Example output when both show_module and show_offset are False:
"start_thread"
"""
#addr is of type stacktrace_build_id
#so invoke the bsym address resolver
typeofaddr = str(type(addr))
# 如果是stacktrace_build_id类型就用bcc_buildsymcache_resolve解析
if typeofaddr.find('bpf_stack_build_id') != -1:
# 创建字符集对象
sym = bcc_symbol()
# 创建build_id对象
b = bcc_stacktrace_build_id()
# 给其赋值
b.status = addr.status
b.build_id = addr.build_id
b.u.offset = addr.offset;
# 调用libbcc库解析(通过bsymc缓存)
res = lib.bcc_buildsymcache_resolve(BPF._bsymcache,
ct.byref(b),
ct.byref(sym))
# 判断返回值结果
if res < 0:
if sym.module and sym.offset:
name,offset,module = (None, sym.offset,
ct.cast(sym.module, ct.c_char_p).value)
else:
name, offset, module = (None, addr, None)
else:
name, offset, module = (sym.name, sym.offset,
ct.cast(sym.module, ct.c_char_p).value)
# 否则调用_sym_cache解析
else:
name, offset, module = BPF._sym_cache(pid).resolve(addr, demangle)
# 处理结果
offset = b"+0x%x" % offset if show_offset and name is not None else b""
name = name or b"[unknown]"
name = name + offset
# 添加模块信息
module = b" [%s]" % os.path.basename(module) \
if show_module and module is not None else b""
return name + module
地址解析的两种方式:
- 如果地址类型是
bpf_stack_build_id类型,那么就调用libbcc库的buildsymcache解析(通过bsymc缓存) - 否则用调用
_sym_cache解析
1.build_id类型
其中bcc对象的结构如下, 作用就是保存地址解析的结果
struct bcc_symbol {
const char *name;
const char *demangle_name; // 程序在编译之后函数的名字是否被编译器修改,改为内部的名字(C++ ABI标识符)
const char *module; // 所属的模块名
uint64_t offset; // 偏移量
};
其中bcc_stacktrace_build_id返回的基本结构:
class bcc_stacktrace_build_id(ct.Structure):
_fields_ = [
('status', ct.c_uint32),
('build_id',ct.c_ubyte*20),
('u',bcc_ip_offset_union)
]
这里传入的addr的结构见上面bpf_stack_build_id, 所以直接依次赋值即可
BPF._bsymcache:源自于python前端一开始的缓存创建
_bsymcache = lib.bcc_buildsymcache_new()
void *bcc_buildsymcache_new(void) {
return static_cast<void *>(new BuildSyms()); // 创建一个新的build缓存实例
}
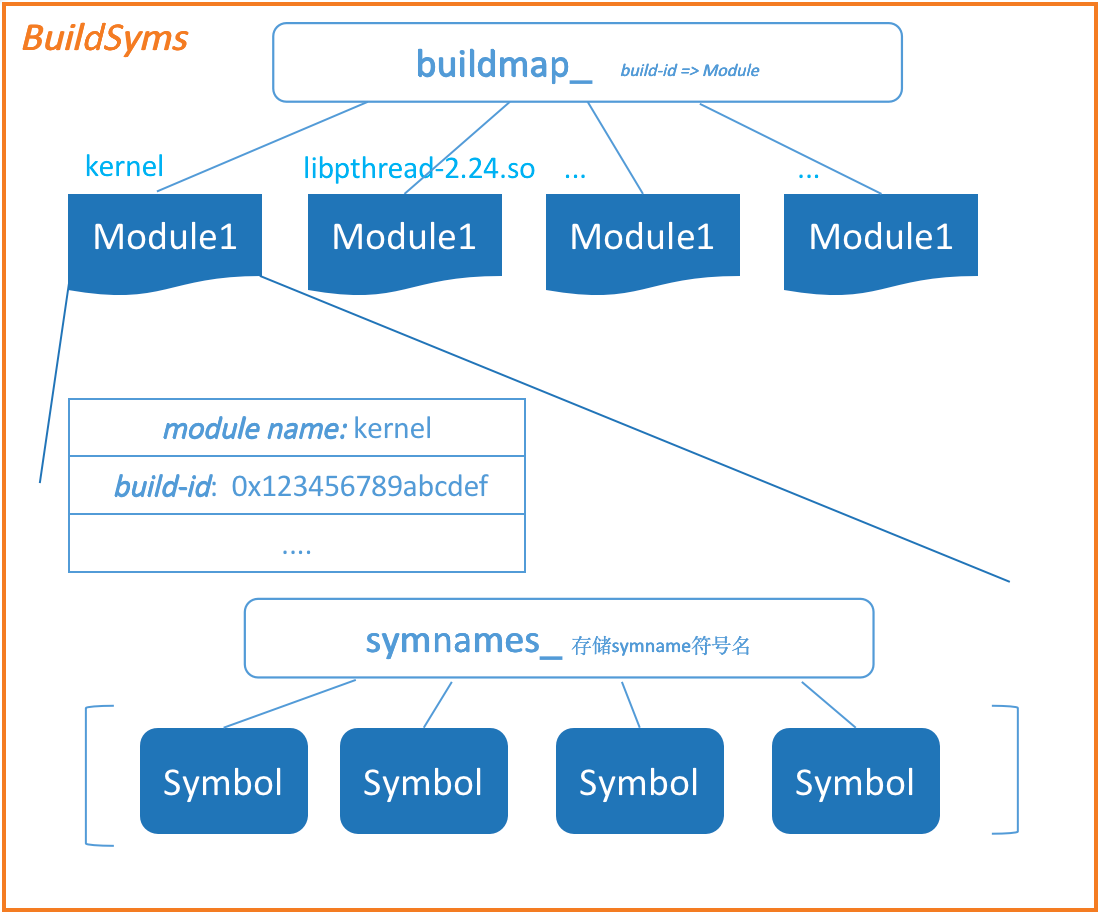
缓存定义的结构体和函数如下:
class BuildSyms {
struct Symbol { // 每个符号结构
Symbol(const std::string *name, uint64_t start, uint64_t size)
:name(name), start(start), size(size) {}
const std::string *name;
uint64_t start; // 开始位置
uint64_t size; // 大小
bool operator<(const struct Symbol &rhs) const { // 排序的比较函数
return start < rhs.start;
}
};
struct Module { // 每个模块(也就是文件名,例如内核是kernel、libpthread-2.24.so)
Module(const char *module_name):
module_name_(module_name),
loaded_(false) {}
const std::string module_name_; // 模块名
const std::string build_id_; // 每个ELF都有的Build_id
bool loaded_;
std::unordered_set<std::string> symnames_;
std::vector<Symbol> syms_; // 每个模块的符号表
bcc_symbol_option symbol_option_;
bool load_sym_table();
static int _add_symbol(const char *symname, uint64_t start, uint64_t size,
void *p);
bool resolve_addr(uint64_t offset, struct bcc_symbol*, bool demangle=true);
};
// build_id => BuildSyms::Module
std::unordered_map<std::string, std::unique_ptr<Module> > buildmap_;
public:
BuildSyms() {}
virtual ~BuildSyms() = default;
virtual bool add_module(const std::string module_name); // 添加一个模块符号表
virtual bool resolve_addr(std::string build_id, uint64_t offset, struct bcc_symbol *sym, bool demangle = true);
}; // demangle = true默认是true
缓存的结构是以模块为划分,每个模块维护一个符号表syms_, 而模块的索引使用build_id
简单的可视化如下图所示:
重点:具体的解析函数bcc_buildsymcache_resolve实现如下:
int bcc_buildsymcache_resolve(void *resolver,
struct bpf_stack_build_id *trace,
struct bcc_symbol *sym)
{
std::string build_id;
unsigned char *c = &trace->build_id[0]; // c指向build id字符
int idx = 0; // 索引
/*cannot resolve in case of fallback*/ // 检查地址的状态
if (trace->status == BPF_STACK_BUILD_ID_EMPTY ||
trace->status == BPF_STACK_BUILD_ID_IP)
return 0;
// 按一定规则构建缓存的键
while( idx < 20) { // 对于build id每一位字符
int nib1 = (c[idx]&0xf0)>>4; // 11110000 &保留前四位再右移4位
int nib2 = (c[idx]&0x0f); // 00001111 保留后4位
build_id += "0123456789abcdef"[nib1];
build_id += "0123456789abcdef"[nib2];
idx++;
}
BuildSyms *bsym = static_cast<BuildSyms *>(resolver); // 类型转换
return bsym->resolve_addr(build_id, trace->offset, sym) ? 0 : -1;
}
具体的bsym->resolve_addr,主要功能就是获取此build_id对应的模块(里面有符号表)
bool BuildSyms::resolve_addr(std::string build_id, uint64_t offset,
struct bcc_symbol *sym, bool demangle)
{
// 创建一个map[string] => BuildSymsL::Module的迭代器
std::unordered_map<std::string,std::unique_ptr<BuildSyms::Module> >::iterator it;
// 遍历,寻找对应build id的迭代器
it = buildmap_.find(build_id);
if (it == buildmap_.end())
/*build-id not added to the BuildSym*/
return false;
// 获得到对应的BuildSyms::Mod(也就是第二个val)
BuildSyms::Module *mod = it->second.get();
// 对应模块继续解析符号(根据偏移量)
return mod->resolve_addr(offset, sym, demangle);
}
mod->resolve_addr的具体逻辑如下:
bool BuildSyms::Module::resolve_addr(uint64_t offset, struct bcc_symbol* sym,
bool demangle)
{
std::vector<Symbol>::iterator it;
// 加载符号表
load_sym_table();
if (syms_.empty()) // 符号表为空直接返回
goto unknown_symbol;
// 找到一个当前符号表第一个比offsert偏移量大的符号位置(迭代器)
it = std::upper_bound(syms_.begin(), syms_.end(), Symbol(nullptr, offset, 0));
if (it != syms_.begin()) {
it--; // 回退一个位置(因为迭代器会找第一个比目标值大的)就是目标偏移量的符号
sym->name = (*it).name->c_str();
if (demangle) // 如果函数编译时被改名则记录
sym->demangle_name = sym->name;
sym->offset = (*it).start; // 记录偏移量
sym->module = module_name_.c_str(); // 记录当前模块的模块名
return true;
}
unknown_symbol: // 未知符号
memset(sym, 0, sizeof(struct bcc_symbol));
return false;
}
其中加载符号表的逻辑:
bool BuildSyms::Module::load_sym_table()
{
if (loaded_) // 防止重复加载
return true;
symbol_option_ = {
.use_debug_file = 1,
.check_debug_file_crc = 1,
.use_symbol_type = (1 << STT_FUNC) | (1 << STT_GNU_IFUNC)
};
// 读取elf文件得到每个符号
bcc_elf_foreach_sym(module_name_.c_str(), _add_symbol, &symbol_option_, this);
std::sort(syms_.begin(), syms_.end()); // 排序优化
for(std::vector<Symbol>::iterator it = syms_.begin();
it != syms_.end(); ++it++) {
}
loaded_ = true;
return true;
}
其中_add_symbol的回调函数如下:
int BuildSyms::Module::_add_symbol(const char *symname, uint64_t start,
uint64_t size, void *p)
{
BuildSyms::Module *m = static_cast<BuildSyms::Module *> (p);
auto res = m->symnames_.emplace(symname); // 添加到symnames
m->syms_.emplace_back(&*(res.first), start, size); // 添加到syms列表
return 0;
}
具体的作用也就显而易见了,就是将elf文件中的符号读取到缓存中,并重新整理排序
2. 传统方式
传统方式核心的就是下面的函数:
name, offset, module = BPF._sym_cache(pid).resolve(addr, demangle)
也是加载对应Pid的cache然后进行解析
首先是获取对应Pid的_sym_cache(如果这个pid不在缓存中):
@staticmethod
def _sym_cache(pid):
"""_sym_cache(pid)
Returns a symbol cache for the specified PID.
The kernel symbol cache is accessed by providing any PID less than zero.
"""
if pid < 0 and pid != -1:
pid = -1
if not pid in BPF._sym_caches:
BPF._sym_caches[pid] = SymbolCache(pid)
return BPF._sym_caches[pid]
BPF._sym_caches结构如下,就是一个字典
_sym_caches = {}
看一下SymbolCache类的结构:
class SymbolCache(object):
def __init__(self, pid):
self.cache = lib.bcc_symcache_new( # 初始化缓存
pid, ct.cast(None, ct.POINTER(bcc_symbol_option)))
def resolve(self, addr, demangle): # 本身自带解析函数,也就是一个解析器
"""
Return a tuple of the symbol (function), its offset from the beginning
of the function, and the module in which it lies. For example:
("start_thread", 0x202, "/usr/lib/.../libpthread-2.24.so")
If the symbol cannot be found but we know which module it is in,
return the module name and the offset from the beginning of the
module. If we don't even know the module, return the absolute
address as the offset.
"""
sym = bcc_symbol() # 和build id的结构一样,用于存储解析结果
if demangle:
res = lib.bcc_symcache_resolve(self.cache, addr, ct.byref(sym))
else:
res = lib.bcc_symcache_resolve_no_demangle(self.cache, addr,
ct.byref(sym))
if res < 0:
if sym.module and sym.offset:
return (None, sym.offset,
ct.cast(sym.module, ct.c_char_p).value)
return (None, addr, None)
if demangle:
name_res = sym.demangle_name
lib.bcc_symbol_free_demangle_name(ct.byref(sym))
else:
name_res = sym.name
return (name_res, sym.offset, ct.cast(sym.module, ct.c_char_p).value)
def resolve_name(self, module, name): # 反解析,函数名=>地址
module = _assert_is_bytes(module)
name = _assert_is_bytes(name)
addr = ct.c_ulonglong()
if lib.bcc_symcache_resolve_name(self.cache, module, name,
ct.byref(addr)) < 0:
return -1
return addr.value
首先看一下它如何初始化缓存的(lib.bcc_symcache_new)
void *bcc_symcache_new(int pid, struct bcc_symbol_option *option) {
if (pid < 0)
return static_cast<void *>(new KSyms());
return static_cast<void *>(new ProcSyms(pid, option));
}
可以看到分为两种缓存:内核缓存符号表和进程缓存符号表
我们在这里先不关心这两种缓存结构,而是先将整体的逻辑梳理完再分内核符号缓存解析器和进程符号缓存解析器的结构详述
看一下内核符号表的解析bcc_symcache_resolve:
int bcc_symcache_resolve(void *resolver, uint64_t addr,
struct bcc_symbol *sym) {
SymbolCache *cache = static_cast<SymbolCache *>(resolver);
return cache->resolve_addr(addr, sym) ? 0 : -1;
}
int bcc_symcache_resolve_no_demangle(void *resolver, uint64_t addr,
struct bcc_symbol *sym) {
SymbolCache *cache = static_cast<SymbolCache *>(resolver);
return cache->resolve_addr(addr, sym, false) ? 0 : -1;
}
其实区别不是很大,都是调用符号缓存结构/解析器/resolver的resolve_addr方法去执行解析
那下面就分内核缓存结构和进程缓存结构分别看一下具体的解析逻辑
先看一下KSyms的结构:
class KSyms : SymbolCache {
struct Symbol { // 符号
Symbol(const char *name, const char *mod, uint64_t addr) : name(name), mod(mod), addr(addr) {}
std::string name;
std::string mod;
uint64_t addr;
bool operator<(const Symbol &rhs) const { return addr < rhs.addr; } // 根据地址排序
};
std::vector<Symbol> syms_; // Symbol列表
std::unordered_map<std::string, uint64_t> symnames_; // string符号字符串 => Symbol Idx
static void _add_symbol(const char *, const char *, uint64_t, void *);
public:
virtual bool resolve_addr(uint64_t addr, struct bcc_symbol *sym, bool demangle = true) override;
virtual bool resolve_name(const char *unused, const char *name,
uint64_t *addr) override;
virtual void refresh() override;
};
它的主要方法:
void KSyms::_add_symbol(const char *symname, const char *modname, uint64_t addr, void *p) {
KSyms *ks = static_cast<KSyms *>(p);
ks->syms_.emplace_back(symname, modname, addr);
}
void KSyms::refresh() { // 刷新就是重新排序
if (syms_.empty()) {
bcc_procutils_each_ksym(_add_symbol, this);
std::sort(syms_.begin(), syms_.end());
}
}
bool KSyms::resolve_addr(uint64_t addr, struct bcc_symbol *sym, bool demangle) {
refresh();
std::vector<Symbol>::iterator it;
if (syms_.empty())
goto unknown_symbol;
it = std::upper_bound(syms_.begin(), syms_.end(), Symbol("", "", addr)); // 基本就是同样的逻辑,找到刚好大于的一个it(也就是Symbol结构)
if (it != syms_.begin()) {
it--;
sym->name = (*it).name.c_str();
if (demangle)
sym->demangle_name = sym->name;
sym->module = (*it).mod.c_str();
sym->offset = addr - (*it).addr;
return true;
}
unknown_symbol:
memset(sym, 0, sizeof(struct bcc_symbol));
return false;
}
重点的解析逻辑resolve_addr其实和build id的方式差不多,这里就不再详细解析了
然后是进程符号表缓存的结构ProcSyms:
class ProcSyms : SymbolCache {
struct NameIdx { // 函数名索引结构
size_t section_idx;
size_t str_table_idx;
size_t str_len;
bool debugfile;
};
struct Symbol {
// 两类symbol初始化方式
Symbol(const std::string *name, uint64_t start, uint64_t size)
: is_name_resolved(true), start(start), size(size) {
data.name = name;
}
Symbol(size_t section_idx, size_t str_table_idx, size_t str_len, uint64_t start,
uint64_t size, bool debugfile)
: is_name_resolved(false), start(start), size(size) {
data.name_idx.section_idx = section_idx;
data.name_idx.str_table_idx = str_table_idx;
data.name_idx.str_len = str_len;
data.name_idx.debugfile = debugfile;
}
bool is_name_resolved; // 表示自己是否已经被解析
union {
struct NameIdx name_idx; // 函数名索引
const std::string *name{nullptr}; // 函数名
} data;
uint64_t start; // 符号开始的地址
uint64_t size; // 符号的大小
bool operator<(const struct Symbol& rhs) const { // 比较函数,根据start地址
return start < rhs.start;
}
};
enum class ModuleType { // 不同的ELF文件类型
UNKNOWN,
EXEC,
SO,
PERF_MAP, // 为java提供的Perf_Map
VDSO
};
struct Module { // 模块
struct Range { // 每个模块的地址范围 (类比于build id因为没有build id的唯一标识所以用一个范围表示一个module)
uint64_t start; // 开始地址
uint64_t end; // 结束地址
uint64_t file_offset; // 文件的偏移量
Range(uint64_t s, uint64_t e, uint64_t f)
: start(s), end(e), file_offset(f) {}
};
Module(const char *name, const char *path, struct bcc_symbol_option *option);
std::string name_;
std::string path_;
std::vector<Range> ranges_;
bool loaded_;
bcc_symbol_option *symbol_option_;
ModuleType type_;
// The file offset within the ELF of the SO's first text section.
uint64_t elf_so_offset_;
uint64_t elf_so_addr_;
std::unordered_set<std::string> symnames_;
std::vector<Symbol> syms_;
void load_sym_table();
bool contains(uint64_t addr, uint64_t &offset) const;
uint64_t start() const { return ranges_.begin()->start; }
bool find_addr(uint64_t offset, struct bcc_symbol *sym);
bool find_name(const char *symname, uint64_t *addr);
static int _add_symbol(const char *symname, uint64_t start, uint64_t size,
void *p);
static int _add_symbol_lazy(size_t section_idx, size_t str_table_idx,
size_t str_len, uint64_t start, uint64_t size,
int debugfile, void *p); // 添加符号索引
};
int pid_;
std::vector<Module> modules_;
ProcStat procstat_; // 进程状态
bcc_symbol_option symbol_option_;
static int _add_module(mod_info *, int, void *);
void load_modules();
public:
ProcSyms(int pid, struct bcc_symbol_option *option = nullptr);
virtual void refresh() override;
virtual bool resolve_addr(uint64_t addr, struct bcc_symbol *sym, bool demangle = true) override;
virtual bool resolve_name(const char *module, const char *name,
uint64_t *addr) override;
};
重点:具体的解析逻辑resolve_addr:
bool ProcSyms::resolve_addr(uint64_t addr, struct bcc_symbol *sym,
bool demangle) {
if (procstat_.is_stale()) // “不健康”状态也就是符号表缓存不是最新,则更新
refresh();
memset(sym, 0, sizeof(struct bcc_symbol));
const char *original_module = nullptr;
uint64_t offset;
bool only_perf_map = false;
for (Module &mod : modules_) { // 遍历modules
if (only_perf_map && (mod.type_ != ModuleType::PERF_MAP)) // 如果只用perf-map则屏蔽掉不是perf-map的类型
continue;
if (mod.contains(addr, offset)) { // 找到地址对应的模块并计算赋值偏移量
if (mod.find_addr(offset, sym)) { // 找到偏移量对应的符号sym
if (demangle) {
if (sym->name && (!strncmp(sym->name, "_Z", 2) || !strncmp(sym->name, "___Z", 4)))
sym->demangle_name =
abi::__cxa_demangle(sym->name, nullptr, nullptr, nullptr);
if (!sym->demangle_name)
sym->demangle_name = sym->name;
}
return true;
} else if (mod.type_ != ModuleType::PERF_MAP) { // 如果对应的偏移量找不到符号那么就尝试在perf-map中尝试寻找
// In this case, we found the address in the range of a module, but
// not able to find a symbol of that address in the module.
// Thus, we would try to find the address in perf map, and
// save the module's name in case we will need it later.
original_module = mod.name_.c_str();
only_perf_map = true;
}
}
}
// If we didn't find the symbol anywhere, the module name is probably
// set to be the perf map's name as it would be the last we tried.
// In this case, if we have found the address previously in a module,
// report the saved original module name instead.
// 在perf-map中找到了地址对应的符号,但是使用其原来匹配的模型名替代(因为perf-map的方式不提供模型名)
if (original_module)
sym->module = original_module;
return false;
}
需要详细的看一下contains的实现:
bool ProcSyms::Module::contains(uint64_t addr, uint64_t &offset) const {
for (const auto &range : ranges_) { // 遍历每个range,确定地址是否在某个范围内
if (addr >= range.start && addr < range.end) {
// 不同文件类型使用不同的方式计算offset
if (type_ == ModuleType::SO || type_ == ModuleType::VDSO) {
// Offset within the mmap
offset = addr - range.start + range.file_offset; // 地址偏移模块开始位置 + 文件原本的偏移量
// Offset within the ELF for SO symbol lookup
offset += (elf_so_addr_ - elf_so_offset_);
} else {
offset = addr;
}
return true;
}
}
return false;
}
再看一下find_addr的实现:
bool ProcSyms::Module::find_addr(uint64_t offset, struct bcc_symbol *sym) {
load_sym_table(); // 加载符号表
sym->module = name_.c_str();
sym->offset = offset;
// 在符号表中寻找刚好大于此偏移量位置的符号
auto it = std::upper_bound(syms_.begin(), syms_.end(), Symbol(nullptr, offset, 0));
if (it == syms_.begin())
return false;
--it;
uint64_t limit = it->start; // limit表示嵌套发生时最起码的end
for (; offset >= it->start; --it) { // 循环往前寻找, --it就是发生了嵌套向前回溯
if (offset < it->start + it->size) { // it->start + it->size = end 注意是严格小于才会确定是此符号it,然后进行解析逻辑
// Resolve and cache the symbol name if necessary
if (!it->is_name_resolved) { // 未被解析
std::string sym_name(it->data.name_idx.str_len + 1, '\0');
if (bcc_elf_symbol_str(path_.c_str(), it->data.name_idx.section_idx,
it->data.name_idx.str_table_idx, &sym_name[0], sym_name.size(),
it->data.name_idx.debugfile))
break;
it->data.name = &*(symnames_.emplace(std::move(sym_name)).first);
it->is_name_resolved = true; // 缓存符号名 标记已经被解析(缓存)
}
// 如果已经被解析则直接赋值
sym->name = it->data.name->c_str();
sym->offset = (offset - it->start); // 改变偏移量
return true;
}
if (limit > it->start + it->size) // 如果it往前回溯到某一位置,但是其end的位置却没有达到最小,则认为符号不存在,中止
break;
// But don't step beyond begin()! 到达最开头begin 中止
if (it == syms_.begin())
break;
}
return false;
}
关于注释:
it指向起始地址严格大于我们要查找的地址的符号。只要当前符号仍然低于期望地址,就开始向后,并查看当前符号的结尾(Start + size)是否高于期望地址。一旦我们有了匹配的符号,就返回它。注意,仅仅查看--it的值是不够的,因为符号可以嵌套
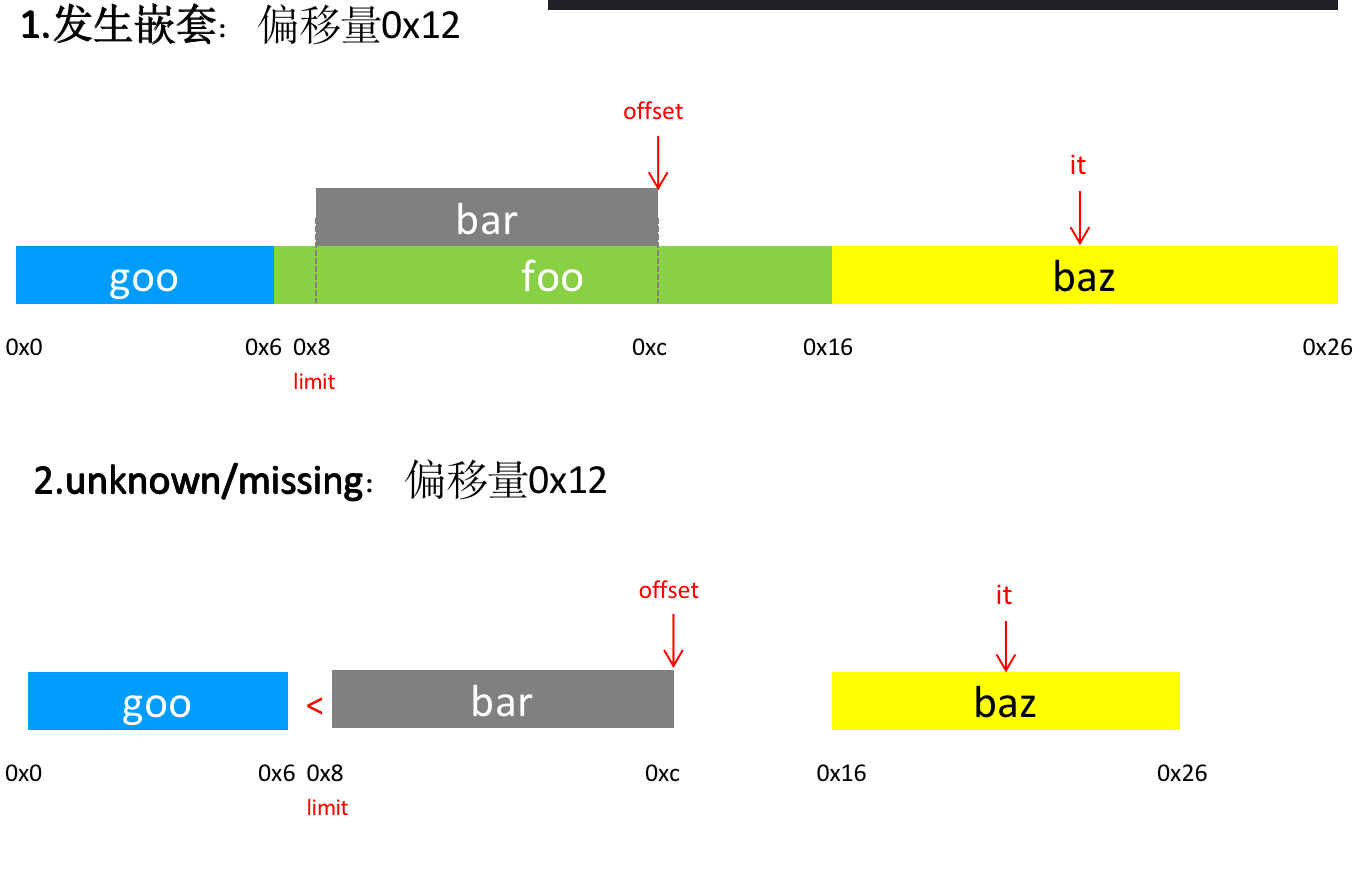
举了一个嵌套的例子:对于偏移量0x12:
SYMBOL START SIZE END
goo 0x0 0x6 0x0 + 0x6 = 0x6
foo 0x6 0x10 0x6 + 0x10 = 0x16
bar 0x8 0x4 0x8 + 0x4 = 0xc
baz 0x16 0x10 0x16 + 0x10 = 0x26
upper_bound查找将返回baz(因为比较函数是根据start),然后返回一个符号将我们带回到bar(返回后一个),它不包含偏移0x12,并且嵌套在foo中(bar的范围确实被foo包含)。再返回一个符号将我们带到foo,它包含0x12,是一个匹配。
但是,我们也不想遍历整个符号列表来查找本身就未知或缺失的符号(因为如果是这两种符号的话在上面的逻辑中就会一直往上回溯)。因此,所以如果我们到达的函数没有覆盖it前面的函数我们就会中断(就是没出现上面的foo覆盖bar范围的情况),这意味着它不可能是包含我们要查找的地址的嵌套函数。
这里可以补充一个Unknown的例子:
根据上面的过程确定了it,就确定了Symbol结构体,其中就含有指定的section段id以及等等符号名索引信息(NameIdx)
下面详细看一下解析逻辑,就是:
if (offset < it->start + it->size) { // it->start + it->size = end 注意是严格小于才会确定是此符号it(it就是symbol结构体),然后进行解析逻辑
// Resolve and cache the symbol name if necessary
if (!it->is_name_resolved) { // 未被解析
std::string sym_name(it->data.name_idx.str_len + 1, '\0'); // 初始化一个len长度的符号名
if (bcc_elf_symbol_str(path_.c_str(), it->data.name_idx.section_idx, // 调用此函数解析
it->data.name_idx.str_table_idx, &sym_name[0], sym_name.size(),
it->data.name_idx.debugfile))
break;
it->data.name = &*(symnames_.emplace(std::move(sym_name)).first); // 加入解析的符号名到symnames_中(first就是取键名)
it->is_name_resolved = true; // 缓存符号名 标记已经被解析(缓存)
}
// 如果已经被解析则直接赋值
sym->name = it->data.name->c_str();
sym->offset = (offset - it->start); // 改变偏移量
return true;
}
对于其中的bcc_elf_symbol_str函数,如下:
int bcc_elf_symbol_str(const char *path, size_t section_idx,
size_t str_table_idx, char *out, size_t len,
int debugfile)
{
Elf *e = NULL, *d = NULL;
int fd = -1, dfd = -1, err = 0;
const char *name;
char *debug_file = NULL;
if (!out)
return -1;
if (openelf(path, &e, &fd) < 0) // 打开elf文件
return -1;
if (debugfile) {
debug_file = find_debug_file(e, path, 0); // 找debug链接的文件
if (!debug_file) {
err = -1;
goto exit;
}
if (openelf(debug_file, &d, &dfd) < 0) { // 打开debug链接的文件
err = -1;
goto exit;
}
if ((name = elf_strptr(d, section_idx, str_table_idx)) == NULL) {
err = -1;
goto exit;
}
} else {
if ((name = elf_strptr(e, section_idx, str_table_idx)) == NULL) {
err = -1;
goto exit;
}
}
strncpy(out, name, len); // 赋值
exit:
if (debug_file)
free(debug_file);
if (e)
elf_end(e);
if (d)
elf_end(d);
if (fd >= 0)
close(fd);
if (dfd >= 0)
close(dfd);
return err;
}
这个函数整体的逻辑就是,根据NameIdx结构中的索引打开elf文件索引,如果使用了debug文件(额外链接或者导出),那么对应的也会去寻找该文件,最终确定地址对应的符号
















 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











